|
||||||||||||||||||||||||||||||||||||||
|
|
6.3 КОНТЕКСТ ПРОЦЕССА 6.4.3 Переключение контекста 6.4.4 Сохранение контекста на случай аварийного завершения 6.4.5 Копирование данных между адресным пространством системы и адресным пространством задачи 6.5 УПРАВЛЕНИЕ АДРЕСНЫМ ПРОСТРАНСТВОМ ПРОЦЕССА 6.5.1 Блокировка области и снятие блокировки 6.5.2 Выделение области 6.5.3 Присоединение области к процессу 6.5.6 Освобождение области 6.6.2 Алгоритмы приостанова и возобновления выполнения ГЛАВА 6. СТРУКТУРА ПРОЦЕССОВВ главе 2 были сформулированы характеристики процессов. В настоящей главе на более формальном уровне определяется понятие «контекст процесса» и показывается, каким образом ядро идентифицирует процесс и определяет его местонахождение. В разделе 6.1 описаны модель состояний процессов для системы UNIX и последовательность возможных переходов из состояния в состояние. В ядре находится таблица процессов, каждая запись которой описывает состояние одного из активных процессов в системе. В пространстве процесса хранится дополнительная информация, используемая в управлении протеканием процесса. Запись в таблице процессов и пространство процесса составляют в совокупности контекст процесса. Аспектом контекста процесса, наиболее явно отличающим данный контекст от контекста другого процесса, без сомнения является содержимое адресного пространства процесса. В разделе 6.2 описываются принципы управления распределением памяти для процессов и ядра, а также взаимодействие операционной системы с аппаратными средствами при трансляции виртуальных адресов в физические. Раздел 6.3 посвящен рассмотрению составных элементов контекста процесса, а также описанию алгоритмов управления контекстом процесса. Раздел 6.4 демонстрирует, каким образом осуществляется сохранение контекста процесса ядром в случае прерывания, вызова системной функции или переключения контекста, а также каким образом возобновляется выполнение приостановленного процесса. В разделе 6.5 приводятся различные алгоритмы, используемые в тех системных функциях, которые работают с адресным пространством процесса и которые будут рассмотрены в следующей главе. И, наконец, в разделе 6.6 рассматриваются алгоритмы приостанова и возобновления выполнения процессов. 6.1 СОСТОЯНИЯ ПРОЦЕССА И ПЕРЕХОДЫ МЕЖДУ НИМИКак уже отмечалось в главе 2, время жизни процесса можно теоретически разбить на несколько состояний, описывающих процесс. Полный набор состояний процесса содержится в следующем перечне: 1. Процесс выполняется в режиме задачи. 2. Процесс выполняется в режиме ядра. 3. Процесс не выполняется, но готов к запуску под управлением ядра. 4. Процесс приостановлен и находится в оперативной памяти. 5. Процесс готов к запуску, но программа подкачки (нулевой процесс) должна еще загрузить процесс в оперативную память, прежде чем он будет запущен под управлением ядра. Это состояние будет предметом обсуждения в главе 9 при рассмотрении системы подкачки. 6. Процесс приостановлен и программа подкачки выгрузила его во внешнюю память, чтобы в оперативной памяти освободить место для других процессов. 7. Процесс возвращен из привилегированного режима (режима ядра) в непривилегированный (режим задачи), ядро резервирует его и переключает контекст на другой процесс. Об отличии этого состояния от состояния 3 (готовность к запуску) пойдет речь ниже. 8. Процесс вновь создан и находится в переходном состоянии; процесс существует, но не готов к выполнению, хотя и не приостановлен. Это состояние является начальным состоянием всех процессов, кроме нулевого. 9. Процесс вызывает системную функцию exit и прекращает существование. Однако, после него осталась запись, содержащая код выхода, и некоторая хронометрическая статистика, собираемая родительским процессом. Это состояние является последним состоянием процесса. Рисунок 6.1 представляет собой полную диаграмму переходов процесса из состояния в состояние. Рассмотрим с помощью модели переходов типичное поведение процесса. Ситуации, которые будут обсуждаться, несколько искусственны и процессы не всегда имеют дело с ними, но эти ситуации вполне применимы для иллюстрации различных переходов. Начальным состоянием модели является создание процесса родительским процессом с помощью системной функции fork; из этого состояния процесс неминуемо переходит в состояние готовности к запуску (3 или 5). Для простоты предположим, что процесс перешел в состояние «готовности к запуску в памяти» (3). Планировщик процессов в конечном счете выберет процесс для выполнения и процесс перейдет в состояние «выполнения в режиме ядра», где доиграет до конца роль, отведенную ему функцией fork. 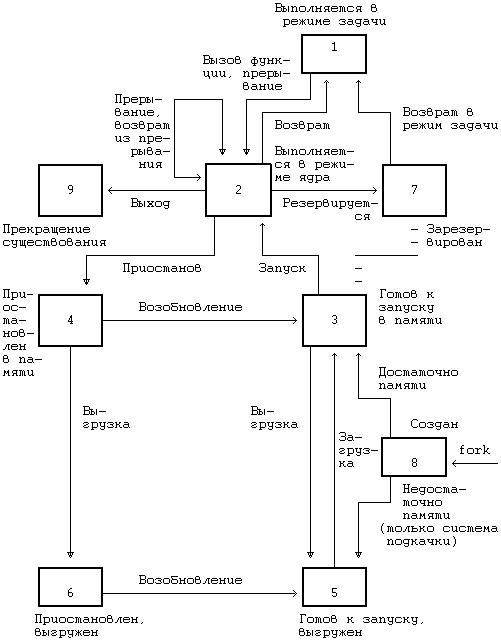 Рисунок 6.1. Диаграмма переходов процесса из состояния в состояние После всего этого процесс может перейти в состояние «выполнения в режиме задачи». По прохождении определенного периода времени может произойти прерывание работы процессора по таймеру и процесс снова перейдет в состояние «выполнения в режиме ядра». Как только программа обработки прерывания закончит работу, ядру может понадобиться подготовить к запуску другой процесс, поэтому первый процесс перейдет в состояние «резервирования», уступив дорогу второму процессу. Состояние «резервирования» в действительности не отличается от состояния «готовности к запуску в памяти» (пунктирная линия на рисунке, соединяющая между собой оба состояния, подчеркивает их эквивалентность), но они выделяются в отдельные состояния, чтобы подчеркнуть, что процесс, выполняющийся в режиме ядра, может быть зарезервирован только в том случае, если он собирается вернуться в режим задачи. Следовательно, ядро может при необходимости подкачивать процесс из состояния «резервирования». При известных условиях планировщик выберет процесс для исполнения и тот снова вернется в состояние «выполнения в режиме задачи». Когда процесс выполняет вызов системной функции, он из состояния «выполнения в режиме задачи» переходит в состояние «выполнения в режиме ядра». Предположим, что системной функции требуется ввод-вывод с диска и поэтому процесс вынужден дожидаться завершения ввода-вывода. Он переходит в состояние «приостанова в памяти», в котором будет находиться до тех пор, пока не получит извещения об окончании ввода-вывода. Когда ввод-вывод завершится, произойдет аппаратное прерывание работы центрального процессора и программа обработки прерывания возобновит выполнение процесса, в результате чего он перейдет в состояние «готовности к запуску в памяти». Предположим, что система выполняет множество процессов, которые одновременно никак не могут поместиться в оперативной памяти, и программа подкачки (нулевой процесс) выгружает один процесс, чтобы освободить место для другого процесса, находящегося в состоянии «готов к запуску, но выгружен». Первый процесс, выгруженный из оперативной памяти, переходит в то же состояние. Когда программа подкачки выбирает наиболее подходящий процесс для загрузки в оперативную память, этот процесс переходит в состояние «готовности к запуску в памяти». Планировщик выбирает процесс для исполнения и он переходит в состояние «выполнения в режиме ядра». Когда процесс завершается, он исполняет системную функцию exit, последовательно переходя в состояния «выполнения в режиме ядра» и, наконец, в состояние «прекращения существования». Процесс может управлять некоторыми из переходов на уровне задачи. Во-первых, один процесс может создать другой процесс. Тем не менее, в какое из состояний процесс перейдет после создания (т. е. в состояние «готов к выполнению, находясь в памяти» или в состояние «готов к выполнению, но выгружен») зависит уже от ядра. Процессу эти состояния не подконтрольны. Во-вторых, процесс может обратиться к различным системным функциям, чтобы перейти из состояния «выполнения в режиме задачи» в состояние «выполнения в режиме ядра», а также перейти в режим ядра по своей собственной воле. Тем не менее, момент возвращения из режима ядра от процесса уже не зависит; в результате каких-то событий он может никогда не вернуться из этого режима и из него перейдет в состояние «прекращения существования» (см. раздел 7.2, где говорится о сигналах). Наконец, процесс может завершиться с помощью функции exit по своей собственной воле, но как указывалось ранее, внешние события могут потребовать завершения процесса без явного обращения к функции exit. Все остальные переходы относятся к жестко закрепленной части модели, закодированной в ядре, и являются результатом определенных событий, реагируя на них в соответствии с правилами, сформулированными в этой и последующих главах. Некоторые из правил уже упоминались: например, то, что процесс может выгрузить другой процесс, выполняющийся в ядре. Две принадлежащие ядру структуры данных описывают процесс: запись в таблице процессов и пространство процесса. Таблица процессов содержит поля, которые должны быть всегда доступны ядру, а пространство процесса — поля, необходимость в которых возникает только у выполняющегося процесса. Поэтому ядро выделяет место для пространства процесса только при создании процесса: в нем нет необходимости, если записи в таблице процессов не соответствует конкретный процесс. Запись в таблице процессов состоит из следующих полей: • Поле состояния, которое идентифицирует состояние процесса. • Поля, используемые ядром при размещении процесса и его пространства в основной или внешней памяти. Ядро использует информацию этих полей для переключения контекста на процесс, когда процесс переходит из состояния «готов к выполнению, находясь в памяти» в состояние «выполнения в режиме ядра» или из состояния «резервирования» в состояние «выполнения в режиме задачи». Кроме того, ядро использует эту информацию при перекачки процессов из и в оперативную память (между двумя состояниями «в памяти» и двумя состояниями «выгружен»). Запись в таблице процессов содержит также поле, описывающее размер процесса и позволяющее ядру планировать выделение пространства для процесса. • Несколько пользовательских идентификаторов (UID), устанавливающих различные привилегии процесса. Поля UID, например, описывают совокупность процессов, могущих обмениваться сигналами (см. следующую главу). • Идентификаторы процесса (PID), указывающие взаимосвязь между процессами. Значения полей PID задаются при переходе процесса в состояние «создан» во время выполнения функции fork. • Дескриптор события (устанавливается тогда, когда процесс приостановлен). В данной главе будет рассмотрено использование дескриптора события в алгоритмах функций sleep и wakeup. • Параметры планирования, позволяющие ядру устанавливать порядок перехода процессов из состояния «выполнения в режиме ядра» в состояние «выполнения в режиме задачи». • Поле сигналов, в котором перечисляются сигналы, посланные процессу, но еще не обработанные (раздел 7.2). • Различные таймеры, описывающие время выполнения процесса и использование ресурсов ядра и позволяющие осуществлять слежение за выполнением и вычислять приоритет планирования процесса. Одно из полей является таймером, который устанавливает пользователь и который необходим для посылки процессу сигнала тревоги (раздел 8.3). Пространство процесса содержит поля, дополнительно характеризующие состояния процесса. В предыдущих главах были рассмотрены последние семь из приводимых ниже полей пространства процесса, которые мы для полноты вновь кратко перечислим: • Указатель на таблицу процессов, который идентифицирует запись, соответствующую процессу. • Пользовательские идентификаторы, устанавливающие различные привилегии процесса, в частности, права доступа к файлу (см. раздел 7.6). • Поля таймеров, хранящие время выполнения процесса (и его потомков) в режиме задачи и в режиме ядра. • Вектор, описывающий реакцию процесса на сигналы. • Поле операторского терминала, идентифицирующее «регистрационный терминал», который связан с процессом. • Поле ошибок, в которое записываются ошибки, имевшие место при выполнении системной функции. • Поле возвращенного значения, хранящее результат выполнения системной функции. • Параметры ввода-вывода: объем передаваемых данных, адрес источника (или приемника) данных в пространстве задачи, смещения в файле (которыми пользуются операции ввода-вывода) и т. д. • Имена текущего каталога и текущего корня, описывающие файловую систему, в которой выполняется процесс. • Таблица пользовательских дескрипторов файла, которая описывает файлы, открытые процессом. • Поля границ, накладывающие ограничения на размерные характеристики процесса и на размер файла, в который процесс может вести запись. • Поле прав доступа, хранящее двоичную маску установок прав доступа к файлам, которые создаются процессом. Пространство состояний процесса и переходов между ними рассматривалось в данном разделе на логическом уровне. Каждое состояние имеет также физические характеристики, управляемые ядром, в частности, виртуальное адресное пространство процесса. Следующий раздел посвящен описанию модели распределения памяти; в остальных разделах состояния процесса и переходы между ними рассматриваются на физическом уровне, особое внимание при этом уделяется состояниям «выполнения в режиме задачи», «выполнения в режиме ядра», «резервирования» и «приостанова (в памяти)». В следующей главе затрагиваются состояния «создания» и «прекращения существования», а в главе 8 — состояние «готовности к запуску в памяти». В главе 9 обсуждаются два состояния выгруженного процесса и организация подкачки по обращению. 