|
||||
|
|
3. СТАТИСТИЧЕСКИЕ МЕТОДЫ ХРОНОЛОГИИ3.1. РОЛЬ И СУТЬ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИРешающую роль в уточнении хронологических данных — наряду с астрономическими — играют статистические методы. Методы анализа противоречивой и неполной информации получили серьезное развитие лишь в последние десятилетия. Математические методы во многих принципиальных случаях позволяют определить истинность-ложность или корреляцию-независимость событий практически со стопроцентной точностью. Грамотный статистический анализ легендарных хронологических событий позволяет «предсказать» истинность, время и место проистекания этих событий. Создание глобальной хронологической карты позволило восстановить предположительный механизм возникновения скалигеровской версии древней и средневековой хронологии. Методики проверки основ хронологии во многом перекликаются с хорошо известными в теории обработки информации расчетами коэффициентов корреляции, однако они лучше адаптированы и более чувствительны для задач обработки хронологических данных. Одной методики — даже такой эффективной, как астрономическая — для глубокого анализа проблемы датировки совершенно недостаточно. Проблема исключительно сложна и требует перекрестных проверок дат разными методами. И здесь решающую роль в уточнении хронологических данных играют статистические методы. Методы анализа противоречивой и неполной информации получили серьезное развитие лишь в последние десятилетия. Корректная обработка статистической информации позволяет при изучении достаточно большого количества событий, разбив эти события на группы, выявить связь (корреляцию) или отсутствие связи (независимость) между этими группами, оценить достоверность рассматриваемых событий и вообще сделать эффектные выводы — иногда самого неожиданного характера. Расчет коэффициентов корреляции позволяет четко уяснить возможность связи между самыми разными событиями, происходившими вроде бы в разных странах и в разное время. Статистические особенности текста позволяют установить автора документа, его образовательный уровень, возраст, пол, национальность, период жизни и многие другие детали биографии. Очень важно, что развитые математические методы во многих принципиальных случаях позволяют определить истинность-ложность или корреляцию-независимость событий практически со стопроцентной точностью. Немалую роль здесь играет и появление все более быстрых компьютеров и все более удобных вычислительных программ. Все это привело к небывалому расцвету обработки информации как науки и возрастанию ее роли в жизни общества. Быть может, наиболее эффектное проявление своих возможностей обработка информации нашла в последние годы при создании научных основ исторической науки. Не исключено, что такой прорыв в развитии хронологии даст пример для ускорения трансформации всех общественных наук в более точные и логичные науки.
Программа проверки основ хронологии реализована А.Т. Фоменко в следующей форме. 1. Разработаны новые эмпирико-статистические методики датирования древних событий. 2. Их эффективность экспериментально проверена на достаточно большом материале средневековой и новой истории XIV–XX веков. Эта проверка подтвердила правильность результатов, получаемых при помощи методик. 3. Затем эти же методики были применены к хронологическому материалу древней истории. В результате были обнаружены фантомные дубликаты, странные периодичности в скалигеровской версии древней и средневековой истории. 4. Все эти фантомные дубликаты были собраны и систематизированы в виде глобальной хронологической карты. 5. На основе глобальной хронологической карты удалось восстановить предположительный механизм возникновения скалигеровской версии древней и средневековой хронологии. Ниже в данной главе для тех, кому интересны математические подробности, кратко изложена суть некоторых из этих методик. Основа использованных методик во многом перекликается с хорошо известными в теории обработки информации расчетами коэффициентов корреляции, однако эти методики лучше адаптированы и более чувствительны для задач обработки хронологических данных. В дальнейшем эти методы были существенно развиты в совместных исследованиях Г.В. Носовского и А.Т. Фоменко. 3.2. ПРИНЦИП КОРРЕЛЯЦИИ МАКСИМУМОВ ДЛЯ ИСТОРИЧЕСКИХ ТЕКСТОВХроника истории искусств и военная летопись существенно по-разному расставляют акценты и по-разному распределяют объем информации по годам. Принцип корреляции максимумов: графики объема глав для зависимых летописей Х и Y, то есть для описывающих один и тот же исторический период (АВ) и одно и то же государство Г, должны одновременно достигать локальных максимумов (делать всплески) на отрезке (АВ), то есть годы, подробно описанные в X, и годы, подробно описанные в Y, должны быть близки или совпадать. Пусть некоторый исторический период от года А до года В в истории одного государства описан в каком-то достаточно обширном погодном тексте X (хронике, летописи и т. п.). То есть летопись разбита (или может быть разбита) на куски — главы X(t), каждая из которых описывает один свой год t. Подсчитаем объем каждого такого куска, например, число слов или число знаков, страниц и т. п. Затем изобразим полученные числа в виде графика, отложив по горизонтали годы t, а по вертикали — объемы глав (рис. 3–1). 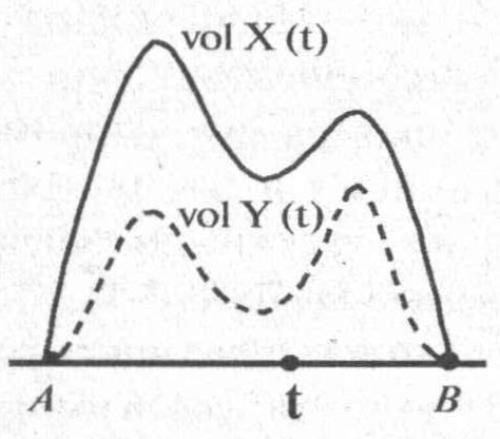
Для другого погодного текста Y, то есть тоже описывающего события этой же эпохи (АВ) по годам, соответствующий график будет иметь, вообще говоря, другой вид, так как большую роль в распределении объема играют личные интересы авторов текстов. Например, хроника истории искусств и военная летопись существенно по-разному расставляют акценты и по-разному распределяют объем информации по годам.
