|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
5.2 READ 5.3 WRIТЕ 5.4 ЗАХВАТ ФАЙЛА И ЗАПИСИ 5.5 УКАЗАНИЕ МЕСТА В ФАЙЛЕ, ГДЕ БУДЕТ ВЫПОЛНЯТЬСЯ ВВОД-ВЫВОД — LSEEК 5.6 CLOSЕ 5.7 СОЗДАНИЕ ФАЙЛА 5.9 СМЕНА ТЕКУЩЕГО И КОРНЕВОГО КАТАЛОГА 5.10 CМЕНА ВЛАДЕЛЬЦА И РЕЖИМА ДОСТУПА К ФАЙЛУ 5.12.5 Примеры 5.14.2 Демонтирование файловой системы 5.16 UNLINК 5.16.1 Целостность файловой системы 5.16.2 Поводы для конкуренции 5.17 АБСТРАКТНЫЕ ОБРАЩЕНИЯ К ФАЙЛОВЫМ СИСТЕМАМ 5.18 СОПРОВОЖДЕНИЕ ФАЙЛОВОЙ СИСТЕМЫ ГЛАВА 5. СИСТЕМНЫЕ ОПЕРАЦИИ ДЛЯ РАБОТЫ С ФАЙЛОВОЙ СИСТЕМОЙВ последней главе рассматривались внутренние структуры данных для файловой системы и алгоритмы работы с ними. В этой главе речь пойдет о системных функциях для работы с файловой системой с использованием понятий, введенных в предыдущей главе. Рассматриваются системные функции, обеспечивающие обращение к существующим файлам, такие как open, read, write, lseek и close, затем функции создания новых файлов, а именно, creat и mknod, и, наконец, функции для работы с индексом или для передвижения по файловой системе: chdir, chroot, chown, stat и fstat. Исследуются более сложные системные функции: pipe и dup имеют важное значение для реализации каналов в shell'е; mount и umount расширяют видимое для пользователя дерево файловых систем; link и unlink изменяют иерархическую структуру файловой системы. Затем дается представление об абстракциях, связанных с файловой системой, в отношении поддержки различных файловых систем, подчиняющихся стандартным интерфейсам. В последнем разделе главы речь пойдет о сопровождении файловой системы. Глава знакомит с тремя структурами данных ядра: таблицей файлов, в которой каждая запись связана с одним из открытых в системе файлов, таблицей пользовательских дескрипторов файлов, в которой каждая запись связана с файловым дескриптором, известным процессу, и таблицей монтирования, в которой содержится информация по каждой активной файловой системе.
Рисунок 5.1. Функции для работы с файловой системой и их связь с другими алгоритмами На Рисунке 5.1 показана взаимосвязь между системными функциями и алгоритмами, описанными ранее. Системные функции классифицируются на несколько категорий, хотя некоторые из функций присутствуют более, чем в одной категории: • Системные функции, возвращающие дескрипторы файлов для использования другими системными функциями; • Системные функции, использующие алгоритм namei для анализа имени пути поиска; • Системные функции, назначающие и освобождающие индекс с использованием алгоритмов ialloc и ifree; • Системные функции, устанавливающие или изменяющие атрибуты файла; • Системные функции, позволяющие процессу производить ввод-вывод данных с использованием алгоритмов alloc, free и алгоритмов выделения буфера; • Системные функции, изменяющие структуру файловой системы; • Системные функции, позволяющие процессу изменять собственное представление о структуре дерева файловой системы. 5.1 OPENВызов системной функции open (открыть файл) — это первый шаг, который должен сделать процесс, чтобы обратиться к данным в файле. Синтаксис вызова функции open: fd = open(pathname, flags, modes); где pathname — имя файла, flags указывает режим открытия (например, для чтения или записи), а modes содержит права доступа к файлу в случае, если файл создается. Системная функция open возвращает целое число[14], именуемое пользовательским дескриптором файла. Другие операции над файлами, такие как чтение, запись, позиционирование головок чтения-записи, воспроизведение дескриптора файла, установка параметров ввода-вывода, определение статуса файла и закрытие файла, используют значение дескриптора файла, возвращаемое системной функцией open. Ядро просматривает файловую систему в поисках файла по его имени, используя алгоритм namei (см. Рисунок 5.2). Оно проверяет права на открытие файла после того, как обнаружит копию индекса файла в памяти, и выделяет открываемому файлу запись в таблице файлов. Запись таблицы файлов содержит указатель на индекс открытого файла и поле, в котором хранится смещение в байтах от начала файла до места, откуда предполагается начинать выполнение последующих операций чтения или записи. Ядро сбрасывает это смещение в 0 во время открытия файла, имея в виду, что исходная операция чтения или записи по умолчанию будет производиться с начала файла. С другой стороны, процесс может открыть файл в режиме записи в конец, в этом случае ядро устанавливает значение смещения, равное размеру файла. Ядро выделяет запись в личной (закрытой) таблице в адресном пространстве задачи, выделенном процессу (таблица эта называется таблицей пользовательских дескрипторов файлов), и запоминает указатель на эту запись. Указателем выступает дескриптор файла, возвращаемый пользователю. Запись в таблице пользовательских файлов указывает на запись в глобальной таблице файлов. алгоритм open входная информация: имя файла режим открытия права доступа (при создании файла) выходная информация: дескриптор файла { превратить имя файла в идентификатор индекса (алгоритм namei); if (файл не существует или к нему не разрешен доступ) return (код ошибки); выделить для индекса запись в таблице файлов, инициализировать счетчик, смещение; выделить запись в таблице пользовательских дескрипторов файла, установить указатель на запись в таблице файлов; if (режим открытия подразумевает усечение файла) освободить все блоки файла (алгоритм free); снять блокировку (с индекса); /* индекс заблокирован выше, в алгоритме namei */ return (пользовательский дескриптор файла); } Рисунок 5.2. Алгоритм открытия файла Предположим, что процесс, открывая файл «/etc/passwd» дважды, один раз только для чтения и один раз только для записи, и однажды файл «local» для чтения и для записи[15], выполняет следующий набор операторов: fd1 = open("/etc/passwd", O_RDONLY); fd2 = open("local", O_RDWR); fd3 = open("/etc/passwd", O_WRONLY); На Рисунке 5.3 показана взаимосвязь между таблицей индексов, таблицей файлов и таблицей пользовательских дескрипторов файла. Каждый вызов функции open возвращает процессу дескриптор файла, а соответствующая запись в таблице пользовательских дескрипторов файла указывает на уникальную запись в таблице файлов ядра, пусть даже один и тот же файл ("/etc/passwd") открывается дважды. Записи в таблице файлов для всех экземпляров одного и того же открытого файла указывают на одну запись в таблице индексов, хранящихся в памяти. Процесс может обращаться к файлу «/etc/passwd» с чтением или записью, но только через дескрипторы файла, имеющие значения 3 и 5 (см. Рисунок). Ядро запоминает разрешение на чтение или запись в файл в строке таблицы файлов, выделенной во время выполнения функции open. Предположим, что второй процесс выполняет следующий набор операторов: fd1 = open("/etc/passwd", O_RDONLY); fd2 = open("private", O_RDONLY); 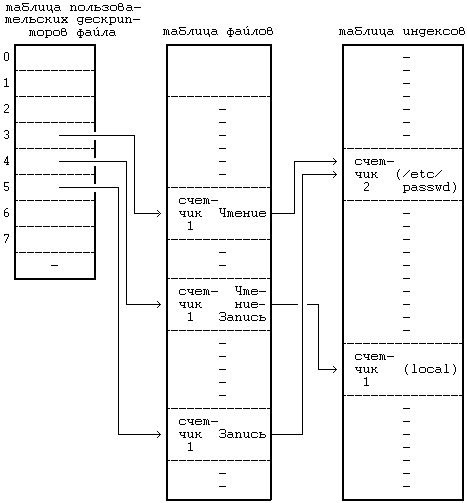 Рисунок 5.3. Структуры данных после открытия На Рисунке 5.4 показана взаимосвязь между соответствующими структурами данных, когда оба процесса (и больше никто) имеют открытые файлы. Снова результатом каждого вызова функции open является выделение уникальной точки входа в таблице пользовательских дескрипторов файла и в таблице файлов ядра, и ядро хранит не более одной записи на каждый файл в таблице индексов, размещенных в памяти. Запись в таблице пользовательских дескрипторов файла по умолчанию хранит смещение в файле до адреса следующей операции ввода-вывода и указывает непосредственно на точку входа в таблице индексов для файла, устраняя необходимость в отдельной таблице файлов ядра. Вышеприведенные примеры показывают взаимосвязь между записями таблицы пользовательских дескрипторов файла и записями в таблице файлов ядра типа «один к одному». Томпсон, однако, отмечает, что им была реализована таблица файлов как отдельная структура, позволяющая совместно использовать один и тот же указатель смещения нескольким пользовательским дескрипторам файла (см. [Thompson 78], стр.1943). В системных функциях dup и fork, рассматриваемых в разделах 5.13 и 7.1, при работе со структурами данных допускается такое совместное использование. 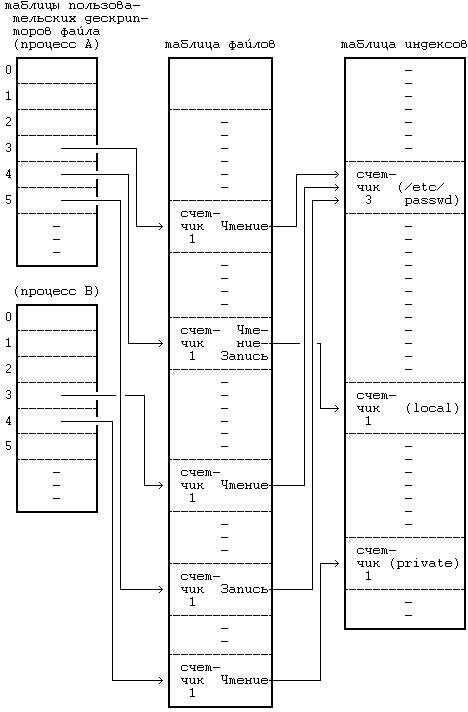 Рисунок 5.4. Структуры данных после того, как два процесса произвели открытие файлов Первые три пользовательских дескриптора (0, 1 и 2) именуются дескрипторами файлов: стандартного ввода, стандартного вывода и стандартного файла ошибок. Процессы в системе UNIX по договоренности используют дескриптор файла стандартного ввода при чтении вводимой информации, дескриптор файла стандартного вывода при записи выводимой информации и дескриптор стандартного файла ошибок для записи сообщений об ошибках. В операционной системе нет никакого указания на то, что эти дескрипторы файлов являются специальными. Группа пользователей может условиться о том, что файловые дескрипторы, имеющие значения 4, 6 и 11, являются специальными, но более естественно начинать отсчет с 0 (как в языке Си). Принятие соглашения сразу всеми пользовательскими программами облегчит связь между ними при использовании каналов, в чем мы убедимся в дальнейшем, изучая главу 7. Обычно операторский терминал (см. главу 10) служит и в качестве стандартного ввода, и в качестве стандартного вывода и в качестве стандартного устройства вывода сообщений об ошибках. 5.2 READ Синтаксис вызова системной функции read (читать): number = read(fd, buffer, count) где fd — дескриптор файла, возвращаемый функцией open, buffer — адрес структуры данных в пользовательском процессе, где будут размещаться считанные данные в случае успешного завершения выполнения функции read, count — количество байт, которые пользователю нужно прочитать, number — количество фактически прочитанных байт. На Рисунке 5.5 приведен алгоритм read, выполняющий чтение обычного файла. Ядро обращается в таблице файлов к записи, которая соответствует значению пользовательского дескриптора файла, следуя за указателем (см. Рисунок 5.3). Затем оно устанавливает значения нескольких параметров ввода-вывода в адресном пространстве процесса (Рисунок 5.6), тем самым устраняя необходимость в их передаче в качестве параметров функции. В частности, ядро указывает в качестве режима ввода-вывода «чтение», устанавливает флаг, свидетельствующий о том, что ввод-вывод направляется в адресное пространство пользователя, значение поля счетчика байтов приравнивает количеству байт, которые будут прочитаны, устанавливает адрес пользовательского буфера данных и, наконец, значение смещения (из таблицы файлов), равное смещению в байтах внутри файла до места, откуда начинается ввод-вывод. После того, как ядро установит значения параметров ввода-вывода в адресном пространстве процесса, оно обращается к индексу, используя указатель из таблицы файлов, и блокирует его прежде, чем начать чтение из файла. алгоритм read входная информация: пользовательский дескриптор файла адрес буфера в пользовательском процессе количество байт, которые нужно прочитать выходная информация: количество байт, скопированных в пользовательское пространство { обратиться к записи в таблице файлов по значению пользовательского дескриптора файла; проверить доступность файла; установить параметры в адресном пространстве процесса, указав адрес пользователя, счетчик байтов, параметры ввода-вывода для пользователя; получить индекс по записи в таблице файлов; заблокировать индекс; установить значение смещения в байтах для адресного пространства процесса по значению смещения в таблице файлов; do (пока значение счетчика байтов не станет удовлетворительным) { превратить смещение в файле в номер дискового блока (алгоритм bmap); вычислить смещение внутри блока и количество байт, которые будут прочитаны; if (количество байт для чтения == 0) /* попытка чтения конца файла */ break; /* выход из цикла */ прочитать блок (алгоритм breada, если производится чтение с продвижением, и алгоритм bread — в противном случае); скопировать данные из системного буфера по адресу пользователя; скорректировать значения полей в адресном пространстве процесса, указывающие смещение в байтах внутри файла, количество прочитанных байт и адрес для передачи в пространство пользователя; освободить буфер; /* заблокированный в алгоритме bread */ } разблокировать индекс; скорректировать значение смещения в таблице файлов для следующей операции чтения; return (общее число прочитанных байт); } Рисунок 5.5. Алгоритм чтения из файла mode чтение или запись count количество байт для чтения или записи offset смещение в байтах внутри файла address адрес места, куда будут копироваться данные, в памяти пользователя или ядра flag отношение адреса к памяти пользователя или к памяти ядра Рисунок 5.6. Параметры ввода-вывода, хранящиеся в пространстве процесса Затем в алгоритме начинается цикл, выполняющийся до тех пор, пока операция чтения не будет произведена до конца. Ядро преобразует смещение в байтах внутри файла в номер блока, используя алгоритм bmap, и вычисляет смещение внутри блока до места, откуда следует начать ввод-вывод, а также количество байт, которые будут прочитаны из блока. После считывания блока в буфер, возможно, с продвижением (алгоритмы bread и breada) ядро копирует данные из блока по назначенному адресу в пользовательском процессе. Оно корректирует параметры ввода-вывода в адресном пространстве процесса в соответствии с количеством прочитанных байт, увеличивая значение смещения в байтах внутри файла и адрес места в пользовательском процессе, куда будет доставлена следующая порция данных, и уменьшая число байт, которые необходимо прочитать, чтобы выполнить запрос пользователя. Если запрос пользователя не удовлетворен, ядро повторяет весь цикл, преобразуя смещение в байтах внутри файла в номер блока, считывая блок с диска в системный буфер, копируя данные из буфера в пользовательский процесс, освобождая буфер и корректируя значения параметров ввода-вывода в адресном пространстве процесса. Цикл завершается, либо когда ядро выполнит запрос пользователя полностью, либо когда в файле больше не будет данных, либо если ядро обнаружит ошибку при чтении данных с диска или при копировании данных в пространство пользователя. Ядро корректирует значение смещения в таблице файлов в соответствии с количеством фактически прочитанных байт; поэтому успешное выполнение операций чтения выглядит как последовательное считывание данных из файла. Системная операция lseek (раздел 5.6) устанавливает значение смещения в таблице файлов и изменяет порядок, в котором процесс читает или записывает данные в файле. #include ‹fcntl.h› main() { int fd; char lilbuf[20], bigbuf[1024]; fd = open("/etc/passwd", O_RDONLY); read(fd, lilbuf, 20); read(fd, bigbuf, 1024); read(fd, lilbuf, 20); } Рисунок 5.7. Пример программы чтения из файла Рассмотрим программу, приведенную на Рисунке 5.7. Функция open возвращает дескриптор файла, который пользователь засылает в переменную fd и использует в последующих вызовах функции read. Выполняя функцию read, ядро проверяет, правильно ли задан параметр «дескриптор файла», а также был ли файл предварительно открыт процессом для чтения. Оно сохраняет значение адреса пользовательского буфера, количество считываемых байт и начальное смещение в байтах внутри файла (соответственно: lilbuf, 20 и 0), в пространстве процесса. В результате вычислений оказывается, что нулевое значение смещения соответствует нулевому блоку файла, и ядро возвращает точку входа в индекс, соответствующую нулевому блоку. Предполагая, что такой блок существует, ядро считывает полный блок размером 1024 байта в буфер, но по адресу lilbuf копирует только 20 байт. Оно увеличивает смещение внутри пространства процесса на 20 байт и сбрасывает счетчик данных в 0. Поскольку операция read выполнилась, ядро переустанавливает значение смещения в таблице файлов на 20, так что последующие операции чтения из файла с данным дескриптором начнутся с места, расположенного