6.2 ФОРМАТ ПАМЯТИ СИСТЕМЫПредположим, что физическая память машины имеет адреса, начиная с 0 и кончая адресом, равным объему памяти в байтах. Как уже отмечалось в главе 2, процесс в системе UNIX состоит из трех логических секций: команд, данных и стека. (Общую память, которая рассматривается в главе 11, можно считать в данном контексте частью секции данных). В секции команд хранится набор машинных инструкций, исполняемых под управлением процесса; адресами в секции команд выступают адреса команд (для команд перехода и обращений к подпрограммам), адреса данных (для обращения к глобальным переменным) и адреса стека (для обращения к структурам данных, которые локализованы в подпрограммах). Если адреса в сгенерированном коде трактовать как адреса в физической памяти, два процесса не смогут параллельно выполняться, если их адреса перекрываются. Компилятор мог бы генерировать адреса, непересекающиеся у разных программ, но на универсальных ЭВМ такой порядок не практикуется, поскольку объем памяти машины ограничен, а количество транслируемых программы неограничено. Даже если для того, чтобы избежать излишнего пересечения адресов в процессе их генерации, машина будет использовать некоторый набор эвристических процедур, подобная реализация не будет достаточно гибкой и не сможет удовлетворять предъявляемым к ней требованиям. Поэтому компилятор генерирует адреса для виртуального адресного пространства заданного диапазона, а устройство управления памятью, называемое диспетчером памяти, транслирует виртуальные адреса, сгенерированные компилятором, в адреса ячеек, расположенных в физической памяти. Компилятору нет необходимости знать, в какое место в памяти ядро потом загрузит выполняемую программу. На самом деле, в памяти одновременно могут существовать несколько копий программы: все они могут выполняться, используя одни и те же виртуальные адреса, фактически же ссылаясь на разные физические ячейки. Те подсистемы ядра и аппаратные средства, которые сотрудничают в трансляции виртуальных адресов в физические, образуют подсистему управления памятью. 6.2.1 ОбластиЯдро в версии V делит виртуальное адресное пространство процесса на совокупность логических областей. Область — это непрерывная зона виртуального адресного пространства процесса, рассматриваемая в качестве отдельного объекта для совместного использования и защиты. Таким образом, команды, данные и стек обычно образуют автономные области, принадлежащие процессу. Несколько процессов могут использовать одну и ту же область. Например, если несколько процессов выполняют одну и ту же программу, вполне естественно, что они используют одну и ту же область команд. Точно так же, несколько процессов могут объединиться и использовать общую область разделяемой памяти. Ядро поддерживает таблицу областей и выделяет запись в таблице для каждой активной области в системе. В разделе 6.5 описываются поля таблицы областей и операции над областями более подробно, но на данный момент предположим, что таблица областей содержит информацию, позволяющую определить местоположение области в физической памяти. Каждый процесс имеет частную таблицу областей процесса. Записи этой таблицы могут располагаться, в зависимости от конкретной реализации, в таблице процессов, в адресном пространстве процесса или в отдельной области памяти; для простоты предположим, что они являются частью таблицы процессов. Каждая запись частной таблицы областей содержит указатель на соответствующую запись общей таблицы областей и первый виртуальный адрес процесса в данной области. Разделяемые области могут иметь разные виртуальные адреса в каждом процессе. Запись частной таблицы областей также содержит поле прав доступа, в котором указывается тип доступа, разрешенный процессу: только чтение, только запись или только исполнение. Частная таблица областей и структура области аналогичны таблице файлов и структуре индекса в файловой системе: несколько процессов могут совместно использовать адресное пространство через область, подобно тому, как они разделяют доступ к файлу с помощью индекса; каждый процесс имеет доступ к области благодаря использованию записи в частной таблице областей, точно так же он обращается к индексу, используя соответствующие записи в таблице пользовательских дескрипторов файла и в таблице файлов, принадлежащей ядру. На Рисунке 6.2 изображены два процесса, A и B, показаны их области, частные таблицы областей и виртуальные адреса, в которых эти области соединяются. Процессы разделяют область команд 'a' с виртуальными адресами 8К и 4К соответственно. Если процесс A читает ячейку памяти с адресом 8К, а процесс 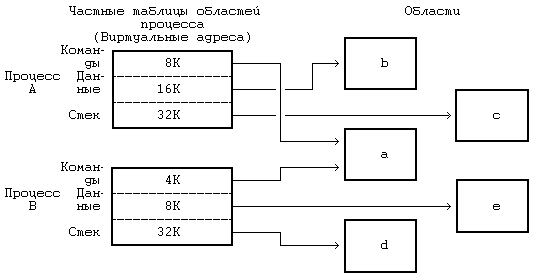 Рисунок 6.2. Процессы и области B читает ячейку с адресом 4К, то они читают одну и ту же ячейку в области 'a'. Область данных и область стека у каждого процесса свои. Область является понятием, не зависящим от способа реализации управления памятью в операционной системе. Управление памятью представляет собой совокупность действий, выполняемых ядром с целью повышения эффективности совместного использования оперативной памяти процессами. Примерами способов управления памятью могут служить рассматриваемые в главе 9 замещение страниц памяти и подкачка по обращению. Понятие области также не зависит и от собственно распределения памяти: например, от того, делится ли память на страницы или на сегменты. С тем, чтобы заложить фундамент для перехода к описанию алгоритмов подкачки по обращению (глава 9), все приводимые здесь рассуждения относятся, в первую очередь, к организации памяти, базирующейся на страницах, однако это не предполагает, что система управления памятью основывается на указанных алгоритмах. 6.2.2 Страницы и таблицы страницВ этом разделе описывается модель организации памяти, которой мы будем пользоваться на протяжении всей книги, но которая не является особенностью системы UNIX. В организации памяти, базирующейся на страницах, физическая память разделяется на блоки одинакового размера, называемые страницами. Обычный размер страниц составляет от 512 байт до 4 Кбайт и определяется конфигурацией технических средств. Каждая адресуемая ячейка памяти содержится в некоторой странице и, следовательно, каждая ячейка памяти может адресоваться парой (номер страницы, смещение внутри страницы в байтах). Например, если объем машинной памяти составляет 2 в 32-й степени байт, а размер страницы 1 Кбайт, общее число страниц — 2 в 22-й степени; можно считать, что каждый 32-разрядный адрес состоит из 22-разрядного номера страницы и 10-разрядного смещения внутри страницы (Рисунок 6.3). Когда ядро назначает области физические страницы памяти, необходимости в назначении смежных страниц и вообще в соблюдении какой-либо очередности при назначении не возникает. Целью страничной организации памяти является повышение гибкости назначения физической памяти, которое строится по аналогии с назначением дисковых блоков файлам в файловой системе. Как и при назначении блоков файлу, так и при назначении области страниц памяти, преследуется задача повышения гибкости и сокращения неиспользуемого (вследствие фрагментации) пространства памяти.
Рисунок 6.3. Адресация физической памяти по страницам
Рисунок 6.4. Отображение логических номеров страниц на физические Ядро устанавливает соотношение между виртуальными адресами области и машинными физическими адресами посредством отображения логических номеров страниц в области на физические номера страниц в машине, как это показано на Рисунке 6.4. Поскольку область это непрерывное пространство виртуальных адресов программы, логический номер страницы служит указателем на элемент массива физических номеров страниц. Запись таблицы областей содержит указатель на таблицу физических номеров страниц, именуемую таблицей страниц. Записи таблицы страниц содержат машинно-зависимую информацию, такую как права доступа на чтение или запись страницы. Ядро поддерживает таблицы страниц в памяти и обращается к ним так же, как и ко всем остальным структурам данных ядра. На Рисунке 6.5 приведен пример отображения процесса в физические адреса памяти. Пусть размер страницы составляет 1 Кбайт и пусть процессу нужно обратиться к объекту в памяти, имеющему виртуальный адрес 68432. Из таблицы областей видно, что виртуальный адрес начала области стека — 65536 (64К), если предположить, что стек растет в направлении увеличения адресов. После вычитания этого адреса из адреса 68432 получаем смещение в байтах внутри области, равное 2896. Так как каждая страница имеет размер 1 Кбайт, адрес указывает со смещением 848 на 2-ю (начиная с 0) страницу области, расположенной по физическому адресу 986К. В разделе 6.5.5 (где идет речь о загрузке области) рассматривается случай, когда запись таблицы страниц помечается «пустой». В современных машинах используются разнообразные аппаратные регистры и кеши, которые повышают скорость выполнения вышеописанной процедуры трансляции адресов и без которых пересылки в памяти и адресные вычисления чересчур бы замедлились. Возобновляя выполнение процесса, ядро посредством загрузки соответствующих регистров сообщает техническим средствам управления памятью о том, в каких физических адресах выполняется процесс и где располагаются таблицы страниц. Поскольку такие операции являются машинно-зависимыми и в разных версиях реализуются по-разному, здесь мы их рассматривать не будем. Часть вопросов, связанных с архитектурой вычислительных систем, затрагивается в упражнениях. 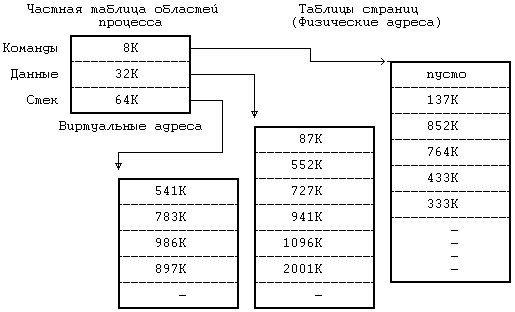 Рисунок 6.5. Преобразование виртуальных адресов в физические Организацию управления памятью попробуем пояснить на следующем простом примере. Пусть память разбита на страницы размером 1 Кбайт каждая, обращение к которым осуществляется через описанные ранее таблицы страниц. Регистры управления памятью в системе группируются по три; первый регистр в тройке содержит адрес таблицы страниц в физической памяти, второй регистр содержит первый виртуальный адрес, отображаемый с помощью тройки регистров, третий регистр содержит управляющую информацию, такую как номера страниц в таблице страниц и права доступа к страницам (только чтение, чтение и запись). Такая модель соответствует вышеописанной модели области. Когда ядро готовит процесс к выполнению, оно загружает тройки регистров соответствующей информацией из записей частной таблицы областей процесса. Если процесс обращается к ячейкам памяти, расположенным за пределами принадлежащего ему виртуального пространства, создается исключительная ситуация. Например, если область команд имеет размер 16 Кбайт (Рисунок 6.5), а процесс обращается к виртуальному адресу 26К, создается исключительная ситуация, обрабатываемая операционной системой. То же самое происходит, если процесс пытается обратиться к памяти, не имея соответствующих прав доступа, например, пытается записать адрес в защищенную от записи область команд. И в том, и в другом примере процесс обычно завершается (более подробно об этом в следующей главе). 6.2.3 Размещение ядраНесмотря на то, что ядро работает в контексте процесса, отображение виртуальных адресов, связанных с ядром, осуществляется независимо от всех процессов. Программы и структуры данных ядра резидентны в системе и совместно используются всеми процессами. При запуске системы происходит загрузка программ ядра в память с установкой соответствующих таблиц и регистров для отображения виртуальных адресов ядра в физические. Таблицы страниц для ядра имеют структуру, аналогичную структуре таблицы страниц, связанной с процессом, а механизмы отображения виртуальных адресов ядра похожи на механизмы, используемые для отображения пользовательских адресов. На многих машинах виртуальное адресное пространство процесса разбивается на несколько классов, в том числе системный и пользовательский, и каждый класс имеет свои собственные таблицы страниц. При работе в режиме ядра система разрешает доступ к адресам ядра, при работе же в режиме задачи такого рода доступ запрещен. Поэтому, когда в результате прерывания или выполнения системной функции происходит переход из режима задачи в режим ядра, операционная система по договоренности с техническими средствами разрешает ссылки на адреса ядра, а при возврате в режим ядра эти ссылки уже запрещены. В других машинах можно менять преобразование виртуальных адресов, загружая специальные регистры во время работы в режиме ядра. На Рисунке 6.6 приведен пример, в котором виртуальные адреса от 0 до 4М-1 принадлежат ядру, а начиная с 4М — процессу. Имеются две группы регистров управления памятью, одна для адресов ядра и одна для адресов процесса, причем каждой группе соответствует таблица страниц, хранящая номера физических страниц со ссылкой на адреса виртуальных страниц. Адресные ссылки с использованием группы регистров ядра допускаются системой только в режиме ядра; следовательно, для перехода между режимом ядра и режимом задачи требуется только, чтобы система разрешила или запретила адресные ссылки с использованием группы регистров ядра. В некоторых системах ядро загружается в память таким образом, что большая часть виртуальных адресов ядра совпадает с физическими адресами и функция преобразования виртуальных адресов в физические превращается в функцию тождественности. Работа с пространством процесса, тем не менее, требует, чтобы преобразование виртуальных адресов в физические производилось ядром. 