Сформулируем модель потери информации: от тех лет, в которые их современниками было написано особенно много текстов, — больше и останется. Другими словами, если фиксировать какой-то момент времени М, то можно построить график CM(t), показывающий объем текстов, которые дожили до момента времени М и описывают события года (t) (рис. 3–2). То есть график CM(t) — это остаточный, сохранившийся фонд информации от эпохи (АВ), который дошел до года М. 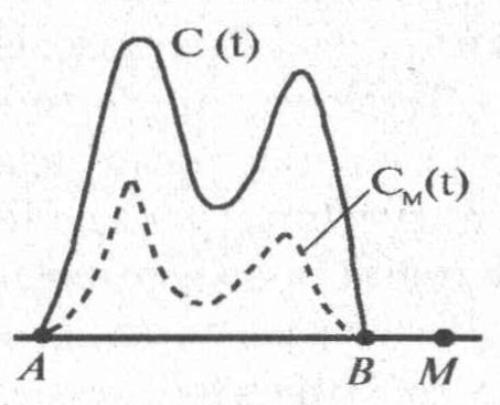
Новая модель может быть переформулирована, следовательно, таким образом: график CM(t) должен иметь всплески примерно в те же годы на интервале (АВ), что и исходный график C(t). Разумеется, проверить модель в таком ее виде трудно, поскольку график C(t) первоначального фонда информации сегодня точно неизвестен. Но одно из следствий проверить можно. Поскольку более поздние летописцы X и Y, описывая один и тот же исторический период (АВ), уже не являются современниками этих древних событий, то они вынуждены опираться на приблизительно один и тот же набор дошедших до них текстов. Следовательно, они должны в среднем более подробно описать именно те годы, от которых сохранилось больше текстов, и менее подробно — годы, о которых сохранилось мало информации. Другими словами, летописцы должны увеличивать подробность изложения при описании тех лет, от которых до них дошло больше текстов. На языке графиков объема эта модель выглядит так. Если летописец X живет в эпоху М, то он будет опираться на фонд CM(t). Если летописец Y живет в эпоху N, отличную, вообще говоря, от эпохи М, то он опирается на сохранившийся фонд CN(t). Естественно ожидать, что в среднем хронисты работают более или менее добросовестно, а потому они должны более подробно описать те годы из эпохи (АВ), от которых до них дошло больше информации, текстов. Другими словами, график объемов vol X(t) будет иметь всплески примерно в те годы, где имеет всплески график CM(t). В свою очередь; график vol Y(t) будет иметь всплески примерно в те годы, где делает всплески график CN(t). Но точки всплесков графика CM(t) близки к точкам всплесков исходного графика C(t). Аналогично и точки всплесков графика CN(t) близки к точкам всплесков графика C(t). Следовательно, графики \vol X(t) и \vol Y(t) должны делать всплески примерно одновременно, т. е. точки их локальных максимумов должны коррелировать (рис. 3–3). При этом, конечно, амплитуды графиков могут быть существенно различны. 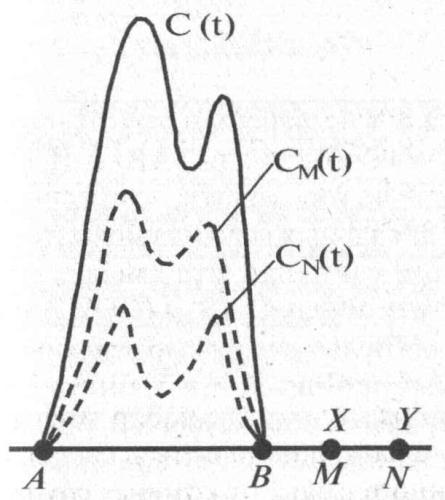
Окончательно принцип корреляции максимумов формулируется так. Графики объема глав для зависимых летописей X и Y, описывающих один и тот же исторический период (АВ) и одно и то же государство Г, должны одновременно достигать локальных максимумов (делать всплески) на отрезке (АВ), то есть годы, подробно описанные в X, и годы, подробно описанные в Y, должны быть близки или совпадать (рис. 3–4). 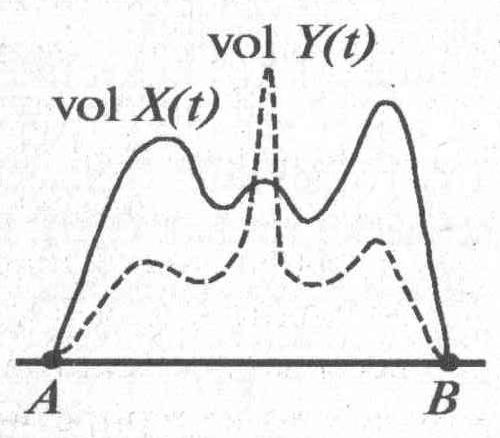
Напротив, если летописи X и Y независимы, то есть описывают либо разные исторические периоды (АВ) и (CD) (одинаковой длины), либо разные государства, то графики объема для X и Y достигают локальных максимумов в разных точках (рис. 3–5). При этом считается, что для сравнения графиков следует совместить отрезки (АВ) и (CD). Этот принцип подтвердится, если для большинства пар реальных, достаточно больших зависимых летописей X и Y, описывающих одни и те же события, графики объема для X и Y делают всплески приблизительно одновременно, в одни и те же годы. При этом величина этих всплесков может быть существенно различной. Для реальных независимых хроник какая-либо корреляция точек всплесков должна отсутствовать. Конечно, для конкретных зависимых хроник одновременность всплесков графиков объема может быть лишь приблизительной. 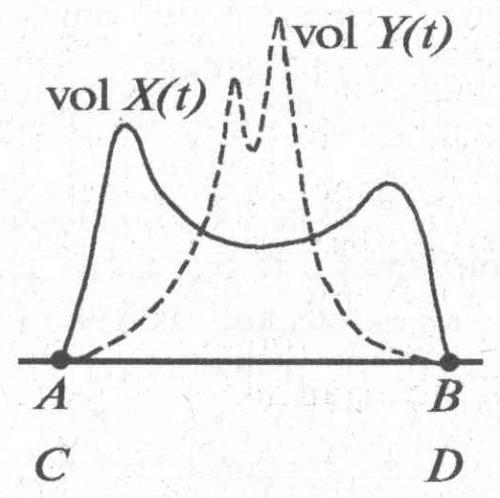
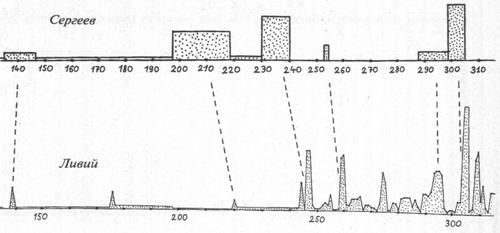
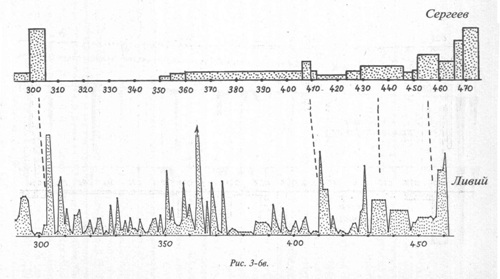
Для количественной оценки близости точек всплесков поступим так. Вычислим число f(X,Y) — сумму квадратов чисел f[k], где f[k] — расстояние в годах от точки всплеска с номером «k» графика объема X до точки всплеска с номером «k» графика объема Y. Если оба графика делают всплески одновременно, то моменты всплесков с одинаковыми номерами совпадают и все числа f[k] равны нулю. Рассмотрев достаточно большой фиксированный запас различных реальных текстов Н и вычисляя для каждого из них число f(X,H), отберем затем только такие тексты Н, для которых это число не превосходит числа f(X,Y). Подсчитав долю таких текстов во всем запасе текстов Н, получаем коэффициент, который можно интерпретировать как вероятность p(X,Y). Если коэффициент p(X,Y) мал, то летописи X и Y зависимы. Если же коэффициент велик, то летописи X и Y независимы, то есть сообщают о разных событиях. 3.3. ПРИМЕРЫ ВЗАИМОЗАВИСИМОСТИ ИСТОРИЧЕСКИХ ДОКУМЕНТОВДля независимых текстов описывающий корреляцию коэффициент p(X,Y) колеблется от 1 до 1/100 при количестве локальных максимумов от 10 до 15. Если же летописи X и Y описывают одни и те же события, то р не превосходит 10-8 для того же количества максимумов. Для упомянутых имен, упоминаний данного года в тексте, частот ссылок на какой-либо другой фиксированный текст и т. п. также выполняется принцип корреляции максимумов. В 1978–1980 гг. А.