|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
.newsrc CDDB/freedb.org -vпрограммы fetchmail .netrc -адо -z Часть IIПроектирование 4Модульность: четкость и простота
Существует естественная иерархия методов разделения кода на блоки, которая развивалась по мере того, как программистам приходилось управлять возрастающими уровнями сложности. Вначале все программы представляли собой огромную глыбу машинного кода. Ранние процедурные языки внесли понятие разделения на подпрограммы. Затем были изобретены служебные библиотеки для совместного использования общих полезных функций между множеством программ. После этого были разработаны отдельные адресные пространства и взаимодействующие процессы. В настоящее время не вызывает удивления тот факт, что программные системы распределяются среди множества узлов, разделенных тысячами миль сетевого кабеля. Ранние разработчики Unix были в числе первопроходцев модульности программного обеспечения. До их прихода правило модульности было теорией компьютерной науки, но не инженерной практикой. В книге "Design Rules" [2], радикальном учении об экономических основах модульности в инженерном дизайне, авторы используют развитие компьютерной индустрии в качестве учебного примера и доказывают, что сообщество Unix фактически было первым в систематическом применении модульной декомпозиции в производстве программного обеспечения в отличие от аппаратного обеспечения. Модульность аппаратного обеспечения, несомненно, была одной из основ инженерии с момента принятия стандартной винтовой резьбы в конце 19-го столетия. Здесь следует акцентировать внимание на правиле модульности: единственным способом создания сложного программного обеспечения, которое будет надежно работать, является его построение из простых модулей, соединенных четкими интерфейсами, с тем чтобы большинство проблем были локальными, а также была большая вероятность наладки или оптимизации какой-либо его части без нарушения конструкции в целом. Традиция заботиться о модульности и уделять пристальное внимание проблемам ортогональности и компактности до сих пор среди Unix-программистов проявляется гораздо ярче, чем в любой другой среде.
Первые Unix-хакеры решали данную проблему различными способами. В 1970 году вызовы функций в языках программирования были очень затратными либо ввиду запутанной семантики вызовов (PL/1, Algol), либо из-за того, что компилятор был оптимизирован для других целей, например, для увеличения скорости внутренних циклов за счет времени вызова. Таким образом, код часто писали в виде больших блоков. Кен и несколько других первых Unix-разработчиков знали, что модульность является хорошей идеей, однако они помнили о PL/1 и неохотно писали небольшие функции, чтобы не снизить производительность.
Всех сегодняшних программистов, пишущих для Unix или других операционных систем, учат создавать модули внутри программ на уровне подпрограмм. Некоторые учатся делать это на уровне модулей или абстрактных типов данных и называют это "хорошим программированием". Сторонники использования моделей проектирования прилагают благородные усилия для повышения уровня разработки и создают все новые успешные абстрактные модели, которые можно применять для организации крупномасштабной структуры программ. Здесь авторы не предпринимают попытки слишком подробно осветить все вопросы, связанные с модульностью внутри программ: во-первых, потому, что данная тема сама по себе является предметом целого тома (или нескольких томов), и, во-вторых, ввиду того, что настоящая книга посвящена искусству Unix-программирования. Здесь более конкретно рассматриваются уроки Unix-традиции, связанные с правилом модульности. В данной главе рассматривается разделение внутри процесса. Далее, в главе 7, будут рассматриваться условия, при которых следует разделять программы на множество взаимодействующих процессов, а также более специфические методики для осуществления такого разделения. 4.1. Инкапсуляция и оптимальный размер модуляПервым и наиболее важным качеством модульного кода является инкапсуляция. Правильно инкапсулированные модули не открывают свое внутренне устройство друг другу. Они не обращаются к центральной части реализации друг друга, кроме того, они не используют глобальные данные беспорядочно. Они осуществляют связь друг с другом посредством программных интерфейсов приложений (API) — компактных, четких наборов вызовов процедур и структур данных. Именно об этом гласит правило модульности. API-интерфейсам между модулями отведена двойная роль. На уровне реализации они функционируют как заслонка между модулями, которая предотвращает воздействие внутренних данных модулей на соседние модули. На уровне проектирования именно API-интерфейсы (а не описание структур данных между ними) действительно определяют структуру программ. Хороший способ проверить правильность проектирования API-интерфейса — определить, будет ли ясен смысл, если попытаться описать API обычным человеческим языком (без демонстрации фрагментов исходного кода)? Весьма целесообразно выработать привычку писать неформальные описания для API-интерфейсов до их кодирования. Более того, некоторые из наиболее способных разработчиков начинают с определения интерфейсов и написания кратких комментариев для них, а затем пишут код, поскольку процесс написания комментариев разъясняет задачи, возлагаемые на код. Подобные описания помогают организовать мышление разработчика, а также создают полезные комментарии для модулей, и в конечном итоге их можно включить в справочный документ для будущих читателей кода. Чем дальше проводится декомпозиция модулей, тем меньше становятся блоки и более важными определения API-интерфейсов, Сокращается глобальная сложность и, как следствие, уязвимость относительно ошибок. С 70-х годов прошлого века общепринятым правилом (описанном в статьях, подобных [61]) стало проектирование программных систем в виде иерархий вложенных модулей, с сохранением минимального размера модулей на каждом уровне. Возможно, однако, что подобное разбиение на модули будет слишком строгим и приведет к появлению очень маленьких модулей. Доказано [33], что при построении диаграммы плотности дефектов относительно размера модуля, кривая становится U-образной, а ее лучи направлены вверх (см. рис. 4.1). Очень большие и очень малые модули обычно служат причиной возникновения гораздо большего количества ошибок, чем модули среднего размера. Другим способом рассмотрения тех же данных является построение диаграммы количества строк кода в модуле относительно общего количества ошибок. Кривая в таком случае подобна логарифмической кривой до зоны "наилучшего восприятия", где она сглаживается (соответственно с минимумом кривой плотности дефектов), и после которой она направляется вверх (как квадрат числа, соответствующего количеству строк кода, т.е. наблюдается то, что, согласно закону Брукса[40], можно интуитивно ожидать для всей кривой).  Рис. 4.1. Качественная диаграмма количества и плотности дефектов относительно размера модуля Этот неожиданный рост количества ошибок при малых размерах модулей устойчиво наблюдается в широком диапазоне систем, реализованных на различных языках программирования. Хаттон (Hatton) предложил модель, связывающую данную нелинейную зависимость с объемом краткосрочной человеческой памяти[41]. Другая интерпретация данной нелинейной зависимости состоит в том, что при малых размерах элемента модуля возрастающая сложность интерфейсов становится доминирующим фактором. Трудно читать код, поскольку необходимо понять все еще до того, как станет возможным понять что-либо. В главе 7 рассматриваются более сложные формы разделения программ. В них также сложность интерфейсных протоколов начинает доминировать на фоне общей сложности системы по мере уменьшения размеров процессов В нематематических понятиях эмпирические результаты Хаттона предполагают точку наилучшего восприятия между 200 и 400 логических строк кода, где сведена к минимуму возможная плотность дефектов, а все остальные факторы (такие как профессионализм программиста) равны. Размер не зависит от используемого языка программирования. Это замечание весьма усиливает приводимый в данной книге совет о программировании с использованием наиболее мощных из доступных языков и инструментов. Не следует однако принимать данные числа слишком буквально. Методы подсчета строк кода в значительной степени различаются в зависимости от того, как аналитик определяет логическую строку, а также от других условий (например, от того, отбрасываются ли комментарии). Сам Хаттон в качестве приближенного подсчета советует использовать двукратное преобразование между логическими и физическими строками, рекомендуя оптимальный диапазон в 400–800 физических строк кода. 4.2. Компактность и ортогональностьКод не является единственным объектом, который имеет оптимальный размер своего элемента. Языки программирования и API-интерфейсы (например, библиотечных или системных вызовов) сталкиваются с теми же ограничениями человеческого восприятия, которые создают U-образную кривую Хаттона. Следовательно, Unix-программисты научились весьма тщательно продумывать при проектировании API-интерфейсов, наборов команд, протоколов и других способов повышения эффективности два другие свойства: компактность и ортогональность. 4.2.1. КомпактностьКомпактность — свойство, которое позволяет конструкции "поместиться" в памяти человека. Для того чтобы проверить компактность, можно использовать хороший практический тест: необходимо определить, нуждается ли обычно опытный пользователь в руководстве для работы с данной программой. Если нет, то конструкция (или, по крайней мере, ее подмножество, которое охватывает обычное использование) является компактной. Компактные программные средства обладают всеми достоинствами удобных физических инструментов. Их приятно использовать, они не препятствуют работе, позволяют повысить продуктивность. Компактность не является синонимом "слабости". Конструкция может обладать большой мощностью и гибкостью, оставаясь при этом компактной, если она построена на абстракциях, которые просты в осмыслении и хорошо взаимосвязаны. Компактность также не эквивалентна "простоте обучения". Некоторые компактные конструкции являются весьма сложными для понимания до тех пор, пока пользователь не овладеет сложной основополагающей концептуальной моделью настолько, что его мировоззрение изменится, благодаря чему компактность станет для него простой. Для многих классическим примером такой конструкции является язык Lisp.
Очень немногие программные конструкции являются компактными в абсолютном смысле, однако многие являются компактными в более широком смысле. Они имеют компактный рабочий набор, подмножество возможностей, подходящее для решения 80-ти или более процентов тех задач, для которых их обычно используют опытные пользователи. На практике для таких конструкций обычно требуется справочная карта или памятка, но не руководство. Подобные конструкции называются полукомпактными в противоположность строго компактным конструкциям. Данная идея, возможно, лучше иллюстрируется с помощью примеров. API системных вызовов Unix является полукомпактным, однако стандартная библиотека С некомпактна в любом смысле. Тогда как Unix-программисты в своей памяти без затруднений содержат подмножество системных вызовов, достаточное для большей части прикладного программирования (операции с файловой системой, сигналы и управление процессами), библиотека С в современных Unix-системах включает в себя много сотен входных точек, например, математические функции, которые "не поместятся" в памяти одного программиста. Статья "The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information" [54] является одним из основных документов по когнитивной психологии (и к тому же особой причиной того, что в Соединенных Штатах местные телефонные номера состоят из семи цифр). Статья показывает, что количество дискретных блоков информации, которое человек способен удерживать в краткосрочной памяти, равно семи плюс-минус два. Из этого следует хорошее практическое правило для оценки компактности API-интерфейсов: необходимо ли программисту помнить более семи входных точек? Любую более крупную конструкцию едва ли можно назвать компактной. Среди инструментальных средств Unix компактной является утилита make(1), a autoconf(1) и automake(1) компактными не являются. Что касается языков разметки: HTML — полукомпактный язык, a DocBook (язык разметки документов, который будет рассматриваться в главе 18) таковым не является. Макросы man(7) компактны, а разметка troff(1) — нет. Среди универсальных языков программирования С и Python являются полукомпактными, a Perl, Java, Emacs Lisp и shell — нет (особенно ввиду того, что серьезное shell-программирование требует от разработчика знаний нескольких других средств, таких как sed(1) и awk(1)). С++ — антикомпактный язык — его разработчик признал, что вряд ли какой-либо один программист когда-нибудь поймет его полностью. Некоторые конструкции, не являющиеся компактными, обладают такой внутренней избыточностью функций, что отдельные программисты с помощью рабочего подмножества языка создают для себя компактные диалекты, достаточные для решения 80% распространенных задач. Например, язык Perl характеризуется подобным типом псевдокомпактности. Такие конструкции имеют встроенные ловушки. В ситуации, когда два программиста пытаются обмениваться информацией по проекту, они могут обнаружить, что различия в их рабочих подмножествах являются значительными препятствиями для понимания и модификации кода. В то же время некомпактные конструкции автоматически не являются безнадежными или плохими. Некоторые предметные области просто являются слишком сложными, для того чтобы компактный дизайн мог их охватить. Иногда необходимо пожертвовать компактностью в обмен на некоторые другие преимущества, такие как большая мощность и диапазон. Разметка Troff, а также API BSD-сокетов являются хорошими примерами таких конструкций. Компактность как преимущество подчеркивается здесь не для того, чтобы заставить трактовать ее как абсолютное требование, а для того, чтобы научить читателей поступать подобно Unix-программистам: должным образом ценить компактность, по возможности использовать ее в конструкциях и не отбрасывать ее по неосторожности. 4.2.2. ОртогональностьОртогональность является одним из наиболее важных свойств, которое позволяет сделать даже сложные конструкции компактными. В исключительно ортогональных конструкциях операции не имеют побочных эффектов. Каждое действие (API-вызов, запуск макроса или операция языка) изменяет только один объект, не оказывая влияния на остальные. Существует один и только один способ для изменения каждого свойства любой управляемой системы. Монитор компьютера имеет ортогональное управление. Яркость можно изменить независимо от уровня контрастности, а управление цветовым балансом не зависит от них обоих (если монитор имеет данную функцию). Представим, насколько более сложно было бы настраивать монитор, в котором регулятор яркости влиял бы на цветовой баланс: пришлось бы корректировать настройки цветового баланса каждый раз после изменения яркости. Еще хуже, если бы управление контрастностью также влияло на цветовой баланс. Пришлось бы манипулировать обоими регуляторами совершенно точно и одновременно, для того чтобы изменить по отдельности контраст или цветовой баланс при сохранении другого параметра постоянным. Слишком многие программные конструкции являются неортогональными. Один общий класс ошибок проектирования, например, возникает в коде, который предназначен для считывания и преобразования данных из одного (исходного) формата в другой (целевой) формат. Проектировщик, который считает, что исходный формат всегда хранится в файле на диске, может написать функцию преобразования для открытия и чтения данных из именованного файла. Как правило, выполненный ранее ввод может также быть любым дескриптором файла. Если бы программа преобразования была спроектирована ортогонально, например, без побочных эффектов открытия файла, то она могла бы облегчить работу в дальнейшем, когда понадобилось бы преобразовать поток данных, поступающий из стандартного ввода, сетевого сокета или любого другого источника. Совет Дуга Макилроя "решать одну задачу хорошо" обычно рассматривается в контексте простоты. Однако он также неявно и, по крайней мере, в той же степени касается ортогональности. В главе 9 рассматривается программа ascii, которая печатает синонимы для названий ASCII-символов, включая шестнадцатеричные, восьмеричные и двоичные значения. Побочный эффект программы заключается в том, что она может служить в качестве быстрого конвертера для чисел в диапазоне 0-255. Это второе ее применение не является нарушением ортогональности, поскольку все функции, поддерживающие его, необходимы для реализации основной функции; они не усложняют документирование или поддержку программы. Проблемы неортогональности возникают, когда побочные эффекты усложняют ментальную модель программиста или пользователя и забываются, что приводит к неприемлемым и даже фатальным результатам. Даже если побочные эффекты не забыты, часто для их подавления приходится выполнять дополнительную работу. Превосходное обсуждение ортогональности и способов ее достижения приведено в книге "The Pragmatic Programmer" [37]. Как указывают ее авторы, ортогональность сокращает время тестирования и разработки, поскольку проверка кода, который не вызывает побочных эффектов и не зависит от побочных эффектов другого кода, упрощается, и следовательно уменьшается количество тестовых комбинаций. Если ортогональный код работает неверно, то его просто заменить другим без нарушения остальной части системы. Наконец, ортогональный код является более простым для документирования и повторного использования. Идея рефакторинга (refactoring), которая впервые возникла как явная идея школы "экстремального программирования" (Extreme Programming), тесно связана с ортогональностью. Рефакторинг кода означает изменение его структуры и организации без изменения его видимого поведения. Инженеры программной индустрии, несомненно, решают эту проблему с момента возникновения отрасли, однако определение данной практики и идентификация главного набора методик рефакторинга способствовало решению данного вопроса. Поскольку все это хорошо согласуется с основными концепциями проектирования Unix, Unix-разработчики быстро переняли терминологию и идеи рефакторинга[42]. Основные API-интерфейсы Unix были спроектированы с учетом ортогональности не идеально, но вполне успешно. Например, возможность открытия файла для записи без его блокировки для остальных пользователей принимается как должное; не все операционные системы настолько "обходительны". Системные сигналы старой школы (System III) были неортогональными, поскольку получение сигнала имело побочный эффект — происходила переустановка обработчика сигналов в стандартное значение и отключение при получении сигнала. Существуют крупные неортогональные фрагменты, такие как API BSD-сокетов, и очень крупные, такие как графические библиотеки системы X Window. Однако в целом API-интерфейс Unix является хорошим примером ортогональности: иначе, он не только не был бы, но и не мог бы широко имитироваться библиотеками С в других операционных системах. Это также является причиной того, что изучение Unix API окупается, даже для программистов, не работающих с Unix, поскольку они усваивают уроки ортогональности. 4.2.3. Правило SPOTВ книге "The Pragmatic Programmer" формулируется правило для одного частного вида ортогональности, который является особенно важным. Это правило "не повторяйтесь": внутри системы каждый блок знаний должен иметь единственное, недвусмысленное и надежное представление. В данной книге предпочтение отдано совету Брайана Кернигана называть данное правило SPOT-правилом (SPOT, или Single Point Of Truth, — единственная точка истины). Повторение ведет к противоречивости и созданию кода, который незаметно разрушается, поскольку изменяются только некоторые повторения, когда необходимо изменить все. Часто это также означает, что организация кода не была продумана должным образом. Константы, таблицы и метаданные следует объявлять и инициализировать только один раз, а затем импортировать. Всякое дублирование кода является опасным знаком. Сложность приводит к затратам; не следует оплачивать ее дважды. Нередко имеется возможность удалить дублирование кода путем рефакторинга, т.е. с помощью изменения организации кода без модификации основных алгоритмов. Иногда возникает дублирование данных, в таком случае следует ответить на несколько важных вопросов. • Если дублирование данных существует в разрабатываемом коде ввиду необходимости иметь два различных представления в двух разных местах, то возможно ли написать функцию, средство или генератор кода для создания одного представления из другого или обоих из общего источника? • Если документация дублирует данные из кода, то можно ли создать фрагменты документации из фрагментов кода или наоборот, или и то, и другое из общего представления более высокого уровня? • Если файлы заголовков и объявления интерфейсов дублируют сведения в реализации кода, то существует ли способ создания файлов заголовков и объявлений интерфейсов из данного кода? Для структур данных существует аналог SPOT-правила: "нет лишнего — нет путаницы". "Нет лишнего" означает, что структура данных (модель) должна быть минимальной, например, не следует делать ее настолько общей, чтобы она могла представлять ситуации, возникновение которых невозможно. "Нет путаницы" означает, что положения, которые должны быть обособлены в реальной проблеме, также должны быть обособлены в модели. Коротко говоря, SPOT-правило поддерживает поиск структуры данных, состояния которой имеют однозначное соответствие с состояниями реальной системы, которая будет моделироваться. Авторы могут добавить некоторые собственные следствия SPOT-правила в контексте Unix-традиций. • Если данные дублируются из-за кэширования промежуточных результатов некоторых вычислений или поиска, то следует внимательно проанализировать, не является ли это преждевременной оптимизацией. Устаревшие данные кэша (и уровни кода, необходимые для поддержки синхронизации кэша) являются "неиссякаемым" источником ошибок[43] и даже способны снизить общую производительность, если (как часто случается) издержки управления кэшем превышают ожидания разработчика. • Если наблюдается большое количество повторов шаблонного кода, то возможно ли создать их все из одного представления более высокого уровня, изменяя некоторые параметры для создания различных вариантов? Теперь модель должна быть очевидной. В мире Unix SPOT-правило редко проявляется как явная унифицирующая идея, однако, интенсивное использование генераторов кода для реализации специфических видов SPOT является весьма большой частью традиции. Данные методики рассматриваются в главе 9. 4.2.4. Компактность и единый жесткий центрОдним неочевидным, но мощным способом поддержать компактность в конструкции является ее организация вокруг устойчивого основного алгоритма, определяющего ясное формальное определение проблемы, избегая эвристики и ухищрений.
В этом заключается сила традиции Unix, но, к сожалению, это часто упускается из вида. Многие из ее эффективных инструментальных средств представляют собой тонкие упаковщики вокруг непосредственного преобразования некоторого единого мощного алгоритма. Вероятно, наиболее ясным примером таких средств является программа diff(1), средство Unix для составления списка различий между связанными файлами. Данное средство и спаренная с ним утилита patch(1) определили стиль распределенной сетевой разработки современной операционной системы Unix. Очень ценным свойством программы diff является то, что она нечасто удивляет пользователей. В ней отсутствуют частные случаи или сложные граничные условия, поскольку используется простой, математически совершенный метод сравнения последовательностей. Из этого можно сделать ряд выводов.
Таким образом, у пользователей программы diff может развиться интуитивное чувство относительно того, что будет делать программа в любой ситуации, даже без полного понимания центрального алгоритма. В Unix имеется множество других широко известных примеров, подтверждающих это. Ниже приводятся некоторые из них. • Утилита grep(1) для выбора из файлов строк, соответствующих шаблону, является простым упаковщиком вокруг формальной алгебры шаблонов регулярных выражений (описание приведено в разделе 8.2.2). Если бы данная программа испытывала недостаток в такой последовательной математической модели, то она, вероятно, выглядела бы подобно конструкции первоначального средства старейших Unix-систем, glob(1) — набор узкоспециальных шаблонов, которые невозможно было комбинировать. • уасс(1) — утилита для создания языковых анализаторов представляет собой тонкий упаковщик вокруг формальной теории грамматики LR(1). Сопутствующая ей утилита, генератор лексических анализаторов lex(1) является подобным тонким упаковщиком вокруг теории недетерминированных конечных автоматов. Все три описанные программы являются настолько "свободными от ошибок", что их корректная работа воспринимается как должное, и в то же время они считаются достаточно компактными, для того чтобы программисты могли их использовать. В основном именно благодаря тому, что данные программы были сконструированы вокруг устойчивой и обоснованно корректной алгоритмической основы, они никогда не нуждались в серьезной доводке в процессе длительного и частого использования. Противоположный формальному подход заключается в использовании эвристики — эмпирических правил, которые позволяют получить вероятностное, а не абсолютно точное решение. В некоторых случаях эвристика применяется ввиду того, что детерминированное корректное решение невозможно. В качестве примера можно рассмотреть методы фильтрации спама. Для алгоритмически идеального спам-фильтра потребовалось бы в качестве модуля полное решение проблемы понимания естественного языка. В других случаях эвристика используется из-за того, что известные формально корректные методы невероятно дороги. Примером этому служит управление виртуальной памятью. Существуют почти совершенные решения, однако они требуют такого количества измерений во время выполнения, что их издержки свели бы к нулю любой теоретический выигрыш по сравнению с эвристикой. Проблема эвристических методов заключается в том, что они увеличивают количество частных и граничных случаев. Если ничего другого не остается, то обычно следует ограничить эвристику с помощью какого-либо механизма восстановления на случай сбоя. Все обычные проблемы, связанные с увеличением сложности, сохраняются. Для управления итоговым выбором оптимальных соотношений необходимо начать их изучение. Всегда следует выяснять, действительно ли эвристические методы дают такой выигрыш производительности, который окупает затраты на них, связанные со сложностью кода. При этом не стоит оценивать наугад прирост производительности. 4.2.5. Значение освобожденияВ начале данной книги упоминалась ссылка на Дзэн об "особой передаче знаний вне священного писания". Не следует рассматривать ее как экзотическую, использованную ради стилистического эффекта. Основные понятия Unix всегда отличались свободной, Дзэн-подобной простотой. Данное качество отражено в основополагающих документах Unix, таких как книга "The С Programming Language" [42], а также доклад CACM 1974 года, в котором Unix была "представлена миру". Приведем одну известную цитату из данного документа: "... ограничение побуждает не только к экономии, но и к определенному изяществу дизайна". Источником этой простоты было стремление думать не о том, как много язык программирования или операционная система способны сделать, а о том, как мало они могут сделать. Для того чтобы проектировать с учетом компактности и ортогональности, следует начинать с нуля. Дзэн учит, что привязанность приводит к мукам; опыт проектирования программного обеспечения учит, что привязанность к поверхностным предположениям ведет к неортогональным, некомпактным конструкциям и проектам, которые терпят неудачу или становятся крайне сложными при сопровождении. Для достижения просветления и прекращения страданий Дзэн учит освобождаться. Традиция Unix преподает ценность освобождения от частных, случайных условий, с которыми была сформулирована проектная задача. Абстрагируйтесь. Упрощайте. Обобщайте. Поскольку программы создаются для разрешения проблем, полностью отделиться от проблем невозможно. Однако стоит приложить умственные усилия, для того чтобы понять, сколько предубеждений можно отбросить, и выяснить, становится ли конструкция более компактной и ортогональной в ходе этого процесса. Часто в результате появляются возможности для повторного использования кода. Различные ассоциации между Unix и Дзэн[44] также являются частью традиции Unix, и это не случайно. 4.3. Иерархичность программного обеспеченияВ проектировании иерархии функций или объектов определяется два направления. От выбора направления очень зависит иерархическое представление кода. 4.3.1. Сравнение нисходящего и восходящего программированияПервое направление является восходящим от конкретной проблемы к абстракции и представляет собой разработку исходя из специфических операций в предметной области, которые необходимо реализовать. Например, если разрабатывается программно-аппаратное обеспечение для дискового накопителя, то некоторыми низкоуровневыми примитивами могут быть "подвод головки к физическому блоку", "чтение физического блока", "запись в физический блок", "переключение светодиодного индикатора диска" и другие. Другое направление является нисходящим, от абстракции к конкретным функциям, от высокоуровневых спецификаций, описывающих проект в целом или логику приложения, вниз к отдельным операциям. Следовательно, при проектировании программного обеспечения для контроллера запоминающего устройства большой емкости, который может оперировать несколькими различными типами носителей, можно начинать с определения абстрактных операций, таких как "поиск логического блока", "чтение логического блока", "запись логического блока", "переключение индикатора активности". Данные операции отличались бы от операций аппаратного уровня с подобными названиями тем, что они были бы предназначены в качестве общих для различных видов физических устройств. Два описанных выше примера могут представлять два конструкторских подхода для одного и того же семейства аппаратного обеспечения. Выбор решения в подобных ситуациях представляется таким: абстрагировать аппаратное обеспечение (так чтобы объекты инкапсулировали реальные элементы внешнего мира, а программа просто представляла собой список операций по их обработке), либо организовать программу на основе некоторой поведенческой модели (а затем внедрить действительные аппаратные манипуляции, которые осуществляют эту модель в потоке поведенческой логики). Аналогичный выбор обнаруживается во многих других ситуациях. Предположим, что разрабатывается программа цифрового музыкального синтезатора (MIDI sequencer). Организовывать такой код можно вокруг его верхнего уровня (упорядочение дорожек) или вокруг нижнего уровня (переключение фрагментов или выборок и управление генераторами колебаний). Существует весьма точный способ анализа данных различий. Он заключается в том, чтобы выяснить, организована ли конструкция вокруг ее главного событийного цикла (стремящегося к тесной связи с высокоуровневой логикой приложения) или вокруг служебной библиотеки всех операций, которые может вызывать главный цикл. Проектировщик, разрабатывающий программу сверху вниз, начнет с обдумывания ее основного событийного цикла, а специфические события внедрит позднее. Проектировщик, работающий снизу вверх, начнет с обдумывания инкапсуляции специфических задач, а позднее соединит их в некую логическую последовательность. В качестве более крупного примера рассмотрим разработку Web-браузера. Верхним уровнем конструкции Web-браузера является спецификация ожидаемого поведения данной программы: какие типы URL-адресов ( http:или ftp:, или file:) она интерпретирует, какие виды изображений она способна визуализировать, допускает ли она использование языков Java или JavaScript и с какими ограничениями и т.д. Уровень реализации, который соответствует данному верхнему уровню, является основным событийным циклом программы. В каждой итерации цикл ожидает, накапливает и координирует действия пользователя (такие как нажатие Web-ссылки или ввод символа в поле). Однако Web-браузер для решения поставленных перед ним задач вынужден вызывать большой набор основных примитивов. Одна группа примитивов занята установкой сетевых соединений, отправкой данных по ним, а также получением ответов. В другую группу входят операции GUI-инструментария, который используется браузером. Третья группа может быть занята механическим преобразованием полученных HTML-документов из текстовой формы в объектное дерево документа. Важно то, с какой стороны этого набора начинается разработка, поскольку уровень на противоположной стороне, весьма вероятно, будет ограничен первоначальным выбором. В частности, если программа разрабатывается исключительно сверху вниз, то программист может оказаться в неудобном положении, когда примитивы предметной области, которые необходимы логике приложения, не совпадают с теми, которые фактически можно реализовать. С другой стороны, если программа разрабатывается исключительно снизу вверх, то может оказаться, что приходится проделывать большой объем работы, не соответствующей логике приложения, или просто проектируется "штабель кирпичей", в то время как необходимо "построить здание". С момента возникновения полемики по поводу структурного программирования в 60-х годах, начинающих программистов, как правило, учат, что верный подход заключается в проектировании сверху вниз. То есть в поэтапном усовершенствовании, где на абстрактном уровне определяется, для чего предназначена данная программа, и постепенном заполнении пустот реализации до тех пор, пока не будет образован точно работающий код. Нисходящий подход становится хорошей практикой, когда выполняются три предусловия: (а) можно с большой точностью определить, для решения каких задач предназначена данная программа, (b) значительные изменения спецификации в ходе реализации маловероятны и (с) большая свобода выбора на низком уровне, каким образом программа будет выполнять свои функции. Данные условия наиболее часто выполняются в программах, расположенных сравнительно близко к пользователю и высоко в стеке программ, т.е. в прикладном программировании. Однако даже в этом случае указанные предусловия часто не выполняются. Невозможно заранее определить "правильный" режим работы текстового редактора или графической программы до тех пор, пока пользовательский интерфейс не пройдет тестирование среди конечных пользователей. Исключительно нисходящее программирование часто характеризуется чрезмерным вложением трудозатрат в код, который придется удалить за ненадобностью и перестроить, поскольку интерфейс не проходит проверку в реальных условиях. Для того чтобы обезопасить себя, программисты пытаются использовать оба подхода — описывают абстрактную спецификацию как нисходящую логику приложения и собирают множество низкоуровневых примитивов предметной области в функциях или библиотеках с тем, чтобы в случае изменения высокоуровневой конструкции их можно было использовать повторно. Unix-программисты наследуют традицию, которая является центральной в системном программировании, где низкоуровневыми примитивами являются операции аппаратного уровня, которые имеют постоянный характер и чрезвычайно важны. Следовательно, "благодаря приобретенному инстинкту" они более склонны к восходящему программированию. Независимо от того является программист системным или нет, восходящий подход также может выглядеть более привлекательно при программировании исследовательским способом, когда пытаются получить контроль над феноменами аппаратного или программного обеспечения или реальными феноменами, которые еще не полностью понятны. Восходящее программирование предоставляет время и пространство для уточнения нечеткой спецификации. Кроме того, восходящее программирование "апеллирует к естественной человеческой лени" программистов: когда требуется удалить часть кода и перестроить его, при работе в нисходящем направлении приходится удалять более крупные фрагменты, чем при работе в восходящем направлении. Таким образом, создание реального кода склоняется к использованию как нисходящего, так и восходящего подходов. Нередко нисходящий и восходящий код является частью одного и того же проекта. В таком случае возникает необходимость использования связующих уровней. 4.3.2. Связующие уровниДовольно часто столкновение нисходящего и восходящего подходов является причиной некоторого беспорядка. Верхний уровень логики приложения и нижний уровень основных примитивов необходимо согласовать с помощью уровня связующей логики. Один из уроков, которые Unix-программисты осваивали десятилетиями, состоит в том, что связующая технология представляет собой опасное нагромождение, и жизненно важным является сохранение связующих уровней как можно более тонкими. Связующий уровень должен соединять другие уровни, но его не следует использовать для сокрытия "изломов" и "шероховатостей" в них. В примере с Web-браузером связующий уровень включал бы в себя код визуализации, который преобразовывает объект документа, полученный из входящего HTML- файла в сглаженное визуальное изображение в виде растра в буфере экрана, используя для формирования изображения основные примитивы GUI-интерфейса. Данный код визуализации печально известен как наиболее подверженная ошибкам часть браузера. Он содержит в себе ухищрения, направленные на разрешение проблем, которые связаны как с синтаксическим анализом HTML-кода (ввиду большого количества неверно сформированной там разметки), так и в инструментальном наборе GUI (в котором могут отсутствовать действительно необходимые примитивы). Связующий уровень Web-браузера должен служить промежуточным звеном не только между спецификацией и основными примитивами, но и между несколькими различными внешними спецификациями: работой сети, описанной в протоколе HTTP, структурой HTML-документа и различными графическими мультимедийными форматами, а также поведенческими ожиданиями пользователей при работе с GUI-интерфейсом. Однако один единственный чреватый ошибками связующий уровень не является наибольшей проблемой. Разработчик, который знает о существовании связующего уровня и пытается организовать его в средний уровень вокруг собственного набора структур данных или объектов, может в итоге получить два связующих уровня — один выше среднего уровня, а другой ниже. Талантливые, но неопытные программисты особенно склонны попадать в эту ловушку. Они правильно выбирают все основные наборы классов (логику приложения, средний уровень и примитивы предметной области) и переделывают их подобно примерам из учебников, и только сбиваются с пути по мере того, как величина нескольких связующих уровней, необходимых для интеграции всего привлекательного кода, становится все больше и больше. Принцип тонкого связующего уровня можно рассматривать как уточнение правила разделения. Политика (т.е. логика приложения) должна быть четко обособлена от механизма (то есть основных примитивов), однако очень большой код, который не является ни политикой, ни механизмом, скорее всего, свидетельствует о том, что его функции минимальны и что он только увеличивает общую сложность в системе. 4.3.3. Учебный пример: язык С считается тонким связующим уровнемЯзык С является хорошим примером эффективности тонкого связующего уровня. В конце 90-х годов Джеррит Блаау (Gerrit Blaauw) и Фред Брукс (Fred Brooks) в книге "Computer Architecture: Concepts and Evolution" [4] отмечали, что архитектура всех поколений компьютеров (от ранних мэйнфреймов, мини-компьютеров и рабочих станций до PC) стремилась к конвергенции. Чем более поздней была конструкция в своем технологическом поколении, тем плотнее она приближался к тому, что Блаау и Брукс назвали "классической архитектурой" (classical architecture): двоичное представление, линейное адресное пространство, разграничение памяти и рабочего хранилища (регистров), универсальные регистры, определение адреса, занимающего фиксированное число байтов, двухадресные команды, порядок следования байтов[45] и типы данных как последовательное множество с размерами, кратными 4, либо 6 (6-битовые семейства в настоящее время устарело). Томпсон и Ритчи разрабатывали язык С как подобие структурированного ассемблера для идеализированной архитектуры процессора и памяти, которую, как они ожидали, можно было смоделировать на большинстве традиционных компьютеров. По счастливой случайности, их моделью для идеализированного процессора был компьютер PDP-11, весьма продуманная и изящная конструкция мини-компьютера, которая вплотную приближалась к классической архитектуре Блаау и Брукса. Здраво рассуждая, Томпсон и Ритчи отказались внедрять в С большинство характерных особенностей (таких как порядок байтов) там, где PDP-11 ему не соответствовал[46]. PDP-11 стал важной моделью для последующих поколений микропроцессоров. Оказалось, что базовые абстракции С весьма четко охватывают классическую архитектуру. Таким образом, С начинался как хорошее дополнение для микропроцессоров и, вместо того чтобы стать непригодным в связи с тем, что его предположения устарели, фактически становился лучше, по мере того, как аппаратное обеспечение все более сильно сливалось с классической архитектурой. Одним примечательным примером этой конвергенции была замена в 1985 году процессора Intel 286 с неуклюжей сегментной адресацией памяти процессором серии 386 с большим простым адресным пространством памяти. Чистый язык С был действительно лучшим дополнением для процессоров 386, чем для процессоров 286-й серии. Не случайно, что экспериментальная эра в компьютерной архитектуре завершилась в середине 80-х годов прошлого века, т.е. в то время, когда язык С (и его ближайший потомок С++) побеждали все предшествующие им универсальные языки программирования. Язык С, разработанный как тонкий, но гибкий уровень над классической архитектурой, выглядит в перспективе двух десятилетий как почти наилучшая из возможных конструкций для ниши структурированного ассемблера, которую он и должен был занять. В дополнение к компактности, ортогональности и независимости (от машинной архитектуры, на которой он первоначально был разработан), данный язык также имеет важное качество прозрачности, рассмотренное в главе 6. В конструкции нескольких языков программирования, которые, возможно, являются лучшими, потребовалось внести серьезные изменения (такие как введение функции сборки мусора в памяти), чтобы создать достаточную функциональную дистанцию от С и избежать вытеснения им. Эту историю стоит вспоминать и переосмысливать, поскольку пример языка С показывает, насколько мощной может быть четкая, минималистская конструкция. Если бы Томпсон и Ритчи были менее дальновидными, то они создали бы язык, который делал бы гораздо больше, опирался бы на более строгие предположения, никогда удовлетворительно не переносился бы с исходной аппаратной платформы и исчез бы вместе с ней. Напротив, язык С расцвел, и с тех пор пример Томпсона и Ритчи влияет на стиль Unix-разработки. Однажды в беседе о конструировании самолетов, писатель, искатель приключений, художник и авиаинженер Антуан де Сент-Экзюпери подчеркнул: "Совершенство достигается не в тот момент, когда более нечего добавить, а тогда, когда нечего более удалить". Ритчи и Томпсон жили по этому принципу. Долгое время после того как ресурсные ограничения на ранних Unix-программах были смягчены, они работали над тем, чтобы поддерживать С в виде настолько тонкого уровня над аппаратным обеспечением, насколько это возможно.