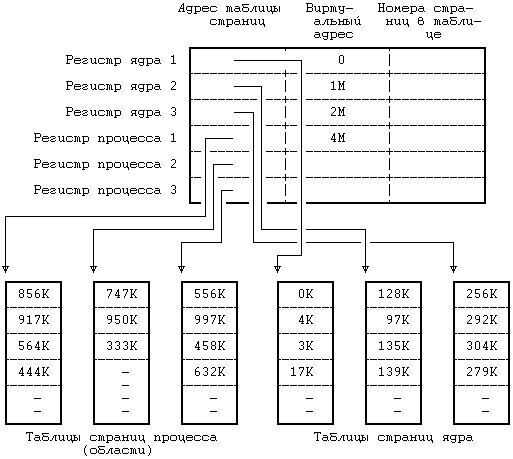 Рисунок 6.6. Переключение режима работы с непривилегированного (режима задачи) на привилегированный (режим ядра) 6.2.4 Пространство процессаКаждый процесс имеет свое собственное пространство, однако ядро обращается к пространству выполняющегося процесса так, как если бы в системе оно было единственным. Ядро подбирает для текущего процесса карту трансляции виртуальных адресов, необходимую для работы с пространством процесса. При компиляции загрузчик назначает переменной 'u' (имени пространства процесса) фиксированный виртуальный адрес. Этот адрес известен остальным компонентам ядра, в частности модулю, выполняющему переключение контекста (раздел 6.4.3). Ядру также известно, какие таблицы управления памятью используются при трансляции виртуальных адресов, принадлежащих пространству процесса, и благодаря этому ядро может быстро перетранслировать виртуальный адрес пространства процесса в другой физический адрес. По одному и тому же виртуальному адресу ядро может получить доступ к двум разным физическим адресам, описывающим пространства двух процессов. Процесс имеет доступ к своему пространству, когда выполняется в режиме ядра, но не тогда, когда выполняется в режиме задачи. Поскольку ядро в каждый момент времени работает только с одним пространством процесса, используя для доступа виртуальный адрес, пространство процесса частично описывает контекст процесса, выполняющегося в системе. Когда ядро выбирает процесс для исполнения, оно ищет в физической памяти соответствующее процессу пространство и делает его доступным по виртуальному адресу. 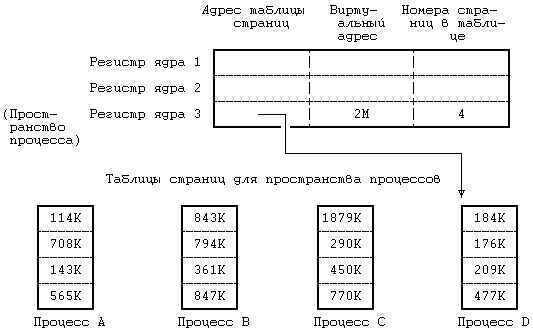 Рисунок 6.7. Карта памяти пространства процесса в ядре Предположим, например, что пространство процесса имеет размер 4 Кбайта и помещается по виртуальному адресу 2М. На Рисунке 6.7 показана карта памяти, где первые два регистра из группы относятся к программам и данным ядра (адреса и указатели не показаны), а третий регистр адресует к пространству процесса D. Если ядру нужно обратиться к пространству процесса A, оно копирует связанную с этим пространством информацию из соответствующей таблицы страниц в третий регистр. В любой момент третий регистр ядра описывает пространство текущего процесса, но ядро может сослаться на пространство другого процесса, переписав записи в таблице страниц с новым адресом. Информация в регистрах 1 и 2 для ядра неизменна, поскольку все процессы совместно используют программы и данные ядра. 6.3 КОНТЕКСТ ПРОЦЕССА Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательский контекст, регистровый контекст и системный контекст[17]. Пользовательский контекст состоит из команд и данных процесса, стека задачи и содержимого совместно используемого пространства памяти в виртуальных адресах процесса. Те части виртуального адресного пространства процесса, которые периодически отсутствуют в оперативной памяти вследствие выгрузки или замещения страниц, также включаются в пользовательский контекст. Регистровый контекст состоит из следующих компонент: • Счетчика команд, указывающего адрес следующей команды, которую будет выполнять центральный процессор; этот адрес является виртуальным адресом внутри пространства ядра или пространства задачи. • Регистра состояния процессора (PS), который указывает аппаратный статус машины по отношению к процессу. Регистр PS, например, обычно содержит подполя, которые указывают, является ли результат последних вычислений нулевым, положительным или отрицательным, переполнен ли регистр с установкой бита переноса и т. д. Операции, влияющие на установку регистра PS, выполняются для отдельного процесса, потому-то в регистре PS и содержится аппаратный статус машины по отношению к процессу. В других имеющих важное значение подполях регистра PS указывается текущий уровень прерывания процессора, а также текущий и предыдущий режимы выполнения процесса (режим ядра/задачи). По значению подполя текущего режима выполнения процесса устанавливается, может ли процесс выполнять привилегированные команды и обращаться к адресному пространству ядра. • Указателя вершины стека, в котором содержится адрес следующего элемента стека ядра или стека задачи, в соответствии с режимом выполнения процесса. В зависимости от архитектуры машины указатель вершины стека показывает на следующий свободный элемент стека или на последний используемый элемент. От архитектуры машины также зависит направление увеличения стека (к старшим или младшим адресам), но для нас сейчас эти вопросы несущественны. • Регистров общего назначения, в которых содержится информация, сгенерированная процессом во время его выполнения. Чтобы облегчить последующие объяснения, выделим среди них два регистра — регистр 0 и регистр 1 — для дополнительного использования при передаче информации между процессами и ядром. Системный контекст процесса имеет «статическую часть» (первые три элемента в нижеследующем списке) и «динамическую часть» (последние два элемента). На протяжении всего времени выполнения процесс постоянно располагает одной статической частью системного контекста, но может иметь переменное число динамических частей. Динамическую часть системного контекста можно представить в виде стека, элементами которого являются контекстные уровни, которые помещаются в стек ядром или выталкиваются из стека при наступлении различных событий. Системный контекст включает в себя следующие компоненты: • Запись в таблице процессов, описывающая состояние процесса (раздел 6.1) и содержащая различную управляющую информацию, к которой ядро всегда может обратиться. • Часть адресного пространства задачи, выделенная процессу, где хранится управляющая информация о процессе, доступная только в контексте процесса. Общие управляющие параметры, такие как приоритет процесса, хранятся в таблице процессов, поскольку обращение к ним должно производиться за пределами контекста процесса. • Записи частной таблицы областей процесса, общие таблицы областей и таблицы страниц, необходимые для преобразования виртуальных адресов в физические, в связи с чем в них описываются области команд, данных, стека и другие области, принадлежащие процессу. Если несколько процессов совместно используют общие области, эти области входят составной частью в контекст каждого процесса, поскольку каждый процесс работает с этими областями независимо от других процессов. В задачи управления памятью входит идентификация участков виртуального адресного пространства процесса, не являющихся резидентными в памяти. • Стек ядра, в котором хранятся записи процедур ядра, если процесс выполняется в режиме ядра. Несмотря на то, что все процессы пользуются одними и теми же программами ядра, каждый из них имеет свою собственную копию стека ядра для хранения индивидуальных обращений к функциям ядра. Пусть, например, один процесс вызывает функцию creat и приостанавливается в ожидании назначения нового индекса, а другой процесс вызывает функцию read и приостанавливается в ожидании завершения передачи данных с диска в память. Оба процесса обращаются к функциям ядра и у каждого из них имеется в наличии отдельный стек, в котором хранится последовательность выполненных обращений. Ядро должно иметь возможность восстанавливать содержимое стека ядра и положение указателя вершины стека для того, чтобы возобновлять выполнение процесса в режиме ядра. В различных системах стек ядра часто располагается в пространстве процесса, однако этот стек является логически-независимым и, таким образом, может помещаться в самостоятельной области памяти. Когда процесс выполняется в режиме задачи, соответствующий ему стек ядра пуст. • Динамическая часть системного контекста процесса, состоящая из нескольких уровней и имеющая вид стека, который освобождается от элементов в порядке, обратном порядку их поступления. На каждом уровне системного контекста содержится информация, необходимая для восстановления предыдущего уровня и включающая в себя регистровый контекст предыдущего уровня. Ядро помещает контекстный уровень в стек при возникновении прерывания, при обращении к системной функции или при переключении контекста процесса. Контекстный уровень выталкивается из стека после завершения обработки прерывания, при возврате процесса в режим задачи после выполнения системной функции, или при переключении контекста. Таким образом, переключение контекста влечет за собой как помещение контекстного уровня в стек, так и извлечение уровня из стека: ядро помещает в стек контекстный уровень старого процесса, а извлекает из стека контекстный уровень нового процесса. Информация, необходимая для восстановления текущего контекстного уровня, хранится в записи таблицы процессов. На Рисунке 6.8 изображены компоненты контекста процесса. Слева на рисунке изображена статическая часть контекста. В нее входят: пользовательский контекст, состоящий из программ процесса (машинных инструкций), данных, стека и разделяемой памяти (если она имеется), а также статическая часть системного контекста, состоящая из записи таблицы процессов, пространства процесса и записей частной таблицы областей (информации, необходимой для трансляции виртуальных адресов пользовательского контекста). Справа на рисунке изображена динамическая часть контекста. Она имеет вид стека и включает в себя несколько элементов, хранящих регистровый контекст предыдущего уровня и стек ядра для текущего уровня. Нулевой контекстный уровень представляет собой пустой уровень, относящийся к пользовательскому контексту; увеличение стека здесь идет в адресном пространстве задачи, стек ядра недействителен. Стрелка, соединяющая между собой статическую часть системного контекста и верхний уровень динамической части контекста, означает то, что в таблице процессов хранится информация, позволяющая ядру восстанавливать текущий контекстный уровень процесса. 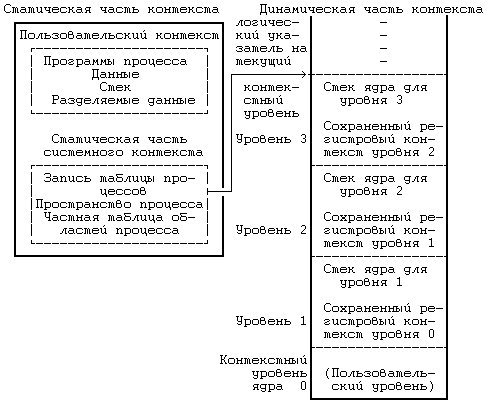 Рисунок 6.8. Компоненты контекста процесса Процесс выполняется в рамках своего контекста или, если говорить более точно, в рамках своего текущего контекстного уровня. Количество контекстных уровней ограничивается числом поддерживаемых в машине уровней прерывания. Например, если в машине поддерживаются разные уровни прерываний для программ, терминалов, дисков, всех остальных периферийных устройств и таймера, то есть 5 уровней прерывания, то, следовательно, у процесса может быть не более 7 контекстных уровней: по одному на каждый уровень прерывания, 1 для системных функций и 1 для пользовательского контекста. 7 уровней будет достаточно, даже если прерывания будут поступать в «наихудшем» из возможных порядков, поскольку прерывание данного уровня блокируется (то есть его обработка откладывается центральным процессором) до тех пор, пока ядро не обработает все прерывания этого и более высоких уровней. Несмотря на то, что ядро всегда исполняет контекст какого-нибудь процесса, логическая функция, которую ядро реализует в каждый момент, не всегда имеет отношение к данному процессу. Например, если возвращая данные, дисковое запоминающее устройство посылает прерывание, то прерывается выполнение текущего процесса и ядро обрабатывает прерывание на новом контекстном уровне этого процесса, даже если данные относятся к другому процессу. Программы обработки прерываний обычно не обращаются к статическим составляющим контекста процесса и не видоизменяют их, так как эти части не связаны с прерываниями. 6.4 СОХРАНЕНИЕ КОНТЕКСТА ПРОЦЕССАКак уже говорилось ранее, ядро сохраняет контекст процесса, помещая в стек новый контекстный уровень. В частности, это имеет место, когда система получает прерывание, когда процесс вызывает системную функцию или когда ядро выполняет переключение контекста. Каждый из этих случаев подробно рассматривается в этом разделе. 6.4.1 Прерывания и особые ситуацииСистема отвечает за обработку всех прерываний, поступили ли они от аппаратуры (например, от таймера или от периферийных устройств), от программ (в связи с выполнением инструкций, вызывающих возникновение «программных прерываний») или явились результатом особых ситуаций (таких как обращение к отсутствующей странице). Если центральный процессор ведет обработку на более низком уровне по сравнению с уровнем поступившего прерывания, то перед выполнением следующей инструкции его работа прерывается, а уровень прерывания процессора повышается, чтобы другие прерывания с тем же (или более низким) уровнем не могли иметь места до тех пор, пока ядро не обработает текущее прерывание, благодаря чему обеспечивается сохранение целостности структур данных ядра. В процессе обработки прерывания ядро выполняет следующую последовательность действий: 1. Сохраняет текущий регистровый контекст выполняющегося процесса и создает в стеке (помещает в стек) новый контекстный уровень. 2. Устанавливает «источник» прерывания, идентифицируя тип прерывания (например, прерывание по таймеру или от диска) и номер устройства, вызвавшего прерывание (например, если прерывание вызвано дисковым запоминающим устройством). При возникновении прерывания система получает от машины число, которое использует в качестве смещения в таблице векторов прерывания. Содержимое векторов прерывания в разных машинах различно, но, как правило, в них хранится адрес программы обработки прерывания, соответствующей источнику прерывания, и указывается путь поиска параметра для программы. В качестве примера рассмотрим таблицу векторов прерывания, приведенную на Рисунке 6.9. Если источником прерывания явился терминал, ядро получает от аппаратуры номер прерывания, равный 2, и вызывает программу обработки прерываний от терминала, именуемую ttyintr.