со смещением 20 байт от начала файла, а системная функция возвращает число байт, фактически прочитанных, т. е. 20. При повторном вызове функции read ядро вновь проверяет корректность указания дескриптора и наличие соответствующего файла, открытого процессом для чтения, поскольку оно никак не может узнать, что запрос пользователя на чтение касается того же самого файла, существование которого было установлено во время последнего вызова функции. Ядро сохраняет в пространстве процесса пользовательский адрес bigbuf, количество байт, которые нужно прочитать процессу (1024), и начальное смещение в файле (20), взятое из таблицы файлов. Ядро преобразует смещение внутри файла в номер дискового блока, как раньше, и считывает блок. Если между вызовами функции read прошло непродолжительное время, есть шансы, что блок находится в буферном кеше. Однако, ядро не может полностью удовлетворить запрос пользователя на чтение за счет содержимого буфера, поскольку только 1004 байта из 1024 для данного запроса находятся в буфере. Поэтому оно копирует оставшиеся 1004 байта из буфера в пользовательскую структуру данных bigbuf и корректирует параметры в пространстве процесса таким образом, чтобы следующий шаг цикла чтения начинался в файле с байта 1024, при этом данные следует копировать по адресу байта 1004 в bigbuf в объеме 20 байт, чтобы удовлетворить запрос на чтение. Теперь ядро переходит к началу цикла, содержащегося в алгоритме read. Оно преобразует смещение в байтах (1024) в номер логического блока (1), обращается ко второму блоку прямой адресации, номер которого хранится в индексе, и отыскивает точный дисковый блок, из которого будет производиться чтение. Ядро считывает блок из буферного кеша или с диска, если в кеше данный блок отсутствует. Наконец, оно копирует 20 байт из буфера по уточненному адресу в пользовательский процесс. Прежде чем выйти из системной функции, ядро устанавливает значение поля смещения в таблице файлов равным 1044, то есть равным значению смещения в байтах до места, куда будет производиться следующее обращение. В последнем вызове функции read из примера ядро ведет себя, как и в первом обращении к функции, за исключением того, что чтение из файла в данном случае начинается с байта 1044, так как именно это значение будет обнаружено в поле смещения той записи таблицы файлов, которая соответствует указанному дескриптору. Пример показывает, насколько выгодно для запросов ввода-вывода работать с данными, начинающимися на границах блоков файловой системы и имеющими размер, кратный размеру блока. Это позволяет ядру избегать дополнительных итераций при выполнении цикла в алгоритме read и всех вытекающих последствий, связанных с дополнительными обращениями к индексу в поисках номера блока, который содержит данные, и с конкуренцией за использование буферного пула. Библиотека стандартных модулей ввода-вывода создана таким образом, чтобы скрыть от пользователей размеры буферов ядра; ее использование позволяет избежать потерь производительности, присущих процессам, работающим с небольшими порциями данных, из-за чего их функционирование на уровне файловой системы неэффективно (см. упражнение 5.4). Выполняя цикл чтения, ядро определяет, является ли файл объектом чтения с продвижением: если процесс считывает последовательно два блока, ядро предполагает, что все очередные операции будут производить последовательное чтение, до тех пор, пока не будет утверждено обратное. На каждом шаге цикла ядро запоминает номер следующего логического блока в копии индекса, хранящейся в памяти, и на следующем шаге сравнивает номер текущего логического блока со значением, запомненным ранее. Если эти номера равны, ядро вычисляет номер физического блока для чтения с продвижением и сохраняет это значение в пространстве процесса для использования в алгоритме breada. Конечно же, пока процесс не считал конец блока, ядро не запустит алгоритм чтения с продвижением для следующего блока. Обратившись к Рисунку 4.9, вспомним, что номера некоторых блоков в индексе или в блоках косвенной адресации могут иметь нулевое значение, пусть даже номера последующих блоков и ненулевые. Если процесс попытается прочитать данные из такого блока, ядро выполнит запрос, выделяя произвольный буфер в цикле read, очищая его содержимое и копируя данные из него по адресу пользователя. Этот случай не имеет ничего общего с тем случаем, когда процесс обнаруживает конец файла, говорящий о том, что после этого места запись информации никогда не производилась. Обнаружив конец файла, ядро не возвращает процессу никакой информации (см. упражнение 5.1). Когда процесс вызывает системную функцию read, ядро блокирует индекс на время выполнения вызова. Впоследствии, этот процесс может приостановиться во время чтения из буфера, ассоциированного с данными или с блоками косвенной адресации в индексе. Если еще одному процессу дать возможность вносить изменения в файл в то время, когда первый процесс приостановлен, функция read может возвратить несогласованные данные. Например, процесс может считать из файла несколько блоков; если он приостановился во время чтения первого блока, а второй процесс собирался вести запись в другие блоки, возвращаемые данные будут содержать старые данные вперемешку с новыми. Таким образом, индекс остается заблокированным на все время выполнения вызова функции read для того, чтобы процессы могли иметь целостное видение файла, то есть видение того образа, который был у файла перед вызовом функции. Ядро может выгружать процесс, ведущий чтение, в режим задачи на время между двумя вызовами функций и планировать запуск других процессов. Так как по окончании выполнения системной функции с индекса снимается блокировка, ничто не мешает другим процессам обращаться к файлу и изменять его содержимое. Со стороны системы было бы несправедливо держать индекс заблокированным все время от момента, когда процесс открыл файл, и до того момента, когда файл будет закрыт этим процессом, поскольку тогда один процесс будет держать все время файл открытым, тем самым не давая другим процессам возможности обратиться к файлу. Если файл имеет имя «/etc/ passwd», то есть является файлом, используемым в процессе регистрации для проверки пользовательского пароля, один пользователь может умышленно (или, возможно, неумышленно) воспрепятствовать регистрации в системе всех остальных пользователей. Чтобы предотвратить возникновение подобных проблем, ядро снимает с индекса блокировку по окончании выполнения каждого вызова системной функции, использующей индекс. Если второй процесс внесет изменения в файл между двумя вызовами функции read, производимыми первым процессом, первый процесс может прочитать непредвиденные данные, однако структуры данных ядра сохранят свою согласованность. Предположим, к примеру, что ядро выполняет два процесса, конкурирующие между собой (Рисунок 5.8). Если допустить, что оба процесса выполняют операцию open до того, как любой из них вызывает системную функцию read или write, ядро может выполнять функции чтения и записи в любой из шести последовательностей: чтение1, чтение2, запись1, запись2, или чтение1, запись1, чтение2, запись2, или чтение1, запись1, запись2, чтение2 и т. д. Состав информации, считываемой процессом A, зависит от последовательности, в которой система выполняет функции, вызываемые двумя процессами; система не гарантирует, что данные в файле останутся такими же, какими они были после открытия файла. Использование возможности захвата файла и записей (раздел 5.4) позволяет процессу гарантировать сохранение целостности файла после его открытия. #include ‹fcntl.h› /* процесс A */ main() { int fd; char buf[512]; fd = open("/etc/passwd", O_RDONLY); read(fd, buf, sizeof(buf)); /* чтение1 */ read(fd, buf, sizeof(buf)); /* чтение2 */ } /* процесс B */ main() { int fd, i; char buf[512]; for (i = 0; i ‹ sizeof(buf); i++) buf[i] = 'a'; fd = open("/etc/passwd", O_WRONLY); write(fd, buf, sizeof(buf)); /* запись1 */ write(fd, buf, sizeof(buf)); /* запись2 */ } Рисунок 5.8. Процессы, ведущие чтение и запись файла Наконец, программа на Рисунке 5.9 показывает, как процесс может открывать файл более одного раза и читать из него, используя разные файловые дескрипторы. Ядро работает со значениями смещений в таблице файлов, ассоциированными с двумя файловыми дескрипторами, независимо, и поэтому массивы buf1 и buf2 будут по завершении выполнения процесса идентичны друг другу при условии, что ни один процесс в это время не производил запись в файл «/etc/passwd». #include ‹fcntl.h› main() { int fd1, fd2; char buf1[512], buf2[512]; fd1 = open("/etc/passwd", O_RDONLY); fd2 = open("/etc/passwd", O_RDONLY); read(fd1, buf1, sizeof(buf1)); read(fd2, buf2, sizeof(buf2)); } Рисунок 5.9. Чтение из файла с использованием двух дескрипторов 5.3 WRIТЕ Синтаксис вызова системной функции write (писать): number = write(fd, buffer, count); где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако, если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, используя алгоритм alloc, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индекса. Если смещение в байтах совпадает со смещением для блока косвенной адресации, ядру, возможно, придется выделить несколько блоков для использования их в качестве блоков косвенной адресации и информационных блоков. Индекс блокируется на все время выполнения функции write, так как ядро может изменить индекс, выделяя новые блоки; разрешение другим процессам обращаться к файлу может разрушить индекс, если несколько процессов выделяют блоки одновременно, используя одни и те же значения смещений. Когда запись завершается, ядро корректирует размер файла в индексе, если файл увеличился в размере. Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации. Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части. Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись (раздел 3.4) данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (раздел 5.12). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге «/tmp» и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы. 5.4 ЗАХВАТ ФАЙЛА И ЗАПИСИ В первой версии системы UNIX, разработанной Томпсоном и Ричи, отсутствовал внутренний механизм, с помощью которого процессу мог бы быть обеспечен исключительный доступ к файлу. Механизм захвата был признан излишним, поскольку, как отмечает Ричи, «мы не имеем дела с большими базами данных, состоящими из одного файла, которые поддерживаются независимыми процессами» (см. [Ritchie 81]). Для того, чтобы повысить привлекательность системы UNIX для коммерческих пользователей, работающих с базами данных, в версию V системы ныне включены механизмы захвата файла и записи. Захват файла — это средство, позволяющее запретить другим процессам производить чтение или запись любой части файла, а захват записи — это средство, позволяющее запретить другим процессам производить ввод-вывод указанных записей (частей файла между указанными смещениями). В упражнении 5.9 рассматривается реализация механизма захвата файла и записи. 5.5 УКАЗАНИЕ МЕСТА В ФАЙЛЕ, ГДЕ БУДЕТ ВЫПОЛНЯТЬСЯ ВВОД-ВЫВОД — LSEEК Обычное использование системных функций read и write обеспечивает последовательный доступ к файлу, однако процессы могут использовать вызов системной функции lseek для указания места в файле, где будет производиться ввод-вывод, и осуществления произвольного доступа к файлу. Синтаксис вызова системной функции: position = lseek(fd, offset, reference); где fd — дескриптор файла, идентифицирующий файл, offset — смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи. Например, в программе, приведенной на Рисунке 5.10, процесс открывает файл, считывает байт, а затем вызывает функцию lseek, чтобы заменить значение поля смещения в таблице файлов величиной, равной 1023 (с переменной reference, имеющей значение 1), и выполняет цикл. Таким образом, программа считывает каждый 1024-й байт файла. Если reference имеет значение 0, ядро осуществляет поиск от начала файла, а если 2, ядро ведет поиск от конца файла. Функция lseek ничего не должна делать, кроме операции поиска, которая позиционирует головку чтения-записи на указанный дисковый сектор. Для того, чтобы выполнить функцию lseek, ядро просто выбирает значение смещения из таблицы файлов; в последующих вызовах функций read и write смещение из таблицы файлов используется в качестве начального смещения. #include ‹fcntl.h› main(argc, argv) int argc; char *argv[]; { int fd, skval; char c; if (argc != 2) exit(); fd = open(argv[1], O_RDONLY); if (fd == -1) exit(); while ((skval = read(fd, &c,1 )) == 1) { printf("char %c\n", c); skval = lseek(fd, 1023L, 1); printf("new seek val %d\n", skval); } } Рисунок 5.10. Программа, содержащая вызов системной функции lseek 5.6 CLOSЕ Процесс закрывает открытый файл, когда процессу больше не нужно обращаться к нему. Синтаксис вызова системной функции close (закрыть): close(fd); где fd — дескриптор открытого файла. Ядро выполняет операцию закрытия, используя дескриптор файла и информацию из соответствующих записей в таблице файлов и таблице индексов. Если счетчик ссылок в записи таблицы файлов имеет значение, большее, чем 1, в связи с тем, что были обращения к функциям dup или fork, то это означает, что на запись в таблице файлов делают ссылку другие пользовательские дескрипторы, что мы увидим далее; ядро уменьшает значение счетчика и операция закрытия завершается. Если счетчик ссылок в таблице файлов имеет значение, равное 1, ядро освобождает запись в таблице и индекс в памяти, ранее выделенный системной функцией open (алгоритм iput). Если другие процессы все еще ссылаются на индекс, ядро уменьшает значение счетчика ссылок на индекс, но оставляет индекс процессам; в противном случае индекс освобождается для переназначения, так как его счетчик ссылок содержит 0. Когда выполнение системной функции close завершается, запись в таблице пользовательских дескрипторов файла становится пустой. Попытки процесса использовать данный дескриптор заканчиваются ошибкой до тех пор, пока дескриптор не будет переназначен другому файлу в результате выполнения другой системной функции. Когда процесс завершается, ядро проверяет наличие активных пользовательских дескрипторов файла, принадлежавших процессу, и закрывает каждый из них. Таким образом, ни один процесс не может оставить файл открытым после своего завершения. На Рисунке 5.11, например, показаны записи из таблиц, приведенных на Рисунке 5.4, после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы «/etc/passwd» и «private» в индексах также уменьшились. Индекс для файла «private» находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу «private», пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в разделе 4.1.2. 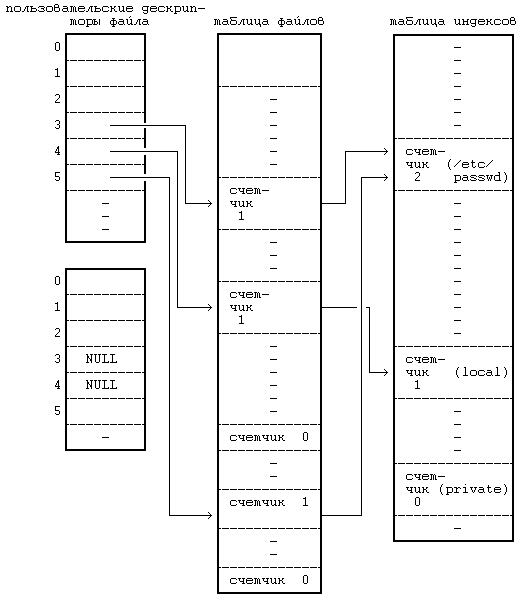 Рисунок 5.11. Таблицы после закрытия файла 5.7 СОЗДАНИЕ ФАЙЛА Системная функция open дает процессу доступ к существующему файлу, а системная функция creat создает в системе новый файл. Синтаксис вызова системной функции creat: fd = creat(pathname, modes); где переменные pathname, modes и fd имеют тот же смысл, что и в системной функции open. Если прежде такого файла не существовало, ядро создает новый файл с указанным именем и указанными правами доступа к нему; если же такой файл уже существовал, ядро усекает файл (освобождает все существующие блоки данных и устанавливает размер файла равным 0) при наличии соответствующих прав доступа к нему[16]. На Рисунке 5.12 приведен алгоритм создания файла. алгоритм creat входная информация: имя файла установки прав доступа к файлу выходная информация: дескриптор файла { получить индекс для данного имени файла (алгоритм namei); if (файл уже существует) { if (доступ не разрешен) { освободить индекс (алгоритм iput); return (ошибку); } } else { /* файл еще не существует */ назначить свободный индекс из файловой системы (алгоритм ialloc); создать новую точку входа в родительском каталоге; включить имя нового файла и номер вновь назначенного индекса; } выделить для индекса запись в таблице файлов, инициализировать счетчик; if (файл существовал к моменту создания) освободить все блоки файла (алгоритм free); снять блокировку (с индекса); return (пользовательский дескриптор файла); } Рисунок 5.12. Алгоритм создания файла Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге. Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (раздел 4.6). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. в разделе 5.16.1). Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать «новый» файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога. Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.) 5.8 СОЗДАНИЕ СПЕЦИАЛЬНЫХ ФАЙЛОВСистемная функция mknod создает в системе специальные файлы, в число которых включаются поименованные каналы, файлы устройств и каталоги. Она похожа на функцию creat в том, что ядро выделяет для файла индекс. Синтаксис вызова системной функции mknod: mknod(pathname, type and permissions, dev) где pathname — имя создаваемой вершины в иерархической структуре файловой системы, type and permissions — тип вершины (например, каталог) и права доступа к создаваемому файлу, а dev указывает старший и младший номера устройства для блочных и символьных специальных файлов (глава 10). На Рисунке 5.13 приведен алгоритм, реализуемый функцией mknod при создании новой вершины. алгоритм создания новой вершины входная информация: вершина (имя файла) тип файла права доступа старший, младший номера устройства (для блочных и символьных специальных файлов) выходная информация: отсутствует { if (новая вершина не является поименованным каналом и пользователь не является суперпользователем) return (ошибку); получить индекс вершины, являющейся родительской для новой вершины (алгоритм namei); if (новая вершина уже существует) { освободить родительский индекс (алгоритм iput); return (ошибку); } назначить для новой вершины свободный индекс из файловой системы (алгоритм ialloc); создать новую запись в родительском каталоге; включить имя новой вершины и номер вновь назначенного индекса; освободить индекс родительского каталога (алгоритм iput); if (новая вершина является блочным или символьным специальным файлом) записать старший и младший номера в структуру индекса; освободить индекс новой вершины (алгоритм iput); } Рисунок 5.13. Алгоритм создания новой вершины Ядро просматривает файловую систему в поисках имени файла, который оно собирается создать. Если файл еще пока не существует, ядро назначает ему новый индекс на диске и записывает имя нового файла и номер индекса в родительский каталог. Оно устанавливает значение поля типа файла в индексе, указывая, что файл является каналом, каталогом или специальным файлом. Наконец, если файл является специальным файлом устройства блочного или символьного типа, ядро записывает в индекс старший и младший номера устройства. Если функция mknod создает каталог, он будет существовать по завершении выполнения функции, но его содержимое будет иметь неверный формат (в каталоге будут отсутствовать записи с именами «.» и «..»). В упражнении 5.33 рассматриваются шаги, необходимые для преобразования содержимого каталога в правильный формат. 5.9 СМЕНА ТЕКУЩЕГО И КОРНЕВОГО КАТАЛОГА Когда система загружается впервые, нулевой процесс делает корневой каталог файловой системы текущим на время инициализации. Для индекса корневого каталога нулевой процесс выполняет алгоритм iget, сохраняет этот индекс в пространстве процесса в качестве индекса текущего каталога и снимает с индекса блокировку. Когда с помощью функции fork создается новый процесс, он наследует текущий каталог старого процесса в своем адресном пространстве, а ядро, соответственно, увеличивает значение счетчика ссылок в индексе. алгоритм смены каталога входная информация: имя нового каталога выходная информация: отсутствует { получить индекс для каталога с новым именем (алгоритм namei); if (индекс не является индексом каталога или же процессу не разрешен доступ к файлу) { освободить индекс (алгоритм iput); return (ошибку); } снять блокировку с индекса; освободить индекс прежнего текущего каталога (алгоритм iput); поместить новый индекс в позицию для текущего каталога в пространстве процесса; } Рисунок 5.14. Алгоритм смены текущего каталога Алгоритм chdir (Рисунок 5.14) изменяет имя текущего каталога для процесса. Синтаксис вызова системной функции chdir: chdir(pathname); где pathname — каталог, который становится текущим для процесса. Ядро анализирует имя каталога, используя алгоритм namei, и проверяет, является ли данный файл каталогом и имеет ли владелец процесса право доступа к каталога. Ядро снимает с нового индекса блокировку, но удерживает индекс в качестве выделенного и оставляет счетчик ссылок без изменений, освобождает индекс прежнего текущего каталога (алгоритм iput), хранящийся в пространстве процесса, и запоминает в этом пространстве новый индекс. После смены процессом текущего каталога алгоритм namei использует индекс в качестве начального каталога при анализе всех имен путей, которые не берут начало от корня. По окончании выполнения системной функции chdir счетчик ссылок на индекс нового каталога имеет значение, как минимум, 1, а счетчик ссылок на индекс прежнего текущего каталога может стать равным 0. В этом отношении функция chdir похожа на функцию open, поскольку обе функции обращаются к файлу и оставляют его индекс в качестве выделенного. Индекс, выделенный во время выполнения функции chdir, освобождается только тогда, когда процесс меняет текущий каталог еще раз или когда процесс завершается. Процессы обычно используют глобальный корневой каталог файловой системы для всех имен путей поиска, начинающихся с «/». Ядро хранит глобальную переменную, которая указывает на индекс глобального корня, выделяемый по алгоритму iget при загрузке системы. Процессы могут менять свое представление о корневом каталоге файловой системы с помощью системной функции chroot. Это бывает полезно, если пользователю нужно создать модель обычной иерархической структуры файловой системы и запустить процессы там. Синтаксис вызова функции: chroot(pathname); где pathname — каталог, который впоследствии будет рассматриваться ядром в качестве корневого каталога для процесса. Выполняя функцию chroot, ядро следует тому же алгоритму, что и при смене текущего каталога. Оно запоминает индекс нового корня в пространстве процесса, снимая с индекса блокировку по завершении выполнения функции. Тем не менее, так как умолчание на корень для ядра хранится в глобальной переменной, ядро освобождает индекс прежнего корня не автоматически, а только после того, как оно само или процесс-предок исполнят вызов функции chroot. Новый индекс становится логическим корнем файловой системы для процесса (и для всех порожденных им процессов) и это означает, что все пути поиска в алгоритме namei, начинающиеся с корня («/»), возьмут начало с данного индекса и что все попытки войти в каталог «..» над корнем приведут к тому, что рабочим каталогом процесса останется новый корень. Процесс передает всем вновь порождаемым процессам этот каталог в качестве корневого подобно тому, как передает свой текущий каталог. 5.10 CМЕНА ВЛАДЕЛЬЦА И РЕЖИМА ДОСТУПА К ФАЙЛУ Смена владельца или режима (прав) доступа к файлу является операцией, производимой над индексом, а не над файлом. Синтаксис вызова соответствующих системных функций: chown(pathname, owner, group) chmod(pathname, mode) Для того, чтобы поменять владельца файла, ядро преобразует имя файла в идентификатор индекса, используя алгоритм namei. Владелец процесса должен быть суперпользователем или владельцем файла (процесс не может распоряжаться тем, что не принадлежит ему). Затем ядро назначает файлу нового владельца и нового группового пользователя, сбрасывает флаги прежних установок (см. раздел 7.5) и освобождает индекс по алгоритму iput. После этого прежний владелец теряет право «собственности» на файл. Для того, чтобы поменять режим доступа к файлу, ядро выполняет процедуру, подобную описанной, вместо кода владельца меняя флаги, устанавливающие режим доступа. 5.11 STAT И FSTАТСистемные функции stat и fstat позволяют процессам запрашивать информацию о статусе файла: типе файла, владельце файла, правах доступа, размере файла, числе связей, номере индекса и времени доступа к файлу. Синтаксис вызова функций: stat(pathname, statbuffer); fstat(fd, statbuffer); где pathname — имя файла, fd — дескриптор файла, возвращаемый функцией open, statbuffer — адрес структуры данных пользовательского процесса, где будет храниться информация о статусе файла после завершения выполнения вызова. Системные функции просто переписывают поля из индекса в структуру statbuffer. Программа на Рисунке 5.33 иллюстрирует использование функций stat и fstat. 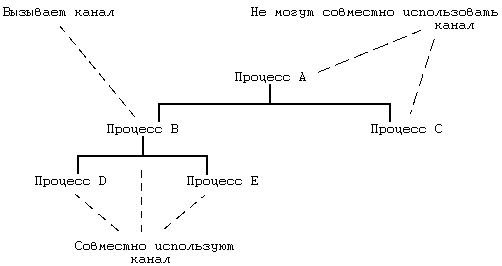 Рисунок 5.15. Дерево процессов и совместное использование каналов 5.12 КАНАЛЫКаналы позволяют передавать данные между процессами в порядке поступления («первым пришел — первым вышел»), а также синхронизировать выполнение процессов. Их использование дает процессам возможность взаимодействовать между собой, пусть даже не известно, какие процессы находятся на другом конце канала. Традиционная реализация каналов использует файловую систему для хранения данных. Различают два вида каналов: поименованные каналы и, за отсутствием лучшего термина, непоименованные каналы, которые идентичны между собой во всем, кроме способа первоначального обращения к ним процессов. Для поименованных каналов процессы используют системную функцию open, а системную функцию pipe — для создания непоименованного канала. Впоследствии, при работе с каналами процессы пользуются обычными системными функциями для файлов, такими как read, write и close. Только связанные между собой процессы, являющиеся потомками того процесса, который вызвал функцию pipe, могут разделять доступ к непоименованным каналам. Например (см. Рисунок 5.15), если процесс B создает канал и порождает процессы D и E, эти три процесса разделяют между собой доступ к каналу, в отличие от процессов A и C. Однако, все процессы могут обращаться к поименованному каналу независимо от взаимоотношений между ними, при условии наличия обычных прав доступа к файлу. Поскольку непоименованные каналы встречаются чаще, они будут рассмотрены первыми. 5.12.1 Системная функция pipеСинтаксис вызова функции создания канала: pipe(fdptr); где fdptr — указатель на массив из двух целых переменных, в котором будут храниться два дескриптора файла для чтения из канала и для записи в канал. Поскольку ядро реализует каналы внутри файловой системы и поскольку канал не существует до того, как его будут использовать, ядро должно при создании канала назначить ему индекс. Оно также назначает для канала пару пользовательских дескрипторов и соответствующие им записи в таблице файлов: один из дескрипторов для чтения из канала, а другой для записи в канал. Поскольку ядро пользуется таблицей файлов, интерфейс для вызова функций read, write и др. согласуется с интерфейсом для обычных файлов. В результате процессам нет надобности знать, ведут ли они чтение или запись в обычный файл или в канал. алгоритм pipe входная информация: отсутствует выходная информация: дескриптор файла для чтения дескриптор файла для записи { назначить новый индекс из устройства канала (алгоритм ialloc); выделить одну запись в таблице файлов для чтения, одну — для переписи; инициализировать записи в таблице файлов таким образом, чтобы они указывали на новый индекс; выделить один пользовательский дескриптор файла для чтения, один — для записи, проинициализировать их таким образом, чтобы они указывали на соответствующие точки входа в таблице файлов; установить значение счетчика ссылок в индексе равным 2; установить значение счетчика числа процессов, производящих чтение, и процессов, производящих запись, равным 1; } Рисунок 5.16. Алгоритм создания каналов (непоименованных) На Рисунке 5.16 показан алгоритм создания непоименованных каналов. Ядро назначает индекс для канала из файловой системы, обозначенной как «устройство канала», используя алгоритм ialloc. Устройство канала — это именно та файловая система, из которой ядро может назначать каналам индексы и выделять блоки для данных. Администраторы системы указывают устройство канала при конфигурировании системы и эти устройства могут совпадать у разных файловых систем. Пока канал активен, ядро не может переназначить индекс канала и информационные блоки канала другому файлу. Затем ядро выделяет в таблице файлов две записи, соответствующие дескрипторам для чтения и записи в канал, и корректирует «бухгалтерскую» информацию в копии индекса в памяти. В каждой из выделенных записей в таблице файлов хранится информация о том, сколько экземпляров канала открыто для чтения или записи (первоначально 1), а счетчик ссылок в индексе указывает, сколько раз канал был «открыт» (первоначально 2 — по одному для каждой записи таблицы файлов). Наконец, в индексе записываются смещения в байтах внутри канала до места, где будет начинаться следующая операция записи или чтения. Благодаря сохранению этих смещений в индексе имеется возможность производить доступ к данным в канале в порядке их поступления в канал («первым пришел первым вышел»); этот момент является особенностью каналов, поскольку для обычных файлов смещения хранятся в таблице файлов. Процессы не могут менять эти смещения с помощью системной функции lseek и поэтому произвольный доступ к данным канала невозможен. 5.12.2 Открытие поименованного каналаПоименованный канал — это файл, имеющий почти такую же семантику, как и непоименованный канал, за исключением того, что этому файлу соответствует запись в каталоге и обращение к нему производится по имени. Процессы открывают поименованные каналы так же, как и обычные файлы, и, следовательно, с помощью поименованных каналов могут взаимодействовать между собой даже процессы, не имеющие друг к другу близкого отношения. Поименованные каналы постоянно присутствуют в иерархии файловой системы (из которой они удаляются с помощью системной функции unlink), а непоименованные каналы являются временными: когда все процессы заканчивают работу с каналом, ядро отбирает назад его индекс. Алгоритм открытия поименованного канала идентичен алгоритму открытия обычного файла. Однако, перед выходом из функции ядро увеличивает значения тех счетчиков в индексе, которые показывают количество процессов, открывших поименованный канал для чтения или записи. Процесс, открывающий поименованный канал для чтения, приостановит свое выполнение до тех пор, пока другой процесс не откроет поименованный канал для записи, и наоборот. Не имеет смысла открывать канал для чтения, если процесс не надеется получить данные; то же самое касается записи. В зависимости от того, открывает ли процесс поименованный канал для записи или для чтения, ядро возобновляет выполнение тех процессов, которые были приостановлены в ожидании процесса, записывающего в поименованный канал или считывающего данные из канала (соответственно). Если процесс открывает поименованный канал для чтения, причем процесс, записывающий в канал, существует, открытие завершается. Или если процесс открывает поименованный файл с параметром «no delay», функция open возвращает управление немедленно, даже когда нет ни одного записывающего процесса. Во всех остальных случаях процесс приостанавливается до тех пор, пока записывающий процесс не откроет канал. Аналогичные правила действуют для процесса, открывающего канал для записи. 