Т. Фоменко был проведен первый обширный вычислительный эксперимент по подсчету чисел p(X,Y) для нескольких сотен пар конкретных исторических текстов — хроник, летописей и т. п. Оказалось, что коэффициент p(X,Y) достаточно хорошо различает заведомо зависимые и заведомо независимые пары летописей. Было обнаружено, что для всех исследованных пар реальных летописей X,Y, описывающих заведомо разные события (разные исторические эпохи или разные государства), то есть для независимых текстов, число p(X,Y) колеблется от 1 до 1/100 при количестве локальных максимумов от 10 до 15. Напротив, если летописи X и Y зависимы, то есть описывают одни и те же события, то число p(X,Y) не превосходит 10-8 для того же количества максимумов. Можно отметить, что методика дает весьма четкий количественный критерий определения взаимозависимости текстов. Рассмотрим пример. В качестве текста X была взята монография современного автора В.С. Сергеева «Очерки по истории Древнего Рима», тома 1, 2 (М.: ОГИЗ, 1938). В качестве текста Y — «античный» источник — «Римская история» Тита Ливия, тома 1–6 (М., 1897–1899) (рис. 3-6а, 3-6б и 3-6в). Оказалось, что здесь p(X,Y) = 2 × 10-12. Это указывает на зависимость текстов. Оба текста описывают один и тот же период в истории «античного» Рима. Если же в качестве X1 взять снова текст В.С. Сергеева, а в качестве Y1 — его же, но заменив порядок лет в нем на противоположный, грубо говоря, прочитав его «задом наперед», то p(X1,Y1) = 1/3. Что неудивительно, так как наша операция «перевертывания летописи» дает два заведомо независимых текста. 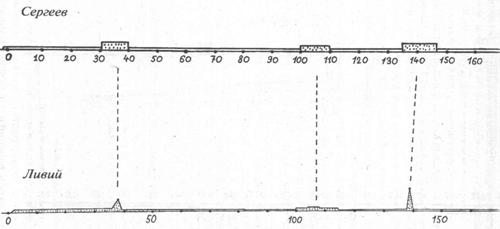
Другой пример зависимых текстов: X = Никифоровская летопись, Y = Супрасльская летопись (рис. 3–7). Оба графика объемов «глав» на интервале 850 — 1255 гг. н. э. делают всплески практически одновременно, в одни и те же годы. Здесь p(X,Y) = 10-24. 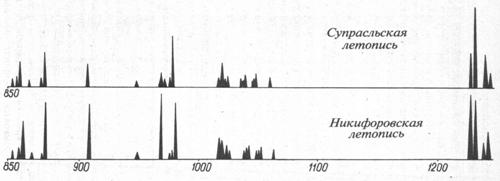
В вычислительном эксперименте сравнивались: а) древние тексты с древними; б) древние с современными; в) современные с современными. Наряду с графиками объема «глав» исследовались и другие количественные характеристики текстов. Например, графики количества упоминаний имен, графики количества упоминаний данного года в тексте, графики частот ссылок на какой-либо другой фиксированный текст и т. п. Оказалось, что для всех этих характеристик выполняется тот же принцип корреляции максимумов. А именно, графики зависимых текстов делают всплески практически одновременно, а для независимых текстов точки всплесков графиков никак не коррелируют. Это позволяет предложить новую методику датирования древних событий. Хотя она, конечно, не универсальна. Опишем идею метода. Пусть Y — исторический текст, описывающий неизвестные события с утраченной абсолютной датировкой. Пусть годы t отсчитываются в тексте от какого-то события местного значения, например, от основания какого-то города или от момента воцарения какого-то царя, абсолютные датировки которых неизвестны. Подсчитаем для текста Y график объема «глав» и сравним его с графиками объема других текстов, для которых абсолютная датировка событий, описанных в них, известна. Если среди этих текстов обнаружится текст X, для которого число p(X,Y) мало, то есть имеет такой же порядок, как и для пар зависимых текстов (не превосходит, например, числа 10-8 для соответствующего количества локальных максимумов), то можно с достаточно большой вероятностью (тем большей, чем меньше число p(X,Y) сделать вывод о совпадении описываемых в этих текстах событий.
3.4. ЧИСЛОВЫЕ ДИНАСТИИ И ПРИНЦИП МАЛЫХ ИСКАЖЕНИЙСуществуют «инвариантные» факты, описания которых в сравнительно малой степени зависят от симпатий летописцев, — например, длительность правления. Последовательность чисел длительностей правления царей в данной династии, извлекаемая из летописи, называется числовой династией. Принцип малых искажений: если две числовые династии мало отличаются друг от друга, то они изображают одну и ту же реальную династию. Для зависимых династий описывающий корреляцию коэффициент с(М,Н) находится в пределах от 10-12 до 10-8, а для независимых династий — колеблется от 1/10 до 1/100 и в редких случаях подает до 1/1000. Пусть обнаружен исторический текст, описывающий неизвестную династию правителей с указанием длительностей их правлений. Возникает вопрос: является ли эта династия новой, ранее неизвестной и, следовательно, нуждающейся в датировке, или это одна из известных династий, описанная в непривычных для нас терминах — например, видоизменены имена правителей и т. п.? Ответ дается излагаемой ниже методикой. Рассмотрим последовательность реальных правителей государства. Условно назовем эту последовательность реальной династией. При этом ее члены не обязаны быть родственниками. Часто одна и та же реальная династия описывается в разных документах разными летописцами с разных точек зрения. Например, по-разному оценивается деятельность правителей и т. д. Тем не менее существуют «инвариантные» факты, описания которых в меньшей степени зависят от симпатий летописцев — например, длительность правления. Обычно нет особых причин, по которым хронист значительно и намеренно исказил бы это число. Однако перед летописцами часто возникали трудности в подсчете длительности правления царя.