Рисунок 6.9. Пример векторов прерывания 3. Вызов программы обработки прерывания. Стек ядра для нового контекстного уровня, если рассуждать логически, должен отличаться от стека ядра предыдущего контекстного уровня. В некоторых разработках стек ядра текущего процесса используется для хранения элементов, соответствующих программам обработки прерываний, в других разработках эти элементы хранятся в глобальном стеке прерываний, благодаря чему обеспечивается возврат из программы без переключения контекста. 4. Программа завершает свою работу и возвращает управление ядру. Ядро исполняет набор машинных команд по сохранению регистрового контекста и стека ядра предыдущего контекстного уровня в том виде, который они имели в момент прерывания, после чего возобновляет выполнение восстановленного контекстного уровня. Программа обработки прерываний может повлиять на поведение процесса, поскольку она может внести изменения в глобальные структуры данных ядра и возобновить выполнение приостановленных процессов. Однако, обычно процесс продолжает выполняться так, как если бы прерывание никогда не происходило. алгоритм inthand /* обработка прерываний */ входная информация: отсутствует выходная информация: отсутствует { сохранить (поместить в стек) текущий контекстный уровень; установить источник прерывания; найти вектор прерывания; вызвать программу обработки прерывания; восстановить (извлечь из стека) предыдущий контекстный уровень; } Рисунок 6.10. Алгоритм обработки прерываний На Рисунке 6.10 кратко изложено, каким образом ядро обрабатывает прерывания. С помощью использования в отдельных случаях последовательности машинных операций или микрокоманд на некоторых машинах достигается больший эффект по сравнению с тем, когда все операции выполняются программным обеспечением, однако имеются узкие места, связанные с числом сохраняемых контекстных уровней и скоростью выполнения машинных команд, реализующих сохранение контекста. По этой причине определенные операции, выполнения которых требует реализация системы UNIX, являются машинно-зависимыми. На Рисунке 6.11 показан пример, в котором процесс запрашивает выполнение системной функции (см. следующий раздел) и получает прерывание от диска при ее выполнении. Запустив программу обработки прерывания от диска, система получает прерывание по таймеру и вызывает уже программу обработки прерывания по таймеру. Каждый раз, когда система получает прерывание (или вызывает системную функцию), она создает в стеке новый контекстный уровень и сохраняет регистровый контекст предыдущего уровня. 6.4.2 Взаимодействие с операционной системой через вызовы системных функцийТакого рода взаимодействие с ядром было предметом рассмотрения в предыдущих главах, где шла речь об обычном вызове функций. Очевидно, что обычная последовательность команд обращения к функции не в состоянии переключить выполнения процесса с режима задачи на режим ядра. Компилятор с языка Си использует библиотеку функций, имена которых совпадают с именами системных функций, иначе ссылки на системные функции в пользовательских программах были бы ссылками на неопределенные имена. В библиотечных функциях обычно исполняется команда, переводящая выполнение процесса в режим ядра и побуждающая ядро к запуску исполняемого кода системной функции. В дальнейшем эта команда именуется «внутренним прерыванием операционной системы». Библиотечные процедуры исполняются в режиме задачи, а взаимодействие с операционной системой через вызов системной функции можно определить в нескольких словах как особый случай программы обработки прерывания. Библиотечные функции передают ядру уникальный номер системной функции одним из машинно-зависимых способов — либо как параметр внутреннего прерывания операционной системы, либо через отдельный регистр, либо через стек — а ядро таким образом определяет тип вызываемой функции.  Рисунок 6.11. Примеры прерываний Обрабатывая внутреннее прерывание операционной системы, ядро по номеру системной функции ведет в таблице поиск адреса соответствующей процедуры ядра, то есть точки входа системной функции, и количества передаваемых функции параметров (Рисунок 6.12). Ядро вычисляет адрес (пользовательский) первого параметра функции, прибавляя (или вычитая, в зависимости от направления увеличения стека) смещение к указателю вершины стека задачи (аналогично для всех параметров функции). Наконец, ядро копирует параметры задачи в пространство процесса и вызывает соответствующую процедуру, которая выполняет системную функцию. После исполнения процедуры ядро выясняет, не было ли ошибки. Если ошибка была, ядро делает соответствующие установки в сохраненном регистровом контексте задачи, при этом в регистре PS обычно устанавливается бит переноса, а в нулевой регистр заносится номер ошибки. Если при выполнении системной функции не было ошибок, ядро очищает в регистре PS бит переноса и заносит возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи. Когда ядро возвращается после обработки внутреннего прерывания операционной системы в режим задачи, оно попадает в следующую библиотечную инструкцию после прерывания. Библиотечная функция интерпретирует возвращенные ядром значения и передает их программе пользователя. алгоритм syscall /* алгоритм запуска системной функции */ входная информация: номер системной функции выходная информация: результат системной функции { найти запись в таблице системных функций, соответствующую указанному номеру функции; определить количество параметров, передаваемых функции; скопировать параметры из адресного пространства задачи в пространство процесса; сохранить текущий контекст для аварийного завершения (см. раздел 6.44); запустить в ядре исполняемый код системной функции; if (во время выполнения функции произошла ошибка) { установить номер ошибки в нулевом регистре сохраненного регистрового контекста задачи; включить бит переноса в регистре PS сохраненного регистрового контекста задачи; } else занести возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи; } Рисунок 6.12. Алгоритм обращения к системным функциям В качестве примера рассмотрим программу, которая создает файл с разрешением чтения и записи в него для всех пользователей (режим доступа 0666) и которая приведена в верхней части Рисунка 6.13. Далее на рисунке изображен отредактированный фрагмент сгенерированного кода программы после компиляции и дисассемблирования (создания по объектному коду эквивалентной программы на языке ассемблера) в системе Motorola 68000. На Рисунке 6.14 изображена конфигурация стека для системной функции создания. Компилятор генерирует программу помещения в стек задачи двух параметров, один из которых содержит установку прав доступа (0666), а другой — переменную «имя файла»[18]. Затем из адреса 64 процесс вызывает библиотечную функцию creat (адрес 7a), аналогичную соответствующей системной функции. Адрес точки возврата из функции 6a, этот адрес помещается процессом в стек. Библиотечная функция creat засылает в регистр 0 константу 8 и исполняет команду прерывания (trap), которая переключает процесс из режима задачи в режим ядра и заставляет его обратиться к системной функции. Заметив, что процесс вызывает системную функцию, ядро выбирает из регистра 0 номер функции (8) и определяет таким образом, что вызвана функция creat. Просматривая внутреннюю таблицу, ядро обнаруживает, что системной функции creat необходимы два параметра; восстанавливая регистровый контекст предыдущего уровня, ядро копирует параметры из пользовательского пространства в пространство процесса. Процедуры ядра, которым понадобятся эти параметры, могут найти их в определенных местах адресного пространства процесса. По завершении исполнения кода функции creat управление возвращается программе обработки обращений к операционной системе, которая проверяет, установлено ли поле ошибки в пространстве процесса (то есть имела ли место во время выполнения функции ошибка); если да, программа устанавливает в регистре PS бит переноса, заносит в регистр 0 код ошибки и возвращает управление ядру. Если ошибок не было, в регистры 0 и 1 ядро заносит код завершения. Возвращая управление из программы обработки обращений к операционной системе в режим задачи, библиотечная функция проверяет состояние бита переноса в регистре PS (по адресу 7): если бит установлен, управление передается по адресу 13c, из нулевого регистра выбирается код ошибки и помещается в глобальную переменную errno по адресу 20, в регистр 0 заносится -1, и управление возвращается на следующую после адреса 64 (где производится вызов функции) команду. Код завершения функции имеет значение -1, что указывает на ошибку в выполнении системной функции. Если же бит переноса в регистре PS при переходе из режима ядра в режим задачи имеет нулевое значение, процесс с адреса 7 переходит по адресу 86 и возвращает управление вызвавшей программе (адрес 64); регистр 0 содержит возвращаемое функцией значение. char name[] = "file"; main() { int fd; fd = creat(name, 0666); } Фрагменты ассемблерной программы, сгенерированной в системе Motorola 68000 Адрес Команда — # текст главной программы — 58: mov &0x1b6, (%sp) # поместить код 0666 в стек 5e: mov &0x204, -(%sp) # поместить указатель вершины стека и переменную «имя файла» в стек 64: jsr 0x7a # вызов библиотечной функции создания файла — # текст библиотечной функции создания файла 7a: movq &0x8, %d0 # занести значение 8 в регистр 0 7c: trap &0x0 # внутреннее прерывание операционной системы 7e: bcc &0x6 ‹86› # если бит переноса очищен, перейти по адресу 86 80: jmp 0x13c # перейти по адресу 13c 86: rts # возврат из подпрограммы — # текст обработки ошибок функции 13c: mov %d0, &0x20e # поместить содержимое регистра 0 в ячейку 20e (переменная errno) 142: movq &-0x1, %d0 # занести в регистр 0 константу -1 144: mova %d0, %a0 146: rts # возврат из подпрограммы Рисунок 6.13. Системная функция creat и сгенерированная программа ее выполнения в системе Motorola 68000  Рисунок 6.14. Конфигурация стека для системной функции creat Несколько библиотечных функций могут отображаться на одну точку входа в список системных функций. Каждая точка входа определяет точные синтаксис и семантику обращения к системной функции, однако более удобный интерфейс обеспечивается с помощью библиотек. Существует, например, несколько конструкций системной функции exec, таких как execl и execle, выполняющих одни и те же действия с небольшими отличиями. Библиотечные функции, соответствующие этим конструкциям, при обработке параметров реализуют заявленные свойства, но в конечном итоге, отображаются на одну и ту же функцию ядра. 6.4.3 Переключение контекста Если обратиться к диаграмме состояний процесса (Рисунок 6.1), можно увидеть, что ядро разрешает производить переключение контекста в четырех случаях: когда процесс приостанавливает свое выполнение, когда он завершается, когда он возвращается после вызова системной функции в режим задачи, но не является наиболее подходящим для запуска, или когда он возвращается в режим задачи после завершения ядром обработки прерывания, но так же не является наиболее подходящим для запуска. Как уже было показано в главе 2, ядро поддерживает целостность и согласованность своих внутренних структур данных, запрещая произвольно переключать контекст. Прежде чем переключать контекст, ядро должно удостовериться в согласованности своих структур данных: то есть в том, что сделаны все необходимые корректировки, все очереди выстроены надлежащим образом, установлены соответствующие блокировки, позволяющие избежать вмешательства со стороны других процессов, что нет излишних блокировок и т. д. Например, если ядро выделяет буфер, считывает блок из файла и приостанавливает выполнение до завершения передачи данных с диска, оно оставляет буфер заблокированным, чтобы другие процессы не смогли обратиться к буферу. Но если процесс исполняет системную функцию link, ядро снимает блокировку с первого индекса перед тем, как снять ее со второго индекса, и тем самым предотвращает возникновение тупиковых ситуаций (взаимной блокировки). Ядро выполняет переключение контекста по завершении системной функции exit, поскольку в этом случае больше ничего не остается делать. Кроме того, переключение контекста допускается, когда процесс приостанавливает свою работу, поскольку до момента возобновления может пройти немало времени, в течение которого могли бы выполняться другие процессы. Переключение контекста допускается и тогда, когда процесс не имеет преимуществ перед другими процессами при исполнении, с тем, чтобы обеспечить более справедливое планирование процессов: если по выходе процесса из системной функции или из прерывания обнаруживается, что существует еще один процесс, который имеет более высокий приоритет и ждет выполнения, то было бы несправедливо оставлять его в ожидании. Процедура переключения контекста похожа на процедуры обработки прерываний и обращения к системным функциям, если не считать того, что ядро вместо предыдущего контекстного уровня текущего процесса восстанавливает контекстный уровень другого процесса. Причины, вызвавшие переключение контекста, при этом не имеют значения. На механизм переключения контекста не влияет и метод выбора следующего процесса для исполнения. 