5.12.3 Чтение из каналов и запись в каналыКанал следует рассматривать под таким углом зрения, что процессы ведут запись на одном конце канала, а считывают данные на другом конце. Как уже говорилось выше, процессы обращаются к данным в канале в порядке их поступления в канал; это означает, что очередность, в которой данные записываются в канал, совпадает с очередностью их выборки из канала. Совпадение количества процессов, считывающих данные из канала, с количеством процессов, ведущих запись в канал, совсем не обязательно; если одно число отличается от другого более, чем на 1, процессы должны координировать свои действия по использованию канала с помощью других механизмов. Ядро обращается к данным в канале точно так же, как и к данным в обычном файле: оно сохраняет данные на устройстве канала и назначает каналу столько блоков, сколько нужно, во время выполнения функции write. Различие в выделении памяти для канала и для обычного файла состоит в том, что канал использует в индексе только блоки прямой адресации в целях повышения эффективности работы, хотя это и накладывает определенные ограничения на объем данных, одновременно помещающихся в канале. Ядро работает с блоками прямой адресации индекса как с циклической очередью, поддерживая в своей структуре указатели чтения и записи для обеспечения очередности обслуживания "первым пришел - первым вышел" (Рисунок 5.17). Рассмотрим четыре примера ввода-вывода в канал: запись в канал, в котором есть место для записи данных; чтение из канала, в котором достаточно данных для удовлетворения запроса на чтение; чтение из канала, в котором данных недостаточно; и запись в канал, где нет места для записи. Рисунок 5.17. Логическая схема чтения и записи в канал Рассмотрим первый случай, в котором процесс ведет запись в канал, имеющий место для ввода данных: сумма количества записываемых байт с числом байт, уже находящихся в канале, меньше или равна емкости канала. Ядро следует алгоритму записи данных в обычный файл, за исключением того, что оно увеличивает размер канала автоматически после каждого выполнения функции write, поскольку по определению объем данных в канале растет с каждой операцией записи. Иначе происходит увеличение размера обычного файла: процесс увеличивает размер файла только тогда, когда он при записи данных переступает границу конца файла. Если следующее смещение в канале требует использования блока косвенной адресации, ядро устанавливает значение смещения в пространстве процесса таким образом, чтобы оно указывало на начало канала (смещение в байтах, равное 0). Ядро никогда не затирает данные в канале; оно может сбросить значение смещения в 0, поскольку оно уже установило, что данные не будут переполнять емкость канала. Когда процесс запишет в канал все свои данные, ядро откорректирует значение указателя записи (в индексе) канала таким образом, что следующий процесс продолжит запись в канал с того места, где остановилась предыдущая операция write. Затем ядро возобновит выполнение всех других процессов, приостановленных в ожидании считывания данных из канала. Когда процесс запускает функцию чтения из канала, он проверяет, пустой ли канал или нет. Если в канале есть данные, ядро считывает их из канала так, как если бы канал был обычным файлом, выполняя соответствующий алгоритм. Однако, начальным смещением будет значение указателя чтения, хранящегося в индексе и показывающего протяженность прочитанных ранее данных. После считывания каждого блока ядро уменьшает размер канала в соответствии с количеством считанных данных и устанавливает значение смещения в пространстве процесса так, чтобы при достижении конца канала оно указывало на его начало. Когда выполнение системной функции read завершается, ядро возобновляет выполнение всех приостановленных процессов записи и запоминает текущее значение указателя чтения в индексе (а не в записи таблицы файлов). Если процесс пытается считать больше информации, чем фактически есть в канале, функция read завершится успешно, возвратив все данные, находящиеся в данный момент в канале, пусть даже не полностью выполнив запрос пользователя. Если канал пуст, процесс обычно приостанавливается до тех пор, пока какой-нибудь другой процесс не запишет данные в канал, после чего все приостановленные процессы, ожидающие ввода данных, возобновят свое выполнение и начнут конкурировать за чтение из канала. Если, однако, процесс открывает поименованный канал с параметром "no delay" (без задержки), функция read возвратит управление немедленно, если в канале отсутствуют данные. Операции чтения и записи в канал имеют ту же семантику, что и аналогичные операции для терминальных устройств (глава 10), она позволяет процессам игнорировать тип тех файлов, с которыми эти программы имеют дело. Если процесс ведет запись в канал и в канале нет места для всех данных, ядро помечает индекс и приостанавливает выполнение процесса до тех пор, пока канал не начнет очищаться от данных. Когда впоследствии другой процесс будет считывать данные из канала, ядро заметит существование процессов, приостановленных в ожидании очистки канала, и возобновит их выполнение подобно тому, как это было объяснено выше. Исключением из этого утверждения является ситуация, когда процесс записывает в канал данные, объем которых превышает емкость канала (то есть, объем данных, которые могут храниться в блоках прямой адресации); в этом случае ядро записывает в канал столько данных, сколько он может вместить в себя, и приостанавливает процесс до тех пор, пока не освободится дополнительное место. Таким образом, возможно положение, при котором записываемые данные не будут занимать непрерывное место в канале, если другие процессы ведут запись в канал в то время, на которое первый процесс прервал свою работу. Анализируя реализацию каналов, можно заметить, что интерфейс процессов согласуется с интерфейсом обычных файлов, но его воплощение отличается, так как ядро запоминает смещения для чтения и записи в индексе вместо того, чтобы делать это в таблице файлов. Ядро вынуждено хранить значения смещений для поименованных каналов в индексе для того, чтобы процессы могли совместно использовать эти значения: они не могли бы совместно использовать значения, хранящиеся в таблице файлов, так как процесс получает новую запись в таблице файлов по каждому вызову функции open. Тем не менее, совместное использование смещений чтения и записи в индексе наблюдалось и до реализации поименованных каналов. Процессы, обращающиеся к непоименованным каналам, разделяют доступ к каналу через общие точки входа в таблицу файлов, поэтому они могли бы по умолчанию хранить смещения записи и чтения в таблице файлов, как это принято для обычных файлов. Это не было сделано, так как процедуры низкого уровня, работающие в ядре, больше не имеют доступа к записям в таблице файлов: программа упростилась за счет того, что процессы совместно используют значения смещений, хранящиеся в индексе. 5.12.4 Закрытие каналовПри закрытии канала процесс выполняет ту же самую процедуру, что и при закрытии обычного файла, за исключением того, что ядро, прежде чем освободить индекс канала, выполняет специальную обработку. Оно уменьшает количество процессов чтения из канала или записи в канал в зависимости от типа файлового дескриптора. Если значение счетчика числа записывающих в канал процессов становится равным 0 и имеются процессы, приостановленные в ожидании чтения данных из канала, ядро возобновляет выполнение последних и они завершают свои операции чтения без возврата каких-либо данных. Если становится равным 0 значение счетчика числа считывающих из канала процессов и имеются процессы, приостановленные в ожидании возможности записи данных в канал, ядро возобновляет выполнение последних и посылает им сигнал (глава 7) об ошибке. В обоих случаях не имеет смысла продолжать держать процессы приостановленными, если нет надежды на то, что состояние канала когда-нибудь изменится. Например, если процесс ожидает возможности производить чтение из непоименованного канала и в системе больше нет процессов, записывающих в этот канал, значит, записывающий процесс никогда не появится. Несмотря на то, что если канал поименованный, в принципе возможно появление нового считывающего или записывающего процесса, ядро трактует эту ситуацию точно так же, как и для непоименованных каналов. Если к каналу не обращается ни один записывающий или считывающий процесс, ядро освобождает все информационные блоки канала и переустанавливает индекс таким образом, чтобы он указывал на то, что канал пуст. Когда ядро освобождает индекс обычного канала, оно освобождает для переназначения и дисковую копию этого индекса. 5.12.5 Примеры Программа на Рисунке 5.18 иллюстрирует искусственное использование каналов. Процесс создает канал и входит в бесконечный цикл, записывая в канал строку символов «hello» и считывая ее из канала. Ядру не нужно ни знать о том, что процесс, ведущий запись в канал, является и процессом, считывающим из канала, ни проявлять по этому поводу какое-либо беспокойство. char string[] = "hello"; main() { char buf[1024]; char *cp1,*cp2; int fds[2]; cp1 = string; cp2 = buf; while(*cp1) *cp2++ = *cp1++; pipe(fds); for (;;) { write(fds[1], buf, 6); read(fds[0], buf, 6); } } Рисунок 5.18. Чтение из канала и запись в канал Процесс, выполняющий программу, которая приведена на Рисунке 5.19, создает поименованный канал с именем «fifo». Если этот процесс запущен с указанием второго (формального) аргумента, он постоянно записывает в канал строку символов «hello»; будучи запущен без второго аргумента, он ведет чтение из поименованного канала. Два процесса запускаются по одной и той же программе, тайно договорившись взаимодействовать между собой через поименованный канал «fifo», но им нет необходимости быть родственными процессами. Другие пользователи могут выполнять программу и участвовать в диалоге (или мешать ему). #include ‹fcntl.h› char string[] = "hello"; main(argc, argv) int argc; char *argv[]; { int fd; char buf[256]; /* создание поименованного канала с разрешением чтения и записи для всех пользователей */ mknod("fifo", 010777, 0); if (argc == 2) fd = open("fifo", O_WRONLY); else fd = open("fifo", O_RDONLY); for (;;) if (argc == 2) write(fd, string, 6); else read(fd, buf, 6); } Рисунок 5.19. Чтение и запись в поименованный канал 5.13 DUРСистемная функция dup копирует дескриптор файла в первое свободное место в таблице пользовательских дескрипторов файла, возвращая новый дескриптор пользователю. Она действует для всех типов файла. Синтаксис вызова функции: newfd = dup(fd); где fd — дескриптор файла, копируемый функцией, а newfd — новый дескриптор, ссылающийся на файл. Поскольку функция dup дублирует дескриптор файла, она увеличивает значение счетчика в соответствующей записи таблицы файлов — записи, на которую указывают связанные с ней точки входа в таблице файловых дескрипторов, которых теперь стало на одну больше. Например, обзор структур данных, изображенных на Рисунке 5.20, показывает, что процесс вызывает следующую последовательность функций: он открывает (open) файл с именем «/etc/passwd» (файловый дескриптор 3), затем открывает файл с именем «local» (файловый дескриптор 4), снова файл с именем «/etc/passwd» (файловый дескриптор 5) и, наконец, дублирует (dup) файловый дескриптор 3, возвращая дескриптор 6. 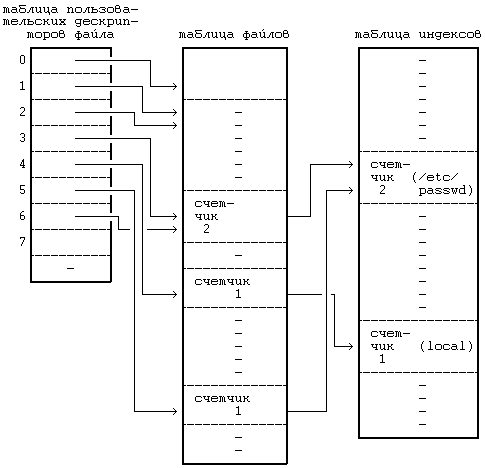 Рисунок 5.20. Структуры данных после выполнения функции dup Возможно, dup — функция, не отличающаяся изяществом, поскольку она предполагает, что пользователь знает о том, что система возвратит свободную точку входа в таблице пользовательских дескрипторов, имеющую наименьший номер. Однако, она служит важной задаче конструирования сложных программ из более простых конструкционных блоков, что, в частности, имеет место при создании конвейеров, составленных из командных процессоров. Рассмотрим программу, приведенную на Рисунке 5.21. В переменной i хранится дескриптор файла, возвращаемый в результате открытия файла «/etc/passwd», а в переменной j — дескриптор файла, возвращаемый системой в результате дублирования дескриптора i с помощью функции dup. В адресном пространстве процесса оба пользовательских дескриптора, представленные переменными i и j, ссылаются на одну и ту же запись в таблице файлов и поэтому используют одно и то же значение смещения внутри файла. Таким образом, первые два вызова процессом функции read реализуют последовательное считывание данных, и в буферах buf1 и buf2 будут располагаться разные данные. Совсем другой результат получается, когда процесс открывает один и тот же файл дважды и читает дважды одни и те же данные (раздел 5.2). Процесс может освободить с помощью функции close любой из файловых дескрипторов по своему желанию, и ввод-вывод получит нормальное продолжение по другому дескриптору, как показано на примере. В частности, процесс может «закрыть» дескриптор файла стандартного вывода (файловый дескриптор 1), снять с него копию, имеющую то же значение, и затем рассматривать новый файл в качестве файла стандартного вывода. В главе 7 будет представлен более реалистический пример использования функций pipe и dup при описании особенностей реализации командного процессора. #include ‹fcntl.h› main() { int i, j; char buf1[512], buf2[512]; i = open("/etc/passwd", O_RDONLY); j = dup(i); read(i, buf1, sizeof(buf1)); read(j, buf2, sizeof(buf2)); close(i); read(j, buf2, sizeof(buf2)); } Рисунок 5.21. Программа на языке Си, иллюстрирующая использование функции dup 5.14 МОНТИРОВАНИЕ И ДЕМОНТИРОВАНИЕ ФАЙЛОВЫХ СИСТЕМФизический диск состоит из нескольких логических разделов, на которые он разбит дисковым драйвером, причем каждому разделу соответствует файл устройства, имеющий определенное имя. Процессы обращаются к данным раздела, открывая соответствующий файл устройства и затем ведя запись и чтение из этого «файла», представляя его себе в виде последовательности дисковых блоков. Это взаимодействие во всех деталях рассматривается в главе 10. Раздел диска может содержать логическую файловую систему, состоящую из блока начальной загрузки, суперблока, списка индексов и информационных блоков (см. главу 2). Системная функция mount (монтировать) связывает файловую систему из указанного раздела на диске с существующей иерархией файловых систем, а функция umount (демонтировать) выключает файловую систему из иерархии. Функция mount, таким образом, дает пользователям возможность обращаться к данным в дисковом разделе как к файловой системе, а не как к последовательности дисковых блоков. Синтаксис вызова функции mount: mount(special pathname, directory pathname, options); где special pathname — имя специального файла устройства, соответствующего дисковому разделу с монтируемой файловой системой, directory pathname — каталог в существующей иерархии, где будет монтироваться файловая система (другими словами, точка или место монтирования), а options указывает, следует ли монтировать файловую систему «только для чтения» (при этом не будут выполняться такие функции, как write и creat, которые производят запись в файловую систему). Например, если процесс вызывает функцию mount следующим образом: mount("/dev/dsk1", "/usr', 0); ядро присоединяет файловую систему, находящуюся в дисковом разделе с именем «/dev/dsk1», к каталогу «/usr» в существующем дереве файловых систем (см. Рисунок 5.22). Файл «/dev/dsk1» является блочным специальным файлом, т. е. он носит имя устройства блочного типа, обычно имя раздела на диске. Ядро предполагает, что раздел на диске с указанным именем содержит файловую систему с суперблоком, списком индексов и корневым индексом. После выполнения функции mount к корню смонтированной файловой системы можно обращаться по имени «/usr». Процессы могут обращаться к файлам в монтированной файловой системе и игнорировать тот факт, что система может отсоединяться. Только системная функция link контролирует файловую систему, так как в версии V не разрешаются связи между файлами, принадлежащими разным файловым системам (см. раздел 5.15). 