История С также подтверждает важность существования работающей эталонной реализации до стандартизации. Повторно данная тема затрагивается в главе 17, где рассматривается развитие стандартов С и Unix. 4.4. БиблиотекиОдним из последствий того влияния, которое стиль Unix-программирования оказал на модульность и четко определенные API-интерфейсы, является устойчивая тенденция к разложению программ на фрагменты связующего уровня, объединяющего семейства библиотек, особенно общих библиотек (эквивалентов структур, которые в Windows и других операционных системах называются динамически подключаемыми библиотеками или DLL (Dynamically-Linked Libraries)). Если подходить к проектированию тщательно и обдуманно, то часто возникает возможность разделить программу таким образом, чтобы она состояла из главной части поддержки пользовательского интерфейса (т.е. политики) и совокупности служебных подпрограмм (т.е. механизма) без связующего уровня вообще. Данный подход представляется особенно целесообразным в ситуации, когда программа должна выполнять большое количество узкоспециальных операций с такими структурами данных, как графические изображения, пакеты сетевых протоколов или блоки управления аппаратного интерфейса. В статье "The Discipline and Method Architecture for Reusable Libraries" [87] собрано несколько общих полезных, конструктивных советов, исходящих из традиций Unix, особенно полезных для решения проблем управления ресурсами в библиотеках такого вида. Практика, при которой подобное разделение на уровни осуществляется явно, в Unix-программировании является стандартной. При этом служебные подпрограммы собираются в библиотеку, которая документируется отдельно. В таких программах клиентская часть специализируется на задачах пользовательского интерфейса и протоколе высокого уровня. Несколько большего внимания к конструкции требует отделение оригинальной клиентской части и ее замена другими, адаптированными для иных целей. Некоторые другие преимущества позволит раскрыть учебный пример. Существует оборотная сторона данной проблемы. В мире Unix библиотеки, поставляемые как библиотеки, должны сопровождаться тестовыми программами.
Кроме упрощения процесса обучения, тестовые программы библиотек часто создают превосходные тестовые структуры. Поэтому опытные Unix-программисты видят в них не только форму для приложения умственных усилий пользователя библиотеки, но и свидетельство того, что код, вероятно, был хорошо протестирован. Важной формой создания иерархии библиотек является подключаемая подпрограмма (plugin) — библиотека с набором известных входных точек, которая динамически загружается после запуска и предназначена для решения специализированной задачи. Для работы таких подпрограмм необходимо, чтобы вызывающая программа была организована в значительной степени как документированная служебная библиотека, в которую подключаемая подпрограмма может направить обратный вызов. 4.4.1. Учебный пример: подключаемые подпрограммы GIMPПрограмма GIMP (GNU Image Manipulation program— программа обработки изображений) разрабатывалась как графический редактор с управлением посредством интерактивного GUI-интерфейса. Однако GIMP построена как библиотека подпрограмм обработки изображений и вспомогательных подпрограмм, которые вызываются сравнительно тонким уровнем управляющего кода. Управляющий код "знает" о GUI, но не имеет непосредственной информации о форматах изображений. Библиотечные подпрограммы, напротив, распознают форматы изображений, но не имеют информации о GUI-интерфейсе. Библиотечный уровень документирован (и фактически распространяется в виде пакета "libgimp" для использования другими программами). Это означает, что программы на языке С, которые называются "подключаемыми подпрограммами", могут динамически загружаться в GIMP и вызывать библиотеку для обработки изображений, фактически принимая на себя управление на том же уровне, что и GUI-интерфейс (см. рис. 4.2).  Рис. 4.2. Связи между вызывающей и вызываемой программой в редакторе GIMP с загруженной подключаемой подпрограммой Подключаемые подпрограммы используются для осуществления множества специализированных преобразований. В число таких преобразований входят: обработка карты цветов, размывание границ и очистка изображения; чтение и запись форматов, не характерных для ядра GIMP; такие расширения, как редактирование мультипликации и тем оконных менеджеров; многие другие виды обработки изображений, которые могут быть автоматизированы с помощью сценариев, содержащих логику обработки изображений в ядре GIMP. Перечень подключаемых подпрограмм для GIMP доступен в World Wide Web. Несмотря на то, что большинство подключаемых подпрограмм для GIMP являются небольшими и простыми C-программами, существует также возможность написать подпрограмму, которая открывает библиотечный API-интерфейс для языков сценариев. Данная возможность описывается в главе 11 в ходе изучения модели "многопараметрических (polyvalent) программ". 4.5. Unix и объектно-ориентированные языкиС середины 80-х годов прошлого века большинство новых конструкций языков обладают собственной поддержкой объектно-ориентированного программирования (Object-Oriented Programming — OO). Напомним, что в объектно-ориентированном программировании функции, воздействующие на определенную структуру данных, инкапсулируются вместе с данными в объект, который может рассматриваться как единое целое. В противоположность этому, модули в не-ОО-языках делают связь между данными и воздействующими на них функциями весьма второстепенной, и модули часто воздействуют на данные и внутреннее устройство других модулей. Первоначально идея ОО-дизайна позитивно сказалась в конструировании графических систем, графических пользовательских интерфейсов и определенных видов моделирования. К удивлению и постепенному разочарованию многих, обнаружились трудности в проявлении существенных преимуществ вне этих областей. Причины этого заслуживают отдельного рассмотрения. Существует некоторый конфликт между Unix-традицией модульности и моделями использования, которые развились вокруг ОО-языков. Unix-программисты всегда несколько более скептически относились к ОО-технологии, чем их коллеги, работающие в других операционных системах. Частично из-за правила разнообразия. Слишком часто ОО-подход объявлялся единственно верным решением проблемы сложности программного обеспечения. Однако здесь кроется еще одна проблема, которую стоит исследовать, прежде чем оценивать определенные ОО (объектно-ориентированные) языки в главе 14. Рассмотрение этой проблемы также поможет лучше описать некоторые характеристики Unix-стиля не-ОО-программирования. Выше отмечалось, что Unix-традиция модульности является традицией тонкого связующего, минималистского подхода с несколькими уровнями абстракции между аппаратным обеспечением и объектами верхнего уровня программ. Частично это является влиянием языка С. Моделирование истинных объектов в языке С обычно сопряжено с большими усилиями. Вследствие этого нагромождение уровней абстракции является утомительным. Поэтому иерархии объектов в С склонны к относительной простоте и прозрачности. Даже применяя другие языки, Unix-программисты склонны переносить стиль использования тонкого связующего уровня и простой иерархии, которому они научились, используя Unix-модели. ОО-языки упрощают абстракцию, возможно, даже слишком упрощают. Они поддерживают создание структур с большим количеством связующего кода и сложными уровнями. Это может оказаться полезным в случае, если предметная область является действительно сложной и требует множества абстракций, и вместе с тем такой подход может обернуться неприятностями, если программисты реализуют простые вещи сложными способами, просто потому что им известны эти способы и они умеют ими пользоваться. Все ОО-языки несколько склонны "втягивать" программистов в ловушку избыточной иерархии. Объектные структуры и браузеры объектов не являются заменой хорошего дизайна или документации, но часто рассматриваются как таковые. Чрезмерное количество уровней разрушает прозрачность: крайне затрудняется их просмотр и анализ ментальной модели, которую по существу реализует код. Всецело нарушаются правила простоты, ясности и прозрачности, а в результате код наполняется скрытыми ошибками и создает постоянные проблемы при сопровождении. Данная тенденция, вероятно, усугубляется тем, что множество курсов по программированию преподают громоздкую иерархию как способ удовлетворения правила представления. С этой точки зрения множество классов приравниваются к внедрению знаний в данные. Проблема данного подхода заключается в том, что слишком часто "развитые данные" в связующих уровнях фактически не относятся к какому-либо естественному объекту в области действия программы — они предназначены только для связующего уровня. (Одним из верных признаков этого является распространение абстрактных подклассов или "смесей".) Другим побочным эффектом ОО-абстракции представляется то, что постепенно исчезают возможности для оптимизации. Например, а+а+а+а может стать а*4 или даже a<<2, в случае если a — целое число. Однако если кто-либо создаст класс с операторами, то ничто не будет указывать на то, являются ли они коммутативными, дистрибутивными или ассоциативными. Так как создатель класса не предполагал показывать внутреннее устройство объекта, то невозможно определить, какое из двух эквивалентных выражений более эффективно. Само по себе это не является достаточной причиной избегать использования ОО-методик в новых проектах; это было бы преждевременной оптимизацией. Однако это причина подумать дважды, прежде чем преобразовывать не-ОО-код в иерархию классов. Для Unix-программистов характерно инстинктивное осознание данных проблем. Данная тенденция представляется одной из причин, по которой ОО-языкам в Unix не удалось вытеснить не-ОО-конструкции, такие как С, Perl (который в действительности обладает ОО-средствами, но они используются не широко) и shell. В мире Unix больше открытой критики ОО-языков, чем это позволяют ортодоксы в других операционных системах. Unix-программисты знают, когда не использовать объектно-ориентированный подход, а, если они действительно используют ОО-языки, то тратят большие усилия, пытаясь сохранить объектные конструкции четкими. Как однажды (в несколько другом контексте) заметил автор книги "The Elements of Networking Style" [60]: "... если программист знает, что делает, то трех уровней будет достаточно, если же нет, то не помогут даже семнадцать уровней". Одной из причин того, что ОО-языки преуспели в большинстве характерных для них предметных областей (GUI-интерфейсы, моделирование, графические средства), возможно, является то, что в этих областях относительно трудно неправильно определить онтологию типов. Например, в GUI-интерфейсах и графических средствах присутствует довольно естественное соответствие между манипулируемыми визуальными объектами и классами. Если выясняется, что создается большое количество классов, которые не имеют очевидного соответствия с тем, что происходит на экране, то, соответственно, легко заметить, что связующий уровень стал слишком большим. Одна из основных трудностей проектирования в стиле Unix состоит в комбинации достоинств отделения (упрощение и обобщение проблем из их исходного контекста) с достоинствами тонкого связующего уровня и плоских, простых и прозрачных иерархий кода и конструкции. Некоторые из этих моментов будут повторно рассматриваться при обсуждении объектно-ориентированных языков программирования в главе 14. 4.6. Создание модульного кодаМодульность выражается в хорошем коде, но главным образом она является следствием хорошего проектирования. Ниже приведен ряд вопросов о разрабатываемом коде, ответы на которые могут помочь программисту в улучшении модульности кода. • Сколько глобальных переменных присутствует в коде? Глобальные переменные — разрушители модульности, простой способ передачи информации из одних компонентов в другие неаккуратным и беспорядочным путем[47]. • Остаются ли размеры отдельных модулей в пределах зоны наилучшего восприятия Хаттона? Если это не так, то возможно появление долговременных проблем при сопровождении. Известны ли пределы зоны наилучшего восприятия для данного программиста? Известны ли пределы зоны для других сотрудничающих программистов? Если нет, то наилучшим решением будет придерживаться консервативной точки зрения и сохранять размеры, ближайшие к нижней границе диапазона Хаттона. • Не слишком ли крупные отдельные функции в модулях? Это не столько вопрос количества строк кода, сколько его внутренней сложности. Если неформально в одной строке невозможно описать взаимодействие функции и вызывающей ее программы, то, вероятно, размер функции слишком велик[48].
• Имеет ли код внутренние API-интерфейсы — т.е. наборы вызовов функций и структур данных, которые можно описать как цельные блоки, каждый из которых изолирует некоторый уровень функций от остальной части кода? Хороший API имеет смысл и понятен без рассмотрения скрытой в нем реализации. Классическая проверка заключается в том, чтобы попытаться описать API другому программисту по телефону. Если это не удалось, то весьма вероятно, что интерфейс слишком сложен и спроектирован неудачно. • Имеет ли любой из разрабатываемых API-интерфейсов более семи входных точек? Имеет ли какой-либо из классов более семи методов? Имеют ли структуры данных более семи членов? • Каково распределение входных точек в каждом модуле проекта?[49] Не кажется ли распределение неравномерным? Действительно ли в некоторых модулях необходимо такое большое количество входных точек? Сложность модуля также растет, как квадрат числа входных точек — еще одна причина того, что простые API лучше, чем сложные. Может оказаться полезным сравнение данных вопросов с перечнем вопросов о прозрачности и воспринимаемости в главе 6. 5Текстовое представление данных: ясные протоколы лежат в основе хорошей практики В данной главе рассматриваются традиции Unix в аспекте двух различных, но тесно связанных друг с другом видов проектирования: проектирования форматов файлов для сохранения данных приложений в постоянном хранилище памяти и проектирования протоколов прикладного уровня для передачи (возможно, через сеть) данных и команд между взаимодействующими программами. Объединяет оба вида проектирования то, что они задействуют сериализацию структур данных. Для внутренней работы компьютерных программ наиболее удобным представлением сложной структуры данных является то, в котором все поля имеют характерный для конкретной машины формат данных (например, представление целых чисел со знаком в двоичном дополнительном коде) и все указатели являются абсолютными адресами памяти (в противоположность, например, именованным ссылкам). Однако такие формы представления не подходят для хранения и передачи. Адреса памяти в структуре данных теряют свое значение за пределами оперативной памяти, и выпуск необработанных собственных форматов данных приводит к проблемам взаимодействия при передаче данных между машинами с различными соглашениями (например, с обратным и прямым порядком следования байтов или между 32- и 64-битовой архитектурами). Для передачи и хранения передаваемое квази-пространственное расположение структур данных, таких как связные списки, должно быть сглажено или сериализовано в представление потока байтов, из которого впоследствии можно будет восстановить исходную структуру. Операция сериализации (сохранения) иногда называется маршалингом (marshaling), а обратная ей операция (загрузка) — демаршалингом (unmarshaling). Данные термины применимы по отношению к объектам в ОО-языках программирования, таких как С++, Python или Java, вместе с тем они в равной степени применимы для таких операций, как загрузка графического файла во внутреннюю память графического редактора и сохранение файла после модификации. Значительной частью того, что поддерживают программисты на С и С++, является специальный код для операций маршалинга и демаршалинга, даже если выбранная форма представления для сохранения и восстановления также проста как дамп бинарной структуры (распространенная методика в не Unix-средах). Современные языки, такие как Python и Java, имеют встроенные функции демаршалинга и маршалинга, которые применимы к любому объекту или потоку байтов, представляющему объект, и в значительной степени сокращают трудозатраты. Однако эти простые методы часто неудовлетворительны в силу различных причин, включая упомянутые выше проблемы взаимодействия между машинами, а также ту негативную особенность, которая связана с их непрозрачностью для других средств. В ситуации, когда приложение представляет собой сетевой протокол, исходя из соображений экономичности, иногда целесообразно представлять внутреннюю структуру данных (такую, например, как сообщение с адресами отправителя и получателя) не в виде одного большого двоичного объекта данных, а в виде последовательности транзакций или сообщений, которые могут быть отклонены принимающей машиной (так что, например, большое сообщение, может быть отклонено, если адрес получателя указан неверно). Способность к взаимодействию, прозрачность, расширяемость и экономичность хранения или транзакций — важнейшие темы в проектировании форматов файлов и прикладных протоколов. Способность к взаимодействию и прозрачность требуют, чтобы при проектировании таких конструкций основное внимание было уделено четким формам представления данных, а не удобству реализации или максимальной производительности. Расширяемость также благоприятствует текстовым протоколам, так как двоичные протоколы часто труднее расширять или четко разделять на подмножества. Экономичность транзакций иногда заставляет двигаться в противоположном направлении, однако следует понимать, что выдвижение данного признака на первый план является некоторой формой преждевременной оптимизации. Более дальновидным будет все же противостоять ей. Наконец, необходимо отметить отличие между форматами файлов данных и конфигурационных файлов, которые часто используются для установки параметров запуска Unix-программ. Самое основное отличие заключается в том, что (за редкими исключениями, такими как конфигурационный интерфейс редактора GNU Emacs) программы обычно не изменяют свои конфигурационные файлы — информационный поток является односторонним (от файла, считываемого при запуске, к настройкам приложения). С другой стороны, форматы файлов данных связывают свойства с именованными ресурсами, и такие файлы считываются и записываются соответствующими приложениями. Конфигурационные файлы, как правило, редактируются вручную и имеют небольшие размеры, тогда как файлы данных генерируются программами и могут достигать произвольных размеров. Исторически Unix обладает связанными, но различными наборами соглашений для данных двух видов представления. Соглашения для конфигурационных файлов рассматриваются в главе 10; в данной главе описываются только соглашения для файлов данных. 5.1. Важность текстовой формы представленияКаналы и сокеты передают двоичные данные так же, как текст. Однако есть важные причины, для того чтобы примеры, рассматриваемые в главе 7, были текстовыми: причины, связанные с рекомендацией Дуга Макилроя, приведенной в главе 1. Текстовые потоки являются ценным универсальным форматом, поскольку они просты для чтения, записи и редактирования человеком без использования специализированных инструментов. Данные форматы прозрачны (или могут быть спроектированы как таковые). Кроме того, сами ограничения текстовых потоков способствуют усилению инкапсуляции. Препятствуя сложным формам представления с богатой, плотно закодированной структурой, текстовые потоки также препятствуют созданию программ, которые смешивают внутренние компоненты друг друга. Текстовые потоки также способствуют усилению инкапсуляции. Эта проблема рассматривается в главе 7 при обсуждении технологии RPC. Если программист испытывает острое желание разработать сложный двоичный формат файла или сложный двоичный прикладной протокол, как правило, мудрым решением будет приостановить работу до тех пор, пока это желание не пройдет. Если основной целью такой разработки является производительность, то внедрение сжатия текстового потока на каком-либо уровне выше или ниже данного протокола прикладного уровня предоставит аккуратную и, вероятно, более производительную конструкцию, чем двоичный протокол (текст хорошо и быстро сжимается).
Проектирование текстового протокола часто защищает систему в будущем, поскольку диапазоны в числовых полях не подразумеваются самим форматом. В двоичных форматах обычно определяется количество битов, выделенных для данного значения, и расширение таких форматов является трудной задачей. Например, протокол IPv4 допускает использование только 32-битового адреса. Для того чтобы увеличить размер до 128 бит (как это сделано в протоколе IPv6), требуется значительная реконструкция[50]. Напротив, если требуется ввести большее значение в текстовый формат, то его необходимо просто записать. Возможно, что какая-либо программа не способна принимать значения в данном диапазоне, однако, программу обычно проще модифицировать, чем изменять все данные, хранящиеся в этом формате. Если планируется манипулировать достаточно большими блоками данных, применение двоичного протокола можно считать оправданным, когда разработчик действительно заботится о наибольшей плотности записи имеющегося носителя, или когда существуют жесткие ограничения времени или инструкций, необходимых для интерпретации данных в структуру ядра. Форматы для больших изображений и мультимедиа данных в некоторых случаях являются примерами первого случая, а сетевые протоколы с жесткими ограничениями задержки — примером второго.
Данные вопросы справедливы и в других предельных случаях, в системе X Window, например, при проектировании форматов графических файлов, предназначенных для хранения очень больших изображений. Однако они обычно также свидетельствуют о преждевременной оптимизации. Текстовые форматы не обязательно имеют более низкую плотность записи, чем двоичные. В них все-таки используются семь из восьми битов каждого байта. И выигрыш в связи с тем, что не требуется осуществлять синтаксический анализ текста, как правило, нивелируется, когда впервые приходится создавать тестовую нагрузку или пристально изучать пример формата, сгенерированный программой. Кроме того, проектирование компактных двоичных форматов значительно затруднено, когда необходимо сделать их четко расширяемыми. С данной проблемой столкнулись разработчики X Window.
Когда разработчик полагает, что столкнулся с предельным случаем, оправдывающим двоичный формат файлов или протокол, следует предусмотреть и возможность расширения пространства в конструкции, необходимого для дальнейшего роста. 5.1.1. Учебный пример: формат файлов паролей в UnixВо многих операционных системах данные пользователей, необходимые для регистрации и запуска пользовательского сеанса, представляют собой трудную для понимания двоичную базу данных. В противоположность этому, в операционной системе Unix такие данные содержатся в текстовом файле с записями, каждая из которых является строкой, разделенной на поля с помощью знаков двоеточия. В приведенном ниже примере содержатся некоторые случайно выбранные строки. Пример 5.1. Пример файла паролейgames:*:2:100:games:/usr/games: gopher:*:13:30:gopher:/usr/lib/gopher-data: ftp:*:14:50:FTP User:/home/ftp: esr:0SmFuPnH5JINs:23:23:Eric S. Raymond:/home/esr: nobody:*:99:99:Nobody:/: Даже не зная ничего о семантике полей, можно отметить, что более плотно упаковать данные в двоичном формате было бы весьма трудно. Ограничивающие поля символы двоеточия должны были бы иметь функциональные эквиваленты, которые, как минимум, занимали бы столько же места (обычно либо определенное количество байтов, либо строки нулевой длины). Каждая запись, содержащая данные одного пользователя, должна была бы иметь ограничитель (который едва ли мог бы быть короче, чем один символ новой строки), либо неэкономно заполняться до фиксированной длины. В действительности, перспективы сохранения пространства посредством двоичного кодирования почти полностью исчезают, если известна фактическая семантика данных. Значения числового идентификатора пользователя (третье поле) и идентификатора группы (четвертое поле) являются целыми числами, поэтому на большинстве машин двоичное представление данных идентификаторов заняло бы по крайней мере 4 байта и было бы длиннее текста для всех значений до 999. Это можно проигнорировать и предположить наилучший случай, при котором значения числовых полей находятся в диапазоне 0-255. В таком случае можно было бы уплотнить числовые поля (третье и четвертое) путем сокращения каждого числа до одного байта и восьмибитового кодирования строки пароля (второе поле). В данном примере это дало бы около 8% сокращения размера. 8% мнимой неэффективности текстового формата имеют весьма большое значение. Они позволяют избежать наложения произвольного ограничения на диапазон числовых полей. Они дают возможность модифицировать файл паролей, используя любой старый предпочтительный текстовый редактор, т.е. освобождают от необходимости создавать специализированный инструмент для редактирования двоичного формата (хотя непосредственно в случае файла паролей необходимо быть особенно осторожным с одновременным редактированием). Кроме того, появляется возможность выполнять специальный поиск, фильтрацию и отчеты по учетной информации пользователей с помощью средств обработки текстовых потоков, таких как grep(1). Действительно, необходимо быть осторожным, чтобы не вставить символ двоеточия в какое-либо текстовое поле. Хорошей практикой является создание такого кода записи файла, который предваряет вставляемые символы двоеточия знаком переключения (escape character), а код чтения файла затем интерпретирует данный символ. В традиции Unix для этих целей предпочтительно использовать символ обратной косой черты. Тот факт, что структурная информация передается с помощью позиции поля, а не с помощью явной метки, ускоряет чтение и запись данного формата, но сам формат становится несколько жестким. Если ожидается изменение набора свойств, связанных с ключом, с любой частотой, то, вероятно, лучше подойдет один из теговых форматов, которые описываются ниже. Экономичность не является главной проблемой файлов паролей, с которой следовало бы начинать обсуждение, поскольку такие файлы обычно считываются редко[51] и нечасто модифицируются. Способность к взаимодействию в данном случае не является проблемой, поскольку некоторые данные в файле (особенно номера пользователей и групп) не переносятся с машины, на которой они были созданы. Таким образом, в случае файлов паролей совершенно ясно, что следование критериям прозрачности было правильным. 5.1.2. Учебный пример: формат файлов |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

| Регулярное выражение | Соответствующая строка |
|---|---|
"x.y" | x, за которым следует любой символ с последующим у |
"x\.y" | х, за которым следует точка с последующим у |
"xz?y" | х, за которым следует не более одного символа z с последующим у, т.е. "xy" или "xzy", но не "xz" или "xdy" |
"xz*y" | х, за которым следует любое количество символов z, за которыми следует y, т.е. "xy" или "xzy" или "xzzzy", но не "xz" или "xdy" |
"xz+y" | x, за которым следует один или несколько экземпляров символа z, за которыми следует у, т.е. " xzy" или " xzzy", но не " xy", " xz" или " xdy" |
"s[xyz]t" | s, за которым следует любой из символов х, уили z, за которым следует t, т.е. " sxt", " syt" или " szt", но не " st" или " sat" |
"a[x0-9]b" | а, за которым следует либо х, либо символ в диапазоне 0-9, за которым следует b, то есть, " axb", " a0b" или " а4b", но не " ab" или " aab" |
"s[^xyz] t" | s, за которым следует любой символ, кроме х, уили z, за которым следует t, т.е. " sdt" или " set", но не "sxt", " syt" или " szt" |
"s[^x0-9]t" | s, за которым следует любой символ, кроме xили символа в диапазоне 0-9, за которым следует t, т.е. " slt" или " smt", но не " sxt", " s0t" или " s4t" |
"^x” | x в начале строки, т.е. "xzy" или " xzzy", но не " yzy" или " уху" |
"x$" | х в конце строки, т.е. "yzx" или " yx", но не " yxz" или " zxy" |
Существует большое количество второстепенных вариантов записи регулярных выражений.
1. Выражения-маски. Ограниченный набор соглашений по применению символов-шаблонов (wildcard), использовавшийся в ранних оболочках Unix для сопоставления имен файлов. Существует всего 3 символа-шаблона:
*— соответствует любой последовательности символов (как .* в других вариантах);
?— соответствует любому единичному символу (как . в других вариантах);
[...]— соответствует классу символов как в других вариантах. В некоторых оболочках (csh, bash, zsh) позднее был добавлен шаблон
{}для выбора подстроки. Таким образом, выражение
x{a,b}cсоответствует строкам
xacили
xbc, но не
xc. В некоторых оболочках выражения-маски получили дальнейшее развитие в направлении расширения регулярных выражений.
2. Базовые регулярные выражения. Форма записи, принятая в исходной утилите grep(1) для извлечения из файла строк, соответствующих заданному регулярному выражению. Выражения этого типа также применяются в строковом редакторе ed(1) и потоковом редакторе sed(1). Профессионалы старой школы Unix считают данное выражение основной, или "унифицированной", разновидностью регулярных выражений. Пользователи, впервые столкнувшиеся с более современными инструментами, склонны использовать расширенную форму, которая описана ниже.
3. Расширенные регулярные выражения. Запись, принятая в расширенной версии grep, egrep(1) для извлечения из файла строк, соответствующих заданному регулярному выражению. Регулярные выражения в Lex и редакторе Emacs весьма близки к egrep-разновидности.
4. Регулярные выражения языка Perl. Форма записи, принятая в regexp-функциях языков Perl и Python. Выражения этого типа являются более мощными по сравнению с egrep-вариантом.
После рассмотрения основных примеров в таблице 8.2 приведена сводка стандартных шаблонов для регулярных выражений. Следует отметить, что в таблицу не включен вариант выражений-масок, поэтому запись "для всех" означает только 3 типа: базовый, расширенный/Emacs и Perl/Python[79].
Таблица 8.2. Введение в операции с регулярными выражениями
| Символ-шаблон | Поддерживается | Соответствующая строка |
|---|---|---|
\ | во всех | Начало escape-последовательности. Определяет, следует ли интерпретировать последующий знак как шаблон. Последующие буквы или цифры интерпретируются различными способами в зависимости от программы |
. | во всех | Любой символ |
^ | во всех | Начало строки |
$ | во всех | Конец строки |
[...] | во всех | Любой из символов, указанных в скобках |
[^...] | во всех | Любые символы, кроме указанных в скобках |
* | во всех | Любое количество экземпляров предыдущего элемента |
? | egrep/Emacs, Perl/Python | Ни одного или один экземпляр предыдущего элемента |
+ | egrep/Emacs, Perl/Python | Один или несколько экземпляров предыдущего элемента |
{n} | egrep, Perl/Python; как \{n\}в Emacs | В точности n повторений предыдущего элемента. Не поддерживается некоторыми старыми regexp-средствами |
{n,} | egrep, Perl/Python; как \{n,\}в Emacs | n или более повторений предыдущего элемента. Не поддерживается некоторыми старыми regexp-средствами |
{m,n} | egrep, Perl/Python; как \{m,n\}в Emacs | Минимум m и максимум n повторений предыдущего элемента. Не поддерживается некоторыми старыми regexp-средствами |
| | | egrep, Perl/Python; как \|в Emacs | Элемент слева или справа. Обычно используется с некоторой формой группирующих разделителей |
(...) | Perl/Python; как \(...\)в более старых версиях | Интерпретировать данный шаблон как группу (в более новых regexp-функциях, например в языках Perl и Python). Более старые средства, такие как regexp-функции в Emacs и в утилите grep требуют записи \(...\) |
В новых языках с поддержкой регулярных выражений установилась практика Perl/Python-варианта. Он является более прозрачным, чем остальные, особенно потому, что обратная косая черта перед не алфавитно-цифровым символом всегда означает, что данный символ трактуется буквально, что значительно устраняет путаницу при ссылке на элементы регулярных выражений.
Регулярные выражения являются исключительным примером того, насколько лаконичным может быть мини-язык. Простые регулярные выражения отражают режим распознавания, который иначе пришлось бы реализовывать с помощью сотен строк туманного, чреватого ошибками кода.
8.2.3. Учебный пример: Glade
Glade представляет собой средство разработки интерфейсов для библиотеки Х-инструментария[80] GTK с открытым исходным кодом. Glade позволяет разрабатывать GUI-интерфейс путем интерактивного выбора, размещения и модификации элементов управления на панели интерфейса. GUI-редактор создает XML-файл, описывающий проектируемый интерфейс. Полученный файл, в свою очередь, можно передать одному из нескольких генераторов кода, которые непосредственно создают С, С++, Python- или Perl-код для интерфейса. Сгенерированный код затем вызывает создаваемые разработчиком функции, определяющие поведение интерфейса.
XML-формат Glade для описания GUI-интерфейсов является хорошим примером простого узкоспециального мини-языка. В примере 8.1 показан Glade-формат для GUI-интерфейса "Hello, world!".
Адекватная спецификация в Glade-формате предполагает набор действий, предпринимаемых GUI-интерфейсом в ответ на действия пользователя. GUI-интерфейс Glade интерпретирует данные спецификации как структурированные файлы данных. С другой стороны, генераторы кода Glade используют их для написания программ, реализующих GUI. Для некоторых языков (включая Python) существуют библиотеки времени выполнения, которые позволяют пропустить этап генерирования кода и просто создавать GUI непосредственно во время обработки XML-спецификации (интерпретируя Glade-разметку вместо того, чтобы компилировать ее). Таким образом, разработчик получает выбор: эффективное использование пространства ценой скорости запуска или наоборот.
Программисту, освоившему подробности XML-формата, разметка Glade представляется довольно простым языком. Она решает только две задачи: объявляет иерархии GUI-элементов и связывает свойства с элементами управления. Чтобы прочесть спецификацию, представленную в примере, разработчику фактически не требуется досконально разбираться в работе glade. Действительно, имея опыт программирования с помощью GUI-инструментариев и читая данную спецификацию, можно сразу довольно наглядно представить себе интерфейс, создаваемый glade на ее основе. (Для тех, кто не имеет такого опыта, можно отметить, что данная спецификация позволяет получить однокнопочный элемент управления в окне).
Пример 8.1. Glade-спецификация "Hello, world!"<?xml version="1.0"?>
<GTK-Interface>
<widget>
<class>GtkWindow</class>
<name>HelloWindow</name>
<border_width>5</border_width>
<Signal>
<name>destroy</name>
<handler>gtk_main_quit</handler>
</Signal>
<title>Hello</title>
<type>GTK_WINDOW_TOPLEVEL</type>
<position>GTK_WIN_POS_NONE</position>
<allow_shrink>True</allow_shrink>
<allow_grow>True</allow_grow>
<auto_shrink>False</auto_shrink>
<widget>
<class>GtkButton</class>
<name>Hello World</name>
<can_focus>True</can_focus>
<Signal>
<name>clicked</name>
<handler>gtk_widget_destroy</handler>
<object>HelloWindow</object>
</Signal>
<label>Hello World</label>
</widget>
</widget>
</GTK-Interface>
Такая прозрачность и простота являются следствием хорошей конструкции мини- языка. Соответствие между нотацией и объектами предметной области весьма очевидно. Связи между объектами выражаются непосредственно, а не через именованные ссылки или другое непрямое преобразование, которого необходимо придерживаться.
Основой функциональный тест для подобного мини-языка прост: возможно ли разобраться в данном языке, не изучая руководство? Для значительного количества случаев использования Glade это так. Например, зная константы C-уровня, которые в GTK используются для описания параметров позиционирования окна, можно распознать константу
GTK_WIN_POS_NONEкак одну из них и немедленно получить возможность изменить параметры позиционирования, связанные с данным GUI-интерфейсом.
Преимущества использования Glade должны быть очевидны. Данная программа специализируется на создании кода, что освобождает разработчика от необходимости его собственной специализации. То есть Glade принимает на себя одну рутинную задачу, которую в противном случае придется решать вручную. Кроме того, разработчик избавляется от одного из источников ошибок, неизбежных при ручном кодировании.
Более подробная информация, включая исходный код, документацию и ссылки на примеры приложений, доступны на странице проекта Glade <http://glade.gnome.org/>. Программа Glade перенесена на платформу Microsoft Windows.
8.2.4. Учебный пример: m4
Макропроцессор m4(1) интерпретирует декларативный мини-язык для описания трансформаций текста. Программа m4 представляет собой набор макросов, который определяет способы преобразования одних текстовых строк в другие. В результате применения описаний к входному тексту с командами m4 происходит макрорасширение и на выходе создается текст. (Препроцессор С предоставляет аналогичные службы для компиляторов С, хотя и в несколько отличающемся стиле.)
В примере 8.2 показана макрокоманда m4, которая заставляет утилиту m4 преобразовывать каждое вхождение строки "OS" в тесте ввода в строку "operating system" на выводе. Данный пример тривиален. m4 поддерживает макросы с аргументами, которые можно использовать для более сложных операций, чем просто преобразование одной фиксированной строки в другую. Ввод
info m4в командную строку оболочки позволит получить справочную документацию по данному языку. Пример 8.2. Макрокоманда m4
define(`OS', `operating system')
Макроязык m4 поддерживает условные операторы и рекурсию, комбинацию которых можно использовать для реализации циклов, что и было задумано разработчиками. Макроязык m4 преднамеренно создан как язык Тьюринга. Однако было бы глубоким заблуждением пытаться использовать его в качестве универсального языка.
Макропроцессор m4 обычно используется как препроцессор для мини-языков, которые испытывают недостаток встроенного понятия именованных процедур или встроенной функции включения файлов. Это простой путь для расширения синтаксиса базового языка, так чтобы комбинация с m4 поддерживала обе эти функции.
Одним из широко известных способов применения m4 является очистка (или, по крайней мере, эффективное сокрытие) другой конструкции мини-языка, который ранее в данной главе был назван плохим примером. В настоящее время большинство системных администраторов генерируют конфигурационные файлы
sendmail.cfс помощью пакета макрокоманд m4, который поставляется с дистрибутивом sendmail. Макросы начинают с имен функций (или пар имя/значение) и генерируют соответствующие (гораздо более уродливые) строки на языке конфигурации программы sendmail.
Однако m4 следует использовать осмотрительно. Опыт Unix научил разработчиков мини-языков остерегаться макрорасширения. Причины этого описываются далее в настоящей главе.
8.2.5. Учебный пример: XSLT
Язык XSLT, подобно макросам m4, является языком для описания трансформаций текстового потока. Однако он делает гораздо больше, чем просто подмену макрокоманд. Он описывает трансформации XML-данных, включая создание запросов и отчетов. XSLT — язык для написания таблиц стилей XML. В целях практического применения рекомендуется изучить описание обработки XML-документов в главе 18. XSLT описан стандартом Консорциума World Wide Web и имеет несколько реализаций с открытым исходным кодом.
XSLT и макросы m4 являются как исключительно декларативными языками, так и языками Тьюринга, но XSLT поддерживает только рекурсии и не поддерживает циклы. Он весьма сложен, несомненно, наиболее трудный для освоения язык из всех упомянутых в учебных примерах данной главы, а возможно, и самый трудный язык из упомянутых в этой книге[81].
Несмотря на сложность, XSLT действительно является мини-языком. Он обладает важными (хотя и не всеми) характеристиками своего класса:
• ограниченная онтология типов, в частности, без каких-либо аналогов структур записи или массивов;
• ограниченный интерфейс для связи с внешним миром; XSLT-процессоры предназначены для фильтрации стандартного ввода на стандартный вывод, с ограниченными возможностями считывать и записывать файлы; они не способны открывать сокеты или запускать подкоманды.
Программа в примере 8.3, трансформирует XML-документ так, что каждый атрибут каждого элемента трансформируется в новую пару тегов, непосредственно заключенную внутри элемента. Значение атрибута представлено как содержимое пары тегов.
Краткий обзор XSLT приведен здесь отчасти для иллюстрации того факта, что понятие "декларативности" не подразумевает "простоту" или "слабость", и главным образом ввиду того, что необходимость работы с XML-документами рано или поздно приводит к проблеме, каковой является XSLT.
Книга "XSLT: Mastering XML Transformations" [84] является хорошим введением в изучение данного языка. Краткие учебные материалы с примерами доступны в Web[82].