1. Принять решение относительно необходимости переклю- чения контекста и его допустимости в данный момент. 2. Сохранить контекст «прежнего» процесса. 3. Выбрать процесс, наиболее подходящий для исполнения, используя алгоритм диспетчеризации процессов, приведенный в главе 8. 4. Восстановить его контекст. Рисунок 6.15. Последовательность шагов, выполняемых при переключении контекста Текст программы, реализующей переключение контекста в системе UNIX, из всех программ операционной системы самый трудный для понимания, ибо при рассмотрении обращений к функциям создается впечатление, что они в одних случаях не возвращают управление, а в других — возникают непонятно откуда. Причиной этого является то, что ядро во многих системных реализациях сохраняет контекст процесса в одном месте программы, но продолжает работу, выполняя переключение контекста и алгоритмы диспетчеризации в контексте «прежнего» процесса. Когда позднее ядро восстанавливает контекст процесса, оно возобновляет его выполнение в соответствии с ранее сохраненным контекстом. Чтобы различать между собой те случаи, когда ядро восстанавливает контекст нового процесса, и когда оно продолжает исполнять ранее сохраненный контекст, можно варьировать значения, возвращаемые критическими функциями, или устанавливать искусственным образом текущее значение счетчика команд. На Рисунке 6.16 приведена схема переключения контекста. Функция save_context сохраняет информацию о контексте исполняемого процесса и возвращает значение 1. Кроме всего прочего, ядро сохраняет текущее значение счетчика команд (в функции save_context) и значение 0 в нулевом регистре при выходе из функции. Ядро продолжает исполнять контекст «прежнего» процесса (A), выбирая для выполнения следующий процесс (B) и вызывая функцию resume_context для восстановления его контекста. После восстановления контекста система выполняет процесс B; прежний процесс (A) больше не исполняется, но он оставил после себя сохраненный контекст. Позже, когда будет выполняться переключение контекста, ядро снова изберет процесс A (если только, разумеется, он не был завершен). В результате восстановления контекста A ядро присвоит счетчику команд то значение, которое было сохранено процессом A ранее в функции save_context, и возвратит в регистре 0 значение 0. Ядро возобновляет выполнение процесса A из функции save_context, пусть даже при выполнении программы переключения контекста оно не добралось еще до функции resume_context. В конечном итоге, процесс A возвращается из функции save_context со значением 0 (в нулевом регистре) и возобновляет выполнение после строки комментария «возобновление выполнение процесса начинается отсюда». if (save_context()) { /* сохранение контекста выполняющегося процесса */ /* выбор следующего процесса для выполнения */ ... resume_context(new_process); /* сюда программа не попадает! */ } /* возобновление выполнение процесса начинается отсюда */ Рисунок 6.16. Псевдопрограмма переключения контекста 6.4.4 Сохранение контекста на случай аварийного завершения Существуют ситуации, когда ядро вынуждено аварийно прерывать текущий порядок выполнения и немедленно переходить к исполнению ранее сохраненного контекста. В последующих разделах, где пойдет речь о приостановлении выполнения и о сигналах, будут описаны обстоятельства, при которых процессу приходится внезапно изменять свой контекст; в данном же разделе рассматривается механизм исполнения предыдущего контекста. Алгоритм сохранения контекста называется setjmp, а алгоритм восстановления контекста — longjmp[19]. Механизм работы алгоритма setjmp похож на механизм функции save_context, рассмотренный в предыдущем разделе, если не считать того, что функция save_context помещает новый контекстный уровень в стек, в то время как setjmp сохраняет контекст в пространстве процесса и после выхода из него выполнение продолжается в прежнем контекстном уровне. Когда ядру понадобится восстановить контекст, сохраненный в результате работы алгоритма setjmp, оно исполнит алгоритм longjmp, который восстанавливает контекст из пространства процесса и имеет, как и setjmp, код завершения, равный 1. 6.4.5 Копирование данных между адресным пространством системы и адресным пространством задачи До сих пор речь шла о том, что процесс выполняется в режиме ядра или в режиме задачи без каких-либо перекрытий (пересечений) между режимами. Однако, при выполнении большинства системных функций, рассмотренных в последней главе, между пространством ядра и пространством задачи осуществляется пересылка данных, например, когда идет копирование параметров вызываемой функции из пространства задачи в пространство ядра или когда производится передача данных из буферов ввода-вывода в процессе выполнения функции read. На многих машинах ядро системы может непосредственно ссылаться на адреса, принадлежащие адресному пространству задачи. Ядро должно убедиться в том, что адрес, по которому производится запись или считывание, доступен, как будто бы работа ведется в режиме задачи; в противном случае произошло бы нарушение стандартных методов защиты и ядро, пусть неумышленно, стало бы обращаться к адресам, которые находятся за пределами адресного пространства задачи (и, возможно, принадлежат структурам данных ядра). Поэтому передача данных между пространством ядра и пространством задачи является «дорогим предприятием», требующим для своей реализации нескольких команд. fubyte: # пересылка байта из пространства задачи prober $3, $1, *4(ap) # байт доступен? beql eret # нет movzbl *4(ap), r0 ret eret: mnegl $1, r0 # возврат ошибки (-1) ret Рисунок 6.17. Пересылка данных из пространства задачи в пространство ядра в системе VAX На Рисунке 6.17 показан пример реализованной в системе VAX программы пересылки символа из адресного пространства задачи в адресное пространство ядра. Команда prober проверяет, может ли байт по адресу, равному (регистр указателя аргумента + 4), быть считан в режиме задачи (режиме 3), и если нет, ядро передает управление по адресу eret, сохраняет в нулевом регистре -1 и выходит из программы; при этом пересылки символа не происходит. В противном случае ядро пересылает один байт, находящийся по указанному адресу, в регистр 0 и возвращает его в вызывающую программу. Пересылка 1 символа потребовала пяти команд (включая вызов функции с именем fubyte). 6.5 УПРАВЛЕНИЕ АДРЕСНЫМ ПРОСТРАНСТВОМ ПРОЦЕССА В этой главе мы пока говорили о том, каким образом осуществляется переключение контекста между процессами и как контекстные уровни запоминаются в стеке и выбираются из стека, представляя контекст пользовательского уровня как статический объект, не претерпевающий изменений при восстановлении контекста процесса. Однако, с виртуальным адресным пространством процесса работают различные системные функции и, как будет показано в следующей главе, выполняют при этом операции над областями. В этом разделе рассматривается информационная структура области; системные функции, реализующие операции над областями, будут рассмотрены в следующей главе. • Запись таблицы областей содержит информацию, необходимую для описания области. В частности, она включает в себя следующие поля: • Указатель на индекс файла, содержимое которого было первоначально загружено в область • Тип области (область команд, разделяемая память, область частных данных или стека) • Размер области • Местоположение области в физической памяти • Статус (состояние) области, представляющий собой комбинацию из следующих признаков: - заблокирована - запрошена - идет процесс ее загрузки в память - готова, загружена в память • Счетчик ссылок, в котором хранится количество процессов, ссылающихся на данную область. К операциям работы с областями относятся: блокировка области, снятие блокировки с области, выделение области, присоединение области к пространству памяти процесса, изменение размера области, загрузка области из файла в пространство памяти процесса, освобождение области, отсоединение области от пространства памяти процесса и копирование содержимого области. Например, системная функция exec, в которой содержимое исполняемого файла накладывается на адресное пространство задачи, отсоединяет старые области, освобождает их в том случае, если они не являются разделяемыми, выделяет новые области, присоединяет их и загружает содержимым файла. В остальной части раздела операции над областями описываются более детально с ориентацией на модель управления памятью, рассмотренную ранее (с таблицами страниц и группами аппаратных регистров), и с ориентацией на алгоритмы назначения страниц физической памяти и таблиц страниц (глава 9). 6.5.1 Блокировка области и снятие блокировки Операции блокировки и снятия блокировки для области выполняются независимо от операций выделения и освобождения области, подобно тому, как операции блокирования-разблокирования индекса в файловой системе выполняются независимо от операций назначения-освобождения индекса (алгоритмы iget и iput). Таким образом, ядро может заблокировать и выделить область, а потом снять блокировку, не освобождая области. Точно также, когда ядру понадобится обратиться к выделенной области, оно сможет заблокировать область, чтобы запретить доступ к ней со стороны других процессов, и позднее снять блокировку. 6.5.2 Выделение области Ядро выделяет новую область (по алгоритму allocreg, Рисунок 6.18) во время выполнения системных функций fork, exec и shmget (получить разделяемую память). Ядро поддерживает таблицу областей, записям которой соответствуют точки входа либо в списке свободных областей, либо в списке активных областей. При выделении записи в таблице областей ядро выбирает из списка свободных областей первую доступную запись, включает ее в список активных областей, блокирует область и делает пометку о ее типе (разделяемая или частная). За некоторым исключением каждый процесс ассоциируется с исполняемым файлом (после того, как была выполнена команда exec), и в алгоритме allocreg поле индекса в записи таблицы областей устанавливается таким образом, чтобы оно указывало на индекс исполняемого файла. Индекс идентифицирует область для ядра, поэтому другие процессы могут при желании разделять область. Ядро увеличивает значение счетчика ссылок на индекс, чтобы помешать другим процессам удалять содержимое файла при выполнении функции unlink, об этом еще будет идти речь в разделе 7.5. Результатом алгоритма allocreg является назначение и блокировка области. алгоритм allocreg /* разместить информационную структуру области */ входная информация: (1) указатель индекса (2) тип области выходная информация: заблокированная область { выбрать область из списка свободных областей; назначить области тип; присвоить значение указателю индекса; if (указатель индекса имеет ненулевое значение) увеличить значение счетчика ссылок на индекс; включить область в список активных областей; return (заблокированную область); } Рисунок 6.18. Алгоритм выделения области 6.5.3 Присоединение области к процессу Ядро присоединяет область к адресному пространству процесса во время выполнения системных функций fork, exec и shmat (алгоритм attachreg, Рисунок 6.19). Область может быть вновь назначаемой или уже существующей, которую процесс будет использовать совместно с другими процессами. Ядро выбирает свободную запись в частной таблице областей процесса, устанавливает в ней поле типа таким образом, чтобы оно указывало на область команд, данных, разделяемую память или область стека, и записывает виртуальный адрес, по которому область будет размещаться в адресном пространстве процесса. Процесс не должен выходить за предел установленного системой ограничения на максимальный виртуальный адрес, а виртуальные адреса новой области не должны пересекаться с адресами существующих уже областей. Например, если система ограничила максимально-допустимое значение виртуального адреса процесса 8 мегабайтами, то привязать область размером 1 мегабайт к виртуальному адресу 7.5M не удастся. Если же присоединение области допустимо, ядро увеличивает значение поля, описывающего размер области процесса в записи таблицы процессов, на величину присоединяемой области, а также увеличивает значение счетчика ссылок на область. Кроме того, в алгоритме attachreg устанавливаются начальные значения группы регистров управления памятью, выделенных процессу. Если область ранее не присоединялась к какому-либо процессу, ядро с помощью функции growreg (см. следующий раздел) заводит для области новые таблицы страниц; в противном случае используются уже существующие таблицы страниц. Алгоритм завершает работу, возвращая указатель на точку входа в частную таблицу областей процесса, соответствующую вновь присоединенной области. Допустим, например, что ядру нужно подключить к процессу по виртуальному адресу 0 существующую (разделяемую) область, имеющую размер 7 Кбайт (Рисунок 6.20). Оно выделяет новую группу регистров управления памятью и заносит в них адрес таблицы страниц области, виртуальный