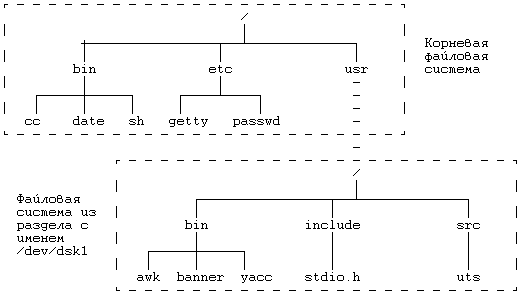 Рисунок 5.22. Дерево файловых систем до и после выполнения функции mount Ядро поддерживает таблицу монтирования с записями о каждой монтированной файловой системе. В каждой записи таблицы монтирования содержатся: • номер устройства, идентифицирующий монтированную файловую систему (упомянутый выше логический номер файловой системы); • указатель на буфер, где находится суперблок файловой системы; • указатель на корневой индекс монтированной файловой системы («/» для файловой системы с именем «/dev/dsk1» на Рисунке 5.22); • указатель на индекс каталога, ставшего точкой монтирования (на Рисунке 5.22 это каталог «usr», принадлежащий корневой файловой системе). Связь индекса точки монтирования с корневым индексом монтированной файловой системы, возникшая в результате выполнения системной функции mount, дает ядру возможность легко двигаться по иерархии файловых систем без получения от пользователей дополнительных сведений. алгоритм mount входная информация: имя блочного специального файла имя каталога точки монтирования опции («только для чтения») выходная информация: отсутствует { if (пользователь не является суперпользователем) return (ошибку); получить индекс для блочного специального файла (алгоритм namei); проверить допустимость значений параметров; получить индекс для имени каталога, где производится монтирование (алгоритм namei); if (индекс не является индексом каталога или счетчик ссылок имеет значение › 1) { освободить индексы (алгоритм iput); return (ошибку); } найти свободное место в таблице монтирования; запустить процедуру открытия блочного устройства для данного драйвера; получить свободный буфер из буферного кеша; считать суперблок в свободный буфер; проинициализировать поля суперблока; получить корневой индекс монтируемой системы (алгоритм iget), сохранить его в таблице монтирования; сделать пометку в индексе каталога о том, что каталог является точкой монтирования; освободить индекс специального файла (алгоритм iput); снять блокировку с индекса каталога точки монтирования; } Рисунок 5.23. Алгоритм монтирования файловой системы На Рисунке 5.23 показан алгоритм монтирования файловой системы. Ядро позволяет монтировать и демонтировать файловые системы только тем процессам, владельцем которых является суперпользователь. Предоставление возможности выполнять функции mount и umount всем пользователям привело бы к внесению с их стороны хаоса в работу файловой системы, как умышленному, так и явившемуся результатом неосторожности. Суперпользователи могут разрушить систему только случайно. Ядро находит индекс специального файла, представляющего файловую систему, подлежащую монтированию, извлекает старший и младший номера, которые идентифицируют соответствующий дисковый раздел, и выбирает индекс каталога, в котором файловая система будет смонтирована. Счетчик ссылок в индексе каталога должен иметь значение, не превышающее 1 (и меньше 1 он не должен быть — почему?), в связи с наличием потенциально опасных побочных эффектов (см. упражнение 5.27). Затем ядро назначает свободное место в таблице монтирования, помечает его для использования и присваивает значение полю номера устройства в таблице. Вышеуказанные назначения производятся немедленно, поскольку вызывающий процесс может приостановиться, следуя процедуре открытия устройства или считывая суперблок файловой системы, а другой процесс тем временем попытался бы смонтировать файловую систему. Пометив для использования запись в таблице монтирования, ядро не допускает использования в двух вызовах функции mount одной и той же записи таблицы. Запоминая номер устройства с монтируемой системой, ядро может воспрепятствовать повторному монтированию одной и той же системы другими процессами, которое, будь оно допущено, могло бы привести к непредсказуемым последствиям (см. упражнение 5.26). Ядро вызывает процедуру открытия для блочного устройства, содержащего файловую систему, точно так же, как оно делает это при непосредственном открытии блочного устройства (глава 10). Процедура открытия устройства обычно проверяет существование такого устройства, иногда производя инициализацию структур данных драйвера и посылая команды инициализации аппаратуре. Затем ядро выделяет из буферного пула свободный буфер (вариант алгоритма getblk) для хранения суперблока монтируемой файловой системы и считывает суперблок, используя один из вариантов алгоритма read. Ядро сохраняет указатель на индекс каталога, в котором монтируется система, давая возможность маршрутам поиска файловых имен, содержащих имя «…», пересекать точку монтирования, как мы увидим дальше. Оно находит корневой индекс монтируемой файловой системы и запоминает указатель на индекс в таблице монтирования. С точки зрения пользователя, место (точка) монтирования и корень файловой системы логически эквивалентны, и ядро упрочивает эту эквивалентность благодаря их сосуществованию в одной записи таблицы монтирования. Процессы больше не могут обращаться к индексу каталога — точки монтирования. Ядро инициализирует поля в суперблоке файловой системы, очищая поля для списка свободных блоков и списка свободных индексов и устанавливая число свободных индексов в суперблоке равным 0. Целью инициализации (задания начальных значений полей) является сведение к минимуму опасности разрушить файловую систему, если монтирование осуществляется после аварийного завершения работы системы. Если ядро заставить думать, что в суперблоке отсутствуют свободные индексы, то это приведет к запуску алгоритма ialloc, ведущего поиск на диске свободных индексов. К сожалению, если список свободных дисковых блоков испорчен, ядро не исправляет этот список изнутри (см. раздел 5.17 о сопровождении файловой системы). Если пользователь монтирует файловую систему только для чтения, запрещая проведение всех операций записи в системе, ядро устанавливает в суперблоке соответствующий флаг. Наконец, ядро помечает индекс каталога как «точку монтирования», чтобы другие процессы позднее могли ссылаться на нее. На Рисунке 5.24 представлен вид различных структур данных по завершении выполнения функции mount. 5.14.1 Пересечение точек монтирования в маршрутах поиска имен файловДавайте повторно рассмотрим поведение алгоритмов namei и iget в случаях, когда маршрут поиска файлов проходит через точку монтирования. Точку монтирования можно пересечь двумя способами: из файловой системы, где производится монтирование, в файловую систему, которая монтируется (в направлении от глобального корня к листу), и в обратном направлении. Эти способы иллюстрирует следующая последовательность команд shell'а. mount /dev/dsk1 /usr cd /usr/src/uts cd ../../.. По команде mount после выполнения некоторых логических проверок запускается системная функция mount, которая монтирует файловую систему в дисковом разделе с именем «/dev/dsk1» под управлением каталога «/usr». Первая из команд cd (сменить каталог) побуждает командный процессор shell вызвать системную функцию chdir, выполняя которую, ядро анализирует имя пути поиска, пересекающего точку монтирования в «/usr». Вторая из команд cd приводит к тому, что ядро анализирует имя пути поиска и пересекает точку монтирования в третьей компоненте «..» имени. 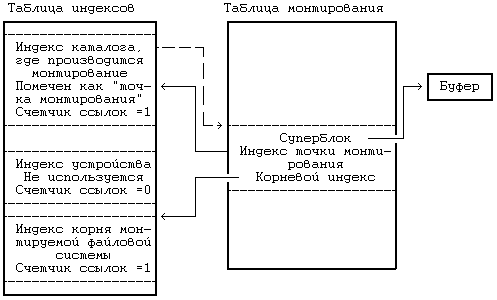 Рисунок 5.24. Структуры данных после монтирования Для случая пересечения точки монтирования в направлении из файловой системы, где производится монтирование, в файловую систему, которая монтируется, рассмотрим модификацию алгоритма iget (Рисунок 5.25), которая идентична версии алгоритма, приведенной на Рисунке 4.3, почти во всем, за исключением того, что в данной модификации производится проверка, является ли индекс индексом точки монтирования. Если индекс имеет соответствующую пометку, ядро соглашается, что это индекс точки монтирования. Оно обнаруживает в таблице монтирования запись с указанным индексом точки монтирования и запоминает номер устройства монтируемой файловой системы. Затем, используя номер устройства и номер индекса корня, общего для всех файловых систем, ядро обращается к индексу корня монтируемого устройства и возвращает при выходе из функции этот индекс. В первом примере смены каталога ядро обращается к индексу каталога «/usr» из файловой системы, в которой производится монтирование, обнаруживает, что этот индекс имеет пометку «точка монтирования», находит в таблице монтирования индекс корня монтируемой файловой системы и обращается к этому индексу. алгоритм iget входная информация: номер индекса в файловой системе выходная информация: заблокированный индекс { do { if (индекс в индексном кеше) { if (индекс заблокирован) { sleep (до освобождения индекса); continue; /* цикл с условием продолжения */ } /* специальная обработка для точек монтирования */ if (индекс является индексом точки монтирования) { найти запись в таблице монтирования для точки монтирования; получить новый номер файловой системы из таблицы монтирования; использовать номер индекса корня для просмотра; continue; /* продолжение цикла */ } if (индекс в списке свободных индексов) убрать из списка свободных индексов; увеличить счетчик ссылок для индекса; return (индекс); } /* индекс отсутствует в индексном кеше */ убрать новый индекс из списка свободных индексов; сбросить номер индекса и файловой системы; убрать индекс из старой хеш-очереди, поместить в новую; считать индекс с диска (алгоритм bread); инициализировать индекс (например, установив счетчик ссылок в 1); return (индекс); } } Рисунок 5.25. Модификация алгоритма получения доступа к индексу Для второго случая пересечения точки монтирования в направлении из файловой системы, которая монтируется, в файловую систему, где выполняется монтирование, рассмотрим модификацию алгоритма namei (Рисунок 5.26). Она похожа на версию алгоритма, приведенную на Рисунке 4.11. Однако, после обнаружения в каталоге номера индекса для данной компоненты пути поиска ядро проверяет, не указывает ли номер индекса на то, что это корневой индекс файловой системы. Если это так и если текущий рабочий индекс так же является корневым, а компонента пути поиска, в свою очередь, имеет имя «..», ядро идентифицирует индекс как точку монтирования. Оно находит в таблице монтирования запись, номер устройства в которой совпадает с номером устройства для последнего из найденных индексов, получает индекс для каталога, в котором производится монтирование, и продолжает поиск компоненты с именем «..», используя только что полученный индекс в качестве рабочего. В корне файловой системы, тем не менее, корневым каталогом является «..» алгоритм namei /* превращение имени пути поиска в индекс */ входная информация: имя пути поиска выходная информация: заблокированный индекс { if (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget); else рабочий индекс = индексу текущего каталога (алгоритм iget); do (пока путь поиска не кончился) { считать следующую компоненту имени пути поиска; проверить соответствие рабочего индекса каталогу и права доступа; if (рабочий индекс соответствует корню и компонента имени «..») continue; /* цикл с условием продолжения */ поиск компоненты: считать каталог (рабочий индекс), повторяя алгоритмы bmap, bread и brelse; if (компонента соответствует записи в каталоге (рабочем индексе)) { получить номер индекса для совпавшей компоненты; if (найденный индекс является индексом корня и рабочий индекс является индексом корня и имя компоненты «..») { /* пересечение точки монтирования */ получить запись в таблице монтирования для рабочего индекса; освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу точки монтирования; заблокировать индекс точки монтирования; увеличить значение счетчика ссылок на рабочий индекс; перейти к поиску компоненты (для «..»); } освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу с новым номером (алгоритм iget); } else /* компонента отсутствует в каталоге */ return (нет индекса); } return (рабочий индекс); } Рисунок 5.26. Модификация алгоритма синтаксического анализа имени файла В вышеприведенном примере (cd «../../..») предполагается, что в начале процесс имеет текущий каталог с именем «/usr/src/uts». Когда имя пути поиска подвергается анализу в алгоритме namei, начальным рабочим индексом является индекс текущего каталога. Ядро меняет текущий рабочий индекс на индекс каталога с именем «/usr/src» в результате расшифровки первой компоненты «..» в имени пути поиска. Затем ядро анализирует вторую компоненту «..» в имени пути поиска, находит корневой индекс смонтированной (перед этим) файловой системы — индекс каталога «usr» — и делает его рабочим индексом при анализе имени с помощью алгоритма namei. Наконец, оно расшифровывает третью компоненту «..» в имени пути поиска. Ядро обнаруживает, что номер индекса для «..» совпадает с номером корневого индекса, рабочим индексом является корневой индекс, а «..» является текущей компонентой имени пути поиска. Ядро находит запись в таблице монтирования, соответствующую точке монтирования «usr», освобождает текущий рабочий индекс (корень файловой системы, смонтированной в каталоге «usr») и назначает индекс точки монтирования (каталога «usr» в корневой файловой системе) в качестве нового рабочего индекса. Затем оно просматривает записи в каталоге точки монтирования «/usr» в поисках имени «..» и находит номер индекса для корня файловой системы («/»). После этого системная функция chdir завершается как обычно, вызывающий процесс не обращает внимания на тот факт, что он пересек точку монтирования. 5.14.2 Демонтирование файловой системы Синтаксис вызова системной функции umount: umount(special filename); где special filename указывает демонтируемую файловую систему. При демонтировании файловой системы (Рисунок 5.27) ядро обращается к индексу демонтируемого устройства, восстанавливает номер устройства для специального файла, освобождает индекс (алгоритм iput) и находит в таблице монтирования запись с номером устройства, равным номеру устройства для специального файла. Прежде чем ядро действительно демонтирует файловую систему, оно должно удостовериться в том, что в системе не осталось используемых файлов, для этого ядро просматривает таблицу индексов в поисках всех файлов, чей номер устройства совпадает с номером демонтируемой системы. Активным файлам соответствует положительное значение счетчика ссылок и в их число входят текущий каталог процесса, файлы с разделяемым текстом, которые исполняются в текущий момент (глава 7), и открытые когда-то файлы, которые потом не были закрыты. Если какие-нибудь файлы из файловой системы активны, функция umount завершается неудачно: если бы она прошла успешно, активные файлы сделались бы недоступными. Буферный пул все еще содержит блоки с «отложенной записью», не переписанные на диск, поэтому ядро «вымывает» их из буферного пула. Ядро удаляет записи с разделяемым текстом, которые находятся в таблице областей, но не являются действующими (подробности в главе 7), записывает на диск все недавно скорректированные суперблоки и корректирует дисковые копии всех индексов, которые требуют этого. Казалось, было бы достаточно откорректировать дисковые блоки, суперблок и индексы только для демонтируемой файловой системы, однако в целях сохранения преемственности изменений ядро выполняет аналогичные действия для всей системы в целом. Затем ядро освобождает корневой индекс монтированной файловой системы, удерживаемый с момента первого обращения к нему во время выполнения функции mount, и запускает из драйвера процедуру закрытия устройства, содержащего файловую систему. Впоследствии ядро просматривает буферы в буферном кеше и делает недействительными те из них, в которых находятся блоки демонтируемой файловой системы; в хранении информации из этих блоков в кеше больше нет необходимости. Делая буферы недействительными, ядро вставляет их в начало списка свободных буферов, в то время как блоки с актуальной информацией остаются в буферном кеше. Ядро сбрасывает в индексе системы, где производилось монтирование, флаг «точки