Итак, каждый летописец, описывая реальную династию, по-своему вычисляет длительности правления царей и получает последовательность чисел A[1], А[2]…А[k], где число А[р] выражает — быть может, с ошибкой — реальную длительность правления царя с номером «р», а число «k» — это общее число царей в данной династии. Эта последовательность чисел, извлекаемая из летописи, называется числовой династией. Другой летописец, описывая эту же реальную династию, припишет этим же царям, возможно, другие длительности правлений. В результате получится другая числовая династия В[1], В[2]…В[k]. Таким образом, одна и та же реальная династия, описанная в разных летописях, может изображаться в них разными числовыми династиями. Сформулируем принцип малых искажений: если две числовые династии мало отличаются друг от друга, то они изображают одну и ту же реальную династию, то есть являются двумя вариантами ее описания. В этом случае числовые династии назовем зависимыми. Если же две числовые династии изображают две различные реальные династии, то они значительно отличаются друг от друга. В этом случае назовем их независимыми. Остальные пары династий назовем нейтральными. Другими словами, летописцы мало искажают реальные династии. Во всяком случае, возникающие расхождения меньше, чем имеющиеся расхождения между различными, то есть независимыми реальными династиями. В случае справедливости принципа малых искажений обнаруживается важное и отнюдь не очевидное свойство, характеризующее практически всех древних летописцев. А именно: числовые династии, возникающие при описании одной реальной династии, отличаются друг от друга и от своего прототипа меньше, чем две разные реальные династии. Оказывается, для оценки «близости» двух династий можно ввести числовой коэффициент, аналогичный p(X,Y). Этот коэффициент с(М,Н) также имеет смысл вероятности. Не вникая в детали, опишем с(М,Н). Числовую династию удобно изображать в виде графика, отложив по горизонтали номера царей, а по вертикали — длительности их правлений. Мы скажем, что династия П «похожа» на две династии М и Н, если график династии П отличается от графика династии М не больше, чем график династии Н отличается от графика династии М. В качестве с(М,Н) берется доля, которую династии, «похожие» на династии М и Н, составляют во множестве всех династий. Другими словами, подсчитывается число: (количество династий, «похожих» на М и Н) / (общее количество династий, описанных в летописях). Длительности правлений могут определяться летописцами с ошибкой, и из летописей фактически извлекаются только некоторые приближенные их значения. Можно математически описать вероятностные механизмы, приводящие к появлению этих ошибок. Кроме того, учитывались еще две возможные ошибки летописцев: перестановка двух соседних царей и замена двух соседних царей одним «царем» с суммарной длительностью правления. Принцип малых искажений нуждается в проверке. В 1977–1979 гг. А.Т. Фоменко, вместе с П. Пучковым и М. Замалетдиновым обработали хронологические таблицы Блера, содержащие все основные хронологические данные из истории Европы, Средиземноморья, Ближнего Востока, Египта за период от 4000 года до н. э. до 1800 года н. э. Эти данные были продублированы и дополнены сведениями из 14 современных хронологических таблиц. Для всех эпох всех этих регионов был составлен полный список всех 15-членных династий, то есть составлены списки всех групп, состоящих из 15 последовательных царей. Каждый царь может при этом попасть в несколько 15-членных династий, то есть династии могут «перекрываться». Приведем здесь лишь часть полного списка основных групп династий: епископы и папы в Риме, Египет, Византия, Римская империя, Испания, Россия, Франция, Италия, сарацины, Оттоманская империя, Шотландия, Лaкедемон, Германия, Швеция, Дания, Израиль, Вавилон, Сирия, первосвященники в Иудее, грекобактрийцы, Сицион, Иудея, Португалия, Парфия, экзархи в Равенне, Боспорское царство, Македония, Польша, Англия. Для любых 15-членных династий М и Н можно подсчитать с(М,Н). Проведенный затем вычислительный эксперимент показал, что принцип малых искажений полностью подтверждается, а именно: для заведомо зависимых династий число с(М,Н) всегда имеет величину от 10-12 до 10-8. А для заведомо независимых династий типичное значение коэффициента с(М,Н) колеблется от 1/10 до 1/100 и в редких случаях падает до 1/1000. Налицо резкое различие — на несколько порядков — между зависимыми и независимыми династиями. Итак, при помощи коэффициента с(М,Н) можно уверенно различать зависимые и независимые пары династий. Важный экспериментальный факт состоит в том, что летописцы ошибаются не слишком сильно. Во всяком случае, их ошибки существенно меньше величины, различающей независимые династии. Это позволяет, в рамках проведенного эксперимента, предложить новую методику распознавания зависимых династий и датировки неизвестных династий. Поступая по аналогии с предыдущим пунктом, вычисляем для неизвестной династии Д коэффициент с(М,Д), где М — известные династии. Если найдется династия М, для которой этот коэффициент мал, то это дает основание утверждать, что династии М и Д зависимы с вероятностью с(М,Д). То есть династии М и Д соответствуют одной реальной династии, датировка которой уже известна, поскольку династия М предполагается уже датированной. Эта методика была проверена на средневековых династиях с заранее известной датировкой. Эффективность методики полностью подтвердилась. 