адрес области в пространстве процесса (0) и размер таблицы страниц (9 записей). алгоритм attachreg /* присоединение области к процессу */ входная информация: (1) указатель на присоединяемую область (заблокированную) (2) процесс, к которому присоединяется область (3) виртуальный адрес внутри процесса, по которому будет присоединена область (4) тип области выходная информация: точка входа в частную таблицу областей процесса { выделить новую запись в частной таблице областей процесса; проинициализировать значения полей записи: установить указатель на присоединяемую область; установить тип области; установить виртуальный адрес области; проверить правильность указания виртуального адреса и размера области; увеличить значение счетчика ссылок на область; увеличить размер процесса с учетом присоединения области; записать начальные значения в новую группу аппаратных регистров; return (точку входа в частную таблицу областей процесса); } Рисунок 6.19. Алгоритм присоединения области 6.5.4 Изменение размера областиПроцесс может расширять или сужать свое виртуальное адресное пространство с помощью функции sbrk. Точно так же и стек процесса расширяется автоматически (то есть для этого процессу не нужно явно обращаться к определенной функции) в соответствии с глубиной вложенности обращений к подпрограммам. Изменение размера области производится внутри ядра по алгоритму growreg (Рисунок 6.21). При расширении области ядро проверяет, не будут ли виртуальные адреса расширяемой области пересекаться с адресами какой-нибудь другой области и не повлечет ли расширение области за собой выход процесса за пределы максимально-допустимого виртуального пространства памяти. Ядро никогда не использует алгоритм growreg для увеличения размера разделяемой области, уже присоединенной к нескольким процессам; поэтому оно не беспокоится о том, не приведет ли увеличение размера области для одного процесса к превышению другим процессом системного ограничения, накладываемого на размер процесса. При работе с существующей областью ядро использует алгоритм growreg в двух случаях: выполняя функцию sbrk по отношению к области данных процесса и реализуя автоматическое увеличение стека задачи. Обе эти области (данных и стека) частного типа. Области команд и разделяемой памяти после инициализации не могут расширяться. Этот момент будет пояснен в следующей главе. 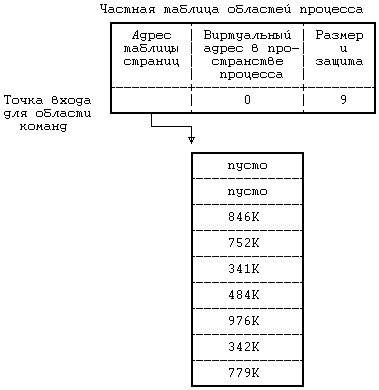 Рисунок 6.20. Пример присоединения существующей области команд Чтобы разместить расширенную память, ядро выделяет новые таблицы страниц (или расширяет существующие) или отводит дополнительную физическую память в тех системах, где не поддерживается подкачка страниц по обращению. При выделении дополнительной физической памяти ядро проверяет ее наличие перед выполнением алгоритма growreg; если же памяти больше нет, ядро прибегает к другим средствам увеличения размера области (см. главу 9). Если процесс сокращает размер области, ядро просто освобождает память, отведенную под область. Во всех этих случаях ядро переопределяет размеры процесса и области и переустанавливает значения полей записи частной таблицы областей процесса и регистров управления памятью (так, чтобы они согласовались с новым отображением памяти). Предположим, например, что область стека процесса начинается с виртуального адреса 128К и имеет размер 6 Кбайт и что ядру нужно расширить эту область на 1 Кбайт (1 страницу). Если размер процесса позволяет это делать и если виртуальные адреса в диапазоне от 134К до 135К-1 не принадлежат какой-либо области, ранее присоединенной к процессу, ядро увеличивает размер стека. При этом ядро расширяет таблицу страниц, выделяет новую страницу памяти и инициализирует новую запись таблицы. Этот случай проиллюстрирован с помощью Рисунка 6.22 6.5.5 Загрузка областиВ системе, где поддерживается подкачка страниц по обращению, ядро может «отображать» файл в адресное пространство процесса во время выполнения функции exec, подготавливая последующее чтение по запросу отдельных физических страниц (см. главу 9). Если же подкачка страниц по обращению не поддерживается, ядру приходится копировать исполняемый файл в память, загружая области процесса по указанным в файле виртуальным адресам. Ядро может присоединить область к разным виртуальным адресам, по которым будет загружаться содержимое файла, создавая таким образом «разрыв» в таблице страниц (вспомним Рисунок 6.20). Эта возможность может пригодиться, например, когда требуется проявлять ошибку памяти (memory fault) в случае обращения пользовательских программ к нулевому адресу (если последнее запрещено). Переменные указатели в программах иногда задаются неверно (отсутствует проверка их значений на равенство 0) и в результате не могут использоваться в качестве указателей адресов. Если страницу с нулевым адресом соответствующим образом защитить, процессы, случайно обратившиеся к этому адресу, натолкнутся на ошибку и будут аварийно завершены, и это ускорит обнаружение подобных ошибок в программах. алгоритм growreg /* изменение размера области */ входная информация: (1) указатель на точку входа в частной таблице областей процесса (2) величина, на которую нужно изменить размер области (может быть как положительной, так и отрицательной) выходная информация: отсутствует { if (размер области увеличивается) { проверить допустимость нового размера области; выделить вспомогательные таблицы (страниц); if (в системе не поддерживается замещение страниц по обращению) { выделить дополнительную память; проинициализировать при необходимости значения полей в дополнительных таблицах; } } else { /* размер области уменьшается */ освободить физическую память; освободить вспомогательные таблицы; } провести в случае необходимости инициализацию других вспомогательных таблиц; переустановить значение поля размера в таблице процессов; } Рисунок 6.21. Алгоритм изменения размера области При загрузке файла в область алгоритм loadreg (Рисунок 6.23) проверяет разрыв между виртуальным адресом, по которому область присоединяется к процессу, и виртуальным адресом, с которого располагаются данные области, и расширяет область в соответствии с требуемым объемом памяти. Затем область переводится в состояние «загрузки в память», при котором данные для области считываются из файла в память с помощью встроенной модификации алгоритма системной функции read. 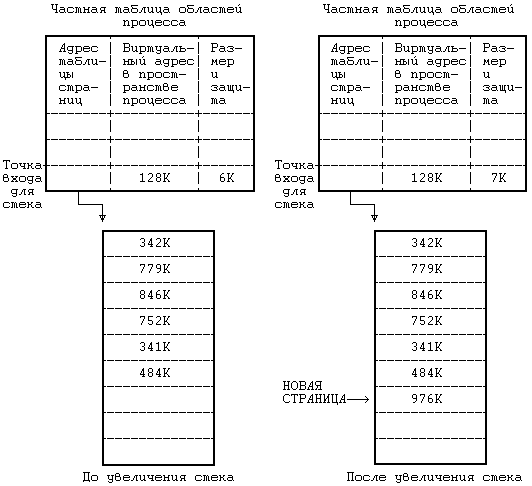 Рисунок 6.22. Увеличение области стека на 1 Кбайт Если ядро загружает область команд, которая может разделяться несколькими процессами, возможна ситуация, когда процесс попытается воспользоваться областью до того, как ее содержимое будет полностью загружено, так как процесс загрузки может приостановиться во время чтения файла. Подробно о том, как это происходит и почему при этом нельзя использовать блокировки, мы поговорим, когда будем вести речь о функции exec в следующей главе и в главе 9. Чтобы устранить эту проблему, ядро проверяет статус области и не разрешает к ней доступ до тех пор, пока загрузка области не будет закончена. По завершении реализации алгоритма loadreg ядро возобновляет выполнение всех процессов, ожидающих окончания загрузки области, и изменяет статус области («готова, загружена в память»). Предположим, например, что ядру нужно загрузить текст размером 7K в область, присоединенную к процессу по виртуальному адресу 0, но при этом оставить промежуток размером 1 Кбайт от начала области (Рисунок 6.24). К этому времени ядро уже выделило запись в таблице областей и присоединило область по адресу 0 с помощью алгоритмов allocreg и attachreg. Теперь же ядро запускает алгоритм loadreg, в котором действия алгоритма growreg выполняются дважды — во-первых, при выделении в начале области промежутка в 1 Кбайт, и во-вторых, при выделении места для содержимого области — и алгоритм growreg назначает для области таблицу страниц. Затем ядро заносит в соответствующие поля пространства процесса установочные значения для чтения данных из файла: считываются 7 Кбайт, начиная с адреса, указанного в виде смещения внутри файла (параметр алгоритма), и записываются в виртуальное пространство процесса по адресу 1K. алгоритм loadreg /* загрузка части файла в область */ входная информация: (1) указатель на точку входа в частную таблицу областей процесса (2) виртуальный адрес загрузки (3) указатель индекса файла (4) смещение в байтах до начала считываемой части файла (5) объем загружаемых данных в байтах выходная информация: отсутствует { увеличить размер области до требуемой величины (алгоритм growreg); записать статус области как «загружаемой в память»; снять блокировку с области; установить в пространстве процесса значения параметров чтения из файла: виртуальный адрес, по которому будут размещены считываемые данные; смещение до начала считываемой части файла; объем данных, считываемых из файла, в байтах; загрузить файл в область (встроенная модификация алгоритма read); заблокировать область; записать статус области как «полностью загруженной в память»; возобновить выполнение всех процессов, ожидающих окончания загрузки области; } Рисунок 6.23. Алгоритм загрузки данных области из файла 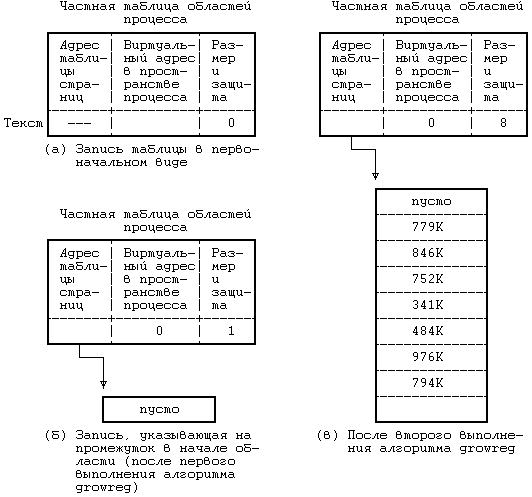 Рисунок 6.24. Загрузка области команд (текста) алгоритм freereg /* освобождение выделенной области */ входная информация: указатель на (заблокированную) область выходная информация: отсутствует { if (счетчик ссылок на область имеет ненулевое значение) { /* область все еще используется одним из процессов */ снять блокировку с области; if (область ассоциирована с индексом) снять блокировку с индекса; return; } if (область ассоциирована с индексом) освободить индекс (алгоритм iput); освободить связанную с областью физическую память; освободить связанные с областью вспомогательные таблицы; очистить поля области; включить область в список свободных областей; снять блокировку с области; } Рисунок 6.25. Алгоритм освобождения области 6.5.6 Освобождение области Если область не присоединена уже ни к какому процессу, она может быть освобождена ядром и возвращена в список свободных областей (Рисунок 6.25). Если область связана с индексом, ядро освобождает и индекс с помощью алгоритма iput, учитывая значение счетчика ссылок на индекс, установленное в алгоритме allocreg. Ядро освобождает все связанные с областью физические ресурсы, такие как таблицы страниц и собственно страницы физической памяти. Предположим, например, что ядру нужно освободить область стека, описанную на Рисунке 6.22. Если счетчик ссылок на область имеет нулевое значение, ядро освободит 7 страниц физической памяти вместе с таблицей страниц. алгоритм detachreg /* отсоединить область от процесса */ входная информация: указатель на точку входа в частной таблице областей процесса выходная информация: отсутствует { обратиться к вспомогательным таблицам процесса, имеющим отношение к распределению памяти, освободить те из них, которые связаны с областью; уменьшить размер процесса; уменьшить значение счетчика ссылок на область; if (значение счетчика стало нулевым и область не является неотъемлемой частью процесса) освободить область (алгоритм freereg); else { /* либо значение счетчика отлично от 0, либо область является неотъемлемой частью процесса */ снять блокировку с индекса (ассоциированного с областью); снять блокировку с области; } } Рисунок 6.26. Алгоритм отсоединения области 6.5.7 Отсоединение области от процессаЯдро отсоединяет области при выполнении системных функций exec, exit и shmdt (отсоединить разделяемую память). При этом ядро корректирует соответствующую запись и разъединяет связь с физической памятью, делая недействительными связанные с областью регистры управления памятью (алгоритм detachreg, Рисунок 6.26). Механизм преобразования адресов после этого будет относиться уже к процессу, а не к области (как в алгоритме freereg). Ядро уменьшает значение счетчика ссылок на область и значение поля, описывающего размер процесса в записи таблицы процессов, в соответствии с размером области. Если значение счетчика становится равным 0 и если нет причины оставлять область без изменений (область не является областью разделяемой памяти или областью команд с признаками неотъемлемой части процесса, о чем будет идти речь в разделе 7.5), ядро освобождает область по алгоритму freereg. В противном случае ядро снимает с индекса и с области блокировку, установленную для того, чтобы предотвратить конкуренцию между параллельно выполняющимися процессами (см. раздел 7.5), но оставляет область и ее ресурсы без изменений. 