монтирования», установленный функцией mount, и освобождает индекс. Пометив запись в таблице монтирования свободной для общего использования, функция umount завершает работу. алгоритм umount входная информация: имя специального файла, соответствующего демонтируемой файловой системе выходная информация: отсутствует { if (пользователь не является суперпользователем) return (ошибку); получить индекс специального файла (алгоритм namei); извлечь старший и младший номера демонтируемого устройства; получить в таблице монтирования запись для демонтируемой системы, исходя из старшего и младшего номеров; освободить индекс специального файла (алгоритм iput); удалить из таблицы областей записи с разделяемым текстом для файлов, принадлежащих файловой системе; /* глава 7ххх */ скорректировать суперблок, индексы, выгрузить буферы на диск; if (какие-то файлы из файловой системы все еще используются) return (ошибку); получить из таблицы монтирования корневой индекс монтированной файловой системы; заблокировать индекс; освободить индекс (алгоритм iput); /* iget был при монтировании */ запустить процедуру закрытия для специального устройства; сделать недействительными (отменить) в пуле буферы из демонтируемой файловой системы; получить из таблицы монтирования индекс точки монтирования; заблокировать индекс; очистить флаг, помечающий индекс как «точку монтирования»; освободить индекс (алгоритм iput); /* iget был при монтировании */ освободить буфер, используемый под суперблок; освободить в таблице монтирования место, занятое ранее; } Рисунок 5.27. Алгоритм демонтирования файловой системы 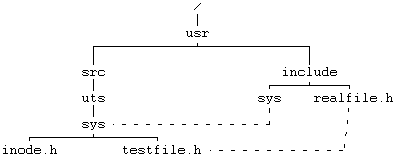 Рисунок 5.28. Файлы в дереве файловой системы, связанные с помощью функции link 5.15 LINКСистемная функция link связывает файл с новым именем в структуре каталогов файловой системы, создавая для существующего индекса новую запись в каталоге. Синтаксис вызова функции link: link(source file name, target file name); где source file name — существующее имя файла, а target file name — новое (дополнительное) имя, присваиваемое файлу после выполнения функции link. Файловая система хранит имя пути поиска для каждой связи, имеющейся у файла, и процессы могут обращаться к файлу по любому из этих имен. Ядро не знает, какое из имен файла является его подлинным именем, поэтому имя файла специально не обрабатывается. Например, после выполнения набора функций: link("/usr/src/uts/sys", "/usr/include/sys"); link("/usr/include/realfile.h", "/usr/src/uts/sys/testfile.h"); на один и тот же файл будут указывать три имени пути поиска: «/usr/src/uts/sys/testfile.h», «/usr/include/sys/testfile.h» и «/usr/include/realfile» (см. Рисунок 5.28). Ядро позволяет суперпользователю (и только ему) связывать каталоги, упрощая написание программ, требующих пересечения дерева файловой системы. Если бы это было разрешено произвольному пользователю, программам, пересекающим иерархическую структуру файлов, пришлось бы заботиться о том, чтобы не попасть в бесконечный цикл в том случае, если пользователь связал каталог с вершиной, стоящей ниже в иерархии. Предполагается, что суперпользователи более осторожны в указании таких связей. Возможность связывать между собой каталоги должна была поддерживаться в ранних версиях системы, так как эта возможность требуется для реализации команды mkdir, которая создает новый каталог. Включение функции mkdir устраняет необходимость в связывании каталогов. алгоритм link входная информация: существующее имя файла новое имя файла выходная информация: отсутствует { получить индекс для существующего имени файла (алгоритм namei); if (у файла слишком много связей или производится связывание каталога без разрешения суперпользователя) { освободить индекс (алгоритм iput); return (ошибку); } увеличить значение счетчика связей в индексе; откорректировать дисковую копию индекса; снять блокировку с индекса; получить индекс родительского каталога для включения нового имени файла (алгоритм namei); if (файл с новым именем уже существует или существующий файл и новый файл находятся в разных файловых системах) { отменить корректировку, сделанную выше; return (ошибку); } создать запись в родительском каталоге для файла с новым именем; включить в нее новое имя и номер индекса существующего файла; освободить индекс родительского каталога (алгоритм iput); освободить индекс существующего файла (алгоритм iput); } Рисунок 5.29. Алгоритм связывания файлов На Рисунке 5.29 показан алгоритм функции link. Сначала ядро, используя алгоритм namei, определяет местонахождение индекса исходного файла, увеличивает значение счетчика связей в индексе, корректирует дисковую копию индекса (для обеспечения согласованности) и снимает с индекса блокировку. Затем ядро ищет файл с новым именем; если он существует, функция link завершается неудачно и ядро восстанавливает прежнее значение счетчика связей, измененное ранее. В противном случае ядро находит в родительском каталоге свободную запись для файла с новым именем, записывает в нее новое имя и номер индекса исходного файла и освобождает индекс родительского каталога, используя алгоритм iput. Поскольку файл с новым именем ранее не существовал, освобождать еще какой-нибудь индекс не нужно. Ядро, освобождая индекс исходного файла, делает заключение: счетчик связей в индексе имеет значение, на 1 большее, чем то значение, которое счетчик имел перед вызовом функции, и обращение к файлу теперь может производиться по еще одному имени в файловой системе. Счетчик связей хранит количество записей в каталогах, которые (записи) указывают на файл, и тем самым отличается от счетчика ссылок в индексе. Если по завершении выполнения функции link к файлу нет обращений со стороны других процессов, счетчик ссылок в индексе принимает значение, равное 0, а счетчик связей — значение, большее или равное 2. Например, выполняя функцию, вызванную как: link("source", "/dir/target"); ядро обнаруживает индекс для файла «source», увеличивает в нем значение счетчика связей, запоминает номер индекса, скажем 74, и снимает с индекса блокировку. Ядро также находит индекс каталога «dir», являющегося родительским каталогом для файла «target», ищет свободное место в каталоге «dir» и записывает в него имя файла «target» и номер индекса 74. По окончании этих действий оно освобождает индекс файла «source» по алгоритму iput. Если значение счетчика связей файла «source» раньше было равно 1, то теперь оно равно 2. Стоит упомянуть о двух тупиковых ситуациях, явившихся причиной того, что процесс снимает с индекса исходного файла блокировку после увеличения значения счетчика связей. Если бы ядро не снимало с индекса блокировку, два процесса, выполняющие одновременно следующие функции: процесс A: link("a/b/c/d", "e/f/g"); процесс B: link("e/f", "a/b/c/d/ee"); зашли бы в тупик (взаимная блокировка). Предположим, что процесс A обнаружил индекс файла «a/b/c/d» в тот самый момент, когда процесс B обнаружил индекс файла «e/f». Фраза «в тот же самый момент» означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. (Рисунок 5.30 иллюстрирует стадии выполнения процессов.) Когда же теперь процесс A попытается получить индекс файла «e/f», он приостановит свое выполнение до тех пор, пока индекс файла «f» не освободится. В то же время процесс B пытается получить индекс каталога «a/b/c/d» и приостанавливается в ожидании освобождения индекса файла «d». Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, нужный процессу A. На практике этот классический пример взаимной блокировки невозможен благодаря тому, что ядро освобождает индекс исходного файла после увеличения значения счетчика связей. Поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимная блокировка не происходит. Следующий пример показывает, как два процесса могут зайти в тупик, если с индекса не была снята блокировка. Одиночный процесс может также заблокировать самого себя. Если он вызывает функцию: link("a/b/c", "a/b/c/d"); то в начале алгоритма он получает индекс для файла «c»; если бы ядро не снимало бы с индекса блокировку, процесс зашел бы в тупик, запросив индекс «c» при поиске файла «d». Если бы два процесса, или даже один процесс, не могли продолжать свое выполнение из-за взаимной блокировки (или самоблокировки), что в результате произошло бы в системе? Поскольку индексы являются теми ресурсами, которые предоставляются системой за конечное время, получение сигнала не может быть причиной возобновления процессом своей работы (глава 7). Следовательно, система не может выйти из тупика без перезагрузки. Если к файлам, заблокированным процессами, нет обращений со стороны других процессов, взаимная блокировка не затрагивает остальные процессы в системе. Однако, любые процессы, обратившиеся к этим файлам (или обратившиеся к другим файлам через заблокированный каталог), непременно зайдут в тупик. Таким образом, если заблокированы файлы «/bin» или «/usr/bin» (обычные хранилища команд) или файл «/bin/sh» (командный процессор shell), последствия для системы будут гибельными. 5.16 UNLINК Системная функция unlink удаляет из каталога точку входа для файла. Синтаксис вызова функции unlink: unlink(pathname); где pathname указывает имя файла, удаляемое из иерархии каталогов. Если процесс разрывает данную связь файла с каталогом при помощи функции unlink, по указанному в вызове функции имени файл не будет доступен, пока в каталоге не создана еще одна запись с этим именем. Например, при выполнении следующего фрагмента программы: unlink("myfile"); fd = open("myfile", O_RDONLY); функция open завершится неудачно, поскольку к моменту ее выполнения в текущем каталоге больше не будет файла с именем myfile. Если удаляемое имя является последней связью файла с каталогом, ядро в итоге освобождает все информационные блоки файла. Однако, если у файла было несколько связей, он остается все еще доступным под другими именами. 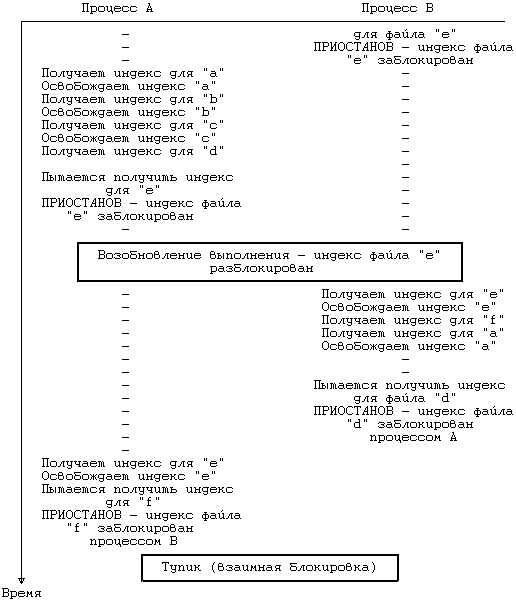 Рисунок 5.30. Взаимная блокировка процессов при выполнении функции link На Рисунке 5.31 представлен алгоритм функции unlink. Сначала для поиска файла с удаляемой связью ядро использует модификацию алгоритма namei, которая вместо индекса файла возвращает индекс родительского каталога. Ядро обращается к индексу файла в памяти, используя алгоритм iget. (Особый случай, связанный с удалением имени файла».», будет рассмотрен в упражнении). После проверки отсутствия ошибок и (для исполняемых файлов) удаления из таблицы областей записей с неактивным разделяемым текстом (глава 7) ядро стирает имя файла из родительского каталога: сделать значение номера индекса равным 0 достаточно для очистки места, занимаемого именем файла в каталоге. Затем ядро производит синхронную запись каталога на диск, гарантируя тем самым, что под своим прежним именем файл уже не будет доступен, уменьшает значение счетчика связей и с помощью алгоритма iput освобождает в памяти индексы родительского каталога и файла с удаляемой связью. При освобождении в памяти по алгоритму iput индекса файла с удаляемой связью, если значения счетчика ссылок и счетчика связей становятся равными 0, ядро забирает у файла обратно дисковые блоки, которые он занимал. На этот индекс больше не указывает ни одно из файловых имен и индекс неактивен. Для того, чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индекса, освобождая все блоки прямой адресации немедленно (в соответствии с алгоритмом free). Что касается блоков косвенной адресации, ядро освобождает все блоки, появляющиеся на различных уровнях косвенности, рекурсивно, причем в первую очередь освобождаются блоки с меньшим уровнем. Оно обнуляет номера блоков в таблице содержимого индекса и устанавливает размер файла в индексе равным 0. Затем ядро очищает в индексе поле типа файла, указывая тем самым, что индекс свободен, и освобождает индекс по алгоритму ifree. Ядро делает необходимую коррекцию на диске, так как дисковая копия индекса все еще указывает на то, что индекс используется; теперь индекс свободен для назначения другим файлам. алгоритм unlink входная информация: имя файла выходная информация: отсутствует { получить родительский индекс для файла с удаляемой связью (алгоритм namei); /* если в качестве файла выступает текущий каталог… */ if (последней компонентой имени файла является ".") увеличить значение счетчика ссылок в индексе; else получить индекс для файла с удаляемой связью (алгоритм iget); if (файл является каталогом, но пользователь не является суперпользователем) { освободить индексы (алгоритм iput); return (ошибку); } if (файл имеет разделяемый текст и текущее значение счетчика связей равно 1) удалить записи из таблицы областей; в родительском каталоге: обнулить номер индекса для удаляемой связи; освободить индекс родительского каталога (алгоритм iput); уменьшить число связей файла; освободить индекс файла (алгоритм iput); /* iput проверяет, равно ли число связей 0, если да, освобождает блоки файла (алгоритм free) и освобождает индекс (алгоритм ifree); */ } Рисунок 5.31. Алгоритм удаления связи файла с каталогом 5.16.1 Целостность файловой системы Ядро посылает свои записи на диск для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя. Например, когда ядро удаляет имя файла из родительского каталога, оно синхронно переписывает каталог на диск — перед тем, как уничтожить содержимое файла и освободить его индекс. Если система дала сбой до того, как произошло удаление содержимого файла, ущерб файловой системе будет нанесен минимальный: один из индексов будет иметь число связей, на 1 превышающее число записей в каталоге, которые ссылаются на этот индекс, но все остальные имена путей поиска файла останутся допустимыми. Если запись на диск не была сделана синхронно, точка входа в каталог на диске после системного сбоя может указывать на свободный (или переназначенный) индекс. Таким образом, число записей в каталоге на диске, которые ссылаются на индекс, превысило бы значение счетчика ссылок в индексе. В частности, если имя файла было именем последней связи файла, это имя указывало бы на не назначенный индекс. Не вызывает сомнения, что в первом случае ущерб, наносимый системе, менее серьезен и легко устраним (см. раздел 5.18). Предположим, например, что у файла есть две связи с именами «a» и «b», одна из которых — «a» — разрывается процессом с помощью функции unlink. Если ядро записывает на диске результаты всех своих действий, то оно, очищая точку входа в каталог для файла «a», делает то же самое на диске. Если система дала сбой после завершения записи результатов на диск, число связей у файла «b» будет равно 2, но файл «a» уже не будет существовать, поскольку прежняя запись о нем была очищена перед сбоем системы. Файл «b», таким образом, будет иметь лишнюю связь, но после перезагрузки число связей переустановится и система будет работать надлежащим образом. Теперь предположим, что ядро записывало на диск результаты своих действий в обратном порядке и система дала сбой: то есть, ядро уменьшило значение счетчика связей для файла «b», сделав его равным 1, записало индекс на диск и дало сбой перед тем, как очистить в каталоге точку входа для файла «a». После перезагрузки системы записи о файлах «a» и «b» в соответствующих каталогах будут существовать, но счетчик связей у того файла, на который они указывают, будет иметь значение 1. Если затем процесс запустит функцию unlink для файла «a», значение счетчика связей станет равным 0, несмотря на то, что файл «b» ссылается на тот же индекс. Если позднее ядро переназначит индекс в результате выполнения функции creat, счетчик связей для нового файла будет иметь значение, равное 1, но на файл будут ссылаться два имени пути поиска. Система не может выправить ситуацию, не прибегая к помощи программ сопровождения (fsck, описанной в разделе 5.18), обращающихся к файловой системе через блочный или строковый интерфейс. Для того, чтобы свести к минимуму опасность искажения файловой системы в случае системного сбоя, ядро освобождает индексы и дисковые блоки также в особом порядке. При удалении содержимого файла и очистке его индекса можно сначала освободить блоки, содержащие данные файла, а можно освободить индекс и заново переписать его. Результат в обоих случаях, как правило, одинаковый, однако, если где-то в середине произойдет системный сбой, они будут различаться. Предположим, что ядро сначала освободило дисковые блоки, принадлежавшие файлу, и дало сбой. После перезагрузки системы индекс все еще содержит ссылки на дисковые блоки, занимаемые файлом прежде и ныне не хранящие относящуюся к файлу информацию. Ядру файл показался бы вполне удовлетворительным, но пользователь при обращении к файлу заметит искажение данных. Эти дисковые блоки к тому же могут быть переназначены другим файлам. Чтобы очистить файловую систему программой fsck, потребовались бы большие усилия. Однако, если система сначала переписала индекс на диск, а потом дала сбой, пользователь не заметит каких-либо искажений в файловой системе после перезагрузки. Информационные блоки, ранее принадлежавшие файлу, станут недоступны для системы, но каких-нибудь явных изменений при этом пользователи не увидят. Программе fsck так же было бы проще забрать назад освободившиеся после удаления связи дисковые блоки, нежели производить очистку, необходимую в первом из рассматриваемых случаев. 