Пример 8.3. XSLT-программа<?xml version="1.0"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output method="xml"/>
<xsl:template match="*">
<xsl:element name="{name()}">
<xsl:for-each select="@*">
<xsl:element name="{name()}">
<xsl:value-of select="."/>
</xsl:element>
</xsl:for-each>
<xsl:apply-templates select="*|text()"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
8.2.6. Учебный пример: инструментарий Documenter's Workbench
Программа troff(1), средство форматирования текстов, была, как отмечалось в главе 2, первоначальным главным приложением операционной системы Unix. Программа troff является наиболее важной в наборе форматирующих средств (получивших коллективное название DWB, (Documenter's Workbench — автоматизированное рабочее место документатора), каждое из которых является отдельным узкоспециальным мини-языком. Большинство из них являются либо препроцессорами, либо постпроцессорами для troff-разметки. В Unix-системах с открытыми исходными кодами используется расширенная реализация DWB (которая называется groff(1)), созданная Фондом свободного программного обеспечения.
Подробнее программа troff рассматривается в главе 18. Здесь достаточно отметить, что она представляет собой хороший пример императивного мини-языка, граничащего с полностью проработанным интерпретатором (в troff поддерживаются условные операции и рекурсия, но нет циклов; troff — отчасти язык Тьюринга).
Постпроцессоры ("драйверы" в терминологии DWB) обычно невидимы для пользователей troff. Первоначально созданные troff-коды для отдельных наборных машин были доступны группе разработки Unix в 1970 году. Позднее они были улучшены до аппаратно-независимого мини-языка для размещения текста и простой графики на страницах. Постпроцессоры преобразовывают данный язык (получивший название "ditroff от device-independent troff — аппаратно-независимый troff) в некоторые данные, которые фактически могут принимать современные графические принтеры — наиболее важным из них (и современным стандартом) является PostScript.
Препроцессоры более интересны, поскольку они фактически расширяют возможности языка troff. Существует 3 распространенных препроцессора: tbl(1) для создания таблиц, eqn(1) для текстового представления математических уравнений и pic(1) для создания диаграмм. Реже используются, но до сих пор сохранились gm(1) для графики, refer(1) и bib(1) для форматирования библиографий. Эквиваленты данных программ с открытыми исходными кодами поставляются с пакетом groff. Препроцессор grap(1) предоставлял довольно гибкое средство для построения графиков; отдельно от groff существует его реализация с открытым исходным кодом.
Некоторые другие препроцессоры не имеют реализации с открытым исходным кодом и в настоящее время широко не используются. Наиболее известным из них была программа ideal(1) для форматирования графики. Более новый член данного семейства, chem(1) отображает формулы химических структур; программа доступна в репозитории netlib Bell Labs[83].
Каждый из описанных препроцессоров представляет собой небольшую программу, которая принимает мини-язык и компилирует его в troff-запросы. Каждый препроцессор распознает разметку, которую необходимо интерпретировать, путем поиска уникального начального и конечного запроса, а любую разметку за пределами таких запросов оставляет неизменной (программа tbl ищет строки
TS/.TE, pic —
.PS/.РЕи т.п.). Таким образом, большинство препроцессоров обычно могут работать в любом порядке, не влияя на другую разметку. Существует несколько исключений: в частности, программы chem и grap используют команды программы pic, и поэтому в конвейерах она должна следовать после них.
cat thesis.ms | chem | tbl | refer | grap | pic | eqn \
| groff -Tps >thesis.ps
Выше приведен подробный пример конвейера DWB-обработки для гипотетических тезисов, включающих в себя химические формулы, математические уравнения, таблицы, библиографию, графики и диаграммы. (Команда cat(1) просто копирует свой ввод или содержимое указанного файла на свой вывод; здесь она используется для подчеркивания порядка операций.) На практике современные реализации troff часто поддерживают параметры командной строки, которые способны вызвать, по крайней мере, такие программы, как tbl(1), eqn(1) и pic(1), а поэтому писать такие сложные конвейеры не обязательно. Но даже если бы это понадобилось, такие инструкции для сборки обычно создаются один раз и сохраняются в make-файле или в shell-сценарии для повторного использования.
Разметка документов средствами Documenter's Workbench несколько устарела, однако диапазон проблем, которые решаются препроцессорами, является некоторым показателем мощности модели мини-языков — было бы чрезвычайно трудно встроить эквивалентные знания в текстовые процессоры класса WYSIWYG. Существует несколько областей, где современные инструментальные связки и способы разметки документов на основе XML, в 2003 году лишь приближаются к возможностям, которыми инструментарий DWB обладал в 1979 году. Эти вопросы подробнее освещаются в главе 18.
Конструктивные идеи, которые дали инструментарию DWB такую мощь, в настоящее время должны быть очевидны. Все инструменты совместно используют общее представление документов в виде текстовых потоков, а система форматирования разбита на независимые компоненты, которые можно отлаживать и совершенствовать по отдельности. Структура конвейеров поддерживает интеграцию с новыми, экспериментальными препроцессорами и постпроцессорами без нарушения работы старых. DWB — модульная и расширяемая конструкция.
Структура инструментария Documenter's Workbench в целом преподносит некоторые уроки того, как связывать несколько специальных языков во взаимодействующую систему. Один препроцессор может быть надстройкой доя другого. Действительно, инструментальные средства DWB были ранними примерами, демонстрирующими мощность каналов, фильтров и мини-языков, которые в дальнейшем во многом повлияли на конструкцию Unix. Конструкции отдельных препроцессоров способны предоставить еще больше примеров того, как выглядит конструкция эффективного мини-языка.
Один из этих уроков отрицательный. Иногда пользователи, пишущие описание в мини-языке, допускают некорректные действия с низкоуровневой troff-разметкой, вставленной вручную. Это может повлечь за собой последствия и ошибки, которые трудно диагностировать, поскольку данные, сгенерированные troff и выходящие из конвейера, не видны, а если бы были видны, то были бы нечитаемыми. Такие ошибки аналогичны ошибкам, которые возникают в коде, когда C-код смешан с фрагментами ассемблера. Было бы лучше, если бы уровни языков были разделены более основательно, если бы это было возможно. Разработчикам мини-языков следует учесть эти проблемы.
Все языки препроцессоров (кроме самой troff-разметки) имеют сравнительно четкий, shell-подобный синтаксис, которые соответствует многим описанным в главе 5 соглашениям о конструкции форматов файлов данных. Существует несколько затруднительных исключений. Особенно выделяется среди них программа tbl(1), по умолчанию использующая символ табуляции как разделитель полей между столбцами таблицы, дублирующая неприятные недоработки в конструкции make(1) и вызывающая досадные ошибки, когда редакторы или другие средства невидимо изменяют состав разделителей.
Хотя troff сам по себе представляет собой специализированный императивный мини-язык, одной из идей, которая "проходит" как минимум через 3 мини-языка в DWB, является декларативная семантика: компоновка документа на основе ограничивающих условий. Данная идея также характерна для современных GUI-инструментариев. Вместо того чтобы указывать координаты пикселей для графических объектов, единственное, что действительно требуется сделать — это объявить пространственные взаимозависимости между ними ("элемент управления А расположен выше элемента В, который находится слева от элемента С"), а затем заставить программное обеспечение вычислить наилучшее расположение элементов А, В и С, соответствующее заданным ограничивающим условиям.
В программе pic(1) данный подход используется для компоновки элементов диаграмм. Диаграмма классификации языков на рис. 8.1 была создана на основе приведенного в примере 8.4[84] исходного pic-кода, обработанного с помощью команды
pic2graph, которая рассматривалась в одном из учебных примеров главы 7.
Это весьма типичная для Unix конструкция мини-языка, и как таковая она имеет несколько интересных моментов даже на уровне синтаксиса. Следует отметить ее сходство с shell-программой: комментарии начинаются с символа #, а синтаксис, очевидно, организован на основе лексем и имеет простейшее возможное соглашение для строк. Разработчик pic(1) знал, что Unix-программисты ожидают подобный этому синтаксис мини-языков, если не существует значительной и специфической причины не делать этого. В данном случае в полной мере выполняется правило наименьшей неожиданности.
Пример 8.4. pic-код для схемы классификации языков#Minilanguage taxonomy (классификация мини-языков)
#
# Base ellipses (основные эллипсы)
define smallellipse {ellipse width 3.0 height 1.5}
M: ellipse width 3.0 height 1.8 fill 0.2
line from M.n to M.s dashed
D: smallellipse() with .e at M.w + (0.8, 0)
line from D.n to D.s dashed
I: smallellipse() with .w at M.e - (0.8, 0)
#
# Captions (подписи)
"" "Data formats" at D.s
"" "Minilanguages" at M.s
"" "interpreters" at I.s
#
# Heads (заголовки)
arrow from D.w + (0.4, 0.8) to D.e + (-0.4, 0.8)
"flat to structured" "" at last arrow.с
arrow from M.w + (0.4, 1.0) to M.e + (-0.4, 1.0)
"declarative to imperative" "" at last arrow.с
arrow from I.w + (0.4, 0.8) to I.e + (-0.4, 0.8)
"less to more general" "" at last arrow.с
#
# The arrow of loopiness (стрелка развития циклов)
arrow from D.w + (0, 1.2) to I.e + (0, 1.2)
"increasing loopiness" "" at last arrow.с
#
# Flat data files (плоские файлы данных)
"/etc/passwd" ".newsrc" at 0.5 between D.c and D.w
# Structured data files (структурированные файлы данных)
"SNG" at 0.5 between D.c and M.w
# Datafile/minilanguage borderline cases (пограничные случаи файлы данных/мини-язык)
"regexps" "Glade" at 0.5 between M.w and D.e
# Declarative minilanguages (декларативные мини-языки)
"m4" "Yacc" "Lex" "make" "XSLT" "pic" "tbl" "eqn" \
at 0.5 between M.с and D.e
# Imperative minilanguages (императивные мини-языки)
"fetchmail" "awk" "troff" "Postscript" at 0.5 between M.c and I.w
# Minilanguage/interpreter borderline cases (пограничные случаи
мини-язык/интерпретатор)
"dc" "bc" at 0.5 between I.w and M.e
# Interpreters (интерпретаторы)
"Emacs Lisp" "JavaScript" at 0.25 between M.e and I.e
"sh" "tcl" at 0.55 between M.e and I.e
"Perl" "Python" "Java" at 0.8 between M.e and I.e
Вероятно, больших усилий не потребуется, чтобы понять, что первая строка кода представляет собой определение макрокоманды. В последующих ссылках на
smallellipse()инкапсулирован повторяющийся элемент диаграммы. Назначение команды arrow также очевидно.
Используя все это как подсказку и глядя на реальную диаграмму, несложно выяснить значение остальных элементов синтаксиса (позиционных ориентиров, таких как
М.s, и конструкций, подобных
last arrowили
at 0.25 between M.e and I.e, или добавление смещения вектора). Как и Glade-разметка, а также m4-код, пример, подобный данному, может прояснить многое в языке без каких-либо ссылок на руководства (к сожалению, свойство компактности для troff(1)-разметки не характерно).
Пример программы pic(1) отражает общую для мини-языков идею конструкции, которая также отражается в Glade — использование интерпретатора мини-языка для инкапсуляции некоторой формы логических расчетов на основе ограничивающих условий и превращения ее в действия. Программу pic(1), в сущности, можно было бы рассматривать скорее как императивный, а не декларативный язык; в ней имеются элементы обоих видов, и дискуссия быстро переросла бы теологическую.
Комбинация макросов с компоновкой на основе ограничивающих условий позволяет программе pic(1) выражать структуру диаграмм таким способом, который недоступен для более современных векторных разметок, таких как SVG. Следовательно, благоприятно, то, что одним из следствий конструкции Documenter's Workbench является то, что она относительно упрощает использование программы pic(1) за пределами среды DWB. Сценарий
pic2graph, использованный в качестве учебного примера в главе 7, был специально создан для достижения этой цели с помощью модернизированных PostScript-возможностей groff(1) как промежуточный этап на пути к современному растровому формату.
Более четким решением является утилита pic2plot(1), распространяемая с пакетом GNU plotutils, в которой использована внутренняя модульность кода GNU pic(1). Код был разделен на клиентскую часть, выполняющую синтаксический анализ, и серверную часть, генерирующую troff-разметку. Обе части взаимодействовали посредством уровня чертежных примитивов. Поскольку данная конструкция подчинялась правилу модульности, программисты pic2plot(1) имели возможность отделить этап синтаксического анализа GNU pic и реконструировать чертежные примитивы с помощью современной библиотеки для построения графиков. Однако их решение имеет один недостаток. Текст на выходе генерируется со встроенными в pic2plot шрифтами, которые не соответствуют шрифтам troff.
8.2.7. Учебный пример: синтаксис конфигурационного файла fetchmail
Рассмотрим пример 8.5.
Конфигурационный файл может рассматриваться как императивный мини-язык. Существует предполагаемый поток выполнения: повторяющаяся, циклическая обработка списка команд опроса ("засыпающая" на время в конце каждого цикла) и последовательный сбор почты с каждого из указанных узлов для каждого пользователя, связанного с определенными узлами. Данный язык далек от универсальных языков. Все, что он способен делать, — создавать последовательность команд опроса серверов.
Как и в случае с программой pic(1), данный мини-язык можно рассматривать как объявления либо как слабый императивный язык и бесконечно спорить об отличиях. С одной стороны, в нем нет ни условных операторов, ни рекурсии, ни циклов. Фактически он вообще не имеет явных управляющих структур. С другой стороны, он описывает скорее действия, чем зависимости, что отличает его от исключительно декларативного синтаксиса, подобного GUI-описаниям Glade.
Пример 8.5. Синтетический кодfetchmailrc
#Опрашивать данный узел первым в цикле.
poll pop.provider.net proto pop3
user "jsmith" with pass "secret1" is "smith" here
user jones with pass "secret2" is "jjones" here with options keep
# Опрашивать данный узел вторым
poll billywig.hogwarts.com with proto imap:
user harry_potter with pass "floo" is harry_potter here
# Опрашивать данный узел третьим в цикле.
# Пароль будет взят из файла ~/.netrc
poll mailhost.net with proto imap:
user esr is esr here
Конфигурационные мини-языки для сложных программ часто переходят эту границу. Данный факт подчеркивается здесь потому, что отсутствие явных управляющих структур в императивном мини-языке может быть колоссальным упрощением, если это позволяет предметная область.
Примечательной особенностью синтаксиса
.fetchmailrcявляется использование необязательных ключевых слов, которые поддерживаются просто для того, чтобы язык спецификаций более походил на английский язык. Ключевые слова "with" и однократное употребление слова "options" в примере фактически не являются обязательными, но позволяют упростить описания для чтения.
Традиционно подобный синтаксис называется синтаксическим сахаром (syntactic sugar). Данному термину сопутствует известное высказывание о том, что "синтаксический сахар вызывает рак двоеточий"[85]. Действительно, чтобы синтаксический сахар не создавал трудностей больше, чем может решить проблем, его необходимо использовать умеренно.
В главе 9 показано, как создание программ, управляемых данными, способствует изящному решению проблемы редактирования конфигурационных файлов fetchmail с помощью графического интерфейса.
8.2.8. Учебный пример: awk
Мини-язык awk является инструментальным средством Unix старой школы, прежде широко используемым в shell-сценариях. Как и m4, утилита awk предназначена для написания небольших, но выразительных программ для преобразования текстового ввода в текстовый вывод. Версии утилиты поставляются со всеми Unix-системами. Некоторые из них реализованы с открытым исходным кодом. Команда
info gawkв командной строке Unix весьма вероятно позволит получить справочную документацию по программе.
Программы, написанные на awk, состоят из пар шаблон/действие. Каждый шаблон представляет собой регулярное выражение; эта концепция подробно описывается в главе 9. После запуска awk-программа последовательно анализирует все строки во входном файле. Каждая строка по порядку сравнивается с парой шаблон/действие. Если шаблон соответствует строке, то осуществляется связанное с шаблоном действие.
Каждое действие кодируется на языке, подобном подмножеству языка С, с переменными, условными операторами, циклами и онтологией типов, включая целые числа, строки и (в отличие от С) словари[86].
Язык действий awk является языком Тьюринга и позволяет считывать и записывать файлы. В некоторых версиях он также позволяет открывать и использовать сетевые сокеты. Однако awk главным образом используется как генератор отчетов, особенно для интерпретации и предварительной обработки табличных данных. Он редко используется автономно, но часто встраивается в сценарии. В главе 9, в учебном примере по созданию HTML-документа имеется пример awk-программы.
Учебный пример awk приведен в этой книге, чтобы подчеркнуть, что данный язык не является моделью для подражания. Фактически с 1990 года awk почти совершенно вышел из употребления. На смену ему пришли языки сценариев новой школы, особенно Perl, который явно предназначался для того, чтобы полностью вытеснить awk. Причины достойны внимания, поскольку они поучительны для разработчиков мини-языков.
Язык awk первоначально разрабатывался как небольшой, выразительный язык специального назначения для создания отчетов. К сожалению, его соотношение сложность-мощность оказалось неудачным. Язык действий некомпактен, а шаблонно-управляемая структура, внутри которой он содержится, не позволяет применять его широко. Данный язык унаследовал худшие черты обоих миров. Кроме того, языки сценариев новой школы могут решать все задачи, решаемые awk. Эквивалентные программы, написанные на этих языках, обычно также, если не лучше, читабельны.
Язык awk вышел из употребления также вследствие того, что более современные оболочки обладают средствами вычислений с плавающей точкой, ассоциативными массивами, поддержкой регулярных выражений и средствами обработки подстрок, поэтому эквивалентные небольшим awk-сценариям программы могут быть реализованы без издержек создания процесса.
(Дэвид Корн.)
В течение нескольких лет после выхода языка Perl в 1987 году, awk оставался конкурентоспособным просто потому, что имел меньшую и более быструю реализацию. Однако по мере того как стоимость вычислительных циклов и памяти падала, экономические причины для привлекательности языка специального назначения, который сравнительно экономно использовал оба ресурса, теряли свою силу. Программисты для реализации awk-подобных функций все более отдавали предпочтение Perl или (позднее) языку Python, вместо того, чтобы удерживать в памяти два различных языка сценария[87]. К 2000 году awk стал для большинства Unix-хакеров старой школы немногим больше, чем воспоминание, но не самое дорогое.
Снижение цен изменило компромиссы проектирования мини-языков. Ограничение возможностей конструкции ради компактности, возможно, до сих пор является хорошей идеей, но такое же ограничения в целях экономии аппаратных ресурсов — идея неудачная. Со временем аппаратные ресурсы становятся дешевле, а пространство в памяти программистов дороже. Современные мини-языки могут быть универсальными и некомпактными, или специализированными и очень компактными, но специализированные и некомпактные просто не выдержат конкуренции.
8.2.9. Учебный пример: PostScript
PostScript — мини-язык, специализацией которого является описание форматированного текста и графики для графических устройств. Данный язык был импортирован в Unix. Он основывался на разработке легендарного центра "Xerox Palo Alto Research Center", созданной во время появления первых лазерных принтеров. В течение нескольких лет после выхода первой коммерческой версии в 1984 году, PostScript оставался доступным только как частный продукт Adobe, Inc. и главным образом ассоциировался с компьютерами Apple. PostScript был клонирован на условиях лицензионного соглашения, очень близкого к лицензиям на открытые исходные коды, и с тех пор стал стандартом де-факто для управления принтерами в операционной системе Unix. Версия с полностью открытым исходным кодом поставляется с большинством современных Unix-систем[88]. Также доступно подробное техническое введение в PostScript[89].
PostScript обладает некоторым функциональным сходством с разметкой troff. Оба языка предназначены для управления принтерами и другими графическими устройствами, и оба обычно генерируются программами или пакетами макрокоманд, а не вручную. Однако тогда как запросы troff являются быстро созданным набором кодов для управления форматом, PostScript был спроектирован снизу вверх как язык и является гораздо более выразительным и мощным. Главное из того, что делает PostScript, — это алгоритмические описания изображений, имеющие гораздо меньшие размеры, чем представленные ими растровые изображения, и поэтому требующие меньше пространства для хранения и меньшей полосы пропускания при передаче.
PostScript является явным языком Тьюринга, поддерживающим условные операции, циклы, рекурсию и именованные процедуры. Онтология типов включает в себя целые и действительные числа, строки и массивы (каждый элемент массива может иметь любой тип), но не имеет эквивалента структур. Технически PostScript является языком, работающим со стеками. Аргументы примитивных процедур (операторов) PostScript обычно извлекаются из магазинного стека аргументов, а результат (или результаты) возвращаются обратно в стек.
Существует около 40 базовых операторов (при том, что общее их приблизительное количество — 400). Большую часть работы выполняет оператор
show, который отображает строку на странице. Другие операторы устанавливают текущий шрифт, изменяют цвет, рисуют линии, дуги или кривые Безье, окрашивают закрытые области, устанавливают области отсечения, а также выполняют другие операции. Подразумевается, что интерпретатор PostScript транслирует данные команды в растровые изображения для передачи на экран или печатный носитель.
Остальные PostScript-операторы реализуют арифметические операции, управляющие структуры и процедуры. Они позволяют выражать повторяющиеся или стереотипные изображения (такие как текст, составленный из повторяющихся графических форм знаков) в виде программ, объединяющих изображения. Часть эффективности PostScript связана с тем фактом, что PostScript-программы для печати текста или простой векторной графики являются гораздо менее громоздкими, чем растровые изображения, в которые преобразовывается текст или векторы. Кроме того, PostScript-программы независимы от разрешающей способности устройств и быстрее передаются по сетевому кабелю или последовательной линии.
Исторически PostScript-интерпретация на основе стеков имеет сходство с языком FORTH, который первоначально предназначался для управления приводами телескопов в реальном времени и имел кратковременную популярность в 80-х годах прошлого века. Языки обработки стеков отличаются превосходной поддержкой чрезвычайно плотного, экономичного кода и печально известны тем, что их трудно читать. Для PostScript характерны обе эти особенности.
PostScript часто реализуется в виде встроенного в принтер программного обеспечения. Ghostscript, реализация PostScript с открытым исходным кодом транслирует PostScript в различные графические форматы и (более слабые) языки управления принтерами. Большая часть остального программного обеспечения обрабатывает PostScript как окончательный формат вывода, который предназначен для передачи PostScript-совместимому графическому устройству, а не для редактирования или просмотра.
PostScript (в оригинальном или упрощенном варианте EPSF с объявленным вокруг него обрамлением, позволяющим встраивать его в другие графические форматы) является очень хорошо спроектированным примером специализированного языка управления и, как модель, заслуживает внимательного изучения. Он является компонентом других стандартов, например, PDF (Portable Document Format — формат для переносимых документов).
8.2.10. Учебный пример: утилиты bc и dc
Впервые утилиты bc(1) и dc(1) рассматривались в главе 7 как учебный пример вызова с созданием подоболочки. Они также являются примерами узкоспециальных мини-языков императивного типа.
dc — старейший язык в Unix. Он был создан на компьютере PDP-7 и перенесен на PDP-11 еще до того, как была перенесена (сама) Unix
(Кен Томпсон.)
Предметной областью данных языков являются арифметические вычисления неограниченной точности. Другие программы могут использовать их для выполнения таких вычислений, "не заботясь" о необходимых для этого специальных методиках.
Фактически первоначальная мотивация для создания dc не была связана с разработкой универсального интерактивного калькулятора, для которого было бы достаточно простой программы, поддерживающей вычисления с плавающей точкой. Мотивирующим фактором была давняя заинтересованность Bell Labs в численном анализе: точному вычислению констант для численных алгоритмов весьма способствует возможность работать с более высокой точностью, чем та, которую использует сам алгоритм. Отсюда и арифметика с неограниченной точностью в dc.
(Генри Спенсер.)
Как и в случае SNG- и Glade-разметки одним из преимуществ обоих языков является их простота. Однажды узнав о том, что dc(1) — калькулятор с обратной польской записью, а bc(1) — калькулятор с алгебраической записью, пользователь найдет новыми очень немногие сведения об интерактивном использовании любого
из двух языков. Важность правила наименьшей неожиданности в интерфейсах повторно рассматривается в главе 11.
В обоих мини-языках имеются условные операции и циклы; они являются языками Тьюринга, но имеют очень ограниченную онтологию типов, включающую только целые числа неограниченной точности и строки, что ставит их между интерпретируемыми мини-языками и полными языками сценариев. Функции программирования реализованы так, чтобы не нарушать обычное использование программы в качестве калькулятора; в действительности, большинство пользователей dc/bc, вероятно, не подозревают о существовании этих функций.
Обычно программы dc/bc используются в диалоговом режиме, но их способность поддерживать библиотеки пользовательских процедур предоставляет им дополнительный вид служебных функций — программируемость. Фактически данное свойство является наиболее важным преимуществом императивных мини-языков, которое, как отмечалось в учебном примере по инструментарию Documenter's Workbench, должно быть очень мощным независимо от того, является ли обычный режим работы программы диалоговым. Данные языки можно использовать для написания высокоуровневых программ, которые включают в себя специализированную логику.
Поскольку интерфейс программ dc/bc прост (передается строка, содержащая выражение, в ответ на которую возвращается строка, содержащая значение), другие программы и сценарии могут легко получит доступ ко всем этим возможностям, вызывая dc/bc как подчиненные процессы. Ниже приводится один известный пример (см. пример 8.6), реализация шифра с открытым ключом Ривеста-Шамира-Адельмана (Rivest-Shamir-Adelman) на Perl, которая широко публиковалась в подписях почтовых сообщений и на футболках как протест против введенного в США в 1995 году ограничения на экспорт криптографических средств. Данный сценарий для выполнения необходимых арифметических расчетов с неограниченной точностью вызывает dc с созданием подоболочки.
Пример 8.6. RSA-реализация с помощью утилиты dcprint pack"C*",split/\D+/,`echo "16iII*o\U@{$/=$z;[(pop,pop,unpack "H*", <>)]}\EsMsKsN0[1N*11K[d2%Sa2/d0<X+d*1MLa^*1N%0]dsXx++\ 1M1N/dsM0<J]dsJxp"|dc`
8.2.11. Учебный пример: Emacs Lisp
Вместо того чтобы просто запускать интерпретируемый язык специального назначения в качестве подчиненного процесса для решения специфических задач, его можно использовать как основу для всей структуры. Преимущества и недостатки данного подхода рассматриваются в главе 13. Запросы troff были его ранним примером. Одним из самых известных и наиболее мощных современных примеров является редактор Emacs. Он создан на основе диалекта языка Lisp с примитивами как для описания действий в буферах редактирования, так и управления подчиненными процессами.
Тот факт, что Emacs построен вокруг мощного языка для описания редактирующих действий или клиентской части для других программ, означает, что он, кроме обычного редактирования, может применяться для многих других целей. Применение развитой, специализированной логики Emacs для повседневной разработки программ (компиляции, отладки, контроля версий) рассматривается в главе 15. "Режимы" Emacs представляют собой пользовательские библиотеки, т.е. программы, написанные на Emacs Lisp, которые приспосабливают редактор для решения специфической задачи, обычно (но не обязательно) связанной с редактированием.
Таким образом, существуют специализированные режимы, которые распознают синтаксис большого числа языков программирования и разметки, таких как SGML, XML и HTML. Однако многие пользователи также используют Emacs-режимы для отправки и получения электронной почты (в таких режимах в качестве подчиненных процессов используются почтовые утилиты Unix) или новостей Usenet. Emacs может служить в качестве Web-браузера или клиентской части для различных программ интерактивного общения. Существует также пакет для составления расписаний, собственная программа-калькулятор для Emacs и даже весьма широкий выбор игр, написанных как режимы Emacs Lisp.
8.2.12 Учебный пример: JavaScript
JavaScript — язык с открытым исходным кодом, спроектированный для внедрения в C-программы. Несмотря на то, что он также встраивается в Web-серверы, первоначальным и наиболее известным его проявлением является клиентский JavaScript, который позволяет встраивать исполняемый код в Web-страницы, просматриваемые любым поддерживающим его браузером. Здесь рассматривается именно эта версия языка.
JavaScript — интерпретируемый язык, полностью попадающий под определения языка Тьюринга, с целыми, действительными числами, булевыми операторами, строками и легковесными, основанными на словарях, объектами, которые имеют сходство с объектами языка Python. Значения типизированы, но переменные могут иметь любой тип. Преобразование типов осуществляется автоматически во многих средах. Синтаксически JavaScript подобен языку Java с некоторым влиянием со стороны Perl и содержит функции для работы с Perl-подобными регулярными выражениями.
Несмотря на все указанные особенности, клиентская версия JavaScript не является полностью универсальным языком. Его возможности жестко ограничены в целях предотвращения атак на браузеры через Web-страницы, содержащие JavaScript-код. Язык принимает входные данные от пользователя и генерирует или модифицирует Web-страницы, но непосредственно не может изменять содержимое дисковых файлов и открывать собственные сетевые соединения.
С течением времени данный язык стал более универсальным и менее связанным со своей клиентской средой. Это закономерное развитие любого удачного специализированного языка. Клиентский вариант JavaScript в настоящее время взаимодействует со своим окружением путем чтения и записи значений в один специальный объект, который называется документной объектной моделью браузера (Document Object Model, DOM). Данный язык до сих пор имеет некоторые устаревшие API-интерфейсы для связи с браузером, которые не работают через DOM, однако они нежелательны, отсутствуют в стандарте для JavaScript ЕСМА-262 и могут не поддерживаться в будущих версиях.
Стандартным справочником по JavaScript является книга "JavaScript: The Definitive Guide" [20]. Исходный код доступен в Web[90]. Язык JavaScript представляет собой интересный пример для изучения по двум причинам. Во-первых, он максимально близок к универсальному языку, фактически не являясь таковым. Во-вторых, связь между клиентским JavaScript и средой браузера через единственный DOM-объект хорошо спроектирована и может послужить моделью для других ситуаций встраивания.
8.3. Проектирование мини-языков
В каких ситуациях целесообразна разработка мини-языка? Выше отмечалось, что мини-языки предоставляют способ перемещения спецификаций проблем на более высокий уровень, а в нескольких учебных примерах это наблюдение подтверждалось фактами. Оборотная сторона данного явления — использование мини-языка, вероятно, будет хорошим подходом всякий раз, когда примитивы предметной области просты и стереотипны, а способы их вероятного применения пользователями изменчивы.
Некоторые родственные идеи можно найти в описании моделей проектирования "Alternate Hard And Soft Layers" <http://www.c2.com/cgi/wiki?Alternate-HardAndSoftLayers> и "Scripted Components" <http://www.doc.ic.ac.uk/~np2/patterns/scripting/scripting.html>.
Интересное обозрение стилей и методик разработки с помощью мини-языков приведено в статье "Notable Design Patterns for Domain-Specific Languages" [77].
8.3.1. Определение соответствующего уровня сложности
Первым важным моментом, о котором необходимо помнить при разработке мини-языка, является, как обычно, сохранение по возможности простой конструкции. Диаграмма классификации, которая использовалась для организации учебных примеров, выражает иерархию сложности. Необходимо удерживать конструкцию как можно ближе к левой границе схемы. Если с проблемой можно справиться путем разработки структурированного файла данных вместо использования мини-языка, который стремится модифицировать внешние данные, в случае если он является интерпретируемым, то следует любыми средствами реализовать эту возможность.
Одной чрезвычайно прагматичной причиной, по которой следует продолжать усердно работать со структурированными данными, а не с мини-языком, является то, что в сетевом мире средства встроенного мини-языка являются предметом неправильного использования, которое может причинять беспокойство или даже быть опасным. JavaScript — главный экземпляр в категории "причиняющих беспокойство". Разработчики данного языка не предвидели того, что он будет использоваться для всплывающей рекламы настолько навязчиво, что создаст потребность в функциях браузера, подавляющих интерпретацию JavaScript.
Макровирусы Microsoft Word показывают, как мини-язык может стать действительно опасной брешью в безопасности системы, простои и потери производительности от которой ежегодно обходятся в миллиарды долларов. Полезно отметить, что несмотря на существование в мире как минимум 20 млн. пользователей[91] Unix, в Unix-среде никогда не было вспышек макровирусов, характерных для Windows. Существует множество причин этому, включая принципиально лучшую с точки зрения безопасности конструкцию Unix; но по крайней мере одной причиной является тот факт, что почтовые агенты в Unix по умолчанию не обрабатывают исполняемое содержимое в документах, просматриваемых пользователем[92].
Если существует какая-либо возможность того, что пользователи приложения могут запускать программы из неблагонадежных источников, рискованные функции мини-языка приложения могут в конце концов привести к необходимости его подавления. Языки, подобные Java и JavaScript, явно изолируются в "песочнице", т.е. они имеют ограниченный доступ к своему окружению. Это сделано не только для того, чтобы упростить их конструкцию, но и для того, чтобы воспрепятствовать потенциально деструктивным операциям со стороны ошибочного или злонамеренного кода.
С другой стороны, большое количество неудачных конструкций были неумело созданы разработчиками, которые оказались не способны принять тот факт, что они нуждаются скорее в мини-языке, чем в формате файлов данных. Слишком много случаев, когда языковые функции были вставлены с опозданием. Двумя наиболее общими симптомами данной проблемы являются слабые, узкоспециализированные управляющие структуры и неразвитые средства для объявления процедур или полное отсутствие таких средств.
Рискованно разрабатывать мини-языки, которые только отчасти являются языками Тьюринга. Если разработчик решается на это, то высока вероятность того, что когда-нибудь в будущем какой-нибудь сообразительный программист придет к необходимости заставить данный язык выполнять циклы и условные операции. Поскольку это можно будет сделать только "туманным путем", он создаст неясный код, который в краткосрочной перспективе, возможно, будет легко обслуживаемым, но, вероятно, будет кошмаром для тех, кто впоследствии будет с ним работать.
Эстетичность и мощь мини-языков заслуживают высокой оценки, но вместе с тем в них скрывается немало ловушек. Существуют конструкции, в которых целесообразно использовать восходящее связывание множества низкоуровневых служб и заботиться об их организации после изучения предметной области. Одним из достоинств мини-языков является то, что они могут способствовать созданию хорошей конструкции без восходящего программирования, позволяя разработчику передвинуть некоторые нисходящие решения в управляющую логику программ, написанных на данном мини-языке. Однако если применить восходящий подход к конструированию самого мини-языка, то в результате, вероятно, получится уродливый синтаксис, отражающий слабость языка и плохо продуманную реализацию.
Существует множество моментов в конструировании мини-языков, где мелкие альтернативные решения создают значительные различия в эксплуатационных качествах и легкости использования инструмента.
Для разработчика языка хорошим принципом является рассмотрение альтернативы сообщениям об ошибке. Если в намерениях программиста существует действительная неоднозначность, то сообщение об ошибке целесообразно, однако во многих случаях намерения очевидны, и будет великим благом заставить язык просто выполнять правильные действия. Хорошим примером является С, принимающий дополнительную запятую в конце списка инициализатора массива, что значительно упрощает как редактирование, так и машинную генерацию инициализаторов массива. Контрпримером является придирчивость различных HTML-анализаторов, особенно их обыкновение бесшумно отбрасывать части документа из-за тривиальной ошибки верстки.
(Стив Джонсон.)
В данном вопросе, как и в других, хороший вкус и инженерное мышление невозможно заменить ничем. Разрабатывая мини-язык, не следует делать это наполовину. Декларативные мини-языки должны иметь очевидный, последовательный языковой синтаксис, облегчающий их чтение. В императивных языках необходимо добавить полный диапазон управляющих структур, который адаптирован из языковых моделей, с которыми, пользователи разрабатываемого мини-языка, вероятно, знакомы. О языке необходимо думать как о языке, спрашивая себя: "будет ли удобно программировать на нем?" и даже "приятно ли будет смотреть на данную конструкцию?". Здесь, как и в других областях разработки программного обеспечения, применим принцип Дэвида Гелентера: красота — основная защита против сложности.
8.3.2. Расширение и встраивание языков
Один из фундаментально важных вопросов заключается в том, возможно ли реализовать мини-язык путем расширения или встраивания существующего языка сценариев. Нередко такой подход является правильным путем к императивному мини-языку, но гораздо менее верным к декларативному.
Иногда можно написать императивный язык путем простого кодирования служебных функций в интерпретируемый язык, который далее в целях освещения данной темы называется "базовым" (host) языком. Программы, написанные на таком мини-языке, являются просто сценариями, которые загружают служебную библиотеку и используют управляющие структуры и другие средства базового языка как каркас. Каждое средство, имеющееся в базовом языке, избавляет от необходимости писать собственное аналогичное средство.
Данный способ является простейшим для написания мини-языка. Lisp-программисты старой школы (включая самого автора) предпочитают данный прием и интенсивно его используют. Он лежит в основе конструкции редактора Emacs и открывается заново в языках сценариев новой школы, таких как Tcl, Python и Perl. Однако такой подход имеет свои недостатки.
Базовый язык может оказаться неспособным предоставить интерфейс к необходимой библиотеке кода. Или его онтология типов данных может оказаться неадекватной для необходимого вида вычислений. Или измерения покажут слишком низкий уровень производительности прототипа. В таких ситуациях обычным решением является программирование на С (или С++) и интеграция результатов в создаваемый мини-язык.
Вариант расширения языка сценариев с помощью C-кода или внедрения языка сценариев в C-программу зависит от существования предназначенного для этих целей языка сценариев. Расширить язык сценариев можно, заставив его динамически загружать C-библиотеку или модуль так, чтобы точки входа С стали видимыми, как функции в расширенном языке. Для того чтобы встроить язык сценария в C-программу, необходимо отправлять команды экземпляру интерпретатора и получать результаты, как значения в С.
Обе методики также зависят от способности перемещать данные между онтологией типов С и онтологией типов используемого языка сценариев. Некоторые языки сценариев, в целях поддержки такой возможности разработаны снизу вверх. Одним из них является Tcl, который рассматривается в главе 14, другим — Guile, диалект с открытым исходным кодом Lisp-варианта Scheme. Guile поставляется в виде библиотеки и специально предназначен для внедрения в C-программы.