3.5. ПРИНЦИП ЗАТУХАНИЯ ЧАСТОТСредняя длительность правления реальных царей, зафиксированных в дошедших до нас летописях, равна 17,1 года. Число разных лиц с одинаковыми полными именами в историческом документе ничтожно мало по сравнению с числом всех персонажей. Принцип затухания частот связан с тем, что каждое поколение рождает новые исторические лица, а при смене поколений эти лица сменяются. На значительных интервалах времени не было моды на древние имена. Настоящая методика позволяет выстроить хронологически правильный порядок фрагментов текста с обнаружением в нем дубликатов на основе анализа, например, совокупности собственных имен, упомянутых в тексте. Целью создания метода датировки, основанного на количественных характеристиках текстов и не требующего анализа их смыслового содержания, которое может быть весьма многозначно и расплывчато. Если в документе упомянуты какие-либо знаменитые персонажи, известные из других, уже датированных хроник, то это позволяет датировать описанные в тексте события. Однако если такое отождествление сразу не удается и если, кроме того, описаны события из жизни нескольких поколений с большим количеством ранее неизвестных действующих лиц, то задача установления тождества персонажей с ранее известными усложняется. Для краткости назовем фрагмент текста, описывающий события из жизни одного поколения, «главой-поколением». Будем считать, что средняя длительность жизни одного поколения — это средняя длительность правления реальных царей, зафиксированных в дошедших до нас летописях. Эта средняя длительность правления была вычислена А.Т. Фоменко на основании результатов, полученных при обработке хронологических таблиц Блера. Она оказалась равной 17,1 года. При работе с реальными историческими текстами выделение в них «глав-поколений» иногда наталкивается на трудности. В таких случаях рассматривалось приблизительное разбиение текста на последовательные фрагменты. Пусть летопись X описывает события на достаточно большом интервале времени (АВ), на протяжении которого менялось по крайней мере несколько поколений персонажей. Пусть летопись X разбита на «главы-поколения» Х(Т), где Т — порядковый номер поколения, описанного во фрагменте X(Т), в той нумерации «глав», которая фиксирована в тексте. Возникает вопрос: правильно ли занумерованы, упорядочены эти «главы-поколения» в летописи? Или же если эта нумерация утрачена или сомнительна, то как ее восстановить? Другими словами, как правильно расположить во времени «главы» друг относительно друга? Оказывается, для реальных исторических текстов в подавляющем большинстве случаев работает следующая «формула»: полное имя — персонаж. Это означает следующее. Если интервал времени, описываемый летописцем, достаточно велик, например, составляет несколько десятков или сотен лет, то, как установил А.Т. Фоменко в результате анализа большого набора исторических документов, в подавляющем большинстве случаев разные персонажи имеют в одном и том же тексте разные полные имена. Полное имя может состоять из нескольких слов, например, «Карл Плешивый». Другими словами, число разных лиц с одинаковыми полными именами ничтожно мало по сравнению с числом всех персонажей. Это верно для нескольких сотен исследованных исторических текстов, описывающих Грецию, Германию, Италию, Россию и т. д. В самом деле, летописец заинтересован в различении разных персонажей, чтобы избежать путаницы. Простейший способ добиться этого — дать разным лицам разные полные имена. Эта простая мысль и подтверждается подсчетами. Сформулируем принцип затухания частот, описывающий хронологически правильный порядок «глав-поколений». При правильной нумерации «глав-поколений» летописец, переходя от описания одного поколения к следующему, сменяет и персонажей. А именно при описании поколений, предшествующих поколению с номером Q, он ничего не говорит о персонажах этого поколения, так как они еще не родились. Затем при описании поколения Q летописец именно здесь больше всего говорит о персонажах этого поколения, поскольку с ними связаны описываемые им события. Наконец, переходя к описанию последующих поколений, летописец все реже и реже упоминает о прежних персонажах, так как описывает новые события, персонажи которых вытесняют умерших. Вкратце мысль формулируется так. Каждое поколение рождает новые исторические лица, при смене поколений эти лица сменяются. Несмотря на внешнюю простоту, этот принцип оказался полезен при создании метода датировки. Принцип затухания частот имеет эквивалентную переформулировку. Так как персонажи практически однозначно определяются своими полными именами (имя = персонаж), то будет изучаться резервуар полных имен текста. Термин «полное» будем опускать, постоянно подразумевая его. Рассмотрим группу имен, впервые появившихся в тексте в «главе-поколении» с номером Q. Условно назовем эти имена Q-именами, а соответствующие им персонажи Q-персонажами. Количество упоминаний (с кратностями) всех этих имен в этой «главе» обозначим через K(Q,Q). Подсчитаем затем, сколько раз эти же имена упомянуты в «главе» с номером Т. Получившееся число обозначим через K(Q,T). При этом если одно и то же имя повторяется несколько раз (то есть с кратностью), то все эти упоминания подсчитываются. Построим график, отложив по горизонтали номера «глав», а по вертикали — числа K(Q,T), где номер Q — фиксирован. Для каждого Q получается свой график. Принцип затухания частот тогда формулируется так. При хронологически правильной нумерации «глав-поколений» каждый график K(Q,T) должен иметь следующий вид. Слева от точки О график равен нулю, в точке Q — абсолютный максимум графика, потом график постепенно падает (затухает). Этот график назовем идеальным. Сформулированный принцип должен быть проверен экспериментально. Если он верен и если «главы» в летописи упорядочены хронологически правильно, то все экспериментальные графики должны быть близки к идеальному. Проведенная экспериментальная проверка полностью подтвердила принцип затухания частот. Вот некоторые типичные примеры. Пример 1. «Римская история» Т. Ливия (М., 1887–1889, тт. 1–6). Все графики K(Q,T) для частей «Истории», описывающих периоды 750–500 гг. до н. э. и 510–293 гг. до н. э., оказались практически тождественными с идеальным, то есть подавляющее большинство имен, впервые появившихся в описании Ливия в каком-то поколении, наиболее часто упоминаются Ливием при описании именно этого поколения, а затем постепенно утрачиваются. Следовательно, принцип подтверждается, и порядок «глав-поколений» внутри указанных частей «Истории» Ливия хронологически правилен. Пример 2. Liber Pontificalis, Изд. Т. Моммзена, Gestorum Pontificum Romanorum, 1898. Выделим из этого набора текстов куски, описывающие периоды: 1) 300–560 годы н. э.; 2) 560–900 годы н. э.; 3) 900 — 1250 годы н. э.; 4) 1250–1500 годы н. э. Оказывается, все частотные графики K(Q,T) для текстов 1–4 практически совпадают с идеальным, что подтверждает принцип затухания частот.