5.16.2 Поводы для конкуренции Поводов для конкуренции при выполнении системной функции unlink очень много, особенно при удалении имен каталогов. Команда rmdir удаляет каталог, убедившись предварительно в том, что в каталоге отсутствуют файлы (она считывает каталог и проверяет значения индексов во всех записях каталога на равенство нулю). Но так как команда rmdir запускается на пользовательском уровне, действия по проверке содержимого каталога и удаления каталога выполняются не так уж просто; система должна переключать контекст между выполнением функций read и unlink. Однако, после того, как команда rmdir обнаружила, что каталог пуст, другой процесс может предпринять попытку создать файл в каталоге функцией creat. Избежать этого пользователи могут только путем использования механизма захвата файла и записи. Тем не менее, раз процесс приступил к выполнению функции unlink, никакой другой процесс не может обратиться к файлу с удаляемой связью, поскольку индексы родительского каталога и файла заблокированы. Обратимся еще раз к алгоритму функции link и посмотрим, каким образом система снимает с индекса блокировку до завершения выполнения функции. Если бы другой процесс удалил связь файла пока его индекс свободен, он бы тем самым только уменьшил значение счетчика связей; так как значение счетчика связей было увеличено перед удалением связи, это значение останется положительным. Следовательно, файл не может быть удален и система работает надежно. Эта ситуация аналогична той, когда функция unlink вызывается сразу после завершения выполнения функции link. Другой повод для конкуренции имеет место в том случае, когда один процесс преобразует имя пути поиска файла в индекс файла по алгоритму namei, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени «a/ b/c/d» и приостанавливается во время получения индекса для файла «c». Он может приостановиться при попытке заблокировать индекс или при попытке обратиться к дисковому блоку, где этот индекс хранится (см. алгоритмы iget и bread). Если процессу B нужно удалить связь для каталога с именем «c», он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога «c» и его содержимое по этой связи. Позднее, процесс A попытается обратиться к несуществующему индексу, который уже был удален. Алгоритм namei, проверяющий в первую очередь неравенство значения счетчика связей нулю, сообщит об ошибке. Такой проверки, однако, не всегда достаточно, поскольку можно предположить, что какой-нибудь другой процесс создаст в любом месте файловой системы новый каталог и получит тот индекс, который ранее использовался для «c». Процесс A будет заблуждаться, думая, что он обратился к нужному индексу (см. Рисунок 5.32). Как бы то ни было, система сохраняет свою целостность; самое худшее, что может произойти, это обращение не к тому файлу — с возможным нарушением защиты — но соперничества такого рода на практике довольно редки. 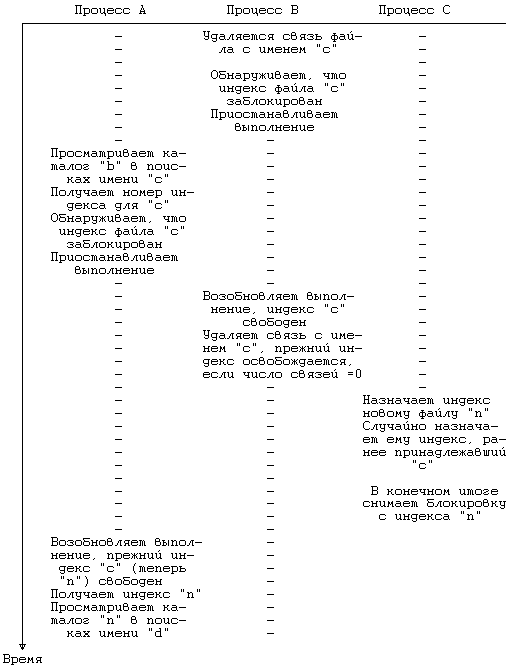 Рисунок 5.32. Соперничество процессов за индекс при выполнении функции unlink #include ‹sys/types.h› #include ‹sys/stat.h› #include ‹fcntl.h› main(argc, argv) int argc; char *argv[]; { int fd; char buf[1024]; struct stat statbuf; if (argc != 2) /* нужен параметр */ exit(); fd = open(argv[1], O_RDONLY); if (fd == -1) /* open завершилась неудачно */ exit(); if (unlink(argv[1]) == -1) /* удалить связь с только что открытым файлом */ exit(); if (stat(argv[1], &statbuf) == -1) /* узнать состояние файла по имени */ printf("stat %s завершилась неудачно\n", argv[1]); /* как и следовало бы */ else printf("stat %s завершилась успешно!\n", argv[1]); if (fstat(fd, &statbuf) == -1) /* узнать состояние файла по идентификатору */ printf("fstat %s сработала неудачно!\n", argv[1]); else printf("fstat %s завершилась успешно\n", argv[1]); /* как и следовало бы */ while (read(fd, buf, sizeof(buf)) › 0) /* чтение открытого файла с удаленной связью */ printf("%1024s", buf); /* вывод на печать поля размером 1 Кбайт */ } Рисунок 5.33. Удаление связи с открытым файлом Процесс может удалить связь файла в то время, как другому процессу нужно, чтобы файл оставался открытым. (Даже процесс, удаляющий связь, может быть процессом, выполнившим это открытие). Поскольку ядро снимает с индекса блокировку по окончании выполнения функции open, функция unlink завершится успешно. Ядро будет выполнять алгоритм unlink точно так же, как если бы файл не был открыт, и удалит из каталога запись о файле. Теперь по имени удаленной связи к файлу не сможет обратиться никакой другой процесс. Однако, так как системная функция open увеличила значение счетчика ссылок в индексе, ядро не очищает содержимое файла при выполнении алгоритма iput перед завершением функции unlink. Поэтому процесс, открывший файл, может производить над файлом все обычные действия по его дескриптору, включая чтение из файла и запись в файл. Но когда процесс закрывает файл, значение счетчика ссылок в алгоритме iput становится равным 0, и ядро очищает содержимое файла. Короче говоря, процесс, открывший файл, продолжает работу так, как если бы функция unlink не выполнялась, а unlink, в свою очередь, работает так, как если бы файл не был открыт. Другие системные функции также могут продолжать выполняться в процессе, открывшем файл. В приведенном на Рисунке 5.33 примере процесс открывает файл, указанный в качестве параметра, и затем удаляет связь только что открытого файла. Функция stat завершится неудачно, поскольку первоначальное имя после unlink больше не указывает на файл (предполагается, что тем временем никакой другой процесс не создал файл с тем же именем), но функция fstat завершится успешно, так как она выбирает индекс по дескриптору файла. Процесс выполняет цикл, считывая на каждом шаге по 1024 байта и пересылая файл в стандартный вывод. Когда при чтении будет обнаружен конец файла, процесс завершает работу: после завершения процесса файл перестает существовать. Процессы часто создают временные файлы и сразу же удаляют связь с ними; они могут продолжать ввод-вывод в эти файлы, но имена файлов больше не появляются в иерархии каталогов. Если процесс по какой-либо причине завершается аварийно, он не оставляет от временных файлов никакого следа. 5.17 АБСТРАКТНЫЕ ОБРАЩЕНИЯ К ФАЙЛОВЫМ СИСТЕМАМ Уайнбергером было введено понятие «тип файловой системы» для объяснения механизма работы принадлежавшей ему сетевой файловой системы (см. краткое описание этого механизма в [Killian 84]) и в позднейшей версии системы V поддерживаются основополагающие принципы его схемы. Наличие типа файловой системы дает ядру возможность поддерживать одновременно множество файловых систем, таких как сетевые файловые системы (глава 13) или даже файловые системы из других операционных систем. Процессы пользуются для обращения к файлам обычными функциями системы UNIX, а ядро устанавливает соответствие между общим набором файловых операций и операциями, специфичными для каждого типа файловой системы. 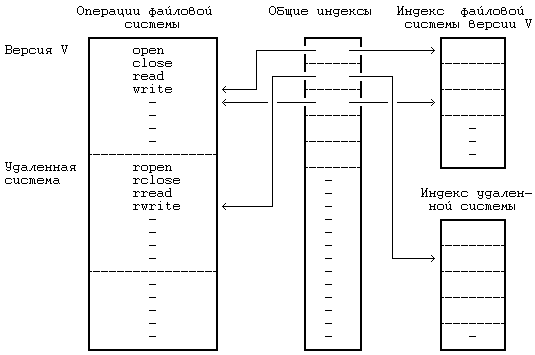 Рисунок 5.34. Индексы для файловых систем различных типов Индекс выступает интерфейсом между абстрактной файловой системой и отдельной файловой системой. Общая копия индекса в памяти содержит информацию, не зависящую от отдельной файловой системы, а также указатель на частный индекс файловой системы, который уже содержит информацию, специфичную для нее. Частный индекс файловой системы содержит такую информацию, как права доступа и расположение блоков, а общий индекс содержит номер устройства, номер индекса на диске, тип файла, размер, информацию о владельце и счетчик ссылок. Другая частная информация, описывающая отдельную файловую систему, содержится в суперблоке и структуре каталогов. На Рисунке 5.34 изображены таблица общих индексов в памяти и две таблицы частных индексов отдельных файловых систем, одна для структур файловой системы версии V, а другая для индекса удаленной (сетевой) системы. Предполагается, что последний индекс содержит достаточно информации для того, чтобы идентифицировать файл, находящийся в удаленной системе. У файловой системы может отсутствовать структура, подобная индексу; но исходный текст программ отдельной файловой системы позволяет создать объектный код, удовлетворяющий семантическим требованиям файловой системы UNIX и назначающий свой «индекс», который соответствует общему индексу, назначаемому ядром. Файловая система каждого типа имеет некую структуру, в которой хранятся адреса функций, реализующих абстрактные действия. Когда ядру нужно обратиться к файлу, оно вызывает косвенную функцию в зависимости от типа файловой системы и абстрактного действия (см. Рисунок 5.34). Примерами абстрактных действий являются: открытие и закрытие файла, чтение и запись данных, возвращение индекса для компоненты имени файла (подобно namei и iget), освобождение индекса (подобно iput), коррекция индекса, проверка прав доступа, установка атрибутов файла (прав доступа к нему), а также монтирование и демонтирование файловых систем. В главе 13 будет проиллюстрировано использование системных абстракций при рассмотрении распределенной файловой системы. 5.18 СОПРОВОЖДЕНИЕ ФАЙЛОВОЙ СИСТЕМЫ Ядро поддерживает целостность системы в своей обычной работе. Тем не менее, такие чрезвычайные обстоятельства, как отказ питания, могут привести к фатальному сбою системы, в результате которого содержимое системы утрачивает свою согласованность: большинство данных в файловой системе доступно для использования, но некоторая несогласованность между ними имеет место. Команда fsck проверяет согласованность данных и в случае необходимости вносит в файловую систему исправления. Она обращается к файловой системе через блочный или строковый интерфейс (глава 10) в обход традиционных методов доступа к файлам. В этом разделе рассматриваются некоторые примеры противоречивости данных, которая обнаруживается командой fsck. Дисковый блок может принадлежать более чем одному индексу или списку свободных блоков. Когда файловая система открывается в первый раз, все дисковые блоки находятся в списке свободных блоков. Когда дисковый блок выбирается для использования, ядро удаляет его номер из списка свободных блоков и назначает блок индексу. Ядро не может переназначить дисковый блок другому индексу до тех пор, пока блок не будет возвращен в список свободных блоков. Таким образом, дисковый блок может либо находиться в списке свободных блоков, либо быть назначенным одному из индексов. Рассмотрим различные ситуации, могущие иметь место при освобождении ядром дискового блока, принадлежавшего файлу, с возвращением номера блока в суперблок, находящийся в памяти, и при выделении дискового блока новому файлу. Если ядро записывало на диск индекс и блоки нового файла, но перед внесением изменений в индекс прежнего файла на диске произошел сбой, оба индекса будут адресовать к одному и тому же номеру дискового блока. Подобным же образом, если ядро переписывало на диск суперблок и его списки свободных ресурсов и перед переписью старого индекса случился сбой, дисковый блок появится одновременно и в списке свободных блоков, и в старом индексе. Если блок отсутствует как в списке свободных блоков, так и в файле, файловая система является несогласованной, ибо, как уже говорилось выше, все блоки обязаны где-нибудь присутствовать. Такая ситуация могла бы произойти, если бы блок был удален из файла и помещен в список свободных блоков в суперблоке. Если производилась запись прежнего файла на диск и система дала сбой перед записью суперблока, блок будет отсутствовать во всех списках, хранящихся на диске. Индекс может иметь счетчик связей с ненулевым значением при том, что его номер отсутствует во всех каталогах файловой системы. Все файлы, за исключением каналов (непоименованных), должны присутствовать в древовидной структуре файловой системы. Если система дала сбой после создания канала или обычного файла, но перед созданием соответствующей этому каналу или файлу точки входа в каталог, индекс будет иметь в поле счетчика связей установленное значение, пусть даже он явно не присутствует в файловой системе. Еще одна проблема может возникнуть, если с помощью функции unlink была удалена связь каталога без проверки удаления из каталога всех содержащихся в нем связей с отдельными файлами. Если формат индекса неверен (например, если значение поля типа файла не определено), значит где-то имеется ошибка. Это может произойти, если администратор смонтировал файловую систему, которая отформатирована неправильно. Ядро обращается к тем дисковым блокам, которые, как кажется ядру, содержат индексы, но в действительности оказывается, что они содержат данные. Если номер индекса присутствует в записи каталога, но сам индекс свободен, файловая система является несогласованной, поскольку номер индекса в записи каталога должен быть номером назначенного индекса. Это могло бы произойти, если бы ядро, создавая новый файл и записывая на диск новую точку входа в каталог, не успела бы скопировать на диск индекс файла из-за сбоя. Также это может случиться, если процесс, удаляя связь файла с каталогом, запишет освободившийся индекс на диск, но не успеет откорректировать каталог из-за сбоя. Возникновение подобных ситуаций можно предотвратить, копируя на диск результаты работы в надлежащем порядке. Если число свободных блоков или свободных индексов, записанное в суперблоке, не совпадает с их количеством на диске, файловая система так же является несогласованной. Итоговая информация в суперблоке всегда должна соответствовать информации о текущем состоянии файловой системы. 5.19 ВЫВОДЫЭтой главой завершается первая часть книги, посвященная рассмотрению особенностей файловой системы. Глава познакомила пользователя с тремя таблицами, принадлежащими ядру: таблицей пользовательских дескрипторов файла, системной таблицей файлов и таблицей монтирования. В ней рассмотрены алгоритмы выполнения системных функций, имеющих отношение к файловой системе, и взаимодействие между этими функциями. Исследованы некоторые абстрактные свойства файловой системы, позволяющие системе UNIX поддерживать файловые системы различных типов. Наконец, описан механизм выполнения команды fsck, контролирующей целостность и согласованность данных в файловой системе. 