Вполне возможно (хотя до сих пор довольно трудно) расширять или встраивать язык Perl. Очень просто расширять Python и немного сложнее внедрять его; C-расширения в мире Python используются особенно интенсивно. Язык Java имеет интерфейс для вызова "собственных методов" в С, хотя практические результаты этого бесперспективны, поскольку нарушается переносимость. Большинство версий командного интерпретатора Unix (shell) не предназначены для внедрения или расширения, однако оболочка Korn (ksh93 и боле поздние версии) является заметным исключением.
Существует множество причин не надстраивать создаваемый императивный мини-язык над существующим языком сценариев. Одна из весомых причин заключается в необходимости реализовать собственный, специальный грамматический аппарат для проверки ошибок. В таком случае следует рассмотреть приведенные ниже рекомендации по применению утилит yacc и lex.
8.3.3. Написание специальной грамматики
Для декларативных мини-языков основной вопрос состоит в том, следует ли использовать XML в качестве основного синтаксиса и определять грамматику как тип XML-документа. Вполне возможно, что такой подход верен для сложно структурированных декларативных мини-языков, однако здесь также актуальны предостережения, изложенные в главе 5, о конструкции форматов файлов данных — XML может быть излишним. Если XML не используется, следует соблюдать правило наименьшей неожиданности, поддерживая описанные Unix-соглашения для файлов данных (простой синтаксис на основе лексем, поддержка C-соглашений об использовании обратной косой черты и т.д.).
Если специальная грамматика действительно требуется, то утилиты yacc и lex (или их локальный эквивалент в используемом языке), вероятно, будут наилучшими помощниками, кроме тех случаев, когда грамматика используемого языка настолько проста, что ручное кодирование рекурсивного нисходящего синтаксического анализатора представляет собой тривиальную задачу. Даже тогда утилита yacc может предоставить более надежное устранение ошибок, а модифицировать yacc-спецификацию по мере развития синтаксиса языка будет проще. В главе 9 рассматриваются производные от yacc и lex инструменты, доступные в языках различной реализации.
Даже в случае принятия решения о реализации собственного синтаксиса рекомендуется рассмотреть возможную выгоду от повторного использования имеющихся инструментальных средств. Если требуются макросредства, следует учесть, что предобработка средствами m4(1) может быть правильным решением. Однако, прежде всего, необходимо учесть предостережения, приведенные в следующем разделе.
8.3.4. Проблемы макросов
Средства макрорасширения были излюбленной тактикой разработчиков языков в ранней Unix. Язык С, несомненно, имеет такое средство. Кроме того, они обнаруживаются в некоторых более сложных мини-языках специального назначения, таких как pic(1). Препроцессор m4 предоставляет общее средство для реализации макрорасширяющих препроцессоров.
Макрорасширение просто определить и реализовать, а также осуществить с его помощью множество изящных и нетривиальных технических приемов. На ранних разработчиков, по-видимому, оказывал влияние опыт ассемблера, в котором макросредства часто были единственным механизмом, доступным для структурирующих программ.
Преимуществом макрорасширения является то, что оно не имеет сведений о синтаксисе, лежащем в основе базового языка, и может применяться для расширения данного синтаксиса. К сожалению, данным преимуществом очень легко злоупотребляют, создавая непрозрачный, непредсказуемый код, который является богатым источником тяжело определяемых ошибок.
Для языка С классическим примером такой проблемы является макрос, подобный следующему.
#define max(x, у) х > у ? x : у
Данный макрос создает как минимум две проблемы. Одна из них заключается в том, что он может вызвать непредсказуемые результаты, в случае если один из аргументов является выражением, включающим в себя оператор меньшего приоритета, чем
>или
?:. Рассмотрим выражение
max(а = b, ++с). Если программист забыл, что max является макросом, то он будет ожидать, что присваивание
a = bи преинкрементная операция с
сбудут выполнены до того, как результирующие значения будут переданы
maxв качестве аргументов.
Однако это не так. Вместо этого препроцессор преобразует данное выражение в
a = b > ++c ? a = b : ++c, которое правила приоритета компилятора С заставляют интерпретировать как
a = (b > ++c ? a = b : ++c). Результат будет присвоен а.
Подобное неверное взаимодействие можно предотвратить, кодируя определение макроса более безопасно.
#define max(x, у) ((x) > (у) ? (х) : (y))
С таким определением выражение будет развернуто как
((a = b) > (++с) ? (а = b) : (++c)), что решает одну проблему, однако следует заметить, что переменная
сможет быть инкрементирована дважды. Существуют менее очевидные варианты данной проблемы, такие как передача макросу вызова функции с побочными эффектами.
Как правило, взаимодействие между макросами и выражениями с побочными эффектами может привести к неудачным результатам, которые трудно диагностировать. Макропроцессор С умышленно создан легковесным и простым. Более мощные макропроцессоры способны действительно вызвать более серьезные проблемы.
Язык форматирования TEX (см. главу 18) хорошо иллюстрирует общую проблему. ТеХ — умышленно разрабатывался как язык Тьюринга (в нем имеются условные операции, циклы и рекурсия), однако, несмотря на то, что его можно заставить делать поразительные вещи, TEX-код часто нечитабельный и трудный в отладке. Исходные коды для LATEX, наиболее широко используемого TEX-макропакета, являются поучительным примером: они созданы в очень хорошем TEX-стиле, но даже несмотря на это их крайне трудно понять.
Менее значительная по сравнению с описанной проблема заключается в том, что макрорасширение склонно усложнять диагностику ошибок. Процессор базового языка создает отчеты об ошибках, относящиеся к развернутому макросом тексту, а не к оригинальному коду, который просматривает программист. Если связь между ними затемняется макрорасширением, то, возможно, что созданные диагностические отчеты будет очень трудно связать с фактическим местом возникновения ошибки.
Данная проблема особенно характерна для препроцессоров и макросов, которые могут иметь многострочные расширения, условно включать или исключать текст, или иным путем изменять количество строк в развернутом тексте.
Каскады макрорасширений, встроенные в язык, могут выполнять самокоррекцию, обрабатывая номера строк так, чтобы создать ссылки на текст до расширения. Так работает, например, макросредство утилиты pic(1). Данную проблему гораздо труднее решить, когда макрорасширение выполняется препроцессором.
В препроцессоре С проблема решается путем создания директив #line каждый раз, когда выполняется включение или многострочное расширение. Ожидается, что C-компилятор интерпретирует их и соответственно скорректирует номера строк в отчетах об ошибках. К сожалению, в макропроцессоре m4 подобное средство отсутствует.
Выше были описаны причины для крайне осторожного использования макрорасширений. Один из долгосрочных уроков опыта Unix заключается в том, что макросы склонны создавать больше проблем, чем решают. Современные конструкции языков и мини-языков отходят от их использования.
8.3.5. Язык или протокол прикладного уровня
Не менее важно определить, будут ли другие программы интерактивно вызывать ядро мини-языка в качестве подчиненного процесса. Если это так, то конструкция, вероятно, должна меньше походить на диалоговый язык для взаимодействия с человеком и быть более похожей на протоколы прикладного уровня, рассмотренные в главе 5.
Основное отличие заключается в том, насколько тщательным является обозначение границ транзакций. Люди хорошо определяют, где заканчивается диалоговый вывод CLI-интерфейса и где находится приглашения для следующего ввода. Человек может использовать контекст, для того чтобы определить, что значительно, а что следует проигнорировать. Компьютерным программам гораздо сложнее справиться с этой задачей. Без однозначных маркеров окончания вывода или указания его точной длины они не способны определить, когда необходимо прекратить чтение.
Еще хуже, когда ввод программы буферизируется (часто непреднамеренно, как в stdio). Программа, которая очевидно прекращает чтение в верной позиции, может, несмотря на это, впоследствии принять ввод.
(Дуг Макилрой.)
Программы, в которых главные процессы пытаются интерактивно обмениваться данными с подчиненными мини-языками, где данная проблема тщательно не проработана, подвержены взаимоблокировкам при рассинхронизации главного и подчиненного процессов (проблема, впервые упомянутая в главе 7).
Существуют обходные пути для управления мини-языками, разработанными не так тщательно. Прототипом для большинства из них является Tcl-пакет expect. Данный пакет облегчает диалог с CLI-интерфейсами. Он создан на основе следующей операции: чтение данных подчиненного процесса до тех пор, пока либо не будет найдено соответствие заданному регулярному выражению, либо пока не истечет определенное время. Используя это (и, конечно, операцию отправки данных подчиненному процессу), нередко можно сконструировать главные программы, осуществляющие надежные диалоги с подчиненными процессами, даже когда последние к этому не приспособлены.
В других языках доступны эквиваленты пакета expect. Полезную информацию можно найти в Web, используя в качестве поисковой фразы название языка с дополнительными ключевыми словами "Tcl expect". Однако для разработчика мини-языка было бы недальновидно предполагать, что все пользователи являются специалистами по использованию пакета expect. Даже если они являются таковыми, данный подход является дополнительным связующим уровнем и местом возникновения ошибок.
При разработке мини-языка следует помнить о данной проблеме. Хорошей идеей может быть добавление опции, которая изменяет диалоговое поведение, и ответы становятся более похожими на протокол прикладного уровня с недвусмысленными разделителями конца вывода и аналогом заполнения байтами.
9
Генерация кода: повышение уровня спецификации
Попавший в тупик программист… часто может сделать больше, отходя от кода, останавливаясь и анализируя имеющиеся данные. Представление является сущностью программирования.
("The Mythical Man-Month", юбилейное издание (1975—1995)) (—Фред Брукс)
В главе 1 отмечалось, что людям гораздо удобнее мысленно представить себе данные, чем анализировать управляющую логику программы. Для того чтобы понять это, следует сравнить выразительность и дидактическую силу диаграммы 50-узлового дерева указателей с блок-схемой программы, состоящей из 50 строк. Или (что еще лучше) диаграмму инициализатора массива, выражающего таблицу преобразования, с эквивалентным оператором выбора. Различия в прозрачности и ясности поразительны[93].
Данные более понятны, чем программная логика. Это верно независимо от того, являются ли данные обычной таблицей, декларативным языком разметки, системой шаблонов или набором макросов, которые расширяют программную логику. Хорошей практикой является перемещение как можно больше сложности конструкции из процедурного кода в данные, а также выбор форм представления данных, которые удобны для человека, осуществляющего сопровождение и манипулирующего этими данными. Преобразование таких форм в формы, пригодные для машинной обработки, — задача машин, а не людей.
Другим важным преимуществом высокоуровневых, более декларативных форм записи является то, что они лучше приспособлены к проверке во время компиляции. Для процедурных форм записи характерно сложное поведение во время выполнения программ, которое трудно анализировать на этапе компиляции. Декларативные нотации предоставляют гораздо больше возможностей для обнаружения ошибок, поскольку позволяют полнее понять запланированное поведение.
(Генри Спенсер.)
Это понимание теоретически обосновывает набор практических приемов, которые всегда были важной частью инструментария Unix-программиста — языки очень высокого уровня, программы, управляемые данными, генераторы кода и узкоспециальные мини-языки. Объединяет их то, что все они являются способами, позволяющими поднять генерацию кода на несколько уровней выше, чтобы спецификации могли быть меньше. Ранее отмечалось, что плотность дефектов стремится к почти постоянному значению в различных языках программирования. Все указанные практические приемы означают сокращение количества строк и, соответственно, уменьшение вероятности появления ошибок.
В главе 8 описывалось использование специализированных мини-языков. В главе 14 представлены аргументы в пользу языков очень высокого уровня. В данной главе рассматривается несколько примеров конструкции программ, управляемых данными, а также ряд примеров генерации особого кода. Некоторые средства генерации кода описаны в главе 15. Как и мини-языки, данные методы позволяют радикально сократить количество строк кода в программах и соответственно уменьшить время отладки и затраты на сопровождение.
9.1. Создание программ, управляемых данными
При создании программ, управляемых данными (data-driven programming), код и структуры данных, на которые он воздействует, четко отделяются друг от друга и проектируются так, чтобы можно было изменять логику программы путем редактирования не кода, а структуры данных.
Создание программ, управляемых данными, иногда путают с объектно-ориентированным программированием — еще одним стилем программирования, в котором самое важное значение имеет организация данных. Между данными стилями есть как минимум два отличия. Одно из них заключается в том, что в первом случае данные представляют собой не просто состояние некоторого объекта, а фактически определяют управляющую логику программы. Тогда как основной проблемой в ОО-программировании является инкапсуляция, основная проблема при создании программ, управляемых данными, заключается в написании как можно меньшего количества фиксированного кода. Операционная система Unix имеет более устойчивые традиции в создании программ, управляемых данными, чем в ОО-программировании.
Разработку управляемых данными программ также часто путают с написанием конечных автоматов. Выразить логику конечного автомата в виде таблицы или структуры данных действительно возможно, однако запрограммированные вручную конечные автоматы обычно представляют собой жесткие блоки кода, которые гораздо труднее модифицировать, чем таблицу.
При выполнении любого вида генерации кода или создании программ, управляемых данными, необходимо помнить важное правило: решение проблемы всегда следует переносить на более высокие уровни. Не следует вручную улучшать сгенерированный код или любые промежуточные формы представления. Вместо этого следует задуматься о способе усовершенствования или замены средства трансляции. Иначе, вероятно, выяснится, что улучшение вручную кода, который должен был быть корректно сгенерированным машиной, превратится в бесконечную трату времени.
На верхней границе шкалы сложности создание управляемых данными программ сливается с написанием интерпретаторов для p-кода или простых мини-языков, которые рассматривались в главе 8. На других границах оно сливается с генерацией кода и программированием конечных автоматов. Различия фактически не так важны. Важной частью является перемещение логики программы из жестко закодированных управляющих структур в данные.
9.1.1. Учебный пример: ascii
Автор этой книги поддерживает программу, которая называется ascii и представляет собой очень простую небольшую утилиту, интерпретирующую аргументы командной строки как названия ASCII-символов (ASCII, American Standard Code for Information Interchange — Американский стандартный код обмена информацией) и отображает все эквивалентные названия. Код и документация данной программы доступны на сайте проекта <http://www.catb.org/~esr/ascii>. Ниже приводится иллюстративная копия экрана.
esr@snark:~/WWW/writings/taoup$ ascii 10
ASCII 1/0 is decimal 016, hex 10, octal 020, bits 00010000: called ^P, DLE
Official name: Data Link Escape
ASCII 0/10 is decimal 010, hex 0a, octal 012, bits 00001010: called LF, NL
Official name: Line Feed
C escape: '\n'
Other names: Newline
ASCII 0/8 is decimal 008, hex 08, octal 010, bits 00001000: called ^H, BS
Official name: Backspace
C escape: '\b'
Other names:
ASCII 0/2 is decimal 002, hex 02, octal 002, bits 00000010: called ^B, STX
Official name: Start of Text
О том, что в основу данной программы положена хорошая идея, свидетельствует тот факт, что программу можно использовать неожиданным способом — как быстрое вспомогательное CLI-средство для преобразования десятичных, шестнадцатеричных, восьмеричных и двоичных форм представления байтов.
Основная логика данной программы могла бы быть реализована в виде конструкции выбора с 128 условными переходами. Однако в таком случае код был бы громоздким и сложным в сопровождении. Кроме того, в нем смешивались бы части, которые изменяются сравнительно часто (такие как список сленговых названий символов), а также части, изменяемые редко или вообще немодифицируемые (такие как официальные названия). Помещение таких частей в один ряд условных обозначений и ошибки в ходе редактирования, вероятнее всего, затрагивали бы данные, которые должны оставаться неизменными.
Вместо этого утилита была создана как управляемая данными программа. Все строки с названиями символов находятся в табличной структуре, которая значительно крупнее любой из функций в коде (в действительности, если учитывать количество строк, она больше чем любые три функции программы). В коде просто реализована навигация по таблице и выполнение низкоуровневых задач, таких как преобразование систем счисления. Инициализатор фактически находится в файле
nametable.h, который генерируется способом, рассмотренным далее в данной главе.
Подобная организация упрощает добавление новых названий символов, изменение существующих или удаление старых названий просто путем редактирования таблицы, не затрагивая кода.
Способ организации программы является хорошим Unix-стилем, но формат ее вывода сомнительный. Трудно понять, как практически можно применить вывод в качестве ввода другой программы, поэтому утилита слабо приспособлена к взаимодействию с другими программами.
9.1.2. Учебный пример: статистическая фильтрация спама
Одним интересным случаем управляемых данными программ являются статистические самообучающиеся алгоритмы для обнаружения спама (нежелательной массы электронной почты). Целый класс программ фильтрации почты (которые легко можно найти в Web, например, popfile, spambayes и bogofilter) используют базу данных взаимосвязи слов как замену для сложной условной логики спам-фильтров на основе сличения с образцами.
Подобные программы стали широко распространенными в Internet очень быстро после выхода в 2002 году примечательной статьи Пола Грэхема (Paul Graham) "A Plan for Spam" [31]. Пока наблюдался бурный рост, вызванный растущими затратами на гонку вооружений в программах сличения с образцами, идея статистической фильтрации была раньше и быстрее принята в среде Unix. Отчасти это, конечно, было связано с тем, что почти все Internet-провайдеры (которые больше всех были озабочены спамом и, следовательно, имели наибольший стимул принимать новые эффективные методики) являются Unix-предприятиями. Этому, несомненно, также способствовало согласие с некоторыми традиционными идеями в конструировании программного обеспечения для Unix.
Традиционные спам-фильтры требуют, чтобы системный администратор (или другое ответственное лицо) поддерживал информацию об образцах текста, найденных в спаме, — имена узлов, не отправляющих ничего, кроме спама, фразы-приманки, часто используемые порнографическими сайтами или Internet-мошенниками, и аналогичные сведения. В своей статье Грэхем точно подметил, что программистам нравится идея фильтрации по образцам, и иногда они не способны "взглянуть за рамки" данного подхода, поскольку он предлагает им такие возможности проявить свою сообразительность.
С другой стороны, статистические спам-фильтры работают, накапливая информацию от пользователей о том, что те считают спамом, а что нет. Данные сведения вносятся в базы данных статистических корреляционных коэффициентов или весов, связывающих слова или фразы с пользовательской классификацией спам/неспам. В наиболее популярных алгоритмах используются частные случаи теоремы Байеса об условных вероятностях, однако также применяются другие методики (включая различные виды полиномиального хэширования).
Во всех таких программах корреляционная проверка представляет собой сравнительно простую математическую формулу. Весовые коэффициенты, подставленные в формулу, наряду с проверяемым сообщением служат в качестве неявной управляющей структуры для фильтрующего алгоритма.
Проблема традиционных спам-фильтров на основе сличения с образцом заключается в их хрупкости. Спамеры постоянно состязаются с базами данных правил фильтрации, заставляя кураторов постоянно перенастраивать фильтры, для того чтобы "оставаться на первых позициях в гонке вооружений". Статистические спам-фильтры создают собственные правила фильтрации на основе информации пользователей.
Фактически опыт работы со статистическими фильтрами показывает, что отдельный используемый самообучающийся алгоритм гораздо менее важен, чем качество наборов данных спам/неспам, на основе которых алгоритм вычисляет весовые коэффициенты. Поэтому результаты статистических фильтров действительно больше определяются моделью данных, чем алгоритмом.
Статья "A Plan for Spam" была ошеломляющей новостью, поскольку ее автор убедительно доказал, что простой, даже грубый статистический подход дает меньшее количество принятых за спам и не являющихся таковыми сообщений, чем могли бы предоставить любые сложные методики на основе сличения с образцом или человек, просматривающий письма. Unix-программистам проще избежать соблазна искусных методик сличения с образом, чем их коллегам в других культурах программирования, которые не так привязаны к принципу K.I.S.S.
9.1.3. Учебный пример: программирование метаклассов в fetchmail
Утилита fetchmailconf(1), конфигуратор файлов профилей, поставляемая с программой fetchmail(1), содержит полезный пример передовой программы, управляемой данными, написанной в объектно-ориентированном языке очень высокого уровня.
В октябре 1997 года серия вопросов в списке рассылки пользователей fetchmail продемонстрировала тот факт, что конечные пользователи сталкивались с возрастающими проблемами при создании конфигурационных файлов для fetchmail. В файле используется простой классический для Unix свободный формат синтаксиса. Однако данный файл может оказаться неприступно сложным, когда пользователь имеет учетные записи POP3 и IMAP на нескольких узлах. Несколько упрощенная версия конфигурационного файла fetchmail приведена в примере 9.1.
Цель создания fetchmaikonf заключалась в том, чтобы полностью скрыть синтаксис управляющего файла за стильным, эргономичным GUI-интерфейсом с кнопками выбора, бегунками и формами для заполнения. Однако в бета-версии была проблема: программа могла легко создавать конфигурационные файлы, исходя из действий, предпринятых пользователем в GUI, но не могла считывать и редактировать уже существующие файлы.
Пример 9.1. Синтаксис файла fetchmailrcset postmaster "esr"
set daemon 300
poll imap.ccil.org with proto IMAP and options no dns
aka snark.thyrsus.com locke.ccil.org ccil.org
user esr there is esr here
options fetchall dropstatus warnings 3600
poll imap.netaxs.com with proto IMAP
user "esr" there is esr here options dropstatus warnings 3600
Анализатор для синтаксиса конфигурационного файла fetchmail является довольно сложным. Фактически он написан с использованием программ yacc и lex, двух классических инструментов Unix для создания кода синтаксического анализатора на языке С. Вначале разработчикам показалось, что для того чтобы с помощью fetchmailconf можно было редактировать существующие конфигурационные файлы, понадобится воспроизвести тот же сложный синтаксический анализатор в языке реализации fetchmailconf — Python.
Такая тактика выглядела бесперспективной. Даже если не принимать во внимание объем необходимой дублирующей работы, очень трудно быть уверенным в том, что два синтаксических анализатора, написанных на двух различных языках, допускают использование одной и той же грамматики. Обеспечить в дальнейшем их синхронизацию по мере развития конфигурационного языка будет чрезвычайно сложно. Данный подход нарушал бы правило SPOT, описанное в главе 4.
На какое-то время автор был поставлен в тупик данной проблемой. Разрешило ее интуитивное понимание того, что программа fetchmailconf может использовать собственный синтаксический анализатор fetchmail в качестве фильтра. В результате в fetchmail был добавлен параметр
--configdump, который позволял бы анализировать файл
.fetchmailrcи отправлять результаты на стандартный вывод в формате Python-инициализатора. Для приведенного выше файла результаты выглядели бы приблизительно так, как показано в примере 9.2 (для экономии места некоторые данные, не связанные с примером, опущены).
Основное препятствие было преодолено. Интерпретатор Python мог затем оценить вывод fetchmail
--configdumpи прочесть доступную для fetchmailconf конфигурацию как значение переменой "fetchmail".
Однако описанное препятствие было не последним. Было действительно необходимо не только предоставить fetchmail существующую конфигурацию, но превратить ее в связанное дерево действующих объектов. В данном дереве было бы 3 вида объектов: Configuration (объект верхнего уровня, представляющий всю конфигурацию), Site (представляющий один из серверов для опроса) и User (представляющий пользовательские данные, связанные с узлом). Файл в примере описывает 3 объекта Site, каждый из которых связан с одним пользовательским объектом.
Данные 3 класса объектов уже существовали в fetchmailconf. Каждый из них имел метод, который заставлял его выводить на экран GUI-панель редактирования для модификации своего экземпляра данных. Последняя проблема сводилась к некоторому преобразованию статических данных в Python-инициализаторе в действующие объекты.
Пример 9.2. Дамп Python-структуры для конфигурации fetchmailfetchmailrc = {
'poll_interval':300,
"logfile":None,
"postmaster":"esr",
'bouncemail':TRUE,
"properties":None,
'invisible':FALSE,
'syslog' :FALSE,
# List of server entries begins here
# (Ниже начинается список серверов)
'servers': [
# Entry for site `imap.ccil.org' begins:
# (Начало записи для узла imap.ccil.org:)
{
"pollname":"imap.ccil.org",
'active':TRUE,
"via":None,
"protocol":"IMAP",
'port':0,
'timeout':300,
'dns':FALSE,
"aka":["snark.thyrsus.com","locke.ccil.org","ccil.org"],
'users': [
{
"remote":"esr",
"password":"masked_one",
'localnames':["esr"],
'fetchall':TRUE,
'keep':FALSE,
'flush':FALSE,
"mda":None,
'limit':0,
'warnings':3600,
}
' ]
}
'
# Entry for site `imap.netaxs.com' begins:
# (Начало записи для узла imap.netaxs.com:)
{
"pollname":"imap.netaxs.com",
'active':TRUE,
"via":None,
"protocol":"IMAP",
'port':0,
'timeout':300,
'dns':TRUE,
"aka":None,
'users': [
{
"remote":"esr",
"password":"masked_two",
'localnames':["esr"],
'fetchall':FALSE,
'keep':FALSE,
'flush':FALSE,
"mda":None,
'limit':0,
'warnings':3600,
}
' ]
}
'
]
}
Рассматривалась идея написания связующего уровня, который имел бы явную информацию о структуре всех 3 классов и использовал бы данную информацию для просмотра инициализатора при создании соответствующих объектов. Однако данная идея была отклонена, поскольку существовала вероятность добавления со временем новых членов класса, по мере создания новых функций в конфигурационном языке. Если бы код создания объектов был написан таким очевидным путем, то он также был бы хрупким и склонным к рассинхронизации при изменении определения классов либо структуры инициализатора, выводимой с помощью генератора отчетов
--configdump. Подобный подход приводит к бесконечному появлению ошибок.
Более надежным способом было бы использование создание программы, управляемой данными, т.е. кода, который анализировал бы форму и члены инициализатора, опрашивал бы определения классов об их членах, а затем согласовывал бы оба набора.
Программисты, работающие с Lisp и Java, называют данную методику интроспекцией (introspection). В некоторых других объектно-ориентированных языках она называется программированием метаклассов (metaclass hacking) и, как правило, считается "черной магией", понятной только "посвященным". В большинстве объектно- ориентированных языков данная методика не поддерживается вообще, а в тех языках, где она поддерживается (среди них Perl и Java), она часто сложна и ненадежна. Однако в языке Python средства интроспекции и программирования метаклассов исключительно доступны.
В примере 9.3 приведен фрагмент кода приблизительно со строки 1895 в версии 1.43.
Пример 9.3. Код метаклассаcopy_instance
def copy_instance(toclass, fromdict):
#Make a class object of given type from a conformant dictionary.
class_sig = toclass.__dict__.keys(); class_sig.sort()
dict_keys = fromdict.keys(); dict_keys.sort()
common = set_intersection(class_sig, dict_keys)
if 'typemap' in class_sig:
class_sig.remove('typemap')
if tuple(class_sig) != tuple(dict_keys):
print "Conformability error"
#print "Class signature: " + `class_sig`
#print "Dictionary keys: " + `dict_keys`
print "Not matched in class signature: "+ \
`set_diff(class_sig, common)`
print "Not matched in dictionary keys: "+ \
`set_diff(dict_keys, common)`
sys.exit(1)
else:
for x in dict_keys:
setattr(toclass, x, fromdict[x])
Большую часть в примере представляет код контроля ошибок, учитывая возможность того, что члены класса и генерация отчета
--configdumpвыпали из синхронизации. Такая проверка гарантирует, что в случае возникновения сбой в коде будет обнаружен на ранней стадии, т.е. реализуется правило исправности. Главной частью кода являются две последние строки, которые устанавливают атрибуты в классе из соответствующих членов в словаре. Данные строки эквивалентны следующим строкам.
def copy_instance(toclass, fromdict):
for x in fromdict.keys():
setattr(toclass, x, fromdict[x])
Если разрабатываемый код настолько же прост, то весьма вероятно, что он верен. В примере 9.4 приведен код, вызывающий данный метакласс.
Ключевым моментом в данном коде является то, что он проходит 3 уровня инициализатора (конфигурация/сервер/пользователь), устанавливая корректные объекты каждого уровня в списки, содержащиеся в следующем объекте более высокого уровня. Поскольку метакласс
copy_instanceуправляется данными и является полностью общим, его можно использовать во всех 3 уровнях для 3 различных типов объектов.
Данный пример — пример новой школы. Язык Python был создан гораздо позднее 1990 года. Однако пример отражает идеи, которые возвращаются к Unix-традициям 1969 года. Если бы размышления над Unix-программированием, практикуемым предшественниками, не научили бы автора "конструктивной лени" — настаивая на повторном использовании кода и отказе от написания дублирующегося связующего кода в соответствии с правилом SPOT — он мог бы "удариться" в программирование синтаксического анализатора на языке Python. Главное понимание того, что сама программа fetchmail могла бы превратиться в синтаксический анализатор конфигурации fetchmailconf, возможно, никогда бы не пришло.
Пример 9.4. Вызывающий контекст дляcopy_instance
#Сложная часть - инициализация объектов из глобального класса
#`configuration'.
#`Configuration' - верхний уровень объектного дерева,
#который планируется изменить
Configuration = Controls()
copy_instance(Configuration, configuration)
Configuration.servers = [];
for server in configuration['servers']:
Newsite = Server()
copy_instance(Newsite, server)
Configuration.servers.append(Newsite)
Newsite.users = [];
for user in server['users']:
Newuser = User()
copy_instance(Newuser, user)
Newsite.users.append(Newuser)
Другое понимание (того, что метакласс
copy_instanceможет быть общим) происходит из Unix-традиции старательного поиска способов избежать кодирования вручную. Но особенно, Unix-программисты привыкли к написанию спецификаций для генерации синтаксических анализаторов для обработки языков разметки. Это скоро привело к предположению, что остальная часть работы может быть выполнена путем некоторого общего обхода дерева конфигурационной структуры. Для четкого разрешения задачи проектирования необходимо было два отдельных (один над другим) этапа создания программы, управляемой данными.
Интуитивное понимание подобное описанному может быть необыкновенно действенным. Рассматриваемый код был написан в течение приблизительно 90 минут, был работоспособен при первом запуске и с тех пор в течение многих лет оставался стабильным (единственный сбой произошел при обработке исключительной ситуации в присутствии действительного перекоса версий). Данный код содержит менее 40 строк и великолепно прост. Не существует способа, при котором примитивный подход полного создания второго синтаксического анализатора мог бы привести к созданию такого же удобства сопровождения, такой же надежности или компактности. Повторное использование кода, упрощение, обобщение, ортогональность — Дзэн операционной системы Unix в действии.
В главе 10 рассматривается синтаксис файла конфигурации fetchmail в качестве примера стандартного shell-подобного метаформата для конфигурационных файлов. В главе 14 fetchmailconf используется как пример, демонстрирующий мощность языка Python в быстрой разработке GUI-интерфейсов.
9.2. Генерация специального кода
Операционная система Unix оснащена несколькими мощными генераторами кода специального назначения, предназначенного для таких целей, как создание лексических анализаторов (tokenizers) и синтаксических анализаторов; они рассматриваются в главе 15. Однако существуют более простые, легковесные виды генераторов кода, которые можно использовать для облегчения работы программиста и не требуют знания теории компиляторов или написания процедурной логики (подверженной ошибкам).
Ниже приводится два иллюстративных учебных примера.
9.2.1. Учебный пример: генерация кода для ascii-дисплеев
Запущенная без аргументов программа ascii генерирует экран справочной информации по использованию, подобный распечатке, приведенной в примере 9.5.
Данный экран достаточно тщательно спроектирован, чтобы уместиться в 23 строки и 79 колонок, поэтому он помещается в терминальном окне 24×80.
Таблицу можно было бы создавать во время выполнения, т.е. на лету. Подгонка десятичных и шестнадцатеричных столбцов была бы достаточно простой. Однако существует достаточно необычных, делающих код крайне неудобным, случаев от перенесения строк таблицы в нужных местах до вывода таких неотображаемых символов, как NUL, вместо обычных символов. Более того, столбцы понадобилось бы неравномерно заполнять пробелами, чтобы заставить таблицу уместиться в 79 колонках. Но любой Unix-программист автоматически выражал бы таблицу как блок данных, прежде чем обнаружил бы данные проблемы.
Самым примитивным способом создания справочного экрана было бы помещение каждой строки в C-инициализатор в исходном коде
ascii.с, а затем заставить код, проходящий через инициализатор, выписывать строки. Проблема такого метода заключается в том, что дополнительные данные в формате C-инициализатора (завершающие разделители строк, строковые кавычки, запятые) удлиняли бы строки более 79 символов. Это привело бы к переносу строк и усложнило бы преобразование внешнего вида кода к внешнему виду вывода, что, в свою очередь, усложнило бы редактирование справочного дисплея, который и без этого сложно было уместить в экран на 24×80 растровых ячеек.
Более сложный метод использования режима вставки строк в препроцессоре ANSI С приводит к другому варианту той же проблемы. По существу, любой способ явного включения в код справочного экрана задействовал бы пунктуацию в начале и конце строки, для которой не было места[94]. А копирование на экран таблицы из файла во время выполнения выглядело ненадежно. В конце концов, файл мог быть утерян.
Пример 9.5. Справка по использованию программы asciiUsage: ascii [-dxohv] [-t] [char-alias...]
-t = one-line output -d = Decimal table -o = octal table -x = hex table
-h = This help screen -v = version information
Prints all aliases of an ASCII character. Args may be chars, C \-escapes,
English names, ^-escapes, ASCII mnemonics, or numerics in decimal/octal/hex.
Dec Hex Dec Hex Dec Hex Dec Hex Dec Hex Dec Hex Dec Hex Dec Hex
0 00 NUL 16 10 DLE 32 20 48 30 0 64 40 @ 80 50 P 96 60 ` 112 70 p
1 01 SOH 17 11 DC1 33 21 ! 49 31 1 65 41 A 81 51 Q 97 61 a 113 71 q
2 02 STX 18 12 DC2 34 22 " 50 32 2 66 42 B 82 52 R 98 62 b 114 72 r
3 03 ETX 19 13 DC3 35 23 # 51 33 3 67 43 C 83 53 S 99 63 c 115 73 s
4 04 EOT 20 14 DC4 36 24 $ 52 34 4 68 44 D 84 54 T 100 64 d 116 74 t
5 05 ENQ 21 15 NAK 37 25 % 53 35 5 69 45 E 85 55 U 101 65 e 117 75 u
6 06 ACK 22 16 SYN 38 26 & 54 36 6 70 46 F 86 56 V 102 66 f 118 76 v
7 07 BEL 23 17 ETB 39 27 ' 55 37 7 71 47 G 87 57 W 103 67 g 119 77 w
8 08 BS 24 18 CAN 40 28 ( 56 38 8 72 48 H 88 58 X 104 68 h 120 78 x
9 09 HT 25 19 EM 41 29 ) 57 39 9 73 49 I 89 59 Y 105 69 i 121 79 у
10 0A LF 26 1A SUB 42 2A * 58 3A : 74 4A J 90 5A Z 106 6A j 122 7A z
11 0B VT 27 1B ESC 43 2B + 59 3B ; 75 4B K 91 5B [ 107 6B k 123 7B {
12 0С FF 28 1С FS 44 2C , 60 3C < 76 4C L 92 5C \ 108 6C l 124 7C |
13 0D CR 29 1D GS 45 2D - 61 3D = 77 4D M 93 5D ] 109 6D m 125 7D }
14 0E SO 30 1E RS 46 2E . 62 3E > 78 4E N 94 5E ^ 110 6E n 126 7E ~
15 0F SI 31 1F US 47 2F / 63 3F ? 79 4F О 95 5F _ 111 6F о 127 7F del
Данная проблема решается следующим образом. В состав исходного дистрибутива входит файл с именем
splashscreen, в котором содержится такой же экран использования, как в приведенном примере. Исходный код на С содержит следующую функцию.
void showHelp(FILE *out, char *progname) {
fprintf(out,"Usage: %s [-dxohv] [-t] [char-alias...]\n", progname);
#include "splashscreen.h"
exit(0);
}
Файл
splashscreen.hгенерируется инструкцией make-файла.
splashscreen.h: splashscreen
sed <splashscreen >splashscreen.h \
-e 's/\\/\\\\/g' -e 's/"/\\"/' -e 's/.*/puts("&");/'
Поэтому при сборке программы файл splashscreen автоматически преобразовывается в серию вызовов функции вывода, которые C-препроцессор затем включает в необходимую функцию.
Путем создания кода из данных поддерживается редактируемая версия справочного экрана, идентичного его представлению на дисплее. В результате этого повышается прозрачность. Более того, при желании можно модифицировать справочный экран, не затрагивая C-кода вообще, а верное внешнее представление будет автоматически получено при следующей сборке.
По тем же причинам инициализатор, содержащий строки синонимичных названий, также генерируется посредством sed-сценария в make-файле из файла с именем
nametable, входящего в состав исходного дистрибутива ascii. Большая часть файла
nametableпросто копируется в С-инициализатор. Но процесс генерации упростил бы адаптацию данного средства для других 8-битовых наборов символов, таких как ISO-8859 (Latin-1 и подобные).
Данный пример почти тривиален, однако он, тем не менее, иллюстрирует преимущества генерации как простого, так и особого кода. Подобные методики могли бы применяться для более крупных программ, предоставляя, соответственно, еще большие преимущества.
9.2.2. Учебный пример: генерация HTML-кода для табличного списка
Предположим, что требуется поместить страницу табличных данных на Web-страницу. Необходимо, чтобы первые несколько строк выглядели, как в примере 9.6.