6.5.8 Копирование содержимого области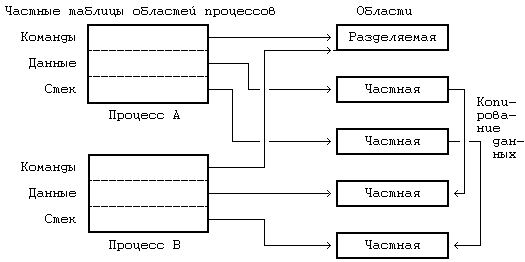 Рисунок 6.27. Копирование содержимого области алгоритм dupreg /* копирование содержимого существующей области */ входная информация: указатель на точку входа в таблице областей выходная информация: указатель на область, являющуюся точной копией существующей области { if (область разделяемая) /* в вызывающей программе счетчик ссылок на область будет увеличен, после чего будет исполнен алгоритм attachreg */ return (указатель на исходную область); выделить новую область (алгоритм allocreg); установить значения вспомогательных структур управления памятью в точном соответствии со значениями существующих структур исходной области; выделить для содержимого области физическую память; «скопировать» содержимое исходной области во вновь созданную область; return (указатель на выделенную область); } Рисунок 6.28. Алгоритм копирования содержимого существующей области Системная функция fork требует, чтобы ядро скопировало содержимое областей процесса. Если же область разделяемая (разделяемый текст команд или разделяемая память), ядру нет надобности копировать область физически; вместо этого оно увеличивает значение счетчика ссылок на область, позволяя родительскому и порожденному процессам использовать область совместно. Если область не является разделяемой и ядру нужно физически копировать ее содержимое, оно выделяет новую запись в таблице областей, новую таблицу страниц и отводит под создаваемую область физическую память. В качестве примера рассмотрим Рисунок 6.27, где процесс A порождает с помощью функции fork процесс B и копирует области родительского процесса. Область команд процесса A является разделяемой, поэтому процесс B может использовать эту область совместно с процессом A. Однако области данных и стека родительского процесса являются его личной принадлежностью (имеют частный тип), поэтому процессу B нужно скопировать их содержимое во вновь выделенные области. При этом даже для областей частного типа физическое копирование области не всегда необходимо, в чем мы убедимся позже (глава 9). На Рисунке 6.28 приведен алгоритм копирования содержимого области (dupreg). 6.6 ПРИОСТАНОВКА ВЫПОЛНЕНИЯК настоящему моменту мы рассмотрели все функции работы с внутренними структурами процесса, выполняющиеся на нижнем уровне взаимодействия с процессом и обеспечивающие переход в состояние «выполнения в режиме ядра» и выход из этого состояния в другие состояния, за исключением функций, переводящих процесс в состояние «приостанова выполнения». Теперь перейдем к рассмотрению алгоритмов, с помощью которых процесс переводится из состояния «выполнения в режиме ядра» в состояние «приостанова в памяти» и из состояния приостанова в состояния «готовности к запуску» с выгрузкой и без выгрузки из памяти.  Рисунок 6.29. Стандартные контекстные уровни приостановленного процесса Выполнение процесса приостанавливается обычно во время исполнения запрошенной им системной функции: процесс переходит в режим ядра (контекстный уровень 1), исполняя внутреннее прерывание операционной системы, и приостанавливается в ожидании ресурсов. При этом процесс переключает контекст, запоминая в стеке свой текущий контекстный уровень и исполняясь далее в рамках системного контекстного уровня 2 (Рисунок 6.29). Выполнение процессов приостанавливается также и в том случае, когда оно наталкивается на отсутствие страницы в результате обращения к виртуальным адресам, не загруженным физически; процессы не будут выполняться, пока ядро не считает содержимое страниц. 6.6.1 События, вызывающие приостанов выполнения, и их адресаКак уже говорилось во второй главе, процессы приостанавливаются до наступления определенного события, после которого они «пробуждаются» и переходят в состояние «готовности к выполнению» (с выгрузкой и без выгрузки из памяти). Такого рода абстрактное рассуждение недалеко от истины, ибо в конкретном воплощении совокупность событий отображается на совокупность виртуальных адресов (ядра). Адреса, с которыми связаны события, закодированы в ядре, и их единственное назначение состоит в их использовании в процессе отображения ожидаемого события на конкретный адрес. Как для абстрактного рассмотрения, так и для конкретной реализации события безразлично, сколько процессов одновременно ожидают его наступления. Как результат, возможно возникновение некоторых противоречий. Во-первых, когда событие наступает и процессы, ожидающие его, соответствующим образом оповещаются об этом, все они «пробуждаются» и переходят в состояние «готовности к выполнению». Ядро выводит процессы из состояния приостанова все сразу, а не по одному, несмотря на то, что они в принципе могут конкурировать за одну и ту же заблокированную структуру данных и большинство из них через небольшой промежуток времени опять вернется в состояние приостанова (более подробно об этом шла речь в главах 2 и 3). На Рисунке 6.30 изображены несколько процессов, приостановленных до наступления определенных событий. 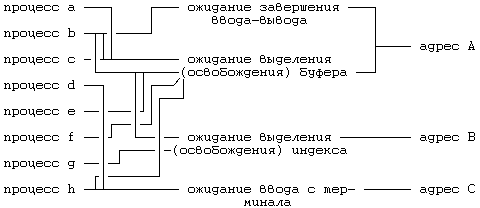 Рисунок 6.30. Процессы, приостановленные до наступления событий, и отображение событий на конкретные адреса Еще одно противоречие связано с тем, что на один и тот же адрес могут отображаться несколько событий. На Рисунке 6.30, например, события «освобождение буфера» и «завершение ввода-вывода» отображаются на адрес буфера («адрес A»). Когда ввод-вывод в буфер завершается, ядро возобновляет выполнение всех процессов, приостановленных в ожидании наступления как того, так и другого события. Поскольку процесс, ожидающий завершения ввода-вывода, удерживает буфер заблокированным, другие процессы, которые ждали освобождения буфера, вновь приостановятся, ибо буфер все еще занят. Функционирование системы было бы более эффективным, если бы отображение событий на адреса было однозначным. Однако на практике такого рода противоречие на производительности системы не отражается, поскольку отображение на один адрес более одного события имеет место довольно редко, а также поскольку выполняющийся процесс обычно освобождает заблокированные ресурсы до того, как начнут выполняться другие процессы. Стилистически, тем не менее, механизм функционирования ядра стал бы более понятен, если бы отображение было однозначным. 6.6.2 Алгоритмы приостанова и возобновления выполнения алгоритм sleep входная информация: (1) адрес приостанова (2) приоритет выходная информация: 1, если процесс возобновляется по сигналу, который ему удалось уловить; вызов алгоритма longjump, если процесс возобновляется по сигналу, который ему не удалось уловить; 0 — во всех остальных случаях; { поднять приоритет работы процессора таким образом, чтобы заблокировать все прерывания; перевести процесс в состояние приостанова; включить процесс в хеш-очередь приостановленных процессов, базирующуюся на адресах приостанова; сохранить адрес приостанова в таблице процессов; сделать ввод для процесса приоритетным; if (приостанов процесса НЕ допускает прерываний) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда «пробуждается» */ снизить приоритет работы процессора так, чтобы вновь разрешить прерывания (как было до приостанова процесса); return (0); } /* приостанов процесса принимает прерывания, вызванные сигналами */ if (к процессу не имеет отношения ни один из сигналов) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда «пробуждается» */ if (к процессу не имеет отношения ни один из сигналов) { восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; return (0); } } удалить процесс из хеш-очереди приостановленных процессов, если он все еще находится там; восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; if (приоритет приостановленного процесса позволяет принимать сигналы) return (1); запустить алгоритм longjump; } Рисунок 6.31. Алгоритм приостанова процесса На Рисунке 6.31 приведен алгоритм приостанова процесса. Сначала ядро повышает приоритет работы процессора так, чтобы заблокировать все прерывания, которые могли бы (путем создания конкуренции) помешать работе с очередями приостановленных процессов, и запоминает старый приоритет, чтобы восстановить его, когда выполнение процесса будет возобновлено. Процесс получает пометку «приостановленного», адрес приостанова и приоритет запоминаются в таблице процессов, а процесс помещается в хеш-очередь приостановленных процессов. В простейшем случае (когда приостанов не допускает прерываний) процесс выполняет переключение контекста и благополучно «засыпает». Когда приостановленный процесс «пробуждается», ядро начинает планировать его запуск: процесс возвращает сохраненный в алгоритме sleep контекст, восстанавливает старый приоритет работы процессора (который был у него до начала выполнения алгоритма) и возвращает управление ядру. алгоритм wakeup /* возобновление приостановленного процесса */ входная информация: адрес приостанова выходная информация: отсутствует { повысить приоритет работы процессора таким образом, чтобы заблокировать все прерывания; найти хеш-очередь приостановленных процессов с указанным адресом приостанова; for (каждого процесса, приостановленного по указанному адресу) { удалить процесс из хеш-очереди; сделать пометку о том, что процесс находится в состоянии «готовности к запуску»; включить процесс в список процессов, готовых к запуску (для планировщика процессов); очистить поле, содержащее адрес приостанова, в записи таблицы процессов; if (процесс не загружен в память) возобновить выполнение программы подкачки (нулевой процесс); else if (возобновляемый процесс более подходит для исполнения, чем ныне выполняющийся) установить соответствующий флаг для планировщика; } восстановить первоначальный приоритет работы процессора; } Рисунок 6.32. Алгоритм возобновления приостановленного процесса Чтобы возобновить выполнение приостановленных процессов, ядро обращается к алгоритму wakeup (Рисунок 6.32), причем делает это как во время исполнения алгоритмов реализации стандартных системных функций, так и в случае обработки прерываний. Алгоритм iput, например, освобождает заблокированный индекс и возобновляет выполнение всех процессов, ожидающих снятия блокировки. Точно так же и программа обработки прерываний от диска возобновляет выполнение процессов, ожидающих завершения ввода-вывода. В алгоритме wakeup ядро сначала повышает приоритет работы процессора, чтобы заблокировать прерывания. Затем для каждого процесса, приостановленного по указанному адресу, выполняются следующие действия: делается пометка в поле, описывающем состояние процесса, о том, что процесс готов к запуску; процесс удаляется из списка приостановленных процессов и помещается в список процессов, готовых к запуску; поле в записи таблицы процессов, содержащее адрес приостанова, очищается. Если возобновляемый процесс не загружен в память, ядро запускает процесс подкачки, обеспечивающий подкачку возобновляемого процесса в память (подразумевается система, в которой подкачка страниц по обращению не поддерживается); в противном случае, если возобновляемый процесс более подходит для исполнения, чем ныне выполняющийся, ядро устанавливает для планировщика специальный флаг, сообщающий о том, что процессу по возвращении в режим задачи следует пройти через алгоритм планирования (глава 8). Наконец, ядро восстанавливает первоначальный приоритет работы процессора. При этом на ядро не оказывается никакого давления: «пробуждение» (wakeup) процесса не вызывает его немедленного исполнения; благодаря «пробуждению», процесс становится только доступным для запуска. Все, о чем говорилось выше, касается простейшего случая выполнения алгоритмов sleep и wakeup, поскольку предполагается, что процесс приостанавливается до наступления соответствующего события. Во многих случаях процессы приостанавливаются в ожидании событий, которые «должны» наступить, например, в ожидании освобождения ресурса (индексов или буферов) или в ожидании завершения ввода-вывода, связанного с диском. Уверенность процесса в неминуемом возобновлении основана на том, что подобные ресурсы могут быть предоставлены только во временное пользование. Тем не менее, иногда процесс может приостановиться в ожидании события, не будучи уверенным в неизбежном наступлении последнего, в таком случае у процесса должна быть возможность в любом случае вернуть себе управление и продолжить выполнение. В подобных ситуациях ядро немедленно нарушает «сон» приостановленного процесса, посылая ему сигнал. Более подробно о сигналах мы поговорим в следующей главе; здесь же примем допущение, что ядро может (выборочно) возобновлять приостановленные процессы по сигналу и что процесс может распознавать получаемые сигналы. Например, если процесс обратился к системной функции чтения с терминала, ядро не будет в состоянии выполнить запрос процесса до тех пор, пока пользователь не введет данные с клавиатуры терминала (глава 10). Тем не менее, пользователь, запустивший процесс, может оставить терминал на весь день, при этом процесс останется приостановленным в ожидании ввода, а терминал может понадобиться другому пользователю. Если другой пользователь прибегнет к решительным мерам (таким как выключение терминала), ядро должно иметь возможность восстановить отключенный процесс: в качестве первого шага ядру следует возобновить приостановленный процесс по сигналу. В том, что процессы могут приостановиться на длительное время, нет ничего плохого. Приостановленный процесс занимает позицию в таблице процессов и может поэтому удлинять время поиска (ожидания) путем выполнения определенных алгоритмов, которые не занимают время центрального процессора и поэтому выполняются практически