Пример 3. В качестве текста X, описывающего период 976 — 1341 гг. н. э. в истории Византии, был взят следующий набор первоисточников: 1. Михаил Пселл. Хронография. М., 1987. Описывает период 976 — 1075 гг. 2. Анна Комнина. Сокращенное сказание о делах царя Алексея Комнина (1081–1118). СПб, 1859. 3. Иоанн Киннам. Краткое обозрение царствования Иоанна и Мануила Комнинов (1118–1180). СПб, 1859. 4. Никита Хониат, т.1. История, начинающаяся с царствования Иоанна Комнина (1118–1185). СПб, 1860. 5. Никита Хониат, т.2. История со времени царствования Иоанна Комнина (1186–1206). СПб, 1862. 6. Георгий Акрополит. Летопись (1203–1261). СПб, 1863. 7. Георгий Пахимер. История о Михаиле и Андронике Палеологах (1255–1282). СПб, 1862. 8. Никифор Григора. Римская история (1204–1341). СПб, 1862. Этот набор текстов содержит несколько десятков тысяч упоминаний полных имен (с кратностями). Оказалось, что все частотные графики K(Q,T) на интервалах 976 — 1200 гг. и 1200–1341 гг. практически тождественны с идеальным. И здесь принцип затухания частот оказался выполненным. А с другой стороны, оказалось, что хронологический порядок текстов внутри каждого из указанных интервалов времени правилен. Пример 4. Ф. Грегоровиус. История города Рима в средние века. СПб, тт. 1–6, 1902–1912. Из этого текста были выделены куски, описывающие: 1) 300–560 гг. н. э.; 2) 560–900 гг. н. э.; 3) 900 — 1250 гг. н. э.; 4) 1250–1500 гг. н. э. Каждый из них был разбит на «главы-поколения», резервуар имен насчитывает несколько десятков тысяч упоминаний. Оказалось, что принцип затухания частот верен и упорядочивание «глав» в каждом из текстов 1–4 хронологически правильно. Аналогичный результат получен и для монографии Кольрауша «История Германии» (М., 1860, тт. 1–2), в которой были выделены куски, описывающие: 1) 600 — 1000 годы н. э.; 2) 1000–1273 годы н. э.; 3) 1273–1700 годы н. э. Всего А.Т. Фоменко было обработано несколько десятков исторических текстов. Во всех случаях принцип затухания частот подтвердился. Отсюда вытекает методика хронологически правильного упорядочивания «глав-поколений» в тексте или в наборе текстов, где этот порядок нарушен или неизвестен. Рассмотрим совокупность «глав-поколений» летописи X и занумеруем их в каком-нибудь порядке. Для каждой «главы» X(Q) подсчитаем число K(Q,T) при заданной нумерации «глав». Все числа K(Q,T), при переменных Q и Т, естественно организуются в квадратную матрицу К(Т) размера n × n, где n — число «глав». В идеальном теоретическом случае частотная матрица К(Т) имеет следующий вид: ниже главной диагонали стоят нули, на главной диагонали расположен абсолютный максимум в каждой строке. Затем каждый график в каждой строке монотонно падает, затухает. Конечно, экспериментальные графики могут не совпадать с теоретическим. Если теперь изменить нумерацию «глав» в летописи, то изменятся и числа K(Q,T), поскольку возникнет довольно сложное перераспределение «впервые появившихся имен». Следовательно, меняется частотная матрица К(Т) и ее элементы. Меняя порядок «глав» летописи с помощью различных перестановок s, и вычисляя каждый раз новую частотную матрицу K(sT), где sT — новая нумерация, соответствующая перестановке s, будем искать такой порядок «глав» летописи, при котором все или почти все графики будут иметь вид, близкий к идеальному. В этом случае экспериментальная частотная матрица K(sT) будет наиболее близка к теоретической матрице. Тот порядок «глав» летописи, при котором отклонение экспериментальной матрицы будет наименьшим, и следует признать хронологически правильным и искомым. Описание «критерия близости» здесь не приводится. Эта методика позволяет также датировать события. Пусть дан какой-то исторический текст Y, о котором известно только, что он описывает какие-то события из эпохи (АВ), уже описанной в тексте X, разбитом на «главы — поколения», причем порядок этих «глав» в X хронологически правилен. Как узнать, какое именно поколение описано в интересующем нас тексте Y? При этом хотелось бы использовать только количественные характеристики текстов, не апеллируя к их смысловому содержанию, которое может быть существенно неоднозначно и допускать разнящиеся трактовки. Ответ таков. Присоединим текст Y к совокупности «глав» текста X, считая при этом Y новой «главой» и приписав ей какой-то номер Q. Затем находим оптимальный, хронологически правильный порядок всех «глав» получившейся «летописи». При этом будет найдено правильное место и для новой «главы» Y. В простейшем случае, построив для нее график K(Q,T), можно добиться, меняя ее положение относительно других «глав», чтобы этот график был как можно ближе к идеальному. То положение, которое Y займет среди других «глав», и следует признать за искомое. Тем самым датируются события, описанные в Y. Методика применима и тогда, когда рассматриваются не все имена, а только одно или несколько имен, например, какие-либо «знаменитые имена». Проверим действие нашей методики на текстах с заранее известной датировкой. Пример 1. Рассмотрим период от 500 до 20 годов до н. э. в истории Греции. В качестве текста X, описывающего этот период, возьмем «Сравнительные жизнеописания» Плутарха (тт. 1–3. М., 1963–1964). Используя описанную методику, убеждаемся, что все «главы-поколения» на интервале 400–200 годы до н. э. расположены в нем правильно. В качестве текста Y возьмем «Пирр» Плутарха. Описываемые в нем события обычно датируются 319–227 годами до н. э. (см. т. 2, с. 502, 503, коммент. 5, 89). Разыскивая для «Пирра» правильное положение среди других «глав», находим, что следует поместить «Пирра» в конец IV — начало III века до н. э. Это хорошо согласуется с известной ранее относительной датировкой. Полученный результат более грубый, так как рассматривались «главы», описывающие целые поколения, а не отдельные годы. Но зато удалось получить относительную датировку для «Пирра», не вникая в его смысловое содержание. Подчеркнем, что здесь говорилось лишь об относительной датировке текста, а не о его абсолютной датировке. Она, как вскоре выяснится, существенно отличается от скалигеровской. И должна быть поднята на несколько сотен лет вверх, ближе к нам. Пример 2. Используя указанные выше византийские тексты, были датированы следующие тексты, описывающие Крестовые походы: Y = Gesta Francorum et aliorum Hierosolymitanorum. — Histoire anonime de la premie're croisade. Ed.L. Bre'hier, Paris, 1924, pp. 194–206 (традиционная относительная датировка 1099 годом н. э. совпала с полученной относительной датировкой: конец XI в. н.э). Y = Robert de Clari. La conquete de Constantinopole. Ed.Ph.Lauer. Paris, 1924 (традиционная относительная дата 1204 год н. э. совпала с нашей: начало XIII века н. э. Таким образом, эффективность методики подтверждается на средневековых текстах с заранее известной датировкой). Особо следует выделить принцип дублирования частот, который является в некотором смысле частным случаем предыдущей методики. Эта методика была проверена на экспериментальном материале. В качестве простого примера было взято издание «Истории Флоренции» Макиавелли 1973 года (Ленинград), снабженное развернутыми комментариями. Ясно, что комментарии можно рассматривать как серию «глав», дублирующих основной текст Макиавелли. Основной текст был разбит на «главы-поколения», что позволило построить квадратную частотную матрицу К(Т), охватывающую и комментарий к «Истории». Эта матрица имеет скопление максимумов вдоль отрезка, параллельного главной диагонали. Это означает, что данная методика успешно обнаруживает известные дубликаты. В данном случае — комментарии к основному тексту «Истории» Макиавелли. 