Пример 9.6. Необходимый формат вывода для таблицы звездAalat David Weber The Armageddon Inheritance
Aelmos Alan Dean Foster The Man who Used the Universe
Aedryr Steve Miller/Sharon Lee Scout's Progress
Aergistal Gerard Klein The Overlords of War
Afdiar L. Neil Smith Tom Paine Maru
Agandar Donald Kingsbury Psychohistorical Crisis
Aghirnamirr Jo Clayton Shadowkill
Примитивнейший способ решения данной задачи заключался бы в написании вручную HTML-кода для необходимого внешнего представления. Таким образом, каждый раз, когда потребуется добавить новое имя, придется вручную писать еще один набор тегов
<tr>и
<td>для новой записи. Такая необходимость очень быстро стала бы утомительной. Но еще хуже то, что при изменении формата списка каждую запись потребуется кодировать вручную.
Внешне разумный способ решить данную проблему заключался бы в том, чтобы внести данные в трехстолбцовую таблицу в базе данных, а затем использовать некоторую причудливую CGI-методику[95] или поддерживающий базы данных шаблонный процессор, например, PHP для создания страницы на лету. Однако, предположим, разработчику известно, что список не будет изменяться очень часто, и не требуется запускать сервер баз данных для того, чтобы отображать данные, а также нежелательно загружать сервер излишним CGI-трафиком.
Существует простое решение: поместить данные в файл в простом табличном формате, см. пример 9.7.
Пример 9.7. Модель таблицы звездAalat :David Weber :The Armageddon Inheritance
Aelmos :Alan Dean Foster :The Man who Used the Universe
Aedryr :Steve Miller/Sharon Lee :Scout's Progress
Aergistal :Gerard Klein :The Overlords of War
Afdiar :L. Neil Smith :Tom Paine Maru
Agandar :Donald Kingsbury :Psychohistorical Crisis
Aghirnamirr :Jo Clayton :Shadowkill
Можно было бы обойтись без явного использования двоеточия в качестве разделителя полей, используя модель, содержащую в качестве разделителя два или более пробела. Однако явный разделитель предохраняет от ошибок, связанных со случайным двойным нажатием пробела в процессе редактирования значений полей.
Затем создается сценарий в shell, Perl, Python или Tcl, который преобразовывает данный файл в HTML-таблицу. Сценарий запускается каждый раз после добавления новой записи. Способ старой школы Unix был бы связан с почти нечитаемым вызовом sed(1)
sed -е 's,^,<tr><td>,' -е 's,$,</td></tr>,' -е 's,$,</td><td>,g'
или, возможно, с несколько более очевидной awk(1)-программой.
awk -F: ' {printf ("<tr><td>%s</td><td>%s</td><td>%s</td></tr>\n", \
$1, $2, $3)}'
Если какой-либо из данных примеров вызывает интерес, но непонятен, то следует прочесть документацию на программу sed(1) или awk(1). В главе 8 отмечалось, что вторая утилита почти совсем вышла из употребления. Первый редактор sed до сих пор остается важным Unix-инструментом, который подробно не рассматривался ввиду того, что (а) Unix-программисты уже знают о нем и (b) тем, кто не является Unix-программистом, нетрудно будет узнать о его использовании из документации, как только они поймут основные идеи конвейеров и перенаправления.
Решение новой школы может основываться на приведенном ниже коде на Python или эквивалентном коде на Perl.
for row in map(lambda x:x.rstrip().split(':'),sys.stdin.readlines()):
print "<tr><td>" + "</td><td>".join(row) + "</td></tr>"
Написание и отладка данных сценариев занимает примерно 5 минут, несомненно, меньше, чем потребовалось бы для создания первоначального HTML-кода вручную или создания и проверки базы данных. Комбинация таблицы и данного кода будет гораздо проще в сопровождении, чем недопроектированный созданный вручную HTML-код или перепроектированная база данных.
Другое преимущество данного способа решения проблемы заключается в том, что поиск информации и редактирование главного файла несложно осуществлять с помощью простого текстового редактора. Еще одним преимуществом является то, что можно экспериментировать с различными преобразованиями таблицы в HTML путем тонкой настройки генерирующего сценария или просто создать подмножество отчета, поместив перед ним фильтр grep(1).
Автор этой книги в настоящее время использует данную технику для сопровождения Web-страницы, на которой перечислены тестовые fetchmail-узлы. Приведенный выше пример является вымышленным только потому, что публикация реальных данных открыла бы учетные записи и пароли пользователей.
Данный пример был отчасти менее тривиальным, чем предыдущий. В данном случае был спроектирован способ разделения между содержанием и форматированием, а также генерирующий сценарий, функционирующий как таблица стилей. (Это еще один способ разделения механизма и политики.)
Урок во всех случаях один и тот же — возможность выполнять как можно меньше работы. Позвольте данным формировать код. Опирайтесь на имеющиеся средства. Отделяйте механизм от политики. Опытные Unix-программисты учатся видеть подобные возможности быстро и автоматически. "Конструктивная лень" является одним из важнейших качеств высококлассного программиста.
10
Конфигурация: правильное начало
Стоит внимательно посмотреть на наши истоки, и результаты организуются сами собой.
(—Александр Кларк (Alexander Clark))
В операционной системе Unix программы могут обмениваться данными со своим окружением различными способами. Эти способы удобно разделить на (а) опрос параметров среды и (b) интерактивные каналы. В данной главе основное внимание уделено опросу параметров среды. Интерактивные каналы рассматриваются в следующей главе.
10.1. Конфигурируемые параметры
Прежде чем погрузиться в детали различных видов конфигурации программ, следует ответить на важнейший вопрос: "Какие параметры должны быть конфигурируемыми?"
Интуитивно Unix-программист ответит: "Все". Правило разделения, которое рассматривалось в главе 1, подталкивает Unix-программистов создавать механизм и там, где это возможно, передавать решения о политике на ближайшие к пользователю уровни. Хотя в таком случае часто создаются мощные и полезные для высококвалифицированных пользователей программы, столь же часто создаются интерфейсы, ошеломляющие новичков и случайных пользователей избытком возможных вариантов и конфигурационных файлов.
В ближайшее время Unix-программисты не собираются избавляться от склонности разрабатывать программы для коллег или наиболее опытных пользователей (в главе 20 рассматривается вопрос о том, будут ли такие перемены действительно желаемыми). Поэтому, вероятно, полезнее будет изменить вопрос: какие параметры не должны быть конфигурируемыми? В Unix-практике имеются некоторые определяющие принципы для решения данной проблемы.
Прежде всего, не следует создавать конфигурационные ключи для тех параметров, которые можно надежно определить автоматическим путем. Такая ошибка поразительно широко распространена. Вместо этого, рекомендуется искать способы устранения конфигурационных ключей путем автоопределения или пытаться использовать альтернативные методы до тех пор, пока один из них не достигнет цели. Если разработчик считает такой подход грубым или слишком дорогим, то ему следует спросить себя, не начал ли он преждевременную оптимизацию.
Я столкнулся с одним из наилучших примеров автоопределения, когда мы с Деннисом Ритчи переносили Unix на Interdata 8/32. Это была машина с обратным порядком следования байтов. Требовалось генерировать для нее данные на компьютере PDP-11, записывать магнитную ленту и загружать эту ленту в Interdata. Обычно ошибка возникала, когда мы забывали изменить порядок следования байтов. Ошибка контрольной суммы показывала, что необходимо отключить ленту, снова подключить ее к PDP-11, заново создать ленту, отключить ее и подключить опять. Однажды Деннис усовершенствовал программу считывания магнитной ленты на Interdata таким образом, что в случае возникновения ошибки контрольной суммы лента перематывалась, активизировался ключ "byte flip" (преобразование порядка байтов) и программа повторно считывала данные с ленты. Вторая ошибка контрольной суммы прерывала загрузку, но в 99% случаев осуществлялось повторное считывание ленты и выполнение верных действий. Продуктивность нашей работы мгновенно возросла, и с того времени мы почти полностью игнорировали порядок следования байтов на ленте.
(Стив Джонсон.)
Существует хорошее эмпирическое правило: необходимо приспосабливаться, если затраты на это не превышают 0,7 сек задержки. 0,7 сек — "магическое" число, поскольку, как обнаружил Джеф Раскин во время разработки Canon Cat, люди почти не способны заметить более короткую задержку при запуске. Она теряется среди ментальных издержек при переключении фокуса внимания.
Второй принцип заключается в том, что ключи оптимизации должны быть невидимыми для пользователей. Экономичная работа программы — задача проектировщика, а не пользователя. Минимальный прирост производительности, который может получить пользователь с помощью ключей оптимизации, обычно не стоит затрат, связанных со сложностью интерфейса.
Unix всегда избегала бессмыслицы файловых форматов (таких как длина записи, фактор блокировки и другие), однако подобная бессмыслица вернулась в чрезмерной, вязкой массе конфигурации. Принцип KISS стал принципом MICAHI: make it complicated and hide it (усложнить и скрыть).
(Дуг Макилрой.)
Наконец, с помощью конфигурационного ключа не следует делать то, что можно сделать при помощи сценария-упаковщика или тривиального конвейера. Не следует вносить в программу дополнительную сложность, если для решения задачи можно без труда задействовать другие программы. (В главе 7 показано, почему утилита ls(1) не содержит встроенного средства формирования страниц или параметра для вызова такого средства.)
Существует несколько более общих вопросов, которые следует обдумывать всякий раз при появлении желания добавить конфигурационный параметр.
• Можно ли исключить данную функцию? Почему "раздувается" справочное руководство, а пользователь перегружен излишними подробностями?
• Можно ли безопасно изменить обычный режим работы программы так, чтобы данный параметр был необязательным?
• Является ли данный параметр только косметическим? Возможно, следует меньше думать о конфигурируемости пользовательского интерфейса и больше внимания уделять корректности его работы?
• Не следует ли сделать режим, активизированный данным параметром, в виде отдельной программы?
Увеличение числа излишних параметров чревато множеством негативных последствий. Одно из наименее очевидных и самых серьезных — это влияние на тестовое покрытие.
Добавление конфигурационного параметра on/off, в случае если оно не сделано очень тщательно, может привести к необходимости удвоения количества тестов. Поскольку на практике количество тестов никогда не удваивается, практический эффект заключается в сокращении количества тестов для любой заданной конфигурации. Десять параметров приводят к 1024 тестированиям, и довольно скоро возникнут реальные проблемы надежности
(Стив Джонсон.)
10.2. Месторасположение конфигурационной информации
Классическая Unix-программа может искать управляющую информацию в 5 группах параметров начальной загрузки:
• файлы конфигурации в каталоге
/etc(или в другом постоянном каталоге системы);
• системные переменные окружения;
• файлы конфигурации (или файлы профилей (dotfile)) в начальном каталоге пользователя (описание данной важной концепции приведено в главе 3);
• пользовательские переменные окружения;
• ключи и аргументы, переданные программе в командной строке во время вызова.
Данные запросы обычно выполняются в описанном выше порядке. Поэтому более поздние (локальные) установки заменяют более ранние (глобальные). Установки, найденные раньше, могут способствовать программе в определении области для дальнейшего поиска конфигурационных данных.
При выборе механизма для передачи программе конфигурационных данных необходимо помнить о том, что хорошая Unix-практика требует использования того механизма, который наиболее близко соответствует ожидаемому времени жизни настроек. Следовательно: для настроек, которые, весьма вероятно, изменяются между вызовами программы, следует использовать ключи командной строки. Для предпочтений, которые изменяются редко, но должны находиться под индивидуальным контролем пользователя, следует использовать конфигурационный файл в начальном каталоге данного пользователя. Для хранения информации о настройках, которые должны устанавливаться системным администратором для всего узла и не изменяются пользователями, используется конфигурационный файл в системной области.
Ниже каждая область конфигурационных параметров рассматривается более подробно, после чего приводится несколько учебных примеров.
10.3. Файлы конфигурации
Файл конфигурации (run-control file) — файл объявлений или команд, связанных с программой, которая интерпретирует его во время запуска. Если программа имеет специфическую для данного узла конфигурацию, которая совместно используется всеми пользователями узла, то часто файл конфигурации находится в каталоге
/etc. (В некоторых Unix-системах для хранения таких данных имеется подкаталог
/etc/conf.)
Сведения пользовательской конфигурации часто находятся в скрытом конфигурационном файле в начальном каталоге данного пользователя. Такие файлы часто называются "dotfiles" (файлы профилей), поскольку они используют Unix-соглашение о том, что имя файла, начинающееся с точки, невидимо для средств создания перечня файлов каталога[96].
Программы также могут иметь конфигурационные или скрытые каталоги. В таких каталогах собираются группы конфигурационных файлов, которые относятся к программе, но их удобнее интерпретировать отдельно (возможно потому, что они связаны с различными подсистемами программы или имеют разный синтаксис).
В настоящее время, независимо от того, используется файл или каталог, соглашение требует, чтобы месторасположение конфигурационной информации имело то же базовое имя что и считывающий ее исполняемый файл. В более раннем соглашении, которое до сих пор широко распространено в системных программах, используется имя исполняемого файла с суффиксом "rc" (от "run control" — управление работой)[97]. Поэтому опытный пользователь Unix, работая с программой "seekstuff", имеющей как общесистемную, так и пользовательскую конфигурацию, ожидает найти первую в файле
/etc/seekstuff, а последнюю — в файле
.seekstuffв своем начальном каталоге. Вместе с тем он не удивился бы, обнаружив файлы
/etc/seekstuffrcи
.seekstuffrc, особенно если программа seekstuff является какой-либо системной утилитой.
В главе 5 описывался несколько отличающийся набор правил проектирования текстовых файловых форматов, а также рассматривались способы оптимизации по различным критериям способности к взаимодействию, прозрачности и экономичности транзакций. Обычно файлы конфигурации только считываются однажды во время запуска программы и не перезаписываются. Следовательно, экономия обычно не является основной проблемой. Возможность взаимодействия и прозрачность подталкивают разработчиков к использованию текстовых форматов, разработанных для чтения людьми и редактирования с помощью обычного текстового редактора.
Несмотря на то, что семантика конфигурационных файлов, несомненно, полностью зависит от программы, существует несколько широко распространенных правил проектирования, связанных с конфигурационным синтаксисом. Они будут описаны далее, а до этого следует рассмотреть важное исключение.
Если программа является интерпретатором какого-либо языка, то ожидается, что существует просто файл команд в синтаксисе данного языка, которые выполняются во время запуска программы. Данное правило важно потому, что Unix-традиции твердо поддерживают разработку всех видов программ как языков специального назначения и мини-языков. Широко известные примеры с файлами профилей такого типа включают в себя различные командные оболочки Unix и программируемый редактор Emacs.
Основанием для данного правила проектирования является убеждение, что частные случаи — негативное явление. Поэтому, любой ключ, изменяющий поведение языка, должен устанавливаться изнутри данного языка. Если при разработке языка обнаруживается, что выразить в самом языке все его начальные установки невозможно, то Unix-программист сказал бы, что в конструкции имеется проблема, которую, вероятнее всего, необходимо исправить, а не разрабатывать конфигурационный синтаксис частного случая.
После рассмотрения исключения следует описать правила обычного стиля конфигурационного синтаксиса. Исторически сложилось так, что моделью для них послужил синтаксис оболочек в Unix.
1. Поддержка объясняющих комментариев, начинающихся с символа #. Синтаксис также должен игнорировать пробел перед символом #, для того чтобы обеспечить поддержку комментариев в строках, содержащих конфигурационные директивы.
2. Предотвращение опасных различий в пустом пространстве. То есть последовательности пробелов и символов табуляции должны синтаксически интерпретироваться как один пробел. Если формат директив ориентирован на строки, то следует игнорировать завершающие пробелы и символы табуляции в строках. Метаправило заключается в том, что интерпретация файла не должна зависеть от невидимых для человеческого глаза различий.
3. Интерпретация нескольких пустых строк и строк комментариев как одной пустой строки. Если во входном формате в качестве разделителей записей используются пустые строки, то, возможно, понадобится гарантия того, что строка комментария не завершает запись.
4. Лексическая интерпретация файла как простой последовательности лексем, разделенных пробелами, или строк лексем. Человеку трудно изучить, запомнить и проанализировать сложные лексические правила, поэтому их следует избегать.
5. Однако следует поддерживать строковый синтаксис для лексем, содержащих пробелы. В качестве сбалансированных разделителей можно использовать одинарные или двойные кавычки. Если поддерживаются оба вида кавычек, то не следует назначать им различную семантику, что характерно для shell, поскольку это является широко известным источником путаницы.
6. Поддержка синтаксиса обратной косой черты для внедрения в строки непечатаемых и специальных символов. Стандартным образцом в данном случае является синтаксис escape-последовательностей, поддерживаемый компиляторами С. Поэтому, например, было бы весьма неожиданно, если бы строка "
a\tb" интерпретировалась бы иначе, чем символ "а", за которым следует символ табуляции, за которым в свою очередь следует символ "b".
С другой стороны, в конфигурационном синтаксисе не следует копировать некоторые аспекты shell-синтаксиса — по крайней мере, не имея значительной и специфической причины. В данную категорию попадают "вычурные" правила использования кавычек и скобок в shell, а также специальные метасимволы shell для масок и подстановки переменных.
Целью данных соглашений является сокращение количества нововведений, с которыми приходится справляться пользователям при чтении и редактировании конфигурационного файла для новой программы. Следовательно, если понадобилось нарушить данные соглашения, то необходимо попытаться сделать необходимость нарушений очевидной, а, кроме того, документировать синтаксис с особенной тщательностью, и (что наиболее важно) проектировать так, чтобы его можно было легко понять из примеров.
Данные правила стандартного стиля только описывают соглашения о лексемах и комментариях. Имена конфигурационных файлов, их высокоуровневый синтаксис и семантическая интерпретация синтаксиса обычно отражают специфику приложения. Однако существует несколько исключений из данного правила; одно из них — файлы профилей, которые стали "широко известными" в том смысле, что обычно содержат информацию, используемую целым классом приложений. Такое совместное использование форматов конфигурационных файлов сокращает количество нововведений, в которых приходится разбираться пользователям.
Среди таких файлов наиболее "укоренившимся", вероятно, является файл
.netrc. Клиентские Internet-программы, которые должны отслеживать пары узел/пароль для пользователя, обычно могут получать их из файла
.netrc, если таковой существует.
10.3.1. Учебный пример: файл .netrc
Файл
.netrc— хороший пример стандартных правил в действии. Пример 10.1 содержит пароли, измененные в целях защиты реального пользователя.
Следует отметить, что разобраться в данном формате не сложно, даже встретив его впервые. Он представляет собой набор троек машина/имя/пароль, каждая из которых описывает учетную запись на удаленном узле. Такая прозрачность фактически гораздо более важна, чем экономия времени путем быстрой интерпретации или экономия пространства путем использования более компактного и непонятного файлового формата. Он позволяет сэкономить гораздо более ценный ресурс — человеческое время, поскольку увеличивает вероятность того, что человек сможет прочесть и модифицировать данный формат без изучения руководства или использования инструмента, менее знакомого, чем простой текстовый редактор.
Пример 10.1. Файл.netrc
#FTP-доступ к моему Web-узлу
machine Unix1.netaxs.com
login esr
password joesatriani
#Мой главный почтовый сервер в Netaxs
machine imap.netaxs.com
login esr
password jeffbeck
#Дополнительный почтовый ящик IMAP в CCIL
machine imap.ccil.org
login esr
password marcbonilla
#Дополнительный почтовый ящик POP в CCIL
machine pop3.ccil.org
login esr
password ericjohnson
#Учетная запись shell в CCIL
machine locke.ccil.org
login esr
password stevemorse
Также следует отметить то, что данный формат используется для предоставления информации нескольким службам. Это является преимуществом, поскольку означает, что конфиденциальную информацию о паролях необходимо хранить только в одном месте. Формат
.netrcбыл разработан для первоначальной клиентской FTP-программы в Unix. Данный формат используется всеми FTP-клиентами, а также распознается некоторыми telnet-клиентами, CLI-инструментом smbclient(1) и программой fetchmail. При разработке Internet-клиента, который должен выполнять аутентификацию паролей посредством удаленной регистрации, правило наименьшей неожиданности требует, чтобы он по умолчанию использовал содержимое файла
.netrc.
10.3.2. Переносимость на другие операционные системы
Общесистемные конфигурационные файлы являются конструкторской тактикой, которую можно применять почти во всех операционных системах, однако довольно трудно найти соответствие файлам профилей в не-Unix-окружении. Критическим элементом, недостающим в большинстве операционных систем, отличных от Unix, является действительная поддержка многопользовательской работы и понятие начального каталога для каждого пользователя. В операционной системе DOS и версиях Windows вплоть до ME (включая Windows 95 и 98), например, такая идея полностью отсутствует; вся конфигурационная информация должна храниться либо в общесистемных файлах конфигурации в фиксированной области, реестре Windows, либо в том же каталоге, из которого запускается программа. В Windows NT имеется некоторое понятие о начальных каталогах пользователей (которое послужило началом пути к Windows 2000 и XP), но оно только недостаточно поддерживается инструментальными средствами системы.
10.4. Переменные окружения
Когда запускается какая-либо Unix-программа, доступная ей среда включает в себя набор связей "имя-значение" (как имена, так и значения являются строками). Некоторые из них устанавливаются пользователем вручную, другие — системой во время регистрации пользователя, либо оболочкой или эмулятором терминала (если таковой используется). В операционной системе Unix в переменных окружения хранится информация о путях поиска файлов, системных установках по умолчанию, номер процесса и идентификатор текущего пользователя, а также другие сведения о среде выполнения программ. Команда
set, введенная в приглашении shell, отображает полный список определенных в текущий момент переменных оболочки.
В языках С и С++ значения данных переменных запрашиваются с помощью библиотечной функции getenv(3). В языках Perl и Python во время запуска инициализируются объекты словарей среды. В других языках, как правило, используется одна из двух перечисленных моделей.
10.4.1. Системные переменные окружения
Существует множество широко известных переменных окружения, значения которых программа может получить при запуске из оболочки Unix. Данные переменные (особенно
НОМЕ) часто требуется оценить до считывания локального файла профиля.
USER
Регистрационное имя учетной записи, под которым инициируется данный сеанс (BSD-соглашение).
LOGNAME
Регистрационное имя учетной записи, под которым инициируется данный сеанс (соглашение System V).
HOME
Начальный каталог пользователя, инициализирующего данный сеанс.
COLUMNS
Количество символьных столбцов управляющего терминала или окна эмулятора терминала.
LINES
Количество символьных строк управляющего терминала или окна эмулятора терминала.
SHELL
Имя командной оболочки данного пользователя (часто используется командами, создающими подоболочку).
PATH
Список каталогов, которые просматривает оболочка при поиске исполняемых команд, соответствующих заданному имени.
TERM
Тип терминала для консоли сеанса или окна эмулятора терминала (предварительные сведения представлены в учебном примере terminfo в главе 6).
TERM— переменная, специально используемая в таких программах для создания удаленных сеансов через сеть (таких как telnet и ssh), предполагается, что они передают и устанавливают значение данной переменной в удаленном сеансе.
(Данный список характерен для Unix-систем, однако он не является исчерпывающим.)
Переменная
HOMEособенно важна, поскольку многие программы используют ее для поиска файлов профилей вызывающего пользователя (другие программы вызывают некоторые функции в динамической C-библиотеке для выяснения начального каталога вызывающего пользователя).
Следует отметить то, что некоторые или все данные системные переменные окружения могут не устанавливаться во время запуска программы, если программа запускается методом, отличным от создания подпроцесса в shell. В частности, демоны-слушатели какого-либо TCP/IP-сокета часто не имеют таких установленных переменных, а если имеют, то их значения едва ли будут полезны.
Наконец, следует отметить, что существует традиция (проиллюстрированная переменной
PATH) использования двоеточия в качестве разделителя, когда переменная окружения должна содержать несколько полей, особенно если данные поля можно интерпретировать как некоторые пути поиска. Заметим, что некоторые оболочки (особенно
bashи
ksh) всегда интерпретируют разделенные двоеточиями поля в переменной окружения как имена файлов. Это, в частности, означает, что символ
~в таких полях преобразовывается в путь к начальному каталогу данного пользователя.
10.4.2. Пользовательские переменные окружения
Несмотря на то, что приложения могут свободно интерпретировать переменные окружения за пределами определенного системой набора, в настоящее время фактическое использование такой возможности является довольно необычным. Значения переменных окружения в действительности непригодны для передачи структурированной информации в программу (хотя в принципе это реализуемо посредством синтаксического анализа значений). Вместо этого в современных Unix-приложениях используются конфигурационные файлы, а также файлы профилей.
Существует, однако, несколько конструкторских моделей, в которых могут оказаться полезными переменные окружения, определяемые пользователем.
Независимые от приложения настройки, которые должны совместно использоваться большим количеством различных программ. Данный набор "стандартных" настроек изменяется исключительно медленно, поскольку множеству программ требуется опознать каждую настройку до того, как она станет полезной[98]. Ниже приводятся стандартные переменные.
EDITOR
Имя предпочтительного для пользователя редактора (часто используется командами, создающими подоболочку)[99].
MAILER
Имя предпочтительного для пользователя почтового агента (часто используется командами, создающими подоболочку).
PAGER
Имя предпочитаемой пользователем программы для просмотра простого текста.
BROWSER
Имя предпочитаемой пользователем программы для просмотра информации в Web. Данная переменная до сих пор считается новой и еще широко не распространена.
10.4.3. Когда использовать переменные окружения
Общим для пользовательских и системных переменных окружения является то обстоятельство, что в них содержатся данные, хранение которых в большом количестве конфигурационных файлов было бы утомительным. И крайне утомительным было бы изменение данной информации во всех файлах конфигурации при изменении настроек. Обычно пользователи задают значения данных переменных в своих файлах начальной конфигурации shell-сеанса.
Значение отличается в нескольких совместно использующих файл профиля контекстах, или родительский процесс должен передать информацию множеству дочерних процессов. Ожидается, что некоторые блоки конфигурационной информации будут отличаться между несколькими контекстами, в которых вызывающий пользователь совместно использовал бы общие файлы конфигурации и файлы профиля. В качестве примера системного уровня можно рассмотреть несколько shell-сеансов, открытых через окна эмулятора терминала на рабочем столе системы X. Все они считывают одни и те же файлы профилей, но могут иметь различные значения переменных
COLUMNS,
LINESи
TERM. (Данный метод широко использовался в shell-программировании старой школы, а в make-файлах используется до сих пор.)
Значение изменяется слишком часто для файлов профилей, но не при каждом запуске. Определяемая пользователем переменная окружения может (например) использоваться для передачи расположения файловой системы или Internet-ресурса, являющегося корнем дерева файлов, с которыми должна работать программа. Так, например, система контроля версий CVS интерпретирует переменную
CVSROOT. Несколько клиентских программ чтения новостей, доставляющих новости от серверов с помощью протокола NNTP, интерпретируют переменную
NNTPSERVERкак расположение запрашиваемого сервера.
Уникальное для процесса переназначение параметров необходимо выразить таким образом, чтобы не требовалось изменять командную строку вызова. Определяемая пользователем переменная среды может быть полезна в ситуациях, когда, по какой-либо причине, может быть неудобно изменять файл профиля приложения или задавать параметры командной строки (возможно, ожидается, что приложение обычно будет использоваться внутри shell-упаковщика или make-файла). Особенно важным контекстом для такого использования является отладка. Например, в Linux использование переменной
LD_LIBRARY_PATH, связанной с компонующим загрузчиком ld(1), позволяет изменить место загрузки библиотек — возможно, для выбора версий, которые выполняют проверку переполнения буфера или профилирование (profiling).
Как правило, определяемая пользователем переменная среды может быть эффективным конструкторским выбором, когда значение изменяется настолько часто, что редактирование файла профиля становится неудобным, но не обязательно при каждом вызове (всегда устанавливать расположение с помощью параметра командной строки также было бы неудобно). Как правило, значения таких переменных следует определять после локального файла профиля и позволить им переназначать значения файла профиля.
В Unix существует одна традиционная конструкторская модель, которую не рекомендуется применять для новых программ. Иногда пользовательские переменные окружения используются как легковесная замена для выражения настроек программы в файле конфигурации. Например, старая игра nethack(1) для того, чтобы получить пользовательские настройки, считывала переменную окружения
NETHACKOPTIONS. Такой подход характерен для старой школы. Современная практика в аналогичном случае склонялась бы к синтаксическому анализу настроек из конфигурационного файла
.nethackили
.nethackrc.
Проблема более раннего стиля заключается в том, что отслеживание месторасположения информации о настройках становится сложнее, чем это было бы, если бы пользователь знал, что в его начальном каталоге находится конфигурационный файл программы. Переменные среды могут быть установлены в любом из нескольких конфигурационных файлов оболочки. В операционной системе Linux в их число, вероятнее всего, входят, как минимум, файлы
.profile,
.bash_profileи
.bashrc. Данные файлы запутаны и ненадежны, поэтому, как только издержки кода, содержащего синтаксический анализатор параметров, стали казаться менее значительными, возникла тенденция к перемещению информации о настройках из переменных окружения в файлы профилей.
10.4.4. Переносимость на другие операционные системы
Переменные среды характеризуются исключительно ограниченной переносимостью из Unix. В операционных системах Microsoft имеются переменные окружения, смоделированные наподобие переменных окружения в Unix, а переменная
PATHиспользуется, как и в Unix, для установки путей поиска исполняемых файлов, однако большинство других переменных, которые принимаются Unix-программистами как должное (такие как идентификатор процесса или текущий рабочий каталог) не поддерживаются. В других операционных системах (включая классическую MacOS), как правило, отсутствует какой-либо локальный эквивалент переменным окружения.
10.5. Параметры командной строки
Unix-традиции поощряют использование ключей командной строки для управления программами, так чтобы параметры можно было задавать из сценариев. Это особенно важно для программ, которые выполняют функции фильтров или каналов. Существует 3 соглашения, которые определяют способ отделения параметров командной строки от обычных аргументов: исходный стиль Unix, стиль GNU и стиль инструментария X.
В оригинальной традиции Unix для обозначения параметров командной строки служат отдельные буквы с предшествующим дефисом. Параметры режимов, которые не принимают последующих аргументов, можно группировать, поэтому если
-аи
-bявляются параметрами режима, то использование последовательностей
-abили
-baтакже является корректным и активизирует оба режима. Аргумент для параметра, если он существует, указывается после параметра (и отделяется от него пробелом), В данном стиле использование нижнего регистра для обозначения параметров более предпочтительно. Использование в разрабатываемой программе обозначений в верхнем регистре хорошо в том случае, если они представляют собой специальные варианты параметров, обозначаемых буквами нижнего регистра.
Исходный стиль Unix развивался на медленных телетайпах ASR-33, в которых краткость ввода была достоинством; отсюда и использование однобуквенных параметров. Удержание клавиши shift требовало определенных усилий, отсюда предпочтение для нижнего регистра и использование для активизации параметров символа "
-" (вместо знака "
+", возможно, более логичного в данном случае).
В GNU-стиле для обозначения параметров используются ключевые слова (вместо отдельных букв), которым предшествуют два дефиса. Данный стиль развивался гораздо позднее, когда некоторые из довольно сложных GNU-утилит начали сталкиваться с нехваткой однобуквенных ключей (это было "лечением симптома", но не избавляло от лежащей в основе проблемы). Данный стиль остается популярным, поскольку GNU-параметры читать проще, чем "алфавитную смесь" более ранних стилей. Параметры в GNU-стиле не могут быть сгруппированы без разделяющего пробела. Аргумент параметра (если есть) может отделяться либо пробелом, либо одиночным знаком равенства ("
=").
Двойной дефис в GNU-стиле был выбран для того, чтобы в одной командной строке можно было недвусмысленно смешивать традиционные однобуквенные параметры и ключевые слова GNU-стиля. Таким образом, если в первоначально разрабатываемой конструкции присутствует только несколько простых параметров, то можно использовать Unix-стиль, не опасаясь "дня флага", в случае если потребуется в дальнейшем перейти на GNU-стиль. С другой стороны, если используется GNU-стиль, то хорошей практикой будет поддержка однобуквенных эквивалентов, по крайней мере, для наиболее широко используемых параметров.
В стиле X-инструментария для обозначения параметра несколько запутанно используется одиночный дефис и ключевое слово. Данный стиль интерпретируется X-инструментариями, которые фильтруют и обрабатывают определенные параметры (такие как
-geometryи
-display) до передачи преобразованной командной строки логике приложения для интерпретации. Стиль X-инструментария не вполне совместим с классическим стилем Unix или GNU-стилем, и его не следует использовать в новых программах, если совместимость с более ранними X-соглашениями не очень важна.
Многие инструментальные средства принимают один дефис, не связанный с какой-либо буквой параметра, как имя псевдофайла, заставляющее приложение считывать данные со стандартного ввода. Кроме того, двойной дефис традиционно распознается как сигнал прекратить интерпретацию параметров и начать буквальную интерпретацию всех последующих аргументов.
Большинство языков программирования в Unix предоставляют библиотеки, которые производят синтаксический анализ командной строки либо в классическом, либо в GNU-стиле (также интерпретируя соглашение по двойному дефису).
10.5.1. Параметры командной строки от -а
до -z
Со временем часто используемые параметры в широко известных Unix-программах создали неформальный стандарт семантики для ожидаемого значения различных флагов. Ниже приводится перечень параметров и их значений, которые будут удобными и привычными для опытных пользователей операционной системы Unix.
-a
Все (без аргументов). В GNU-стиле параметр
-all. Было бы очень неожиданно встретить другое значение для
-а, кроме синонима
--all. Примеры: fuser(1), fetchmail(1).
Добавить в конец, как в утилите tar(1). Часто образовывает пару с ключом
-dдля удаления.
-b
Размер буфера или блока (с аргументом). Устанавливает размер буфера или размер блока (в программе, осуществляющей архивирование или управление устройствами хранения информации). Примеры: du(1), df(1), tar(1).
Неинтерактивный (пакетный (batch)) режим. Если программа изначально интерактивна, то ключ
-bможет использоваться для подавления подсказок или установки других параметров, необходимых для принятия входных данных из файла, а не от пользователя. Пример: flex(1).
-с
Команда (с аргументом). Если программа является интерпретатором, обычно принимающим команды со стандартного ввода, то ожидается, что аргумент
-cбудет передан программе как одна строка ввода. Данное соглашение особенно четко соблюдается в оболочках и shell-подобных интерпретаторах. Примеры: sh(1), ash(1), bsh(1), ksh(1), python(1). Сравните с ключом
-ениже.
Проверка (check) (без аргумента). Проверяется корректность аргумента (или аргументов) файла для команды, но обычная обработка фактически не выполняется. Часто используется как параметр проверки синтаксиса в программах, которые действительно интерпретируют командные файлы. Примеры: getty(1), perl(1).
-d
Отладка (debug) (с аргументом или без). Устанавливает уровень отладочных сообщений. Данное значение весьма распространено.
Иногда ключ
-dимеет значение "delete" (удалить) или "directory" (каталог).
Определить (define) (с аргументом). Устанавливает значение какого-либо символа в интерпретаторе, компиляторе или (особенно) в приложении с функциями макропроцессора. Моделью послужило использование ключа
-Dв препроцессоре макрокоманд компилятора С. Это устойчивая ассоциация для большинства Unix-программистов; ее не следует нарушать.
-e
Выполнить (execute) (с аргументом). Программы, которые являются упаковщиками или могут использоваться как упаковщики, часто допускают ключ
-едля определения программы, которой они передают управление.
Редактирование (edit). Программа, способная открыть ресурс либо в режиме только для чтения, либо в режиме редактирования, может принимать ключ
-едля активизации режима редактирования. Примеры: crontab(1) и утилита get(1) системы контроля версий SCCS.
Иногда ключ
-еимеет значение "exclude" (исключить) или "expression" (выражение).
-f
Файл (с аргументом). Очень часто используется с аргументом для указания файла входных (или реже выходных) данных для программ, которым требуется произвольный доступ к входным или выходным данным (там, где недостаточно перенаправления посредством символов < или >). Классическим примером является утилита tar(1); существует также множество других примеров. Кроме того, данный ключ часто используется для указания того, что аргумент, обычно принимаемый из командной строки, необходимо взять из файла. Классические примеры: awk(1) и egrep(1). Сравните с ключом
-ониже. Часто
-fпредставляет собой входной аналог
-о.
Форсировать (force) (обычно без аргумента). Форсирует некоторые операции (такие как блокировка или разблокировка файлов), которые обычно осуществляются по условию. Данное значение менее распространено.
Демоны часто используют ключ
-f, комбинируя оба значения, для того чтобы форсировать обработку конфигурационного файла, расположенного в нестандартном месте. Примеры: ssh(1), httpd(1) и многие другие демоны.
-h
Заголовки (headers) (обычно без аргумента). Включает, подавляет или модифицирует заголовки табличных отчетов, сгенерированных программой. Примеры: pr(1), ps(1).
Помощь (help). В настоящее время данное значение распространено меньше, чем можно ожидать. В большинстве случаев разработчики ранней Unix считали справку лишней тратой памяти, которую они не могли себе позволить. Вместо этого они создавали страницы руководства (что определенным способом сформировало соответствующий стиль справочных руководств в Unix, см. главу 18).
-i
Инициализировать (initialize) (обычно без аргумента). Устанавливает некоторый критический ресурс или базу данных, связанную с программой, в первоначальное или пустое состояние. Пример: ci(1) в RCS.
Диалоговый (интерактивный (interactive)) режим (обычно без аргумента). Заставляет программу (которая обычно этого не делает) запрашивать подтверждение выполняемых операций. Существуют классические примеры (rm(1), mv(1)), однако данное значение не является общепринятым.