незаметно. Чтобы как-то различать между собой состояния приостанова, ядро устанавливает для приостанавливаемого процесса (при входе в это состояние) приоритет планирования на основании соответствующего параметра алгоритма sleep. То есть ядро запускает алгоритм sleep с параметром «приоритет», в котором отражается наличие уверенности в неизбежном наступлении ожидаемого события. Если приоритет превышает пороговое значение, процесс не будет преждевременно выходить из приостанова по получении сигнала, а будет продолжать ожидать наступления события. Если же значение приоритета ниже порогового, процесс будет немедленно возобновлен по получении сигнала[20]. Проверка того, имеет ли процесс уже сигнал при входе в алгоритм sleep, позволяет выяснить, приостанавливался ли процесс ранее. Например, если значение приоритета в вызове алгоритма sleep превышает пороговое значение, процесс приостанавливается в ожидании выполнения алгоритма wakeup. Если же значение приоритета ниже порогового, выполнение процесса не приостанавливается, но на сигнал процесс реагирует точно так же, как если бы он был приостановлен. Если ядро не проверит наличие сигналов перед приостановом, возможна опасность, что сигнал больше не поступит вновь и в этом случае процесс никогда не возобновится. Когда процесс «пробуждается» по сигналу (или когда он не переходит в состояние приостанова из-за наличия сигнала), ядро может выполнить алгоритм longjump (в зависимости от причины, по которой процесс был приостановлен). С помощью алгоритма longjump ядро восстанавливает ранее сохраненный контекст, если нет возможности завершить выполняемую системную функцию. Например, если из-за того, что пользователь отключил терминал, было прервано чтение данных с терминала, функция read не будет завершена, но возвратит признак ошибки. Это касается всех системных функций, которые могут быть прерваны во время приостанова. После выхода из приостанова процесс не сможет нормально продолжаться, поскольку ожидаемое событие не наступило. Перед выполнением большинства системных функций ядро сохраняет контекст процесса, используя алгоритм setjump и вызывая тем самым необходимость в последующем выполнении алгоритма longjump. Встречаются ситуации, когда ядро требует, чтобы процесс возобновился по получении сигнала, но не выполняет алгоритм longjump. Ядро запускает алгоритм sleep со специальным значением параметра «приоритет», подавляющим исполнение алгоритма longjump и заставляющим алгоритм sleep возвращать код, равный 1. Такая мера более эффективна по сравнению с немедленным выполнением алгоритма setjump перед вызовом sleep и последующим выполнением алгоритма longjump для восстановления первоначального контекста процесса. Задача заключается в том, чтобы позволить ядру очищать локальные структуры данных. Драйвер устройства, например, может выделить свои частные структуры данных и приостановиться с приоритетом, допускающим прерывания; если по сигналу его работа возобновляется, он освобождает выделенные структуры, а затем выполняет алгоритм longjump, если необходимо. Пользователь не имеет возможности проконтролировать, выполняет ли процесс алгоритм longjump; выполнение этого алгоритма зависит от причины приостановки процесса, а также от того, требуют ли структуры данных ядра внесения изменений перед выходом из системной функции. 6.7 ВЫВОДЫМы завершили рассмотрение контекста процесса. Процессы в системе UNIX могут находиться в различных логических состояниях и переходить из состояния в состояние в соответствии с установленными правилами перехода, при этом информация о состоянии сохраняется в таблице процессов и в адресном пространстве процесса. Контекст процесса состоит из пользовательского контекста и системного контекста. Пользовательский контекст состоит из программ процесса, данных, стека задачи и областей разделяемой памяти, а системный контекст состоит из статической части (запись в таблице процессов, адресное пространство процесса и информация, необходимая для отображения адресного пространства) и динамической части (стек ядра и сохраненное состояние регистров предыдущего контекстного уровня системы), которые запоминаются в стеке и выбираются из стека при выполнении процессом обращений к системным функциям, при обработке прерываний и при переключениях контекста. Пользовательский контекст процесса распадается на отдельные области, которые представляют собой непрерывные участки виртуального адресного пространства и трактуются как самостоятельные объекты использования и защиты. В модели управления памятью, которая использовалась при описании формата виртуального адресного пространства процесса, предполагалось наличие у каждой области процесса своей таблицы страниц. Ядро располагает целым набором различных алгоритмов для работы с областями. В заключительной части главы были рассмотрены алгоритмы приостанова (sleep) и возобновления (wakeup) процессов. Структуры и алгоритмы, описанные в данной главе, будут использоваться в последующих главах при рассмотрении системных функций управления процессами и планирования их выполнения, а также при объяснении различных методов распределения памяти. 6.8 УПРАЖНЕНИЯ1. Составьте алгоритм преобразования виртуальных адресов в физические, на входе которого задаются виртуальный адрес и адрес точки входа в частную таблицу областей. 2. В машинах AT&T 3B2 и NSC серии 32000 используется двухуровневая схема трансляции виртуальных адресов в физические (с сегментацией). То есть в системе поддерживается указатель на таблицу страниц, каждая запись которой может адресовать фиксированную часть адресного пространства процесса по смещению в таблице. Сравните алгоритм трансляции виртуальных адресов на этих машинах с алгоритмом, изложенным в тексте при обсуждении модели управления памятью. Подумайте над проблемами производительности и потребности в памяти для размещения вспомогательных таблиц. 3. В архитектуре системы VAX-11 поддерживаются два набора регистров защиты памяти, используемых машиной в процессе трансляции пользовательских адресов. Механизм трансляции используется тот же, что и в предыдущем пункте, за одним исключением: указателей на таблицу страниц здесь два. Если процесс располагает тремя областями — команд, данных и стека — то каким образом, используя два набора регистров, следует производить отображение областей на таблицы страниц? Увеличение стека в архитектуре системы VAX-11 идет в направлении младших виртуальных адресов. Какой тогда вид имела бы область стека? В главе 11 будет рассмотрена область разделяемой памяти: как она может быть реализована в архитектуре системы VAX-11? 4. Составьте алгоритм выделения и освобождения страниц памяти и таблиц страниц. Какие структуры данных следует использовать, чтобы достичь наивысшей производительности или наибольшей простоты реализации алгоритма? 5. Устройство управления памятью MC68451 для семейства микропроцессоров Motorola 68000 допускает выделение сегментов памяти размером от 256 байт до 16 мегабайт. Каждое (физическое) устройство управления памятью поддерживает 32 дескриптора сегментов. Опишите эффективный метод выделения памяти для этого случая. Каким образом осуществлялась бы реализация областей? 6. Рассмотрим отображение виртуальных адресов, представленное на Рисунке 6.5. Предположим, что ядро выгружает процесс (в системе с подкачкой процессов) или откачивает в область стека большое количество страниц (в системе с замещением страниц). Если через какое-то время процесс обратится к виртуальному адресу 68432, будет ли он должен обратиться к соответствующей ячейке физической памяти, из которой он считывал данные до того, как была выполнена операция выгрузки (откачки)? Если нижние уровни системы управления памятью реализуются с использованием таблицы страниц, следует ли эти таблицы располагать в тех же, что и сами страницы, местах физической памяти? *7. Можно реализовать систему, в которой стек ядра располагается над вершиной стека задачи. Подумайте о достоинствах и недостатках подобной системы. 8. Каким образом, присоединяя область к процессу, ядро может проверить то, что эта область не накладывается на виртуальные адреса областей, уже присоединенных к процессу? 9. Обратимся к алгоритму переключения контекста. Допустим, что в системе готов к выполнению только один процесс. Другими словами, ядро выбирает для выполнения процесс с только что сохраненным контекстом. Объясните, что произойдет при этом. 10. Предположим, что процесс приостановился, но в системе нет процессов, готовых к выполнению. Что произойдет, когда приостановившийся процесс переключит контекст? 11. Предположим, что процесс, выполняемый в режиме задачи, израсходовал выделенный ему квант времени и в результате прерывания по таймеру ядро выбирает для выполнения новый процесс. Объясните, почему переключение контекста произойдет на системном контекстном уровне 2. 12. В системе с замещением страниц процесс, выполняемый в режиме задачи, может столкнуться с отсутствием нужной страницы, которая не была загружена в память. В ходе обработки прерывания ядро считывает страницу из области подкачки и приостанавливается. Объясните, почему переключение контекста (в момент приостанова) произойдет на системном контекстном уровне 2. 13. Процесс использует системную функцию read с форматом вызова read(fd,buf,1024); в системе с замещением страниц памяти. Предположим, что ядро исполняет алгоритм read для считывания данных в системный буфер, однако при попытке копирования данных в адресное пространство задачи сталкивается с отсутствием нужной страницы, содержащей структуру buf, вследствие того, что она была ранее выгружена из памяти. Ядро обрабатывает возникшее прерывание, считывая отсутствующую страницу в память. Что происходит на каждом из системных контекстных уровней? Что произойдет, если программа обработки прерывания приостановится в ожидании завершения считывания страницы? 14. Что произошло бы, если бы во время копирования данных из адресного пространства задачи в память ядра (Рисунок 6.17) обнаружилось, что указанный пользователем адрес неверен? *15. При выполнении алгоритмов sleep и wakeup ядро повышает приоритет работы процессора так, чтобы не допустить прерываний, препятствующих ей. Какие отрицательные последствия могли бы возникнуть, если бы ядро не предпринимало этих действий? (Намек: ядро зачастую возобновляет приостановленные процессы прямо из программ обработки прерываний). *16. Предположим, что процесс пытается приостановиться до наступления события A, но, запуская алгоритм sleep, еще не заблокировал прерывания; допустим, что в этот момент происходит прерывание и программа его обработки пытается возобновить все процессы, приостановленные до наступления события A. Что случится с первым процессом? Не представляет ли эта ситуация опасность? Если да, то может ли ядро избежать ее возникновения? 17. Что произойдет, если ядро запустит алгоритм wakeup для всех процессов, приостановленных по адресу A, в то время, когда по этому адресу не окажется ни одного приостановленного процесса? 18. По одному адресу может приостановиться множество процессов, но ядру может потребоваться возобновление только некоторых из них — тех, которым будет послан соответствующий сигнал. С помощью механизма посылки сигналов можно идентифицировать отдельные процессы. Подумайте, какие изменения следует произвести в алгоритме wakeup для того, чтобы можно было возобновлять выполнение только одного процесса, а не всех процессов, приостановленных по заданному адресу. 19. Обращения к алгоритмам sleep и wakeup в системе Multics имеют следующий синтаксис: sleep(событие); wakeup(событие, приоритет); Таким образом, в алгоритме wakeup возобновляемому процессу присваивается приоритет. Сравните форму вызова этих алгоритмов с формой вызова события. Примечания:1 Организации, получившие права на перепродажу с надбавкой к цене за дополнительные услуги, оснащают вычислительную систему прикладными программами, касающимися конкретных областей применения, стремясь удовлетворить требования рынка. Такие организации чаще продают прикладные программы, нежели операционные системы, под управлением которых эти программы работают. 2 А что же версия IV? Модификация внутреннего варианта системы получила название «версия V». 17 Используемые в данном разделе термины «пользовательский контекст» (user-level context), «регистровый контекст» (register context), «системный контекст» (system-level context) и «контекстные уровни» (context layers) введены автором. 18 Очередность, в которой компилятор вычисляет и помещает в стек параметры функции, зависит от реализации системы. 19 Эти алгоритмы не следует путать с имеющими те же названия библиотечными функциями, которые могут вызываться непосредственно из пользовательских программ (см. [SVID 85]). Однако действие этих функций похоже. 20 Словами «выше» и «ниже» мы заменяем термины «высокий приоритет» и «низкий приоритет». Однако на практике приоритет может измеряться числами, более низкие значения которых подразумевают более высокий приоритет. |
|
||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||