3.6. СТАТИСТИЧЕСКИЙ АНАЛИЗ БИБЛИИБиблия содержит две серии дубликатов. В ней упомянуто около 2000 имен, а число их упоминаний с кратностями — несколько десятков тысяч, что открывает неплохие возможности для статистического исследования. В Библии много раз повторяются одинаковые описания, списки имен, одинаковые религиозные формулы и т. д. Эти повторы давно обнаружены и систематизированы. Статистическое исследование Библии имеет большое значение для анализа скалигеровской хронологии. В Библии содержится несколько десятков тысяч упоминаний имен. Известно, что в Библии есть две серии дубликатов. А именно каждое поколение, описанное в книгах 1 Царств, 2 Царств, 3 Царств, 4 Царств, затем повторно описано в книгах 1 Паралипоменон, 2 Паралипоменон. При исследовании было выполнено разбиение Ветхого и Нового Заветов на отдельные «главы-поколения». В 1974–1979 гг. В.П. Фоменко и Т.Г. Фоменко провели огромную работу по составлению полного списка всех имен Библии с учетом их кратностей и точным распределением имен по «главам-поколениям». Оказалось, что всего упомянуто около 2000 имен, а число их упоминаний с кратностями — несколько десятков тысяч, что открывает неплохие возможности для статистического исследования. Это позволило построить все частотные графики K(Q,T), где номер Т пробегает перечисленные «главы». Оказалось, что графики, построенные для «глав» из книг 1–4 Царств, позволяют сделать следующий вывод. Имена, впервые появившиеся в этих «главах», затем снова «возрождаются» в прежнем количестве в соответствующих «главах» из книг 1–2 Паралипоменон. Итак, новая методика успешно обнаружила и отождествила те дубликаты в Библии, которые и ранее были известны как таковые. Отчетливо видны и новые статистические дубликаты, впервые обнаруженные в описываемом статистическом эксперименте. Применение указанных методик иногда облегчается тем, что для многих исторических текстов комментаторами проведена работа по выявлению повторяющихся фрагментов текста. Под «повтором» можно понимать не только повторение имени, но и повторное описание какого-то события и т. п. Например, в Библии много раз повторяются одинаковые описания, списки имен, одинаковые религиозные формулы и т. д. Все эти повторы в Библии давно обнаружены и систематизированы. Рядом с некоторыми стихами указано, какие стихи Библии в этой же или в других книгах Библии считаются его «повторами», то есть ему «параллельными». Если исследуемый текст X снабжен таким или похожим аппаратом, то можно применить методику обнаружения дубликатов, считая повторяющиеся фрагменты за «повторяющиеся имена». 3.7. ПРИМЕНЕНИЕ АНКЕТ-КОДОВА.Т. Фоменко было введено понятие анкет-кода или формализованной «биографии». Анкет-код иерархически упорядочивает факты «биографии» по мере уменьшения их инвариантности относительно субъективных оценок хронистов. Анкет-код состоит из 34 пунктов, каждый из которых содержит несколько подпунктов. Если анкет-коды двух династий мало отличаются друг от друга, то они изображают одну и ту же реальную династию. Если же два анкет-кода изображают разные династии, то они далеки друг от друга. В традиционной истории распространены штампы и заимствования, использовавшиеся, например, при описании правителей. Считается, что летописцы иногда приписывали правителю качества и деяния каких-то древних царей. Для выявления и изучения таких штампов, а также для обнаружения дубликатов А.Т. Фоменко было введено понятие анкет-кода или формализованной «биографии». Реальный правитель, будучи описан в летописях, приобретает тем самым «историческую литературную биографию», которая может не иметь ничего общего с реальной его биографией, быть полностью легендарной. На основе изучения большого числа исторических биографий была разработана таблица, названная анкет-кодом АК, иерархически упорядочивающая факты «биографии» по мере уменьшения их инвариантности относительно субъективных оценок хронистов. Анкет-код состоит из 34 пунктов, каждый из которых содержит несколько подпунктов: 1. Пол: а) мужской; б) женский. 2. Длительность жизни. 3. Длительность правления. Конец правления практически всегда однозначно фиксирован, начало правления допускает иногда несколько вариантов (см. ниже). Отмечаются как равноправные все варианты. 4. Социальное положение и занимаемый пост: а) царь, император, король; б) полководец; в) политик, общественный деятель; г) ученый, писатель и т. д.; д) религиозный вождь, папа, епископ и т. д. 5. Смерть правителя: а) естественная смерть в мирной обстановке; б) убит на поле боя противниками или смертельно ранен; в) убит в результате заговора, вне войны; г) убит в результате заговора во время войны; д) специальные, экзотические обстоятельства смерти. 6. Стихийные бедствия во время правления: а) голод; б) наводнения; в) повальные болезни; г) землетрясения; д) извержения вулканов. При этом отмечаются также длительность бедствий и год или годы, когда они имели место. 7. Астрономические явления во время правления: а) есть; б) нет; если есть, то какие именно: в) затмения; г) кометы; д) «вспышки звезд». 8. Войны во время правления: а) есть; б) нет. 9. В = число войн. 10. Основные временные характеристики войн В[1 |, В[р]. А именно: а[k] = на каком году правления происходила или началась война В[k]; с[k,х] = временное расстояние от войны В[k] до войны В[х]. 11. «Сила» войны В[k] по летописи, для каждого номера «k»: а) сильная; б) слабая; более точно: сколькими строками описана война в данной летописи. 12. Число противников в войне В[k] и схема их взаимоотношений — союзники, противники, нейтральные силы, посредники и т. д. 13. Локализация войны В[k]: а) около столицы; б) внутри государства; в) вне государства, внешняя война, где именно; г) одновременно внутренняя и внешняя война. 14. Результат войны: а) победа; б) поражение; в) неопределенный исход. 15. Мирные договоры: а) заключение мирного договора при неопределенном исходе; б) заключение мирного договора после поражения. 16. О захвате столицы: а) захвачена; б) не захвачена. 17. Судьба мирного договора: а) нарушен (кем); б) не нарушен во время правления. 18. Обстоятельства захвата, падения столицы. 19. Схема траекторий походов во время войны. 20. Личное участие правителя в войне: а) участвует; б) не участвует. 21) Заговоры против правителя во время его правления: а) есть; б) нет. 22. Географическая локализация заговоров и войн. 23. Название столицы с переводом. 24. Названия государства и народа с переводами. 25. Географическая локализация столицы. 26. Географическая локализация государства. 27. Законодательная деятельность правителя: а) реформы и их характер; б) издание нового свода законов; в) реставрация старых законов и каких именно. 28. Список всех имен правителя с их переводами. 29. Этническая принадлежность правителя, а также членов его семьи, состав семьи. 30. Этническая принадлежность народа, племени, клана. 31. Основание новых городов, столиц и т. п. 32. Религиозная обстановка: а) введение новой религии; б) борьба сект, каких именно; в) религиозные восстания и войны; г) соборы, религиозные собрания. 