Включить (include) (с аргументом). Добавляет имя файла или каталога в список просматриваемых приложением ресурсов. Все Unix-компиляторы с любым эквивалентом включения файла исходного кода в своих языках используют ключ
-Iименно в этом смысле. Было бы крайне неожиданно увидеть иное использование данного параметра.
-k
Хранить (keep) (с аргументом). Подавляет обычное удаление какого-либо файла, сообщения или ресурса. Примеры: passwd(1), bzip(1) и fetchmail(1).
Иногда ключ
-kимеет значение "kill" (уничтожить, завершить).
-l
Вывести список (list) (без аргумента). Если разрабатываемая программа является архиватором или интерпретатором/программой просмотра для какого- либо каталога или архива, то было бы очень неожиданно использовать ключ
-lдля действий, отличных от запроса списка объектов. Примеры: arc(1), binhex(1), unzip(1). (Утилиты tar(1) и cpio(1) являются исключениями.)
В программах, которые уже являются генераторами отчетов, ключ
-lпочти без исключений означает "long" (длинный) и отображает список в длинном формате, где открываются более подробные сведения по сравнению со стандартным режимом. Примеры: ls(1), ps(1).
Загрузить (load) (с аргументом). Если программа является компоновщиком или интерпретатором языка, то ключ
-lнеизменно загружает библиотеку в некотором соответствующем состоянии. Примеры: gcc(1), f77(1), emacs(1).
Регистрация в системе (login). В таких программах, как rlogin(1) и ssh(1), в которых необходимо указать сеть, это можно сделать с помощью ключа
-l.
Иногда
-lимеет значение "length" (длина, длительность) или "lock" (блокировка).
-m
Сообщение (message) (с аргументом). Ключ
-mпередает свой аргумент в программу как строку сообщения для протоколирования или извещения. Примеры: ci(1), cvs(1).
Иногда ключ
-mимеет значение "mail" (почта), "mode" (режим) или "modification-time" (время изменения).
-n
Число (number) (с аргументом). Используется, например, для указания диапазонов номеров страниц в таких программах, как head(1), tail(1), nroff(1) и troff(1). Некоторые сетевые инструменты, обычно отображающие DNS-имена, принимают ключ
-nкак параметр, который вызывает отображение IP-адресов вместо имен. Основные примеры: ifconfig(1) и tcpdump(1).
Нет (not) (без аргумента). Используется для подавления обычных действий в таких программах, как make(1).
-о
Вывод (output) (с аргументами). Используется для того, чтобы указать программе в командной строке выходной файл или устройство по имени. Примеры: as(1), cc(1), sort(1). Во всех программах с интерфейсами, подобными интерфейсу компилятора, было бы крайне неожиданно увидеть иное использование данного параметра. Программы, поддерживающие ключ
-oчасто (как gcc) имеют логику, которая позволяет опознавать его как после обычных аргументов, так и перед ними.
-p
Порт (port) (с аргументом). Главным образом применяется для параметров, которые определяют номера TCP/IP-портов. Примеры: cvs(1), инструменты PostgreSQL, smbclient(1), snmpd(1), ssh(1).
Протокол (protocol) (с аргументом). Примеры: fetchmail(1), snmpnetstat(1).
-q
Подавление вывода (quiet) (обычно без аргумента). Подавляет обычное отображение результата или сведений диагностики. Данное значение является весьма распространенным. Примеры: ci(1), со(1), make(1). См. также значение "подавление вывода" ключа
-s.
-r(а также
-R)
Рекурсия (recurse) (без аргумента). Если программа выполняет операции над каталогом, данный параметр может указывать на то, что операции рекурсивно повторяются для всех входящих в данный каталог подкаталогов. Любое другое применение данного ключа в утилите, обрабатывающей каталоги, было бы весьма неожиданным. Классическим примером, несомненно, является утилита cp(1).
Реверс (reverse) (без аргумента). Примеры: ls(1), sort(1). Данный параметр может использоваться в фильтре для реверсирования своего обычного действия преобразования (сравните с ключом
-d).
-s
Подавление вывода (silent) (без аргументов). Подавляет обычное отображение сведений диагностики или результатов (аналогичен ключу
-q; когда поддерживаются оба ключа, то
qозначает "quiet" (тихо), a
-s— "utterly silent" (очень тихо)). Примеры: csplit(1), ex(1), fetchmail(1).
Тема сообщения (subject) (с аргументом). Всегда используется в данном значении в командах, которые отправляют или манипулируют почтовыми сообщениями или новостями. Крайне важно обеспечить поддержку данного параметра, поскольку он ожидается программами, отправляющими почту. Примеры: mail(1), elm(1), mutt(1).
Иногда ключ
-s имеет значение "size" (размер).
-t
Тег (tag) (с аргументом). Назвать расположение или передать программе строку, используемую в качестве ключа поиска. Главным образом используется с текстовыми редакторами и программами просмотра. Примеры: cvs(1), ех(1), less(1), vi(1).
-u
Пользователь (user) (с аргументом). Указать пользователя по имени или числовому идентификатору (UID). Примеры: crontab(1), emacs(1), fetchmail(1), fuser(1), ps(1).
-v
Вывод подробных сведений (verbose) (с аргументом или без). Используется для включения мониторинга транзакций, более объемных списков или вывода отладочных сообщений. Примеры: cat(1), cp(1), flex(1), tar(1) и многие другие.
Версия (version) (без аргумента). Отображает версию программы на стандартном выводе и завершает свою работу. Примеры: cvs(1), chattr(1), patch(1), uucp(1). В более распространенном варианте данное действие вызывается ключом
-V.
Версия (version) (без аргумента). Отображает версию программы на стандартный вывод и завершает работу (кроме того, часто распечатывает на экране детали конфигурации, с которой была скомпилирована программа). Примеры: gcc(1), flex(1), hostname(1) и многие другие. Было бы крайне неожиданно, если бы данный ключ использовался иным способом.
-w
Ширина (width) (с аргументом). Главным образом используется для определения ширины в форматах вывода. Примеры: faces(1), grops(1), od(1), pr(1), shar(1).
Предупреждение (warning) (без аргументов). Включает диагностические предупреждения или подавляет их. Примеры: fetchmail(1), flex(1), nsgmls(1).
-x
Разрешить отладку (с аргументом или без). Данный ключ подобен
-d. Примеры: sh(1), uucp(1).
Извлечь (extract) (с аргументом). В качестве аргумента указываются файлы, которые необходимо извлечь из архива или рабочего комплекта. Примеры: tar(1), zip(1).
-y
Да (yes) (без аргументов). Санкционирует потенциально разрушительные действия, для которых программа обычно запрашивает подтверждение. Примеры: fsck(1), rz(1).
-z
Разрешает сжатие (без аргументов). Часто данный ключ используется в программах архивирования и резервного копирования. Примеры: bzip(1), GNU tar(1), zcat(1), zip(1), cvs(1).
Приведенные выше примеры взяты из инструментария Linux, но соответствуют большинству современных Unix-систем.
Выбирая буквы для параметров командной строки разрабатываемой программы, следует обратиться к справочным руководствам по подобным инструментам и попытаться использовать такие же буквы, какие используются в них для аналогичных функций разрабатываемой программы. Следует заметить, что некоторые отдельные прикладные области имеют особенно жесткие соглашения о ключах командной строки, нарушать которые опасно. Такие соглашения характерны для компиляторов, почтовых агентов, текстовых фильтров, сетевых утилит и программного обеспечения для X Window. Например, разработчик, который написал почтовый агент, использующий ключ
-sдля какой-либо другой функции вместо подстановки темы, услышит справедливую критику в свой адрес.
Стандарты программирования проекта GNU[100] рекомендуют традиционные значения для нескольких параметров с двойным дефисом. В проекте также перечислены длинные параметры, которые используются во многих GNU-программах, хотя они и не стандартизированы. Если программа разрабатывается с использованием GNU-стиля, и какой-либо необходимый параметр обладает функцией, подобной одному из перечисленных параметров, то следует всеми способами соблюсти правило наименьшей неожиданности и использовать имеющееся имя.
10.5.2. Переносимость на другие операционные системы
Для применения параметров командной строки необходимо ее присутствие в системе. В семействе MS-DOS командная строка, несомненно, присутствует, хотя в Windows она скрыта GUI-интерфейсом и используется слабо. Тот факт, что символом параметра обычно является "
/" вместо "
-" — только деталь. Классическая MacOS и другие исключительно GUI-среды не имеют близкого эквивалента параметров командной строки.
10.6. Выбор метода
Выше последовательно были рассмотрены системные и пользовательские файлы конфигурации, переменные окружения и аргументы командной строки — направление от конфигурации, которую изменить сложнее, к конфигурации, изменяемой проще. Имеется четкое соглашение о том, что удобные Unix-программы, использующие несколько мест хранения конфигурационных сведений, должны просматривать их в указанном порядке, позволяя более поздним установкам переназначать более ранние (существуют специфические исключения, такие как параметры командной строки, определяющие местонахождение файла профиля).
В частности, настройки окружения обычно имеют превосходство над установками файлов конфигурации, но могут быть переназначены параметрами командной строки. Хорошей практикой является предоставление параметра командной строки, подобного ключу
-eв утилите make(1), который может переназначить установки окружения или объявления в конфигурационных файлах. Данный способ позволяет включать программу в сценарии со строго определенным поведением независимо от вида файлов конфигурации или значений переменных окружения.
Выбор мест хранения настроек зависит от количества постоянных конфигурационных параметров, которые должны сохраняться между вызовами программы. Программы, разработанные преимущественно для использования в неинтерактивном режиме (как, например, генераторы или фильтры в конвейерах), обычно полностью конфигурируются с помощью параметров командной строки. В число хороших примеров данной модели включаются утилиты ls(1), grep(1) и sort(1). Другой крайний случай — крупные программы со сложным диалоговым поведением могут полностью зависеть от файлов конфигурации и переменных окружения, и в обычном использовании требуют только несколько параметров командной строки или не требуют их вообще. Большинство диспетчеров окон системы X представляют собой хорошие примеры такой модели.
(В операционной системе Unix файл может иметь несколько имен или "ссылок". Во время запуска каждая программа может определить имя, посредством которого она была вызвана. Другой способ указать программе, имеющей несколько режимов работы, в каком из них она должна запуститься, заключается в создании ссылки для каждого режима. Программа обнаруживает ссылку, через которую она была вызвана, и соответствующим образом изменяет режим работы. Однако данная техника обычно считается неаккуратной и используется нечасто.)
Ниже рассматриваются две программы, которые учитывают информацию, собранную из всех трех групп конфигурационных данных. Читателям будет полезно обдумать, почему для каждого блока конфигурационных данных информация накапливается именно таким способом.
10.6.1. Учебный пример: fetchmail
Программа fetchmail использует только две переменные среды —
USERи
НОМЕ. Данные переменные входят в состав предопределенного набора конфигурационных данных, инициализируемых системой, и используются многими программами.
Значение переменной
HOMEиспользуется для поиска файла профиля
.fetchmailrc, который содержит конфигурационную информацию, описанную с помощью довольно сложного синтаксиса, подчиняющегося shell-подобным лексическим правилам, описанным выше. В данном случае такой подход целесообразен, поскольку после первоначальной установки конфигурация fetchmail изменяется исключительно редко.
Не существует ни
/etc/fetchmailrc, ни какого-либо другого специфичного для fetchmail общесистемного файла. Обычно в таких файлах содержится конфигурация, которая не является специфичной для отдельного пользователя. В fetchmail действительно используется небольшая группа подобных свойств, в частности, имя локального почтмейстера (postmaster), несколько ключей и значений, описывающих настройку локального почтового транспорта (например, номер порта локального SMTP-слушателя). Однако на практике данные значения редко отклоняются от стандартных значений, настроенных на этапе компиляции. Если они изменяются, то это часто происходит определенным для пользователя способом. Поэтому в общесистемном конфигурационном файле fetchmail нет никакой необходимости.
Программа fetchmail может извлекать тройки узел/ имя/пароль из файла
.netrc. Таким образом, программа получает сведения аутентификации наименее неожиданным способом.
В fetchmail имеется развитый набор параметров командной строки, близко, но не полностью дублирующих установки, которые могут быть выражены в файле
.fetchmailrc. Данный набор первоначально не был большим, однако со временем он разрастался, по мере того как в мини-язык
.fetchmailrcдобавлялись новые конструкции, а также более или менее автоматически добавлялись параллельные параметры командной строки.
Цель поддержки всех данных параметров заключалась в том, чтобы сделать программу fetchmail более простой для включения в сценарии, позволяя пользователям переназначать с помощью командной строки настройки, определенные в файлах конфигурации. Но оказалось, что за исключением нескольких параметров, таких как
--fetchallи
-verbose, требуются очень не многие имеющиеся параметры. Кроме того, в ходе использования программы вообще не возникает потребностей, которые невозможно было бы удовлетворить с помощью сценария, создающего на лету временный конфигурационный файл и передающего его в fetchmail с помощью ключа
-f.
Таким образом, большинство параметров командной строки никогда не используются, и их включение, вероятно, было ошибкой. Они несколько загромождают код fetchmail, не давая какого-либо полезного эффекта.
Если бы загромождение кода было единственной проблемой, то никто, кроме нескольких кураторов, не беспокоился бы. Однако параметры увеличивают вероятность появления ошибок в коде, особенно ввиду непредвиденного взаимодействия между редко используемыми параметрами. Еще хуже то, что они значительно загромождают справочные руководства, которые обременяют всех.
(Дуг Макилрой)
Из всего вышесказанного можно извлечь следующий урок: если бы я достаточно тщательно продумал модель использования программы fetchmail и меньше придерживался специализированного подхода в добавлении функций, то дополнительной сложности можно было бы избежать.
Альтернативный способ исправления подобных ситуаций, который не загромождает ни код, ни руководство, заключается в использовании ключа "установить переменную параметра", такого как ключ
-Ов sendmail, позволяющий указать имя и значение параметра и устанавливающий значение данного параметра так, как если бы оно было задано в конфигурационном файле. Более мощный вариант данной функции имеется в программе ssh с (ключ-о): аргумент ключа-оинтерпретируется так, как будто он представляет собой строку, добавленную в конец конфигурационного файла. При создании аргумента можно использовать весь доступный конфигурационный синтаксис. Любой из таких подходов предоставляет пользователям с необычными требованиями способ переназначать конфигурацию из командной строки, не требуя при этом от разработчика создания отдельного параметра для каждого конфигурационного значения. (Генри Спенсер.)
10.6.2. Учебный пример: сервер XFree86
Система оконного интерфейса X представляет собой ядро, поддерживающее растровые дисплеи на Unix-машинах. Unix-приложения, запущенные на клиентской машине с растровым дисплеем, получают входные события посредством системы X и отправляют ей запросы на создание экранных изображений. Многих ставит в тупик то, что "серверы" X фактически запускаются на клиентской машине — они существуют для обслуживания запросов на взаимодействие с дисплеем клиентской машины. Приложения, отправляющие такие запросы X-серверу, называются "X-клиентами", несмотря на то, что они могут быть запущены на серверной машине. Невозможно без путаницы объяснить эту "перевернутую" терминологию.
X-серверы имеют неприступно сложный интерфейс к своему окружению. Это не удивительно, поскольку им приходится взаимодействовать с широким диапазоном сложного аппаратного обеспечения и пользовательских настроек. Запросы окружения являются общими для всех X-серверов, документированными в справочных руководствах Х(1) и Xserver(1), а значит, представляют собой полезный пример для изучения. Ниже рассматривается XFree86, реализация системы X, применяемая в операционной системе Linux и других Unix-системах с открытым исходным кодом.
Во время запуска сервер XFree86 изучает общесистемный конфигурационный файл. Точный путь к данному файлу варьируется в различных сборках X на разных платформах, но базовое имя постоянно — XF86Config. Данный файл имеет shell-подобный синтаксис, как было описано выше. Ниже приводится пример одного из разделов файла XF86Config.
Пример 10.2. Конфигурация X# VGA-сервер 16 цветов
Section "Screen"
Driver "vga16"
Device "Generic VGA"
Monitor "LCD Panel 1024x768"
Subsection "Display"
Modes "640x480" "800x600"
Viewport 0 0
EndSubsection
EndSection
В файле XF86Config описывается аппаратное обеспечение машины (графическая плата, монитор), клавиатура и указательное устройство (мышь/трекбол/сенсорная панель). Хранение данных сведений в общесистемном конфигурационном файле целесообразно, поскольку они касаются всех пользователей машины.
Как только X-сервер получил конфигурацию аппаратного обеспечения из конфигурационного файла, он использует значение переменной окружения HOME для обнаружения двух файлов профиля, расположенных в начальном каталоге вызывающего пользователя,
.Xdefaultsи
.xinitrc[101].
В файле
.Xdefaultsуказываются специализированные ресурсы данного пользователя, относящиеся к системе X (в число простейших примеров можно включить шрифт и цвета фона и переднего плана для эмулятора терминала). Однако выражение "относящиеся к системе X" указывает на проблему проектирования. Группировать описания всех данных ресурсов в одном месте удобно для проверки и редактирования, но не всегда ясно, какие ресурсы следует объявлять в файле
.Xdefaults, и какие параметры необходимо хранить в файле профиля приложения. В файле
.xinitrcопределяются команды, которые должны быть выполнены для инициализации пользовательского рабочего стола в X сразу после запуска сервера. В число данных программ почти всегда включается диспетчер окон или диспетчер сеанса.
X-серверы имеют большой набор параметров командной строки. Некоторые из них, такие как
-fp(font path — путь к шрифтам), имеют преимущество перед параметрами файла XF86Config. Некоторые, например,
-audit, предназначены для того, чтобы облегчить отслеживание ошибок сервера. Если данные параметры вообще используются, то, скорее всего, очень часто изменяются между тестовыми запусками, а следовательно, являются маловероятными кандидатами на включение в конфигурационный файл. Очень важным является параметр, устанавливающий номер дисплея сервера. На узле могут быть запущены несколько серверов, если каждому из них предоставляется уникальный номер дисплея, но все экземпляры совместно используют один и тот же конфигурационный файл (или файлы), поэтому номер дисплея невозможно получить исключительно из данных файлов.
10.7. Нарушение правил
Описанные в данной главе соглашения не абсолютны, но их нарушение в будущем усугубить разногласия между пользователями и разработчиками. В случае крайней необходимости их можно нарушить, однако, прежде чем это сделать, необходимо точно знать, для чего это необходимо. Разработчику, нарушающему данные соглашения, следует убедиться, что решение задач традиционными способами невозможно и что он имеет полное представление об ошибках в соответствии с правилом исправности.
11
Интерфейсы: модели проектирования пользовательских интерфейсов в среде Unix
Начало всех наших знаний в наших ощущениях.
(—Леонардо да Винчи)
Интерфейсом программы является совокупность всех способов, посредством которых программа обменивается данными с пользователями и другими программами. В главе 10 рассматривалось применение переменных окружения, ключей, файлов конфигурации и других элементов интерфейсов запуска. В данной главе эта тема развивается далее и поясняется работа Unix-интерфейсов после запуска. Поскольку создание кода пользовательского интерфейса обычно занимает не менее 40% времени разработки, знание хороших конструкторских моделей в этой области особенно важно, так как позволяет избежать многих неудачных попыток и переделок.
Для Unix-традиции проектирования интерфейсов всегда были характерны две идеи. Одна из них состоит в заблаговременном проектировании обмена данными с другими программами, а другая — это правило наименьшей неожиданности.
Использование синергетических комбинаций Unix-программ может предоставить дополнительный выигрыш. Различные методы создания таких комбинаций рассматривались в главе 7. "Другие программы" в проектировании интерфейсов в Unix — не запоздалое дополнение и не предельный случай, как во многих других операционных системах. Данная часть проектирования интерфейсов скорее является центральной проблемой, которую необходимо сбалансировать и взвешенно интегрировать с пользовательскими требованиями к конструкции интерфейсов.
Многое в традиции Unix-сообщества, касающейся проектирования интерфейсов программ, при первом рассмотрении может показаться чуждым и бессистемным или даже (в контексте эпохи GUI-интерфейсов) полностью регрессивным. Однако несмотря на различные недостатки и неупорядоченность, данная традиция обладает внутренней логикой, которая достойна изучения и понимания. Она отражает эмпирические правила, накопленные за годы долгой истории Unix, касающиеся способов обеспечения эффективного взаимодействия, как с пользователями, так и с другими программами. Традиция включает в себя множество соглашений, которые позволяют унифицировать программы — она определяет "наименее неожиданные" альтернативы для широкого диапазона общих проблем проектирования интерфейсов.
После запуска программа обычно получает входные данные или команды из следующих источников:
• данные и команды, представленные на стандартном вводе программы;
• входные данные, переданные посредством IPC-методов, такие как события X-сервера и сетевые сообщения;
• файлы и устройства с известным расположением (например, имя файла данных, переданное или вычисленное программой).
Теми же путями программы могут отправлять данные (вывод направляется на стандартный вывод).
Некоторые Unix-программы являются графическими, некоторые имеют символьные экранные интерфейсы, а в некоторых используется простейшая конструкция текстового фильтра, которая не изменилась со времен механических телетайпов. Непосвященным далеко не очевидно, почему в какой-либо программе используется тот или иной стиль, или, вернее, почему в Unix вообще поддерживается такое многообразие стилей интерфейса.
В Unix существует несколько конкурирующих стилей интерфейса. Все они до сих пор существуют по определенным причинам. Они оптимизированы для использования в различных ситуациях. Поняв соответствие между задачей и стилем интерфейса, можно научиться выбирать наиболее подходящий стиль для выполнения необходимой работы.
11.1. Применение правила наименьшей неожиданности
Правило наименьшей неожиданности представляет собой общий принцип проектирования всех видов интерфейсов, а не только программных: "делайте наименее неожиданные вещи". Данное правило — следствие того факта, что человек способен уделять внимание одновременно только одному объекту (см. книгу "The Humane Interface" [64]). Неожиданности в интерфейсе притягивают внимание к самому интерфейсу, а не к задаче, для решения которой он предназначен.
Таким образом, наилучший способ разработки удобных интерфейсов заключается в том, чтобы по возможности никогда не разрабатывать полностью новую модель интерфейса. Нововведения — входные препятствия для пользователя. Они повышают нагрузку на пользователя, поскольку требуют изучения, поэтому их количество должно быть минимальным. Вместо этого, следует взвешенно оценить опыт и знания пользовательского контингента и попытаться найти функциональное сходство между разрабатываемой программой и программами, которые пользователи, вероятнее всего, уже изучили, а затем сымитировать соответствующие части существующих интерфейсов.
Правило наименьшей неожиданности не следует трактовать как призыв к механическому консерватизму в проектировании. Нововведения повышают издержки нескольких первых попыток взаимодействия пользователя с интерфейсом, но неразвитая конструкция навсегда сделает интерфейс излишне трудным. Как и в других видах проектирования, правила не заменят хорошего вкуса и инженерного подхода. Необходимо тщательно взвешивать компромиссы и рассматривать их с точки зрения пользователя. Осознанный уклон в сторону правила наименьшей неожиданности — хорошая практика, и главным образом потому, что разработчики интерфейсов (как и другие программисты) имеют несознательную тенденцию быть "излишне умными" для блага пользователя.
Одно из следствий правила наименьшей неожиданности: при любой возможности позволять пользователю делегировать функции интерфейса хорошо знакомой программе. В главе 7 уже отмечалось, что если разрабатываемая программа требует от пользователя редактирования значительного количества текста, то ее следует писать так, чтобы она вызывала редактор (указанный пользователем), а не создавать собственный интегрированный редактор. Такой подход дает возможность пользователям, которым их предпочтения известны лучше, чем разработчикам, выбрать наименее неожиданную альтернативу.
В данной книге уже пропагандировался симбиоз и делегирование как тактики, стимулирующие повторное использование кода и сокращение сложности. Суть данных методик заключается в том, что если пользователи могут перехватить делегирование и направить его избранному агенту, то это не просто экономически выгодно для разработчика, но и активно расширяет возможности пользователей.
В случае, когда делегирование невозможно, следует воспроизводить удачные решения. Целью правила наименьшей неожиданности является сокращение общей сложности, которую необходимо постичь пользователю, для того чтобы использовать интерфейс. Относительно примера с текстовым редактором, это означает, что если реализовать встроенный редактор действительно необходимо, то будет лучше, если команды этого редактора будут представлять собой подмножество команд широко известного универсального редактора (или нескольких редакторов; в оболочках
bashи
kshимеются CLI-редакторы, которые позволяют пользователям выбирать стиль редактирования vi или Emacs.)
Например, в Unix-версиях Web-браузеров Netscape и Mozilla текстовые поля форм распознают подмножество стандартных клавиатурных комбинаций для редактора Emacs. Control-A переводит курсор в начало строки, Control-D удаляет следующий символ и так далее. Такой вариант помогает пользователям, знакомым с Emacs, а остальным позволяет использовать не худший, уникальный набор команд. Единственным способом улучшить его был выбор клавиатурных комбинаций, связанных с каким-либо редактором, получившим более широкое распространение, чем Emacs. Но среди первых пользователей Netscape такой редактор не использовался.
Данные принципы применимы во многих других областях проектирования интерфейсов. Они, в частности, означают, что было бы крайне недальновидно создавать для интерактивной справочной системы нестандартные форматы документов, тогда как пользователям удобно использовать Web-браузер, распознающий HTML. Даже при разработке аркадной игры целесообразно рассмотреть интерфейсы предыдущих игр, для того чтобы понять, можно ли обеспечить новым пользователям чувство комфорта, позволяя им перенести накопленные в других играх навыки управления.
11.2. История проектирования интерфейсов в Unix
Операционная система Unix предшествует современному стилю проектирования программных интерфейсов с интенсивным применением графики. Более 10 лет после появления первой Unix-системы в 1969 году на телетайпах и "немых" текстовых терминалах нормой был интерфейс командной строки (Command-Line Interface — CLI). Большая часть базового инструментария Unix (такие программы как ls(1), cat(1) и grep(1)) до сих пор отражает это наследие.
После 1980 года в Unix постепенно развивалась поддержка прорисовки экранов на символьных терминалах. В программах начали смешивать интерфейс командной строки с визуальным интерфейсом. Часто общим командам присваивались клавиатурные комбинации, которые не отражались на экране. Некоторые ранние программы, написанные в этом стиле (они часто называются curses-программами по названию библиотеки управления курсором для прорисовки экрана, которая обычно применялась в их реализации, или rogue-подобными по названию первого приложения, использовавшего библиотеку curses), используются до сих пор. В число известнейших примеров входят ролевая игра rogue(1), текстовый редактор vi(1), а также почтовая программа elm(1) (вышедшая несколькими годами позднее) и ее современный потомок mutt(1).
Через несколько лет, в середине 80-х годов прошлого века, весь компьютерный мир начал усваивать результаты передовых разработок графических пользовательских интерфейсов (Graphical User Interface — GUI), которые с начала 70-х годов продолжались в исследовательском центре компании Xerox Palo Alto Research Center (PARC). В области персональных компьютеров работа Xerox PARC вдохновила создание интерфейса Apple Macintosh, а через него и дизайна Microsoft Windows. Адаптация данных идей в операционной системе Unix пошла значительно более сложным путем.
Приблизительно в 1987 году система X Window обошла несколько более ранних конкурирующих и опытных проектов и стала стандартным средством графического интерфейса для операционной системы Unix. Споры о том, хорошо это было или плохо, продолжаются до сих пор. Возможно, некоторые из конкурентов X Window (особенно Network Window System или NeWS разработки Sun) были гораздо более мощными и изящными. Система X, однако, имела одно неоспоримое преимущество — открытый исходный код. Ее код разрабатывался в Массачусетском технологическом университете исследовательской группой, более заинтересованной изучением проблемной области, а не созданием продукта, и остался свободно распространяемым и модифицируемым. В силу данных причин код X оказался способным
привлечь поддержку со стороны широкого круга разработчиков и спонсирующих корпораций, которые не хотели оставаться позади закрытого продукта одного поставщика. (Это, несомненно, послужило прообразом важной идеи в прорыве операционной системы Linux десятью годами позже.)
Разработчики X в самом начале решили, что система будет поддерживать "механизм, а не политику". Их целью было сделать систему X настолько гибкой и переносимой между платформами, насколько это возможно, одновременно внося как можно меньше ограничений на вид и восприятие X-программ. Было решено, что вид и восприятие интерфейса будут поддерживаться "инструментариями" — библиотеками, вызывающими X-службы, которые связаны с пользовательскими программами. Система X должна была быть спроектирована для поддержки множества диспетчеров окон[102] и не требовала бы от диспетчера окон наличия каких-либо особых привилегий или уникально тесной интеграции с механизмом системы X.
Данный подход был диаметрально противоположным принятому в коммерческих продуктах Macintosh и Windows, которые навязывали определенный вид и восприятие интерфейса, непосредственно встраивая его в систему. Различие в подходах обеспечило системе X долгосрочные эволюционные преимущества — она оставалась легко адаптируемой по мере открытия новых нюансов человеческого фактора в конструкции интерфейсов. Однако различие подходов также обеспечило последующее разделение мира X вследствие разнообразия инструментариев оконных менеджеров, а также из-за многих экспериментов с внешним видом и восприятием интерфейса.
С середины 90-х годов прошлого века система X стала использоваться повсеместно даже на низкопроизводительных персональных Unix-машинах. Использование операционной системы Unix с текстовых терминалов, в противоположность графическим компьютерным консолям, резко пошло на спад и, вероятно, достигло своего заката. Соответственно, использование псевдографических интерфейсов для новых приложений также пошло на убыль. Большинство новых приложений, которые прежде разрабатывались бы в данном стиле, в настоящее время используют X-инструментарий. Полезно отметить, что более старая традиция Unix, традиция использования CLI-дизайна, до сих пор весьма сильна и во многих областях и успешно конкурирует с X.
Также полезно отметить факт существования нескольких специфических прикладных областей, в которых псевдографические интерфейсы curses- или rogue-подобного стиля остаются нормой — особенно текстовые редакторы и интерактивные коммуникационные программы, такие как почтовые агенты, программы чтения новостей и chat-клиенты.
Таким образом, по историческим причинам в Unix-программах имеется широкий диапазон стилей интерфейсов. Строчные, псевдографические экранные и интерфейсы на основе системы X. Мир X-интерфейсов отчасти разделен конкуренцией между различными видами X-инструментария и диспетчерами окон (хотя в настоящее время данная проблема стоит уже не так остро, как несколько лет назад).
11.3. Оценка конструкций интерфейсов
Все данные стили интерфейсов продолжают существовать до сих пор благодаря тому, что они адаптированы для различных задач. Принимая решение о конструкции проекта, важно знать, как подбирать (или комбинировать) приемлемые стили для данного приложения и его пользователей.
Ниже для разделения стилей интерфейсов на категории используются пять базовых показателей: лаконичность, выразительность, простота, прозрачность и возможность использования в сценариях. Некоторые из данных понятий уже упоминались ранее в данной книге, здесь даны их определения. Данные показатели являются сравнительными, а не абсолютными, и оценивать их необходимо в контексте определенной проблемной области, имея некоторые сведения об уровне навыков пользователей. Тем не менее, данные показатели способствуют в формировании конструктивного мышления.
Интерфейс программы является "лаконичным", если максимальная длительность и сложность действий, которые необходимо выполнить для совершения транзакции с данным интерфейсом, не высоки (мерой может послужить количество нажатий клавиш, жестов или секунд необходимого внимания). В лаконичных интерфейсах множество усилий упаковано в относительно небольшом числе изменений состояния.
Интерфейсы являются "выразительными", когда их можно без трудностей использовать для управления целым рядом действий. Наиболее выразительные интерфейсы могут управлять комбинациями действий, которые не предусмотрены разработчиком программы, но, тем не менее, предоставляют пользователю полезные и последовательные результаты.
Различие между лаконичностью и выразительностью представляется весьма важным. Рассмотрим два различных способа ввода текста: с клавиатуры или путем выбора с помощью мыши символов на экране дисплея. Оба способа имеют равную выразительность, однако клавиатура предоставляет более лаконичный способ (это можно легко проверить, сравнив средние значения скорости ввода текста). С другой стороны, рассмотрим два диалекта одного языка программирования, один с типом комплексных чисел, а другой без него. Внутри общей проблемной области их лаконичность идентична, но для математиков или инженеров электротехников диалект с комплексными числами будет более выразительным.
"Простота" интерфейса обратно пропорциональна мнемонической нагрузке на пользователя — количество элементов (команд, жестов, основных понятий), которые должен запомнить пользователь специально для работы с данным интерфейсом. Программные языки характеризуются высокой мнемонической нагрузкой и низкой простотой, меню и экранные кнопки с понятными надписями более просты.
Идее прозрачности ранее была отведена целая глава, в которой она рассматривалась через призму прозрачности интерфейса, и как замечательный пример прозрачности описывался редактор аудиофайлов audacity. Однако тогда больше внимания было уделено прозрачности другого вида, относящейся скорее к структуре кода, а не к структуре пользовательского интерфейса. Таким образом, прозрачность пользовательского интерфейса описывалась скорее в аспекте его эффективности (ничто не вторгается между пользователем и проблемной областью), чем в специфических особенностях создающей его конструкции. В данной главе основное внимание уделяется именно специфическим особенностям.
Понятие прозрачности интерфейса — определяется тем, как мало сведений об условиях проблемы, данных или программы необходимо помнить пользователю во время использования интерфейса. Интерфейс обладает высокой прозрачностью, когда он естественно представляет промежуточные результаты, полезную обратную связь и уведомления об ошибках в результате действий пользователя. Так называемые интерфейсы WYSIWYG (What You See Is What You Get — что видишь, то получаешь) предназначены для создания максимальной прозрачности, однако иногда наблюдается обратный эффект, в частности создание чрезмерно упрощенного вида проблемной области.
К конструированию интерфейсов также применимо родственное понятие воспринимаемости. Воспринимаемый интерфейс предоставляет пользователю помощь в его изучении, например, приветственное сообщение, указывающее на контекстную справку, или всплывающие надписи с содержательными пояснениями. Несмотря на то, что воспринимаемость должна реализовываться довольно разными способами для каждого стиля интерфейса, которые будут рассматриваться далее, степень ее досягаемости почти совсем не зависит от стиля интерфейса. Поэтому как показатель, воспринимаемость в данном обсуждении не используется.
Необходимо отметить, что прозрачность кода и конструкции автоматически не означает прозрачность интерфейса и наоборот. Достаточно просто найти код, который имеет одно качество, но не имеет другого.
"Возможность использования интерфейса в сценариях" — легкость, с которой другие программы могут манипулировать данным интерфейсом (например, посредством IPC-механизмов, рассмотренных в главе 7). Программы, имеющие такую возможность, могут легко использоваться другими программами как компоненты, что сокращает необходимость дорогостоящего специального программирования и относительно упрощает автоматизацию повторяющихся задач.
Последний момент — автоматизация повторяющихся задач — заслуживает большего внимания, чем ему обычно уделяется. У Unix-программистов, администраторов и пользователей развивается привычка продумывать используемые рутинные процедуры, а затем организовывать их так, что им более не приходится выполнять данные действия вручную или даже думать о них. Такая привычка зависит от интерфейсов, которые можно использовать в сценариях. Этот незаметный, но чрезвычайно мощный усилитель продуктивности не доступен в большинстве других программных сред.
Полезно учитывать то, что работа компьютерных программ и работа пользователей зависит от описываемых показателей абсолютно по-разному. То же можно сказать о новичках и опытных пользователях в отдельной проблемной области. Ниже рассматривается, как изменяются компромиссы между этими показателями для различных контингентов пользователей.
11.4. Компромиссы между CLI- и визуальными интерфейсами
После ухода телетайпов CLI-стиль ранней Unix в течение долгого времени остается полезным по двум причинам. Первая заключается в том, что интерфейсы командной строки и командных языков являются более выразительными, чем визуальные, особенно для сложных задач. Другая причина состоит в том, что CLI-интерфейсы очень хорошо используются в сценариях — они легко поддерживают комбинирование программ, как подробно разъяснялось в главе 7. Обычно (хотя и не всегда) CLI-интерфейсы также более лаконичны.
Недостатком CLI-стиля, несомненно, является то, что он почти всегда представляет высокую мнемоническую нагрузку (низкую простоту) и обычно имеет слабую прозрачность. Большинство пользователей (особенно нетехнические конечные пользователи) находят такие интерфейсы довольно непонятными и сложными в изучении.
С другой стороны, "дружественные" GUI-интерфейсы других операционных систем имеют свои собственные проблемы. Поиски необходимых кнопок подобны игре в "Adventure": интерфейсы в этих системах настолько же трудны, насколько любой интерфейс командной строки в Unix, за исключением того, что пользователь теоретически может "найти сокровища" после достаточного исследования. В Unix пользователю необходимо руководство.
(Брайан Керниган.)
Запросы к базам данных представляют собой хороший пример интерфейса, для которого нажатие клавиш является не просто обременительным, а крайне ограничивающим. Ни клавиатурные комбинации в полноэкранном символьном интерфейсе, ни GUI-жесты на графическом дисплее не способны выразить обычные действия в данной предметной области так же выразительно или лаконично, как передача SQL-запроса непосредственно серверу. И, безусловно, проще заставить клиентскую программу генерировать SQL-запросы, чем заставить ту же программу имитировать действия пользователя в GUI-интерфейсе.
С другой стороны, многие нетехнические пользователи баз данных настолько не приемлют необходимость запоминания SQL-синтаксиса, что предпочитают менее лаконичный и менее выразительный полноэкранный или GUI-интерфейс.