5.20 УПРАЖНЕНИЯ1. Рассмотрим программу, приведенную на Рисунке 5.35. Какое значение возвращает каждая операция read и что при этом содержится в буфере? Опишите, что происходит в ядре во время выполнения каждого вызова read. 2. Вновь вернемся к программе на Рисунке 5.35 и предположим, что оператор lseek(fd, 9000L, 0); стоит перед первым обращением к функции read. Что ищет процесс и что при этом происходит в ядре? 3. Процесс может открыть файл для работы в режиме добавления записей в конец файла, при этом имеется в виду, что каждая операция записи располагает данные по адресу смещения, указывающего текущий конец файла. Таким образом, два процесса могут открыть файл для работы в режиме добавления записей в конец файла и вводить данные, не опасаясь затереть записи друг другу. Что произойдет, если процесс откроет файл в режиме добавления в конец, а записывающую головку установит на начало файла? 4. Библиотека стандартных подпрограмм ввода-вывода повышает эффективность выполнения пользователем операций чтения и записи благодаря буферизации данных в библиотеке и сохранению большого количества модулей обращения к операционной системе, необходимых пользователю. Как бы вы реализовали библиотечные функции fread и fwrite? Что должны делать библиотечные функции fopen и fclose? #include ‹fcntl.h› main() { int fd; char buf[1024]; fd = creat("junk", 0666); lseek(fd, 2000L, 2); /* ищется байт с номером 2000 */ write(fd, "hello", 5); close(fd); fd = open("junk", O_RDONLY); read(fd, buf, 1024); /* читает нули */ read(fd, buf, 1024); /* считывает нечто, отличное от 0 */ read(fd, buf, 1024); } Рисунок 5.35. Считывание нулей и конца файла 5. Если процесс читает данные из файла последовательно, ядро запоминает значение блока, прочитанного с продвижением, в индексе, хранящемся в памяти. Что произойдет, если несколько процессов будут одновременно вести последовательное считывание данных из одного и того же файла? #include ‹fcntl.h› main() { int fd; char buf[256]; fd = open("/etc/passwd", O_RDONLY); if (read(fd, buf, 1024) ‹ 0) printf("чтение завершается неудачно\n"); } Рисунок 5.36. Чтение большой порции данных в маленький буфер 6. Рассмотрим программу, приведенную на Рисунке 5.36. Что произойдет в результате выполнения программы? Обоснуйте ответ. Что произошло бы, если бы объявление массива buf было вставлено между объявлениями двух других массивов размером 1024 элемента каждый? Каким образом ядро устанавливает, что прочитанная порция данных слишком велика для буфера? *7. В файловой системе BSD разрешается фрагментировать последний блок файла в соответствии со следующими правилами: • Свободные фрагменты отслеживаются в структурах, подобных суперблоку; • Ядро не поддерживает пул ранее выделенных свободных фрагментов, а разбивает на фрагменты в случае необходимости свободный блок; • Ядро может назначать фрагменты блока только для последнего блока в файле; • Если блок разбит на несколько фрагментов, ядро может назначить их различным файлам; • Количество фрагментов в блоке не должно превышать величину, фиксированную для данной файловой системы; • Ядро назначает фрагменты во время выполнения системной функции write. Разработайте алгоритм, присоединяющий к файлу фрагменты блока. Какие изменения должны быть сделаны в индексе, чтобы позволить использование фрагментов? Какие преимущества с системной точки зрения предоставляет использование фрагментов для тех файлов, которые используют блоки косвенной адресации? Не выгоднее ли было бы назначать фрагменты во время выполнения функции close вместо того, чтобы назначать их при выполнении функции write? *8. Вернемся к обсуждению, начатому в главе 4 и касающемуся расположения данных в индексе файла. Для того случая, когда индекс имеет размер дискового блока, разработайте алгоритм, по которому остаток данных файла переписывается в индексный блок, если помещается туда. Сравните этот метод с методом, предложенным для решения предыдущей проблемы. *9. В версии V системы функция fcntl используется для реализации механизма захвата файла и записи и имеет следующий формат: fcntl(fd, cmd, arg); где fd — дескриптор файла, cmd — тип блокирующей операции, а в arg указываются различные параметры, такие как тип блокировки (записи или чтения) и смещения в байтах (см. приложение). К блокирующим операциям относятся • Проверка наличия блокировок, принадлежащих другим процессам, с немедленным возвратом управления в случае обнаружения таких блокировок, • Установка блокировки и приостанов до успешного завершения, • Установка блокировки с немедленным возвратом управления в случае неудачи. Ядро автоматически снимает блокировки, установленные процессом, при закрытии файла. Опишите работу алгоритма, реализующего захват файла и записи. Если блокировки являются обязательными, другим процессам следует запретить доступ к файлу. Какие изменения следует сделать в операциях чтения и записи? *10. Если процесс приостановил свою работу в ожидании снятия с файла блокировки, возникает опасность взаимной блокировки: процесс A может заблокировать файл «one» и попытаться заблокировать файл «two», а процесс B может заблокировать файл «two» и попытаться заблокировать файл «one». Оба процесса перейдут в состояние, при котором они не смогут продолжить свою работу. Расширьте алгоритм решения предыдущей проблемы таким образом, чтобы ядро могло обнаруживать ситуации взаимной блокировки и прерывать выполнение системных функций. Следует ли поручать обнаружение взаимных блокировок ядру? 11. До существования специальной системной функции захвата файла пользователям приходилось прибегать к услугам параллельно действующих процессов для реализации механизма захвата путем вызова системных функций, выполняющих элементарные действия. Какие из системных функций, описанных в этой главе, могли бы использоваться? Какие опасности подстерегают при использовании этих методов? 12. Ричи заявлял (см. [Ritchie 81]), что захвата файла недостаточно для того, чтобы предотвратить путаницу, вызываемую такими программами, как редакторы, которые создают копию файла при редактировании и переписывают первоначальный файл по окончании работы. Объясните, что он имел в виду, и прокомментируйте. 13. Рассмотрим еще один способ блокировки файлов, предотвращающий разрушительные последствия корректировки. Предположим, что в индексе содержится новая установка прав доступа, позволяющая только одному процессу в текущий момент открывать файл для записи и нескольким процессам открывать файл для чтения. Опишите реализацию этого способа. main(argc, argv) int argc; char *argv[]; { if (argc != 2) { printf("введите: команда имя каталога\n"); exit(); } /* права доступа к каталогу: запись, чтение и исполнение разрешены для всех */ /* только суперпользователь может делать следующее */ if (mknod(argv[1], 040777, 0) == -1) printf("mknod завершилась неудачно\n"); } Рисунок 5.37. Каталог, создание которого не завершено *14. Рассмотрим программу (Рисунок 5.37), которая создает каталог с неверным форматом (в каталоге отсутствуют записи с именами "." и ".."). Попробуйте, находясь в этом каталоге, выполнить несколько команд, таких как ls - l, ls - ld, или cd. Что произойдет при этом? 15. Напишите программу, которая выводит для файлов, имена которых указаны в качестве параметров, информацию о владельце, типе файла, правах доступа и времени доступа. Если файл (параметр) является каталогом, программа должна читать записи из каталога и выводить вышеуказанную информацию для всех файлов в каталоге. 16. Предположим, что у пользователя есть разрешение на чтение из каталога, но нет разрешения на исполнение. Что произойдет, если каталог использовать в качестве параметра команды ls, заданной с опцией «-i»? Что будет, если указана опция «-l»? Поясните свои ответы. Ответьте на вопрос, сформулированный для случая, когда есть разрешение на исполнение, но нет разрешения на чтение из каталога. 17. Сравните права доступа, которые должны быть у процесса для выполнения следующих действий, и прокомментируйте: • Для создания нового файла требуется разрешение на запись в каталог. • Для «создания» существующего файла требуется разрешение на запись в файл. • Для удаления связи файла с каталогом требуется разрешение на запись в каталог, а не в файл. *18. Напишите программу, которая навещает все каталоги, начиная с текущего. Как она должна управлять циклами в иерархии каталогов? 19. Выполните программу, приведенную на Рисунке 5.38, и объясните, что при этом происходит в ядре. (Намек: выполните команду pwd, когда программа закончится). 20. Напишите программу, которая заменяет корневой каталог указанным каталогом, и исследуйте дерево каталогов, доступное для этой программы. 21. Почему процесс не может отменить предыдущий вызов функции chroot? Измените конкретную реализацию процесса таким образом, чтобы он мог менять текущее значение корня на предыдущее. Какие у этой возможности преимущества и неудобства? 22. Рассмотрим простой пример канала (Рисунок 5.19), когда процесс записывает в канал строку «hello» и затем считывает ее. Что произошло бы, если бы массив для записи данных в канал имел размер 1024 байта вместо 6 (а объем считываемых за одну операцию данных оставался равным 6)? Что произойдет, если порядок вызова функций read и write в программе изменить, поменяв функции местами? main(argc,argv) int argc; char *argv[]; { if (argc != 2) { printf("нужен 1 аргумент — имя каталога\n"); exit(); } if (chdir(argv[1]) == -1) printf("%s файл не является каталогом\n", argv[1]); } Рисунок 5.38. Пример программы с использованием функции chdir 23. Что произойдет при выполнении программы, иллюстрирующей использование поименованных каналов (Рисунок 5.19), если функция mknod обнаружит, что канал с таким именем уже существует? Как этот момент реализуется ядром? Что произошло бы, если бы вместо подразумеваемых в тексте программы одного считывающего и одного записывающего процессов связь между собой через канал попытались установить несколько считывающих и записывающих процессов? Как в этом случае гарантировалась бы связь одного считывающего процесса с одним записывающим процессом? 24. Открывая поименованный канал для чтения, процесс приостанавливается до тех пор, пока еще один процесс не откроет канал для записи. Почему? Не мог бы процесс успешно пройти функцию open, продолжить работу до того момента, когда им будет предпринята попытка чтения данных из канала, и приостановиться при выполнении функции read? 25. Как бы вы реализовали алгоритм выполнения системной функции dup2 (из версии 7), вызываемой следующим образом: dup2(oldfd, newfd); где oldfd — файловый дескриптор, который дублируется дескриптором newfd? Что произошло бы, если бы дескриптор newfd уже принадлежал открытому файлу? *26. Какие последствия имело бы решение ядра позволить двум процессам одновременно смонтировать одну и ту же файловую систему в двух точках монтирования? 27. Предположим, что один процесс меняет свой текущий каталог на каталог «/mnt/a/b/c», после чего другой процесс в каталоге «/mnt» монтирует файловую систему. Завершится ли функция mount успешно? Что произойдет, если первый процесс выполнит команду pwd? Ядро не позволит функции mount успешно завершиться, если значение счетчика ссылок в индексе каталога «/mnt» превышает 1. Прокомментируйте этот момент. 28. При исполнении алгоритма пересечения точки монтирования по имени «..» в маршруте поиска файла ядро проверяет выполнение трех условий, связанных с точкой монтирования: что номер обнаруженного индекса совпадает с номером корневого индекса, что рабочий индекс является корнем файловой системы и что имя компоненты маршрута поиска — «..». Почему необходимо проверять выполнение всех трех условий? Докажите, что проверки любых двух условий недостаточно для того, чтобы разрешить процессу пересечь точку монтирования. 29. Если пользователь монтирует файловую систему только для чтения, ядро устанавливает соответствующий флаг в суперблоке. Как ядро может воспрепятствовать выполнению операций записи в функциях write, creat, link, unlink, chown и chmod? Какого рода информацию записывают в файловую систему все перечисленные функции? *30. Предположим, что один процесс пытается демонтировать файловую систему, в то время как другой процесс пытается создать в файловой системе новый файл. Только одна из функций umount и creat выполнится успешно. Подробно рассмотрите возникшую конкуренцию. *31. Когда функция umount проверяет отсутствие в файловой системе активных файлов, возникает одна проблема, связанная с тем, что корневой индекс файловой системы, назначаемый при выполнении функции mount с помощью алгоритма iget, имеет счетчик ссылок с положительным значением. Как функция umount сможет убедиться в отсутствии активных файлов и отчитаться перед корнем файловой системы? Рассмотрите два случая: • функция umount освобождает корневой индекс по алгоритму iput перед проверкой активных индексов. (Как функции вернуть этот индекс обратно, если будут обнаружены активные файлы?) • функция umount проверяет отсутствие активных файлов до того, как освободить корневой индекс, и разрешая корневому индексу оставаться активным. (Насколько активным может быть корневой индекс?) 32. Обратите внимание на то, что при выполнении команды ls — ld количество связей с каталогом никогда не равно 1. Почему? 33. Как работает команда mkdir (создать новый каталог)? (Наводящий вопрос: какие номера по завершении выполнения команды имеют индексы для файлов "." и ".."?) *34. Понятие «символические связи» имеет отношение к возможности указания с помощью функции link связей между файлами, принадлежащими к различным файловым системам. С файлом символической связи ассоциирован указатель нового типа; содержимым файла является имя пути поиска того файла, с которым он связан. Опишите реализацию символических связей. *35. Что произойдет, если процесс вызовет функцию unlink("."); Каким будет текущий каталог процесса? Предполагается, что процесс обладает правами суперпользователя. 36. Разработайте системную функцию, которая усекает существующий файл до произвольных размеров, указанных в качестве аргумента, и опишите ее работу. Реализуйте системную функцию, которая позволяла бы пользователю удалять сегмент файла, расположенный между двумя адресами, заданными в виде смещений, и сжимать файл. Напишите программу, которая не вызывала бы эти функции, но обладала бы теми же функциональными возможностями. 37. Опишите все условия, при которых счетчик ссылок в индексе может превышать значение 1. 38. Затрагивая тему абстрактных обращений к файловым системам, ответьте на вопрос: следует ли файловой системе каждого типа иметь личную операцию блокирования, вызываемую из общей программы, или же достаточно общей операции блокирования? Примечания:1 Организации, получившие права на перепродажу с надбавкой к цене за дополнительные услуги, оснащают вычислительную систему прикладными программами, касающимися конкретных областей применения, стремясь удовлетворить требования рынка. Такие организации чаще продают прикладные программы, нежели операционные системы, под управлением которых эти программы работают. 14 Все системные функции возвращают в случае неудачного завершения код -1. Код возврата, равный -1, больше не будет упоминаться при рассмотрении синтаксиса вызова системных функций. 15 В описании вызова системной функции open содержатся три параметра (третий используется при открытии в режиме создания), но программисты обычно используют только первые два из них. Компилятор с языка Си не проверяет правильность количества параметров. В системе первые два параметра и третий (с любым «мусором», что бы ни произошло в стеке) передаются обычно ядру. Ядро не проверяет наличие третьего параметра, если только необходимость в нем не вытекает из значения второго параметра, что позволяет программистам указать только два параметра. 16 Системная функция open имеет два флага, O_CREAT (создание) и O_TRUNC (усечение). Если процесс устанавливает в вызове функции флаг O_CREAT и файл не существует, ядро создаст файл. Если файл уже существует, он не будет усечен, если только не установлен флаг O_TRUNC. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||