33. Династическая борьба внутри родственного клана правителя, убийства родственников, противников, претендентов и т. д. 34. Остальные факты «биографии» не будем дифференцировать подробно и условно назовем пункт 34 «остатком». Обозначим эти пункты АК-1, АК-2…, АК-34. Итак, каждую «биографию» можно записать в виде такой таблицы, некоторые номера которой могут быть пустыми, если соответствующая информация не сохранилась. Допустим, что некоторая реальная династия описана в какой-то летописи. Занумеруем правителей и на основе этой летописи составим для каждого из них его анкет-код АК. Получим последовательность анкет-кодов, которую назовем анкет-кодом династии. Поскольку одна и та же реальная династия может описываться в разных летописях, то она может изображаться и разными анкет-кодами. Как узнать, не обращаясь к анализу смыслового содержания летописей, описывают ли они одну и ту же реальную династию или разные? Если в летописях записаны длительности правлений, то можно применить методику распознавания числовых династий. Однако если таких числовых данных не сохранилось, задача усложняется. Итак, как распознать в множестве всех анкет-кодов одну и ту же реальную династию? Для решения этого вопроса была разработана методика, основанная на принципе «малых искажений», который в данном случае кратко формулируется так. Если анкет-коды двух династий мало отличаются друг от друга, то они изображают одну и ту же реальную династию. Если же два анкет-кода изображают разные династии, то они далеки друг от друга. Здесь опускается описание числового коэффициента, аналогичного с(М,Н), позволяющего уверенно отделять зависимые анкет-коды от независимых. Экспериментальная проверка подтвердила верность принципа малых искажений и в этом случае. Оказалось, что анкет-коды, изображающие одну и ту же династию, отличаются друг от друга существенно меньше, чем анкет-коды разных реальных династий. Ясно, что это позволяет датировать анкет-коды династий, следуя схеме, описанной выше. 3.8. МЕТОД ХРОНОЛОГИЧЕСКОГО УПОРЯДОЧИВАНИЯ ГЕОГРАФИЧЕСКИХ КАРТКаждая географическая карта отражает состояние науки о земле в ту эпоху, когда эта карта была составлена. Проведенная А.Т. Фоменко в 1979–1980 гг. экспериментальная проверка позволила сформулировать и подтвердить принцип улучшения карт. Визуально близкие карты оказываются близкими и во времени. Лишь глобус XVII века и более позднего времени довольно хорошо отражает реальность. Известная карта из «Географии» Птолемея, считающаяся сегодня древней и античной, датируется не II, а XV–XVI вв. н. э. Была разработана также методика хронологического упорядочивания древних карт. Каждая географическая карта отражает состояние науки о земле в ту эпоху, когда эта карта была составлена. По мере развития научных представлений карты улучшаются, то есть количество ошибочных сведений в целом уменьшается, а количество правильных сведений увеличивается. На основе изучения конкретных древних карт был разработан оптимальный карт-код, позволяющий представить каждую карту, изображенную графически или описанную словесно, в виде таблицы, аналогичной АК. Список пунктов этой таблицы здесь опущен. Проведенная А.Т. Фоменко в 1979–1980 гг. экспериментальная проверка позволила сформулировать и подтвердить следующий принцип улучшения карт. Если задана хронологически правильно упорядоченная последовательность карт, то при переходе от старых карт к более новым происходят следующие два процесса: а) неправильные признаки, то есть не соответствующие реальной географии, исчезают и больше не появляются на картах. Другими словами, «ошибки не повторяются». б) Появившийся на карте правильный признак — например, наличие пролива, реки или более правильное очертание берега— фиксируется и сохраняется во всех последующих картах. То есть правильные сведения не забываются. Ввиду той роли, которую всегда играли карты в мореплавании и военном деле, принцип улучшения карт отражает насущные потребности практики. Сформулированный выше принцип был проверен по схеме предыдущих пунктов. Фиксируем некоторое упорядочивание карт, затем для каждого номера Q построим частотный график L(Q,T), где число L(Q,Q) равно числу признаков, впервые появившихся на карте с номером Q, а число L(Q,T) показывает, сколько из них осталось на карте с номером Т. Анализ показывает, что визуально близкие карты оказываются близкими и во времени. Каждая историческая эпоха характеризуется, как выясняется, своим уникальным набором карт. Проверка принципа была затруднена тем, что до нашего времени дошло мало древних карт. Тем не менее удалось собрать достаточное число карт, позволившее проверить теоретическую модель. При этом выяснилось, что последовательность средневековых карт начинается в XI–XII веках н. э. совершенно примитивными картами, весьма далекими от действительности. Затем качество карт более или менее монотонно улучшается, пока наконец в XVI веке н. э. не появляются уже достаточно правильные карты и глобусы. В то же время это улучшение качества происходило достаточно медленно. Так, например, географические познания в Европе XVI века н. э. были еще очень далеки от современных. На карте 1522 года, составленной Оккупарио и хранящейся в Государственном историческом музее города Москвы, изображены Европа и Азия в пропорциях, резко отличающихся от современных. А именно Гренландия представлена как полуостров Европы. Скандинавский полуостров вытянут тонкой полоской. Проливы Босфор и Дарданеллы резко расширены и увеличены. Черное море перекошено по вертикали. Каспийское море вытянуто горизонтально и буквально неузнаваемо, и т. п. Единственным районом, отраженным более или менее верно, является средиземноморское побережье, да и то Греция представлена в виде треугольника без Пелопоннеса. Этнографические указания на этой и на других картах того времени еще более далеки от тех, которые зафиксированы на это время скалигеровской историей. Например, Дакия помещена в Скандинавии, Албания — на берегу Каспийского моря, Gottia (готы?) отмечены на Скандинавском полуострове. Китай вообще отсутствует. На севере Сибири видно Judei и т. д. Карта Корнелиуса Николаи 1598 года также грешит аналогичными искажениями, но уже в меньшей степени. И наконец, глобус XVII века, хранящийся в Государственном историческом музее города Москвы, уже довольно хорошо отражает реальность. Описанная выше методика позволяет датировать карты, в том числе и «античные», следуя схеме, описанной в предыдущих пунктах. Полученные результаты весьма неожиданны. Приведем здесь только некоторые примеры. 1. Известная карта из «Географии» Птолемея, издания Баслера 1545 года, считающаяся сегодня древней и античной, попала отнюдь не во II век н. э., а в XV–XVI века н. э., то есть в эпоху публикации книги Птолемея. Это заставляет вспомнить совершенно аналогичную ситуацию с «Альмагестом» Птолемея (см. выше). 2. Не менее известная «античная» карта tabula Pentingeriana попадает не в начало н. э., эпоху Августа, а в XII–XIV века н. э. Расхождение со скалигеровской датировкой — более тысячи лет. 3. Приведем также результаты по серии «античных» карт, являющихся, правда, позднейшими реконструкциями по их словесным описаниям в «античных» текстах. Речь идет о картах Гесиода, якобы VIII века до н. э.; Гекатея, якобы VI–V веков до н. э.; Геродота, якобы V века до н. э.; Демокрита, якобы V–IV веков до н. э.; Эратосфена, якобы 276–194 годов до н. э.; о «глобусе» Кратеса, якобы 168–165 годов до н. э. При их датировке описанным выше методом все эти карты попадают отнюдь не в указанные выше скалигеровские временные интервалы, а в период XIII–XV веков н. э. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||