SQL является хорошим примером, иллюстрирующим другой момент. Большинство мощных CLI-интерфейсов представляют собой не уникальные наборы команд, а императивные мини-языки, разработанные согласно описанным в главе 8 принципам. Данные мини-языки находятся на самой мощной и самой сложной границе спектра CLI-интерфейсов. Они достигают максимальной выразительности, но сводят к минимуму простоту. Их трудно использовать, и обычно необходимо осмотрительно скрывать их от обычных конечных пользователей, однако они представляют собой идеальное решение там, где мощность и гибкость интерфейса является наиболее важной. Если они разработаны соответствующим образом, то их также намного проще использовать в сценариях.
Некоторые приложения, в отличие от запросов к базам данных, являются естественно визуальными. К ним относятся программы для рисования, Web-браузеры и презентационное программное обеспечение. Данные прикладные области имеют два общих аспекта — (а) прозрачность в них крайне важна и (b) простейшие действия в предметной области сами по себе являются визуальными: "нарисовать", "показать выбранный объект", "переместить объект".
Оборотной стороной программ для рисования является то, что в них трудно фиксировать связи внутри изображений, которыми они манипулируют. Требуется тщательное, продуманное проектирование, для того чтобы, например, предоставить пользователю какой-либо указатель на структуру изображений с повторяющимися элементами. Это является общей проблемой проектирования визуальных интерфейсов.
В главе 6 рассматривался редактор звуковых файлов Audacity. Конструкция его интерфейса имеет успех, поскольку она выполняет определенно четкую задачу преобразования предметной области, т.е. звука в простой набор визуальных представлений (заимствованных с индикаторов эквалайзеров на стереосистемах). Это достигается полным воспроизведением результатов преобразования звуков в изображения колебаний. Визуальные операции не просто подогнаны под трансформацию звука. Все они связаны с данным преобразованием.
Однако в приложениях, которые не являются естественно визуальными, визуальные интерфейсы наиболее целесообразны для простых единичных или нечастых заданий, выполняемых начинающими пользователями (что иллюстрируется примером баз данных).
Сопротивление CLI-интерфейсам часто уменьшается по мере того, как пользователи становятся более опытными. Во многих предметных областях пользователи (особенно те, которые используют программы регулярно) достигают того момента, когда лаконичность и выразительность CLI становится более ценной, чем избежание мнемонической нагрузки. Поэтому, например, начинающие пользователи компьютеров предпочитают рабочие столы GUI, а опытные пользователи часто постепенно обнаруживают, что они предпочитают ввод команд в оболочке.
CLI-интерфейсы также часто становятся полезными, по мере того как проблемы расширяются и вовлекают больше заранее подготовленных, процедурных и повторяющихся действий. Поэтому, например, настольная издательская программа WYSIWYG-типа обычно предоставляет простейший способ создания сравнительно небольших и неструктурированных документов, таких как деловые письма. Однако для сложных документов, сравнимых по размеру с книгами, которые составляются из разделов и во время компоновки могут потребовать множество глобальных изменений формата или структурных манипуляций, такой форматер, как troff, Тех или какой-либо процессор XML-разметки, является обычно более эффективным вариантом (более подробное обсуждение данного компромисса приведено в главе 18).
Даже в тех сферах, которые являются естественно визуальными, расширение проблемы часто склоняет выбор компромиссного решения в пользу CLI-интерфейса. Если требуется загрузить и сохранить одну Web-страницу с заданного URL, то выбор и щелчок мыши (или ввод и щелчок) будет превосходным способом. Однако для Web-форм потребуется использование клавиатуры. И если необходимо загрузить и сохранить страницы, соответствующие заданному списку из 50 URL-адресов, то CLI-клиент, способный считывать URL со стандартного ввода или из командной строки, позволит сократить количество излишних движений.
В качестве другого примера рассмотрим изменение таблицы цветов в графическом изображении. Если требуется изменить один цвет (например, осветлить его на величину, которую можно определить только посмотрев на изображение), то визуальное диалоговое окно со средствами подбора цветов является почти обязательным. Однако предположим, что необходимо заменить всю таблицу набором указанных RGB-значений или создать и проиндексировать большое количество пиктограмм. Это те операции, в которых GUI-интерфейсам обычно не хватает выразительности. Даже если такая выразительность достигнута, вызов соответствующим образом разработанного CLI-интерфейса или программы фильтра позволит выполнить задачу гораздо более лаконичным способом.
Наконец, (как отмечалось выше) CLI-интерфейсы являются важным средством, облегчающим использование одних программ из других. Графический редактор с GUI-интерфейсом, который способен создавать пакеты пиктограмм для списка файлов, вероятно, выполнит данную задачу с помощью дополнительного приложения, написанного на языке сценариев, вызывающего внутренний CLI-интерфейс графического редактора (как, например, средство script-fu для GIMP). Unix-среды настолько повышают ценность CLI-интерфейсов именно потому, что их IPC-средства хорошо развиты, имеют низкие издержки и легкодоступны из пользовательских программ.
Рост популярности GUI-интерфейсов (начиная с 1984 года) имел неудачное последствие: они затмили достоинства CLI-интерфейсов. Конструкция потребительского программного обеспечения, в частности, стала в большой степени склоняться к GUI-интерфейсам. Несмотря на то, что это удобно для начинающих и случайных пользователей, которые составляют большую часть потребительского рынка, это также несет в себе скрытые затраты для более опытных пользователей, по мере того как они сталкиваются с ограничениями выразительности GUI-интерфейсов. Такие затраты неуклонно увеличиваются по мере того, как пользователи принимаются за решение более сложных проблем. Большая часть затрат связана с тем, что GUI-интерфейсы просто вообще не могут использоваться в сценариях — каждая операция взаимодействия с ними должна инициироваться пользователем.
Гентнер и Нильсен ярко обобщили данный компромисс в статье "The Anti-Mac Interface" [28]: "[Визуальные интерфейсы] хорошо подходят для простых действий с небольшим количеством объектов, но по мере того как количество действий или объектов растет, непосредственное управление быстро становится повторяющейся, монотонной работой. Темная сторона интерфейса непосредственного управления заключается в том, что пользователю приходится управлять всем. Вместо руководителя, раздающего высокоуровневые инструкции, пользователь понижается до рабочего конвейера, который должен выполнять одно и то же задание снова и снова". Знаменитый писатель-фантаст Нил Стефенсон (Neal Stephenson) выразил то же мнение не так явно, но более увлекательно в своем ярком и обобщенном очерке "In the Beginning Was the Command Line" [79].
Подход к данной проблеме типичных представителей старой Unix-школы является значительно менее теоретическим.
Коммерческий мир, как правило, стремится к моде новичков, потому что (а) решения о покупках часто принимаются на основе тридцатисекундного пробного использования и (b) необходимость поддержки пользователей при этом сводится к минимуму, поскольку им предоставляется упрощенный до абсурда GUI-интерфейс. Я нахожу многие не-Unix-системы очень неудобными, поскольку, например, они не предоставляют способа выполнять какие-либо действия с сотней или тысячей файлов; я хочу написать сценарий, но он не поддерживается. Основная проблема таких систем заключается в предположении, что все пользователи постоянно остаются начинающими, и, следовательно, они отвергают Unix, поскольку она в данную модель не вписывается.
(Майк Леск.)
Для того чтобы обеспечить программе долгую жизнь, чтобы программа могла обслуживать как начинающих, так и опытных пользователей, взаимодействовать с другими компьютерными программами, и независимо от того, является ли предметная область естественно визуальной, важна поддержка обоих видов интерфейсов как CLI-, так и визуальных. История Unix свидетельствует о том, что данная система хорошо подходит для удовлетворения обеих групп потребностей. После представления показательного учебного примера далее в настоящей главе рассматриваются характерные модели проектирования, которые развились в Unix для удовлетворения данных потребностей.
11.4.1. Учебный пример: два способа написания программы калькулятора
Для того чтобы более конкретно изучить преимущества и недостатки GUI- и CLI-интерфейсов, рассмотрим, как данные стили можно полезно применить в конструкции простой интерактивной программы: настольного калькулятора. В качестве примеров для контраста используются утилиты dc(1)/bc(1) и xcalc(1).
Первоначально программой настольного калькулятора в Unix, впервые распространявшегося с Version 7, была утилита dc(1) — калькулятор с обратной польской нотацией, который мог выполнять арифметические вычисления с неограниченной точностью. Позднее над утилитой dc(1) был реализован язык алгебраического (с инфиксной нотацией) калькулятора, bc(1) (взаимосвязь данных программ рассматривалась в качестве учебного примера в главе 7, а затем в главе 8). В обеих программах используется CLI-интерфейс. Пользователь вводит выражение на стандартный ввод и нажимает клавишу Enter, после чего значение выражения печатается на стандартный вывод.
С другой стороны, программа xcalc(1) визуально имитирует простой калькулятор с кнопками и дисплеем обычного калькулятора.
Подход, примененный в xcalc(1), проще описать, так как он имитирует интерфейс, с которым знакомы начинающие пользователи. Действительно, в справочном руководстве сказано: "Цифровые клавиши, клавиши
+/
-,
+,
-,
*,
/и
=выполняют в точности те функции, которые от них можно ожидать". Все возможности программы передаются надписями на визуальных клавишах. В данном случае соблюдается правило наименьшей неожиданности в строжайшей его форме, а для редких и начинающих пользователей, которым никогда не понадобится читать справочное руководство по использованию данной программы, это представляется реальным преимуществом.
Рис. 11.1. Графический интерфейс программы xcalc
Однако xcalc также наследует почти полную непрозрачность обычного калькулятора. При расчете сложного выражения невозможно просмотреть и проверить нажатия клавиш, что может оказаться проблемой, если пользователь, например, неверно поставит десятичную точку в выражении, подобном (2.51 + 4.6) * 0.3. В программе не предусмотрено сохранение истории команд, поэтому проверить ввод выражения невозможно. Пользователь получит результат, однако он не будет соответствовать запланированным вычислениям.
Иначе обстоит дело с программами dc(1) и bc(1). Пользователь может исправлять ошибки в выражении по мере его создания. Интерфейс данных программ более прозрачен, поскольку пользователь может просмотреть выполняемые вычисления на каждой стадии. Интерфейс более выразителен, так как интерпретатор dc/bc, не будучи ограниченным подходящей визуальной моделью калькулятора, может включать в себя гораздо более широкий ассортимент функций (и такие средства, как условные переходы, хранимые переменные и циклы). Следствием данных преимуществ, естественно, является большая мнемоническая нагрузка.
Лаконичность в данном случае — это случайная характеристика. Пользователь, хорошо владеющий навыками машинописи, сочтет CLI-интерфейс более лаконичным, тогда как для не владеющего машинописью пользователя, возможно, будет быстрее выбирать и нажимать клавиши в GUI-интерфейсе. Возможность использования в сценариях совсем не случайна. Комбинацию dc/bc можно легко использовать в качестве фильтра, a xcalc вообще невозможно задействовать в сценарии.
Компромисс между простотой для начинающих и полезностью для опытных пользователей в данном случае весьма очевиден. Для нерегулярного использования в ситуациях, когда не трудно проверить ошибку вычисления в уме, более применима программа xcalc. В более сложных вычислениях, где этапы должны быть не только корректными, но их корректность должна быть видимой, или в которых значения более удобно вычисляются другой программой, выигрывает комбинация dc/bc.
11.5. Прозрачность, выразительность и возможность конфигурирования
Unix-программисты унаследовали сильную склонность к созданию выразительных и конфигурируемых интерфейсов. Как и остальные программисты, они думают о том, как привести разрабатываемые интерфейсы в соответствие с требованиями целевой аудитории. Однако они иначе решают вопрос неопределенности целевой аудитории. Разработчики программного обеспечения, главным образом сталкивающиеся с клиентскими операционными системами, обычно склоняются к созданию простых интерфейсов. Они предпочитают жертвовать выразительностью ради простоты. Unix- программисты обычно склонны создавать выразительные и прозрачные интерфейсы и для достижения данных качеств скорее готовы пожертвовать простотой.
Результаты этого часто описываются как интерфейсы, созданные "программистами для программистов". Однако это значительно упрощает проблему. Когда Unix-программист делает выбор в пользу возможности конфигурирования и выразительности вместо простоты, он не обязательно считает свою аудиторию состоящей исключительно из других программистов. Скорее он поступает так инстинктивно, из-за отсутствия знаний о целях конечных пользователей он выбирает наилучший путь — не опекать пользователей и не предугадывать их действия.
Недостатком данной позиции (родственной подходу "механизм, а не политика") является склонность предполагать, что когда высококонфигурируемый и выразительный интерфейс создан, то работа окончена, даже если для кого-либо другого результат почти невозможно использовать без длительного обучения. Обратной стороной конфигурируемости является неотложная потребность в хороших стандартных установках и простом способе устанавливать все настройки в стандартные значения. Обратной стороной выразительности является потребность в руководстве, в самой программе или в документации, где указано, с чего необходимо начинать и как добиваться наиболее распространенных результатов.
(Генри Спенсер.)
Правило прозрачности также оказывает свое влияние. При написании программы, удовлетворяющей требованиям RFC или другого стандарта, который определяет набор управляющих параметров, Unix-программист часто предполагает, что его работа заключается в обеспечении совершенного и прозрачного интерфейса ко всем данным параметрам, причем независимо от того, будет ли, по его мнению, использоваться какой-либо из параметров. Его работа — механизм, а политика принадлежит пользователю.
Эта позиция гораздо меньше допускает неполную поддержку функций. В тех случаях, когда Macintosh или Windows-разработчик сказал бы: "Нам не нужна поддержка данной функции стандарта, большинство пользователей не обратит на это внимания, и она является слишком сложной для них", Unix-разработчик, вероятно, скажет: "Пока не ясно, потребуется ли данная функция или параметр в будущем, следовательно, ее необходимо поддерживать".
Такие противоположные позиции могут приводить к конфликтам, когда Unix-программист работает с не-Unix-программистами, которые, вероятно, истолкуют его выбор конструкции как необдуманное стремление обременять пользователей малопонятными, бессмысленными и даже пугающими техническими подробностями. Mac- и Windows-программисты боятся отпугивать большинство, чтобы служить повышенным потребностям меньшинства.
С другой стороны, Unix-пограммист, вероятно, рассматривает отказ от выразительности как своеобразное бегство от действительности или даже предательство будущих пользователей, которые будут знать о своих требованиях лучше, чем нынешний разработчик. Парадоксально, но несмотря на то, что позиция Unix-разработчиков часто истолковывается как программистское высокомерие, она в действительности является формой смирения, часто приобретаемой с множеством боевых шрамов.
Противоположные культуры программистов по-разному оценивают степень целесообразности позиции Unix. На какой бы стороне водораздела не оказался читатель, разумным будет умение слушать других и понимание предпосылок, лежащих в основе противоположной точки зрения. Чтобы не попасть в ловушку запугивания пользователей или снисходительного отношения к ним, возможно, следует создавать прозрачные интерфейсы, в которых дополнительные функции присутствуют, но присутствуют незаметно. Хорошими примерами для подражания в данном случае являются программы audacity и kmail, рассмотренные в главе 6.
Наконец, приведем замечание относительно конструирования пользовательского интерфейса для нетехнических пользователей. Это сложное искусство, и в нем Unix-программисты не имеют хороших традиций. Однако идеи, которые были сформулированы здесь при изучении Unix-традиций, позволяют сделать одно четкое и полезное утверждение о нем. Когда пользователи говорят, что интерфейс интуитивен, они имеют в виду, что он (а) воспринимаемый, (b) прозрачный в использовании и (с) подчиняется правилу наименьшей неожиданности[103]. Из трех данных правил правило наименьшей неожиданности является наименее ограничивающим. С первоначальной неожиданностью можно справиться, если воспринимаемость и прозрачность делают долгосрочное использование стоящим.
Пользовательские интерфейсы современных мобильных телефонов (например) характеризуются относительно высокой мнемонической нагрузкой, так как пользователю приходится сохранять в памяти хотя бы приблизительную ментальную модель интерфейсных меню, для того чтобы использовать их быстро и без необходимости постоянно уделять внимание расположению текущего пункта в иерархии. Однако хорошо спроектированные интерфейсы в любом случае быстро становятся "интуитивными" для своих пользователей, благодаря тому, что обладают всеми указанными качествами.
Понятое интуитивности не тождественно понятию простоты, поскольку (как показывает пример мобильных телефонов) пользователи способны развивать свою "интуицию" относительно прозрачных интерфейсов, имеющих довольно высокую мнемоническую нагрузку, до тех пор, пока простые операции легко осуществимы и есть способ, позволяющий быстро освоить наиболее трудные функции в интерфейсе.
11.6. Модели проектирования интерфейсов в Unix
В традициях операционной системы Unix описанные выше компромиссы достигаются с помощью твердо установившихся моделей проектирования интерфейсов. Ниже представлены лучшие из этих моделей, их анализ и примеры, после чего описывается их применение.
Следует отметить, что в число лучших примеров не включены модели GUI-конструкций (хотя включается модель проектирования, способная использовать GUI как компонент). В самих графических пользовательских интерфейсах не существует моделей проектирования, которые были бы особенно характерными для Unix. Общее описание моделей проектирования GUI-интерфейсов можно найти в статье "Experiences — A Pattern Language for User Interface Design" [15].
Кроме того, следует отметить, что программы могут иметь режимы, которые подходят для нескольких моделей интерфейсов. Программа, имеющая интерфейс, подобный интерфейсу компилятора, например, может работать как фильтр, если в командной строке не указаны файловые аргументы (подобным образом работают многие конвертеры форматов).
11.6.1. Модель фильтра
Моделью проектирования интерфейсов, которая наиболее традиционно связывается с операционной системой Unix, является фильтр (filter). Программа-фильтр принимает данные на стандартном вводе, трансформирует их определенным образом, после чего они могут запрашивать параметры начальной загрузки (например, переменные окружения), и, как правило, управляются параметрами командной строки, но не требуют обратной связи или ввода пользовательских команд во входной поток.
Двумя классическими примерами фильтров являются программы tr(1) и grep(1). Программа tr(1) представляет собой утилиту, которая преобразует данные на стандартном вводе в результаты на стандартном выводе, используя спецификацию преобразования, заданную в командной строке. Программа grep(1) выбирает из потока стандартного ввода строки, соответствующие выражению, указанному в командной строке. Полученные в результате такого отбора строки отправляются на стандартный вывод. Третья программа-фильтр — утилита sort(1), которая сортирует входящие строки согласно критериям, заданным в командной строке, и отправляет отсортированный результат в поток стандартного вывода.
Обе утилиты grep(1) и sort(1) (но не tr(1)) способны в качестве альтернативы принимать данные из файла (или файлов), указанного в командной строке. В таком случае программы не считывают стандартный ввод, а функционируют так, как если бы поток ввода представлял собой соединение содержимого заданных файлов в порядке следования их имен в командной строке. (В данном случае также ожидается, что ввод в командной строке символа "-" в качестве имени файла вынуждает программу считывать данные со стандартного ввода.) Прообразом таких "cat-подобных" фильтров является программа cat(1), причем предполагается, что фильтры функционируют именно так, если не существует специфических для приложения причин иначе обрабатывать файлы, заданные в командной строке.
При разработке фильтров полезно учитывать несколько дополнительных правил, которые были частично сформулированы в главе 1.
1. Помнить рекомендацию Постела: быть снисходительным к принимаемым данным и строгим к отправляемым данным. То есть пытаться принимать настолько свободные и неорганизованные входные форматы, насколько это возможно, и выпускать насколько возможно хорошо структурированный и компактный исходящий формат. Соблюдение первого условия сокращает вероятность того, что разрабатываемый фильтр будет хрупким в ситуации неожиданного применения и сломается в чужих руках (или в центре чужой инструментальной связки). Соблюдение второго условия увеличивает вероятность того, что данный фильтр будет полезен в качестве ввода для других программ.
2. В ходе фильтрации никогда не следует отбрасывать ненужную информацию. Это также увеличивает вероятность того, что данный фильтр когда-нибудь будет полезен в качестве ввода для других программ. Отброшенная информация — информация, которую не сможет использовать ни один из последующих этапов конвейера.
3. При фильтрации не следует добавлять излишнюю информацию. Необходимо избегать добавления несущественной информации и переформатирования, которое может усложнить анализ отфильтрованных данных в последующих программах. Наиболее распространенными примерами такой информации являются такие косметические добавления, как заголовки, колонтитулы, пустые строки и линейки, итоговые сводки и преобразования, такие как добавление выровненных столбцов или запись "150%" вместо коэффициента "1.5". Значения времени и даты — предмет особого беспокойства, поскольку их сложно анализировать в последующих программах. Любые подобные дополнения должны быть необязательными и контролироваться ключами командной строки. Если разрабатываемая программа выводит даты, то хорошей практикой является наличие ключа, который позволяет выводить их в ISO8601-форматах YYYY-MM-DD и hh:mm:ss, или, что еще лучше, использовать эти форматы по умолчанию.
Термин "фильтр" для данной модели является давно укоренившимся жаргоном Unix.
Понятие "фильтр" действительно давно укоренилось. Оно стало использоваться в то же время, что и каналы (pipes). Термин был заимствован у инженеров-электриков: данные поступали от источника через фильтры в приемник. Источником или приемником мог быть либо процесс, либо файл. Коллективный термин инженеров- электриков, "цепь" (circuit), никогда не рассматривался, так как "водопроводная метафора" для потока данных уже твердо укрепилась.
(Дуг Макилрой.)
Некоторые программы имеют конструкторские модели, подобные фильтрам, но еще проще (и, что существенно, их проще включать в сценарий). Ими являются заклинания (cantrips), источники (sources) и приемники (sinks).
11.6.2. Модель заклинаний
Модель заклинаний является простейшей из моделей проектирования интерфейсов. Нет ни ввода, ни вывода данных, только вызов и числовой код завершения. Режим работы заклинания контролируется только условиями запуска. Не существует другого типа программ, которые проще было бы использовать в сценариях, чем заклинания.
Таким образом, модель заклинаний является замечательным стандартом в ситуациях, когда программе во время выполнения не требуется взаимодействовать с пользователем, кроме получения довольно простых установок первоначальных условий или управляющей информации.
На практике Unix-разработчики учатся противостоять соблазну написания более интерактивных программ, когда для решения задачи вполне подходят заклинания. Набором заклинаний всегда можно управлять из интерактивного упаковщика или shell-программы, но включать в сценарии интерактивные программы сложнее. Следовательно, хороший стиль программирования требует, чтобы разработчик пытался найти конструкцию заклинания для своего средства, прежде чем поддаваться соблазну написания интерактивного интерфейса, который сложнее включать в сценарии. А в ситуациях, когда интерактивность кажется обязательной, необходимо помнить характерную для операционной системы Unix модель проектирования с отделением ядра от интерфейса. Нередко верным решением является написание на каком-либо языке сценариев интерактивного упаковщика, который для выполнения реальной работы вызывает заклинание.
Консольная утилита clear(1), которая просто очищает экран, является заклинанием в чистейшей из возможных его форм. Данная утилита даже не принимает параметров командной строки. Другими классическими примерами являются утилиты rm(1) и touch(1). Программа startx(1), которая применяется для запуска X-сервера, представляет собой комплексный пример, типичный для целого класса программ вызова демонов.
Несмотря на то, что данная модель проектирования является довольно распространенной, она не получила традиционного названия; термин "заклинания" (cantrips) придуман автором. (Cantrips — шотландское слово, первоначально буквально означающее магическое заклинание, которое было подобрано в популярной фантастической ролевой игре для обозначения волшебного слова, которое может быть применено немедленно с минимальной подготовкой или без подготовки.)
11.6.3. Модель источника
Источником (source) является фильтр-подобная программа, которая не требует входных данных, а ее вывод управляется только начальными условиями. Принципиальными примером является утилита ls(1), программа для отображения содержимого каталогов в Unix. В число других классических примеров входят программы who(1) и ps(1).
В операционной системе Unix генераторы отчетов, такие как ls(1), ps(1) и who(1), строго руководствуются моделью источника, так что их вывод можно фильтровать с помощью стандартных инструментальных средств.
Понятие "источник" (source) является, как отмечал Дуг Макилрой, весьма традиционным. Оно менее широко распространено, чем могло бы быть, поскольку термин "источник" имеет другие важные толкования.
11.6.4. Модель приемника
Приемник (sink) — фильтр-подобная программа, которая принимает данные на стандартном вводе, но не отправляет никаких данных на стандартный вывод. Как и в двух предыдущих моделях, действия программы управляются только стартовыми условиями.
Данная модель интерфейсов необычна, и существует только несколько широко известных примеров. Одним из них является программа lpr(1), спулер печати в Unix, которая помещает в очередь для печати текст, переданный ей на стандартном вводе. Как и многие программы-приемники, данная утилита также обрабатывает файлы, указанные в командной строке. Другим примером является программа mail(1) в режиме отправки почты.
Многие программы, которые на первый взгляд могут показаться приемниками, принимают управляющую информацию, как и данные на стандартном вводе, и фактически являются вариантами модели ed (рассматривается ниже).
Понятие "губка" (sponge) иногда применяется именно для программ-приемников, подобных утилите sort(1), которые должны полностью считать входные данные, прежде чем смогут обрабатывать любую их часть.
Термин "приемник" является традиционным и общепринятым.
11.6.5. Модель компилятора
Программы, подобные компиляторам, не используют ни стандартный вывод, ни стандартный ввод; однако они способны отправлять сообщения об ошибках в соответствующий поток данных (stderr). Вместо этого программы данного типа принимают имена файлов или ресурсов из командной строки, определенным образом преобразовывают имена данных ресурсов и отправляют вывод в файлы с трансформированными именами. Как и заклинания, программы, подобные компиляторам, после запуска не нуждаются во взаимодействии с пользователем.
Данная модель названа так потому, что основным образцом для нее служит компилятор языка С, сс(1) (или gcc(1) в Linux и многих других современных Unix-системах). Однако данная модель также широко применяется для программ, осуществляющих (например) преобразование или компрессию/декомпрессию графических файлов.
Хорошим примером программ-конвертеров является утилита gif2png(1), которая применяется для преобразования формата GIF (Graphic Interchange Format) в PNG (Portable Network Graphics)[104]. Хорошими примерами программ компрессии/декомпрессии являются GNU-утилиты gzip(1) и gunzip(1), несомненно, поставляемые с большинством Unix-систем.
Как правило, модель компилятора хорошо применима при проектировании конструкции интерфейса, когда разрабатываемой программе часто приходится оперировать с множеством именованных ресурсов и ее можно написать так, чтобы она не требовала высокой интерактивности (т.е. когда управляющая информация предоставляется во время запуска программы). Программы, подобные компиляторам, можно легко включать в сценарии.
Понятие "компиляторный интерфейс" (compiler-like interface) для данной модели понятно многим в Unix-сообществе.
11.6.6. Модель редактора ed
Для всех предыдущих моделей характерна весьма низкая интерактивность. В них используется только управляющая информация, переданная во время запуска и обособленная от данных. Однако многим программам после запуска требуется управление с помощью продолжительного диалога с пользователем.
Традиционно для Unix, простейшая модель проектирования интерактивного интерфейса иллюстрируется на примере строчного редактора ed(1). В число других классических примеров включаются ftp(1) и sh(1), оболочка Unix. Программа ed(1) принимает в качестве аргумента имя файла и модифицирует данный файл. На входе программа принимает командные строки. Некоторые из команд отражаются на выходных данных на стандартном выводе для немедленного просмотра пользователем, как часть диалога с программой.
Реальный пример сеанса работы в редакторе ed(1) включен в главу 13.
Многие программы в Unix, подобные браузерам и редакторам, придерживаются данной модели, даже когда редактируемые ими именованные ресурсы не являются текстовыми файлами. В качестве примера можно упомянуть символьный GNU-отладчик
Программы, подчиняющиеся модели ed, не так широко можно использовать в сценариях, как можно было бы использовать более простые типы интерфейсов, аналогичные фильтрам. Таким программам можно передать команды через стандартный ввод, но генерировать последовательности команд (и интерпретировать любой их вывод) сложнее, чем просто устанавливать значения переменных окружения и параметры командной строки. Если действие команд не является настолько предсказуемым, что они могут выполняться вслепую (например, с потоковым документом (here document) в качестве входных данных и игнорируя вывод), то управление ed-подобными программами требует протокола и соответствующего конечного автомата в вызывающем процессе. Это приводит к проблемам, отмеченным в главе 7 при обсуждении управления подчиненными процессами.
Тем не менее, данная модель является простейшей и предоставляет наибольшие возможности использования в сценариях, которые доступны для полностью интерактивных программ. Соответственно, она остается весьма полезной как компонент модели "разделения ядра и интерфейса", которая описывается ниже.
11.6.7. Rogue-подобная модель
Данная модель получила свое название благодаря первому примеру ее реализации, ролевой игре rogue(1) (см. рис. 11.2) в BSD. Определение "rogue-подобная" для данной модели широко известно в традиции Unix. Rogue-подобные программы предназначены для запуска в системной консоли, эмуляторе X-терминала или видеотерминале. Они используют полный экран и поддерживают визуальный стиль интерфейса, но с псевдографическим экраном вместо графического экрана и мыши.
Команды обычно представлены в виде одиночных клавиш, ввод которых не отображается для пользователя (в противоположность командным строкам ed-модели), хотя некоторые из них приводят к открытию командного окна (часто, хотя и не всегда, последняя строка экрана), в котором можно вводить более сложные вызовы. Структура команд заставляет пользователя интенсивно использовать клавиши управления курсором для выбора участков экрана или строк, на которых необходимо выполнить какую-либо операцию.
a) some food
b) +1 ring mail [4] being worn
------------------------ ########## c) a +1, +2 mace in hand
| +############### d) a +1,+0 short bow
| | e) 28 +0,+0 arrows
-----------------+------ f) a short bow
# i) a magnesium wand
# g) a magnesium wand
### --------------- j) a potion of detect things
----------+---------- | l) a scroll of teleportation
| | #+ --press space to continue--
| | #| | #
| +#######| | ##
| | | |+##############
--------+------------ ----------------- #
###### #
------+---------- ######
|...........@..!| #
|...........%...| ---------------- #
|...............| #+ | #######
|...............+#################| | #
|...............| | +############
----------------- ----------------
Level: 3 Gold: 73 Hp: 36(36) Str: 14(16) Arm: 4 Exp: 4/78

Рис. 11.2. Копия экрана оригинальной игры Rogue
Программы, написанные в данном стиле, часто моделируются на основе редакторов vi(1) либо emacs(1) и (подчиняясь правилу наименьшей неожиданности) используют их последовательности команд для выполнения таких частых операций, как получение справки и завершение программы. Следовательно, можно, например, ожидать, что программа, написанная согласно данной модели, завершит работу после команд "х", "q" или "C-x C-c".
В число других элементов интерфейсов, связываемых с данной моделью, входят: (а) меню, каждая строка которого состоит из одного пункта, причем текущий выбор выделяется жирным шрифтом или инверсной подсветкой, и (b) "строки состояния" — сводные данные о состояния программы, представленные в подсвечиваемой строке экрана часто вблизи нижней или верхней его границы.
Rogue-подобная модель развивалась в окружении видеотерминалов. Многие из них не имели клавиш-стрелок или функциональных клавиш. В мире персональных компьютеров, поддерживающих графические интерфейсы, с постепенно исчезающими из памяти псевдографическими терминалами, не трудно забыть, какое влияние данная модель оказала на проектирование. Но ранние экземпляры rogue-подобной модели были разработаны за несколько лет до того, как в 1981 году IBM стандартизировала клавиатуру персонального компьютера. Как следствие, традиционной, но в настоящее время архаичной частью модели является использование клавиш h, j, k и l в качестве клавиш управления курсором, когда они не интерпретируются как самостоятельные символы в окне редактирования. Неизменно клавиша k соответствует стрелке "вверх", j — стрелке "вниз", h — стрелке "влево" и l — стрелке "вправо". Данный исторический факт также объясняет, почему в старых Unix-программах часто не использовались клавиши ALT, а функциональные клавиши использовались ограниченно или вообще не использовались.
Существует множество программ, подчиняющихся данной модели: текстовый редактор vi(1) во всех его вариантах, а также редактор emacs(1); elm(1), pine(1), mutt(1) и большинство других Unix-программ для чтения почты; tin(1), slrn(1) и другие программы чтения новостей в Unix; Web-браузер lynx(1) и многие др. Большинство Unix-программистов в основном управляют программами с подобными интерфейсами.
Программы Rogue-подобной модели трудно включать в сценарии. На практике такой подход редко встречается. Среди прочего в данной модели используется режим непосредственного, посимвольного ввода, который неудобен для написания сценариев. Также весьма затруднительно программно интерпретировать вывод, поскольку он обычно состоит из последовательностей действий по окрашиванию экрана.
Также в данной модели отсутствует визуальная гладкость, присущая управляемому с помощью мыши полному GUI-интерфейсу. Несмотря на то, что целью использования полноэкранного интерфейса является поддержка простых видов непосредственного управления и интерфейсов на основе меню, в rogue-подобных программах до сих пор требуется, чтобы пользователи изучали весь ассортимент команд. Действительно, интерфейсы, созданные на основе данной модели, демонстрируют тенденцию к нагромождению режимов и команд, причем требующих одновременного нажатия нескольких клавиш, что может удовлетворить только радикально настроенных хакеров. Может показаться, что данная модель приобрела худшие качества обоих подходов: она не предоставляет возможности включения в сценарии и не согласуется с последними течениями в дизайне интерфейсов для конечных пользователей.
Однако в данной модели существует и определенная ценность. Rogue-подобные почтовые программы, программы для чтения новостей, редакторы и другие программы остаются чрезвычайно популярными даже среди пользователей, которые неизменно запускают их посредством эмуляторов терминала на X-дисплее, поддерживающем GUI-конкурентов. Более того, rogue-подобная модель настолько распространена, что в операционной системе Unix даже GUI-программы часто подражают ей, добавляя поддержку мыши и графики в командный и экранный интерфейс, который выглядит скорее rogue-подобно. Характерными примерами такой доработки являются программы emacs(1) и клиент xchat(1). В чем причина неисчезающей популярности данной модели?
Важными факторами представляются эффективность и ощутимая польза. Для rogue-подобных программ характерна более высокая скорость работы и легковесность по сравнению с их ближайшими GUI-конкурентами. С точки зрения скорости запуска и выполнения, использование rogue-подобной программы в Xterm может быть более предпочтительным по сравнению с запуском GUI-интерфейса, который потребляет солидные ресурсы, устанавливая параметры дисплея и впоследствии медленнее отвечая на запросы пользователя. Кроме того, программы на основе рассматриваемой модели могут применяться на telnet-каналах или низкоскоростных коммутируемых соединениях, для которых X-средства недоступны.
Владеющие "слепым" методом набора операторы предпочитают rogue-подобные программы, поскольку, работая с ними не нужно снимать руки с клавиатуры и перемещать мышь. Имея выбор, такие операторы предпочтут интерфейсы, сокращающие нажатия клавиш, находящихся выше клавиши "home". Возможно, это наибольшая весомая причина популярности редактора vi(1).
Но, более важно то, что rogue-подобные интерфейсы являются предсказуемыми и экономно используют площадь X-дисплея. Они не загромождают дисплей множеством окон, элементами управления, диалоговыми окнами и другим GUI-снаряжением. Это делает данную модель подходящей для использования в программах, которые совместно с другими программами должны часто разделять внимание пользователя (это особенно характерно для редакторов, почтовых программам, программам чтения новостей, chat-клиентов и других коммуникационных программ).
Наконец (и, вероятно, это наиболее важно), rogue-подобная модель часто более, чем GUI, привлекает пользователей, которые ценят лаконичность и выразительность командного набора достаточно высоко для того, чтобы принять дополнительную мнемоническую нагрузку. Выше отмечалось, что существуют весомые причины для того, чтобы такой подход становился более распространенным по мере роста сложности задач, частоты использования и опыта пользователей. Данная модель соответствует предпочтениям таких пользователей, одновременно поддерживая GUI-подобные элементы непосредственного управления, которые не способна поддерживать ed-модель. Таким образом, rogue-подобная модель имеет не только худшие свойства обоих типов интерфейса, но и способна собрать в себе некоторые лучшие их черты.
11.6.8. Модель "разделения ядра и интерфейса"
В главе 7 рассматривались доводы против создания крупных однопроцессных монолитов, а также обсуждалась возможность понижения глобальной сложности программ путем их разделения на взаимодействующие блоки. В мире Unix данная тактика часто реализуется путем отделения "ядра" программы (основных алгоритмов и логики, специфической для данной прикладной области) от "интерфейсной" ее части (которая принимает пользовательские команды, отображает результаты, а также может предоставлять такие службы, как интерактивная справочная система или история команд). В сущности, данная модель обособленного ядра и интерфейса, вероятно, является наиболее характерной моделью проектирования интерфейсов в Unix.
Другими более очевидными кандидатами для такого разграничения были бы фильтры. Однако фильтры в не-Unix-средах встречаются чаще, чем пары ядро/интерфейс с двунаправленной передачей данных между ними. Имитировать конвейеры просто. Сложно реализовать более развитые IPC-механизмы, необходимые для пар ядро/интерфейс.
Оуэн Тейлор (Owen Taylor), куратор библиотеки GTK+, широко используемой для создания пользовательских интерфейсов в системе X, превосходно показал технические преимущества данного вида разделения в конце своей заметки "Why GTK_MODULES is not a security hole" <http://www.gtk.org/setuid.html>. Он заканчивает статью так: "Безопасной setuid-программой является программа в 500 строк кода, выполняющая только то, что необходимо, а не библиотека в 500 000 строк, основной задачей которой является поддержка пользовательских интерфейсов".
Эта идея не нова. Ранние исследования сотрудников центра Xerox PARC в области графических пользовательских интерфейсов привели их к созданию схемы "модель-отображение-контроллер" (model-view-controller) как прототипа для GUI-интерфейсов.
• "Модель" в данном случае — то, что в мире Unix обычно называется "ядром" (engine). Модель содержит структуры данных, зависящие от предметной области, и логику приложения. Серверы баз данных являются основными примерами моделей.
• В часть "отображение" входит то, что приводит объекты предметной области в визуальную форму. В приложении с действительно четко разделенными "моделью/отображением/контроллером" компонент отображения извещается об обновлениях модели и отвечает скорее самостоятельно, а не под синхронным управлением контроллера или явных запросов на обновление.
• Компонент "контроллер" обрабатывает пользовательские запросы и передает их модели в виде команд.
На практике части "отображение" и "контроллер" часто сильнее связаны друг с другом, чем с моделью. Например, в большинстве GUI-интерфейсов комбинируется поведение частей "отображения" и "контроллера". Они разделяются только в тех случаях, когда приложение требует нескольких видов отображения модели.
Схема модель/отображение/контроллер в операционной системе Unix распространена гораздо шире, чем в других средах, именно потому, что существует прочная традиция "решать одну задачу хорошо", а IPC-методы являются одновременно простыми и гибкими.
Особенно мощная форма данной методики связывает интерфейс политики (часто GUI-интерфейс, комбинирующий функции отображения и контроллера) с ядром (моделью), который содержит интерпретатор для узкоспециального мини-языка. Данная модель проектирования рассматривалась в главе 8, где основное внимание было уделено конструкциям мини-языков. Здесь рассматриваются различные способы, с помощью которых такие ядра могут формировать компоненты более крупных систем кода.
Существует несколько основных вариантов данной модели проектирования.
11.6.8.1. Пара конфигуратор/актор
В данной паре интерфейсная часть управляет средой запуска фильтра или программы, подобной демону, которая затем выполняется, не требуя пользовательских команд.
Хорошим примером пары конфигуратор/актор являются программы fetchmail(1) и fetchmaileonf(1) (которые уже использовались как учебные примеры воспринимаемости и создания программ, управляемых данными, а также рассматриваются в главе 14 как учебные примеры использования языка Python). Утилита fetchmailconf представляет собой интерактивный конфигуратор файлов профилей, который поставляется с программой fetchmail. fetchmailconf также может служить в качестве GUI-упаковщика, который запускает fetchmail либо в приоритетном, либо в фоновом режиме.
Данная модель проектирования позволяет обеим программам, fetchmail и fetchmailconf, специализироваться в том, что они делают хорошо, и конечно, позволяет писать их на различных языках, которые целесообразно использовать в данных предметных областях. Программу fetchmail, которая обычно запускается в фоновом режиме как демон, не требуется объединять с GUI-кодом, и наоборот, fetchmailconf может специализироваться на сложном GUI-представлении, не требуя от fetchmail затрат размера и сложности. Наконец, ввиду того, что информационные каналы между ними являются узкими и четко определенными, остается возможность управлять программой fetchmail из командной строки, а также из сценариев, отличных от fetchmailconf.
Термин "конфигуратор/актор" придуман автором данной книги.
11.6.8.2. Пара спулер/демон
Облегченный вариант пары конфигуратор/актор может оказаться полезным в ситуациях, когда требуется сериализованный доступ к общему ресурсу в пакетном режиме, т.е. когда четко определенный поток заданий или последовательность запросов требует некоторого совместно используемого ресурса, но ни одна отдельная задача не требует взаимодействия с пользователем.
В данной модели спулер или клиентская часть просто помещает запросы на выполнение заданий и данные в спул-область. Запросы на выполнение заданий и данные — просто файлы, а спул-областью, как правило, является каталог. Расположение данного каталога и формат запросов согласовывается между спулером и демоном.
Демон постоянно работает в фоновом режиме, опрашивая спул-каталог в поисках задания. Когда он находит запрос на выполнение задания, то пытается обработать связанные с ним данные. Если обработка прошла успешно, то запрос и данные из спул-области удаляются.
Классическим примером данной модели является система спулера печати Unix, lpr(1)/lpd(1). Интерфейсной частью в данном случае является утилита lpr(1), просто помещающая предназначенные для печати файлы в спул-область, которая периодически сканируется демоном lpd. Задача данного демона — сериализация доступа к печатающим устройствам.
Другим классическим примером является пара at(1)/atd(1), обеспечивающая выполнение команд по расписанию. Третьим исторически важным примером, хотя и не распространенным в настоящее время, была программа UUCP (Unix-to-Unix Copy Program), широко применявшаяся в качестве почтового транспорта на коммутируемых линиях до того, как в начале 90-х годов прошлого века не начался взрывной рост Internet.
Модель спулер/демон и сейчас остается важной в программах транспортировки почты (которые по своей природе являются пакетными). Интерфейсные части почтовых транспортных программ, таких как sendmail(1) и qmail(1), обычно предпринимают одну попытку немедленной доставки почты через SMTP-сервер и внешнее Internet-соединение. Если попытка не удалась, то почта помещается в спул-область; демон-версия или режим почтового транспорта попытается доставить почту позднее.
Как правило, система спулер/демон состоит из четырех частей: модуль запуска задания, организатор очереди, утилита отмены задания и спулер-демон. Фактически присутствие первых трех частей определенно указывает на то, что за ними находится спулер-демон.
Понятия "спулер" и "демон" — прочно укоренившийся жаргон в Unix-сообществе (фактически термин "спулер" появился во время ранних мэйнфреймов).
11.6.8.3. Пара драйвер/ядро
В данной модели, в отличие от пары конфигуратор/актор или спулер/демон, интерфейсная часть подает команды и интерпретирует вывод от ядра после запуска. Ядро имеет простую модель интерфейса. Используемый IPC-метод является деталью реализации: ядро может быть подчиненным процессом драйвера (в том смысле, который обсуждался в главе 7), или ядро и драйвер могут взаимодействовать через сокеты, общую память, или посредством любого другого IPC-метода. Ключевыми моментами в данном случае являются (а) интерактивность пары и (b) способность ядра к самостоятельной работе со своим собственным интерфейсом.
Написание таких пар сложнее, чем написание пар конфигуратор/актор, поскольку они теснее и сложнее связаны. Драйверу необходимы сведения не только об ожидаемой среде запуска ядра, но и о его наборе команд, а также о форматах ответов.
Однако если ядро спроектировано с возможностью использования в сценариях, то нередко драйверная часть пишется не автором ядра, а другим разработчиком, или несколько драйверов могут подключаться к определенному ядру. Превосходный пример в обоих случаях представлен программами gv(1) и ghostview(1), которые являются драйверами для gs(1), интерпретатора Ghostscript. Ghostscript переводит PostScript в различные графические форматы и низкоуровневые языки управления принтерами. Программы gv и ghostview обеспечивают GUI-упаковщики для весьма уникальных ключей вызова и синтаксиса команд Ghostscript.
Другим превосходным примером данной модели является комбинация программ
xcdroast/
cdrtools. В дистрибутив cdrtools входит программа cdrecord(1) с интерфейсом командной строки. Код cdrecord специализируется на работе с аппаратным обеспечением приводов CD-ROM. Программа xcdroast представляет собой GUI-интерфейс и предназначена для того, чтобы создать комфортные условия работы для пользователя. Для выполнения большей части работы программа xcdroast(1) вызывает cdrecord(1).
Программа xcdroast также вызывает другие CLI-инструменты: cdda2wav(1) (конвертер звуковых файлов) и mkisofs(1) (средство для создания из списка файлов CD-ROM-образов с файловой системой ISO-9660). Подробности того, как данные средства вызываются, скрыты от пользователей, которые могут сконцентрировать внимание на создании CD-образов, а не на необходимости знать секреты преобразования звуковых файлов или структуры файловых систем. Равно важно и то, что разработчики каждого из данных средств могут концентрироваться на профессиональных знаниях в своей предметной области без необходимости быть экспертами в разработке пользовательских интерфейсов.
Главный "подводный камень" организации драйвер/ядро состоит в том, что часто драйвер должен распознавать состояние ядра, для того чтобы отражать его пользователю. Если ядро работает практически без задержек, то это не является проблемой, однако если ядру требуется большой промежуток времени (например, при доступе к множеству URL-адресов), то недостаток обратной связи может создавать значительные сложности. Подобной проблемой является отклик на ошибки. Например, традиционный (хотя и не совсем соответствующий духу Unix) запрос на подтверждение при перезаписи существующего файла сложен в написании в системе драйвер/ядро. Ядру, обнаружившему проблему, приходится требовать от драйвера выдать сообщение пользователю.
(Стив Джонсон.)
Важно спроектировать ядро так, чтобы оно не только правильно работало, но и уведомляло драйвер о выполняемой работе, с тем чтобы драйвер мог представить изящный интерфейс с соответствующей обратной связью.
Понятия "драйвер" и "ядро" являются редкими, но устоявшимися в Unix-сообществе.
11.6.8.4. Пара клиент/сервер
Пара клиент/сервер подобна паре драйвер/ядро, за исключением того, что часть ядра является запущенным в фоновом режиме демоном, от которого не требуется интерактивная работа и наличие собственного пользовательского интерфейса. Обычно демон предназначен для того, чтобы быть посредником в доступе к какому-либо совместно используемому ресурсу — базе данных, потоку транзакций или совместно используемому специализированному аппаратному обеспечению, такому как звуковое устройство. Другой причиной для использования такого демона может быть необходимость избежать выполнения дорогостоящих начальных действий при каждом вызове программы.
Рис. 11.3. GUI-интерфейс программы Xcdroast
Раньше, например, очень популярной была пара ftp(1)/ftpd(1), реализующая протокол FTP (File Transfer Protocol — протокол передачи файлов); также в качестве примера можно упомянуть два экземпляра программы sendmail(1) — это отправитель в приоритетном режиме и слушатель в фоновом, передающие электронную почту в Internet. В настоящее время таким примером будет любая пара браузер/Web-сервер.
Однако данная модель не ограничена коммуникационными программами. Другим важным случаем ее применения являются базы данных, например пара psql(1)/postmaster(1). В данной паре программа psql сериализует доступ к совместно используемой базе данных, управляемой демоном postgres, передавая ему SQL-запросы и представляя данные, отправленные в качестве ответов.
Приведенные выше примеры иллюстрируют важное свойство данных пар, которое заключается в том, что чистота протокола, сериализующего связь между ними, является крайне важной. Если протокол четко определен и описан открытым стандартом, то он может предоставить широкие возможности для развития, изолируя клиентские программы от деталей управления серверными ресурсами и позволяя клиентам и серверам развиваться почти независимо. Все программы с ядром, отделенным от интерфейса, потенциально извлекают данное преимущество из четкого разделения функций, но в случае клиент/сервер выигрыш от верной реализации часто особенно высок именно потому, что управлять общими ресурсами действительно сложно.
Для связи клиентской части с серверной могут использоваться и используются очереди сообщений и пары именованных каналов, однако преимущества от возможности запуска сервера на другой машине являются настолько весомыми, что в настоящее время почти во всех современных парах клиент/сервер используются TCP/IP-сокеты.
11.6.9. Модель CLI-сервера
В мире Unix обычной является практика, когда серверные процессы вызываются управляющими программами[105], такими как inetd(8), т.е. сервер может получать команды через стандартный ввод и отправлять ответы на стандартный вывод. Управляющая программа затем обеспечивает подключение стандартного ввода и вывода сервера к порту определенной TCP/IP-службы. Преимущество такой организации функций заключается в том, что управляющая программа может работать как одна безопасная программа-диспетчер (gatekeeper) для всех серверов, которые она запускает.
Таким образом, одной из классических моделей интерфейсов является CLI-сервер. CLI-сервер — программа, которая при запуске в привилегированном режиме имеет простой CLI-интерфейс, считывающий данные со стандартного ввода и отправляющий данные на стандартный вывод. Когда сервер запускается в фоновом режиме сервер, он обнаруживает это и подключает свой стандартный ввод и вывод к определенному TCP/IP-порту.
В некоторых вариантах данной модели сервер по умолчанию переводится в фоновый режим, а для того чтобы он оставался в привилегированном режиме, в командной строке необходимо использовать определенный ключ. Но еще более важно то, что большая часть кода "не знает" и "не заботится" о том, работает ли программа в привилегированном режиме или запущена как управляющая TCP/IP-программа.
Серверы POP3, IMAP, SMTP и HTTP обычно соответствуют данной модели. Ее можно комбинировать с любыми моделями клиент/сервер, описанными ранее в данной главе. HTTP-сервер также может функционировать в качестве управляющей программы. CGI-сценарии, которые создают большую часть интерактивного содержания в Web, выполняются в обеспеченной данным сервером специальной среде, где они могут принимать ввод (из аргументов) из стандартного ввода и записывать сгенерированные в результате своей работы HTML-страницы в стандартный вывод.
Хотя данная модель весьма традиционна, термин "CLI-сервер" впервые введен в употребление автором данной книги.
11.6.10. Модель интерфейсов на основе языков
В главе 8 рассматривались узкоспециальные мини-языки как средства перемещения спецификации программ на более высокий уровень с приобретением гибкости и сокращением количества ошибок. Благодаря этим достоинствам CLI-интерфейс на основе языков сегодня во многом определяет стиль Unix-интерфейсов.
Сильные стороны данной модели хорошо иллюстрируются приведенным ранее в данной главе учебным примером, в котором комбинация утилит dc(1)/bc(1) сравнивается с программой xcalc(1). Преимущества, отмеченные ранее (выигрыш в выразительности и возможностях использования в сценариях), типичны для мини- языков. Они обобщаются в других ситуациях, в которых обычно приходится последовательно выполнять сложные операции в специализированной прикладной области. Довольно часто, в отличие от примера с калькулятором, мини-языки также обладают явным преимуществом лаконичности.
Одной из наиболее мощных моделей проектирования в Unix является комбинация клиентского GUI-интерфейса с серверной частью, представленной CLI-мини-языком. Хорошо спроектированные примеры данного типа неизбежно сложны, но часто являются более простыми и гибкими, чем большой объем уникального кода, который понадобился бы для решения даже небольшой части тех задач, которые способен решить мини-язык.
Данная общая модель, без сомнения, не является уникальной для Unix. Современные пакеты приложений для работы с базами данных в большинстве операционных систем обычно состоят из одного или нескольких GUI-клиентов и генераторов отчетов, каждый из которых обращается к общему серверу, используя язык запросов, такой как SQL. Однако данная модель развивалась преимущественно в Unix-среде и до сих пор остается в ней гораздо более понятной и применяется шире, чем в каких-либо других операционных системах.
Когда клиентская и серверная части системы, удовлетворяющей данной модели проектирования, скомбинированы в одной программе, то о такой программе часто говорят, что она имеет "встроенный язык сценариев". В Unix-среде одним из наиболее известных экземпляров данной модели является редактор Emacs. Некоторые преимущества Emacs рассматриваются в главе 8.
Другим хорошим примером является средство script-fu программы GIMP. GIMP — мощный графический редактор с открытым исходным кодом, имеющий GUI-интерфейс, подобный интерфейсу программы Adobe Photoshop. Средство script-fu позволяет использовать функции GIMP в сценариях, написанных на языке Scheme (диалект Lisp). Доступно также написание сценариев на языках Tcl, Perl или Python. Программы, написанные на любом из указанных языков, могут вызывать внутренние функции GIMP через его интерфейс подключаемых подпрограмм. Демонстрационное приложение для данного средства представлено на Web-странице[106], позволяющей создавать простые логотипы и графические кнопки посредством CGI-интерфейса, который передает сгенерированную Scheme-программу экземпляру GIMP и возвращает завершенное изображение.
11.7. Применение Unix-моделей проектирования интерфейсов
Для того чтобы облегчить написание сценариев и создание конвейеров, разумно выбрать простейшую из возможных моделей интерфейса, т.е. модель с минимальным числом каналов к окружению и наименьшей интерактивностью.
При описании многих однокомпонентных моделей подчеркивалось, что соответствующая программа после запуска не требует взаимодействия с пользователем. Если ожидается, что "пользователем" часто будет другая программа (которой, естественно, не достает гибкости человеческого мозга), то это является очень ценной особенностью, максимальной увеличивающей возможность использования программы в сценариях.
Выше уже говорилось, что в различных моделях оптимизированы характеристики, ценные в различных обстоятельствах. В частности, существует жесткое и давнее противоречие между GUI-интерфейсами, а также моделями, подходящими для начинающих и нетехнических конечных пользователей (с одной стороны), и интерфейсами, которые обслуживают опытных пользователей и максимально расширяют возможности использования программ в сценариях (с другой стороны).
Один из способов обойти эту дилемму заключается в создании программ с различными режимами, представляющими несколько моделей. В данном случае замечательным примером является Web-браузер lynx(1). Обычно lynx имеет rogue-подобный интерфейс для интерактивного использования, но может быть вызван с параметром
-dump, превращающим его в программу-источник, форматирующую указанную Web-страницу в текст, который распечатывается на стандартный вывод.
Однако подобные двухрежимные интерфейсы обычно не применяются, когда программа должна иметь действительно графический пользовательский интерфейс. Причины этого частично являются историческими, но главная причина — необходимость управлять глобальной сложностью. GUI-интерфейсы склонны требовать сложной начальной конфигурации и большого количества специализированного кода. Наличие данных особенностей в более простых моделях небезопасно. В худшем случае двухрежимная программа (работающая как с GUI-интерфейсом, так и без него) может потребовать двух отдельных циклов интерпретации команд, а также выполнения других условий, подразумевающих распухание кода и потенциальную несовместимость.
Таким образом, когда выбор "простейшей модели" противоречит созданию GUI-интерфейса, Unix-способом будет разделение программы на две части согласно модели "разделение ядра и интерфейса".
В сущности, комбинируя идею из главы 7 с описанной выше, можно определить новую модель проектирования, возникшую в Linux и других современных Unix-системах с открытым исходным кодом. В этой модели GUI-интерфейсы являются не просто вынужденными дополнениями, а определяют перспективное направление для приложения усилий многих разработчиков.
11.7.1. Модель многопараметрических программ
Многопараметрическая (polyvalent) программа обладает рядом характерных особенностей.
1. Прикладная логика программы находится в библиотеке с документированным API-интерфейсом, который может быть связан с другими программами. Интерфейсная логика программы для связи с внешним миром представляет собой тонкий уровень над библиотекой. Или, возможно, существует несколько уровней с различными стилями пользовательского интерфейса, к любому из которых можно подключить данную библиотеку.
2. Одним из режимов пользовательского интерфейса является модель "заклинания", модель компилятора" или CLI-модель", в которой интерактивные команды выполняются в режиме пакетной обработки.
3. Одним из режимов пользовательского интерфейса является GUI-интерфейс, либо связанный непосредственно с основной библиотекой, либо функционирующий как отдельный процесс, управляющий CLI-интерфейсом.
4. Одним из режимов пользовательского интерфейса является интерфейс сценариев, использующий один из современных универсальных языков сценариев, например Perl, Python или Tcl.
5. Не обязательное дополнение: одним из режимов пользовательского интерфейса является rogue-подобный интерфейс, в котором используется библиотека curses(3).
В наибольшей степени данной модели в настоящее время соответствует пакет GIMP.
11.8. Использование Web-браузера в качестве универсального клиента
Отделение CLI-сервера от GUI-интерфейса стало особенно привлекательной стратегией после того, как в середине 1990-х годов технология World Wide Web преобразила мир компьютерных вычислений. Для большого класса приложений возрастает смысл вообще не писать нестандартные GUI-клиенты, а вместо этого в данной роли использовать Web-браузеры.
Такой подход имеет целый ряд преимуществ. Наиболее очевидным является то, что разработчику не требуется писать процедурный GUI-код. Вместо этого можно описать желаемый GUI-интерфейс на специально предназначенных для этого языках (HTML и JavaScript). Это позволяет избежать большого количества дорогого и сложного одноцелевого кодирования и часто более чем вдвое сокращает общие усилия по проекту. Другое преимущество заключается в том, что разрабатываемое приложение немедленно становится готовым для использования в Internet. Клиент может быть расположен на том же узле, что и сервер, или находиться за тысячи километров от него. Также преимуществом является то, что все второстепенные детали представления приложения (такие как шрифты и цвет) более не являются задачей сервера, и пользователи действительно смогут выбирать их по своему усмотрению с помощью таких механизмов, как настройки браузера и каскадные таблицы стилей. Наконец, единообразные элементы Web-интерфейса существенно облегчают пользователям задачу изучения.
Данный подход имеет и недостатки. Два наиболее важных из них: (а) пакетный стиль взаимодействия, навязанный Web-средой, и (b) сложности управления постоянными сеансами при использовании протокола без фиксации состояния. Хотя указанные недостатки не являются исключительно проблемами Unix, их следует рассмотреть здесь, поскольку на уровне конструкции весьма важно четко определить, когда стоит принять или обработать данные ограничения.
Рис. 11.4. Связи вызывающих и вызываемых программ в многопараметрической программе
Интерфейс общего шлюза (Common Gateway Interface — CGI), посредством которого браузер может вызывать программы на серверном узле, не вполне поддерживает интерактивность на уровне мелких модулей. Не поддерживают ее и шаблонные системы, серверы приложений и встроенные серверные сценарии, которые постепенно заменяют CGI (слегка злоупотребляя данным понятием, автор далее в настоящем разделе использует аббревиатуру CGI для обозначения всех указанных технологий).
Через CGI-шлюз невозможно осуществлять посимвольный или пожестовый ввод-вывод в GUI. Вместо этого необходимо заполнить HTML-форму и нажать кнопку "отправить", после чего содержимое формы будет отослано CGI-сценарию, который затем обработает данные, а сервер передаст обратно клиенту сгенерированную сценарием HTML-страницу (которая сама по себе может быть другой CGI-формой).
Описанная выше методика по существу представляет пакетный стиль взаимодействия, который концептуально недалеко ушел от загрузки перфокарт во входной бункер и получения распечатки. Этот стиль можно преобразовать в более приемлемую форму, используя для взаимодействия с пользователем JavaScript-сценарий, группирующий транзакции в сообщения для отправки серверу.
Java-аплеты способны открывать собственные соединения для символьных потоков обратно к серверу с целью поддержать более управляемую интерактивность. Однако Java имеет технические проблемы — данный язык может использовать только фиксированную область экрана на странице и не способен изменить часть экрана за пределами этого прямоугольника. Имеются также гораздо более серьезные проблемы, связанные с политикой (частное лицензирование со стороны Sun заблокировало Java-разработку и вынудило остальных с недоверием относиться к Java; разработчик не может рассчитывать на то, что браузеры всех пользователей поддерживают данную технологию).
Кроме того, как Java, так и JavaScript могут столкнуться с несовместимостью браузеров. Сопротивление Microsoft внедрению JDK 1.2 и Swing в Internet Explorer является серьезной проблемой для Java-аплетов. Различные уровни версий JavaScript также могут нарушить работу приложения (хотя ошибки JavaScript исправляются проще). Тем не менее, часто решить данные проблемы не так сложно, как написать и внедрить нестандартный клиентский интерфейс. Более сложной проблемой является растущее число искушенных пользователей, которые по привычке отключают в своих браузерах поддержку Java и даже JavaScript из-за проблем с безопасностью и нарушения интерфейса.
Возникает также отдельная проблема — сложно поддерживать информацию о сеансах между несколькими CGI-формами. Между CGI-транзакциями сервер не хранит сведения о состоянии клиентских сеансов, поэтому на них нельзя полагаться, связывая формы, отправленные пользователем позднее, с ранее отправленными тем же пользователем формами. Существует два стандартных технических приема для решения данной проблемы: связанные формы и cookie-файлы.
При связывании форм подготавливается CGI-сценарий для формирования первой формой уникального идентификатора в скрытом поле второй формы, а вторая и все последующие формы передают данный идентификатор последующим элементам. Cookie-файлы достигают подобного эффекта путем аналогичным переменным окружения (подробные инструкции описаны в любой из сотен книг по CGI-программированию). В любом случае в CGI-сценарии необходимо использовать идентификатор в качестве индекса сеанса (или cookie-файлов для непосредственного сохранения состояния) и явно обрабатывать мультиплексирование сеансов.
Часто данными ограничениями можно пренебречь. Многие нетривиальные приложения могут уместиться в одной форме и работать, избегая обеих проблем. Даже если это не так и приложению требуется множество форм, понижение сложности и сокращение количества средств по сравнению с необходимостью создания и распространения специализированного клиента настолько велико, что может свободно окупить усилия, необходимые для написания достаточно развитых CGI-сценариев, самостоятельно осуществляющих отслеживание сеансов.
Проблема управления сеансами может быть переадресована серверам приложений, таким как Zope или Enhydra, которые обеспечивают отделение сеансов и предоставляют службы аутентификации для программ внутри них. Недостаток данных программ равноценен их достоинству: они облегчают сохранение на сервере информации о состоянии по каждому пользовательскому сеансу. Хранение данных сведений может оказаться проблемой. Оно занимает ресурсы, и данную информацию необходимо удалять по истечении определенного времени, поскольку между транзакциями не существует способа точно определить, остается ли пользователь на связи.
Как обычно, наилучшая рекомендация — выбирать простейшую из возможных моделей, т.е. сопротивляться соблазну создавать тяжеловесную конструкцию, опирающуюся на Java или сервер приложений, в ситуациях, когда решить задачу можно с помощью простых CGI-сценариев и cookie-файлов.
Проблемой методики использования браузера в качестве универсального клиента является то, что CGI-серверы очень непросто отделить от среды браузера, поэтому может быть трудно написать сценарий или автоматизировать транзакции к серверу. Unix-ответ — трехуровневая архитектура: Web-формы, вызывающие CGI-сценарии, которые в свою очередь вызывают команды. Интерфейсом автоматизации являются команды.
Способ, с помощью которого браузеры отделяют клиентов от серверов, имеет более серьезные последствия. В Web-среде стало сложнее и не так привлекательно привязывать потребителей к закрытым, частным протоколам и API-интерфейсам. Экономика разработки программ, таким образом, склоняется к HTML, XML и другим открытым, текстовым Internet-стандартам. Данная тенденция успешно и интересно объединяется с развитием модели разработки открытого исходного кода, которая рассматривается в главе 19. В мире, где Web является созидательной средой, Unix-традиции проектирования, включая рассмотренные в настоящей главе методики проектирования интерфейсов, выглядит гораздо более естественно, чем когда-либо прежде.
11.9. Молчание — золото
Рассматривая тему интерактивных пользовательских интерфейсов нельзя не упомянуть одну из наиболее давних и постоянных идей проектирования в Unix — правило тишины. В главе 1 отмечалось, что хорошо спроектированные Unix-программы, не имеющие интересной или неожиданной для пользователя информации, должны выполнять свою работу бесшумно. Для этого существуют веские причины, которые намного "пережили" медленные телетайпы, на которых родилась операционная система Unix.
Одна из них заключается в том, что программы, которые выдают излишнюю информацию, часто не способны надежно взаимодействовать с другими программами. Если CLI-программа отправляет сообщения о состоянии на стандартный вывод, то программы, пытающиеся интерпретировать данный вывод, столкнутся с проблемой обработки или отклонения данных сообщений (даже если ничего неординарного не произошло). Гораздо лучше отправлять только реальные ошибки в стандартный вывод сообщений об ошибках и вообще не выводить незапрашиваемые данные.
Другой проблемой является то, что вертикальное пространство пользовательского экрана весьма ценно. Каждая строка бесполезных данных, отображаемых программой, означает потерю одной строки дисплея.
Третья проблема: бесполезные сообщения отвлекают внимание пользователя. Они являются еще одним источником отвлекающих перемещений по экрану дисплея, который может быть посредником в решении более важных приоритетных задач, таких как общение с другими пользователями.
Необходимо двигаться дальше и снабжать длительные операции индикаторами выполнения. Это хороший стиль, позволяющий пользователю, распределять свое внимание на чтение почты или другие задачи, ожидая подтверждения. Однако не следует загромождать GUI-интерфейсы всплывающими окнами подтверждения, кроме случаев, когда необходимо обезопасить операции, в результате которых данные могут быть утеряны или повреждены, и даже тогда необходимо скрывать их, если родительское окно свернуто, и не показывать до тех пор, пока родительское окно не получит фокус[107]. Задача дизайнера интерфейса заключается в том, чтобы помогать пользователю, а не беспричинно вмешиваться в его работу.
Как правило, считается плохим стилем сообщать пользователю о том, что он уже знает (два классических примера: "Программа <foo> запускается…" или "Программа <foo> завершает свою работу…"). Конструкция интерфейса в целом должна подчиняться правилу наименьшей неожиданности, а содержание сообщений — правилу наибольшей неожиданности. Сообщения должны уведомлять пользователя только о явлениях, отклоняющихся от нормы.
Данное правило звучит еще жестче для запросов на подтверждение. Постоянные запросы на подтверждение, когда ответом почти всегда является "Да", вырабатывают у пользователя привычку нажимать кнопку "Да", не принимая во внимание сути запроса, привычку, которая может иметь весьма печальные последствия. Программы должны запрашивать подтверждение только в случае, если имеется веская причина подозревать, что ответом будет "нет, нет и еще раз нет". Запрос на подтверждение, суть которого не является неожиданной, — признак плохого дизайна. Любые запросы на подтверждение вообще могут означать, что единственное, чего действительно не достает интерфейсу, это команда отмены предыдущего действия.
Если подробные сообщения о выполнении операций необходимы в целях отладки, то по умолчанию они должны быть отключены и вызываться только в случае запуска программы с ключом
-v(вывод подробных сведений). Перед окончательным выпуском программы необходимо сделать так, чтобы как можно больше обычных сообщений отображались только в случае использования ключа вывода подробных сведений.
12
Оптимизация
Преждевременная оптимизация — корень всех зол.
(-Ч. Хоар)
Данная глава очень короткая, поскольку главное, чему учит опыт Unix относительно оптимизации производительности, — как узнать, когда не следует выполнять оптимизацию. Второстепенный урок заключается в том, что наиболее эффективные тактики оптимизации обычно связаны с мероприятиями, имеющими иные цели, например, обеспечение четкости конструкции.
12.1. Отказ от оптимизации
Наиболее мощная методика оптимизации, входящая в инструментарий любого программиста, заключается в том, чтобы ничего не делать.
Этот весьма выдержанный в духе Дзэн совет верен по нескольким причинам. Одной из них является экспоненциальный эффект закона Мура — самый разумный, дешевый и часто самый быстрый способ достичь прироста производительности заключается в том, чтобы подождать несколько месяцев, пока целевое аппаратное обеспечение станет более мощным. Учитывая ценовое соотношение между аппаратным обеспечением и временем программиста, почти всегда существуют лучшие варианты использования времени, чем оптимизация уже работающей системы.
Данная точка зрения может быть обоснована математически. Почти никогда не следует выполнять оптимизацию, которая сокращает использование ресурсов просто на постоянную величину. Гораздо разумнее сконцентрировать усилия на случаях, в которых можно сократить среднее время запуска или использование пространства с O(n²) до O(n) или О(n log n)[108] или подобным образом понизить порядок. Согласно закону Мура, линейный прирост производительности достаточно быстро уменьшается[109].
Существует другая весьма конструктивная форма отказа от оптимизации — не писать код. Скорость работы программы не может быть уменьшена кодом, которого в ней нет, она может быть уменьшена кодом, который в ней есть, если он менее эффективен, чем мог бы быть. Однако это уже другая проблема.
12.2. Измерения перед оптимизацией
Когда имеются реальные доказательства того, что разрабатываемое приложение работает слишком медленно, тогда (и только тогда) наступает время обдумать оптимизацию кода. Однако перед этим необходимо сделать нечто большее — провести измерения.
Читателям следует вспомнить шесть правил Роба Пайка, описанных в главе 1. Один из первых уроков, который усвоили программисты Unix, заключается в том, что интуиция — неверный советчик при определении местоположения "бутылочных горлышек", причем даже для того, кто очень хорошо знает свой код. Unix-системы, в отличие от большинства других операционных систем, обычно поставляются вместе с профайлерами (profiler — подпрограмма протоколирования), и их стоит использовать.
Чтение результатов работы профайлера вполне можно сравнить с искусством. Существует несколько периодически повторяющихся проблем: первая — погрешность измерения, вторая — влияние налагаемых внешних задержек, третья — перевес верхних узлов графа вызовов.
Фундаментальной является проблема погрешности измерений. Профайлеры выполняют свои функции, внедряя инструкции, которые фиксируют время выполнения в точках входа и выхода из подпрограмм, а также в фиксированных интервалах во внутреннем коде программ. Выполнение данных инструкций само по себе отнимает некоторое время. В результате сокращается разброс времени вызовов: очень короткие подпрограммы часто выглядят более дорогостоящими, чем они есть на самом деле, с большим количеством шума в их относительном времени вызова, тогда как для более длинных подпрограмм издержки измерения незаметны.
Принимая во внимание погрешность измерения, разумно предположить, что значения времени, указанные для самых быстрых, кратчайших подпрограмм, из-за шума будут завышены. Их выполнение также потребует большого количества времени, если они будут вызываться очень часто, однако, следует уделить должное внимание статистическим данным по количеству их вызовов.
Проблема внешней задержки также является фундаментальной. Существуют различные виды задержек и искажений, которые могут возникать вне поля зрения профайлера. Простейшим примером являются издержки операций с непредсказуемой задержкой: доступ к дискам и сетям, заполнение кэша, переключение контекста процессов и им подобные. Проблема заключается не столько в возникновении данных задержек — возможно, именно их и требуется измерить, особенно если основное внимание уделяется производительности системы в целом, а не просто регулировке критически важного внутреннего цикла. Реальная проблема состоит в том, что они содержат случайный компонент, а это означает, что результаты любого отдельного запуска профайлера могут быть не самыми достоверными.
Одним из способов минимизации влияния указанных источников шума и получения более четкой картины утечки времени в среднем случае является сложение результатов от множества запусков профайлера. Существует множество весомых причин для создания средств тестирования и тестовых нагрузок до оптимизации разрабатываемых программ. Наиболее важной причиной, как правило, гораздо более важной, чем регулировка производительности, является то, что впоследствии, по мере модификации программы, можно использовать возвратное тестирование ее корректности. После того как это сделано, возможность выполнять профилирование повторяющихся тестов под нагрузкой является хорошим побочным эффектом, который часто предоставляет более точную информацию, чем несколько запусков вручную.
Различные факторы склонны перекладывать затраты времени на вызывающие программы, а не на вызываемые, что увеличивает вес верхних узлов графа вызовов. Например, издержки вызова функции часто относят к вызывающей программе (так это или нет, в некоторой степени зависит от архитектуры конкретной машины и от того, где профайлеру разрешено размещать пробы). Макросы и встраиваемые функции, в случае если компилятор их поддерживает, не показываются в отчете профайлера вообще. Расходуемое ими время относится к вызывающей функции.
Более важно то, что многие средства учета времени создают такое впечатление, будто время, затраченное на подпрограммы, относится к вызывающей программе. (Данная особенность характерна для профайлера gprof(1), распространяемого в составе Unix-систем с открытыми исходными кодами). Простое вычитание времени вызываемой программы из времени вызывающей не даст достоверных результатов, если одну и ту же программу могут вызывать несколько других программ — результатом было бы искусственное сокращение времени всех вызывающих программ. Особенно опасным является распространенный случай функции с несколькими узлами вызова, одни из которых создают множество простейших вызовов, а другие создают несколько сложных.
Для получения более прозрачных результатов следует организовать код так, чтобы программы верхнего уровня содержали как можно больше обращений к программам более низкого уровня, а не ко встроенному коду. Если издержки управляющей логики верхнего уровня остаются минимальными, то структура вызова кода будет стремиться организовать отчет профайлера таким способом, который будет сравнительно простым для понимания.
Использование профайлеров еще больше проясняет ситуацию, если в меньшей степени рассматривать их как способы накопления отдельных показателей производительности, и в большей степени как способы определения закономерности, по которой производительность изменяется как функция от интересующих параметров. Такими параметрами могут быть, например, размер проблемной области, частота процессора, скорость диска, размер памяти, оптимизация компилятора или другие релевантные факторы. Необходимо попытаться подобрать модель для данных чисел, используя программное обеспечение с открытым исходным кодом, такое как R, или качественный коммерческий инструмент, подобный MATHLAB.
Естественное сглаживание данных, определяемое моделью, характеризуется выявлением главных факторов и пренебрежением второстепенных, связанных с шумом. Например, при использовании кубической модели в подпрограмме обращения матрицы в MATHLAB на случайных матрицах от 10×10 до 1000×1000, очевидно, что фактически получается 3 куба с четко определенными границами, которые примерно соответствуют областям "в кэше", "в памяти, но вне кэша" и "вне памяти". Данные демонстрируют такой эффект, даже если не искать его, а просто изучать отклонения от наилучших результатов.
(Стив Джонсон.)
12.3. Размер кода
Наиболее эффективный способ оптимизировать код заключается в том, чтобы сохранять его небольшой размер и простоту. Ранее в данной книге уже рассматривалось множество весомых причин для сохранения небольшого размера и простоты кода. В данной главе рассматривается еще одна такая причина: необходимо, чтобы центральные структуры данных и циклы в коде, время выполнения которых критически важно, никогда не выходили за пределы кэша.
Рассмотрим целевую машину как иерархию типов памяти, упорядоченных по удаленности от процессора. Она включает в себя собственные регистры процессора; его конвейер инструкций; кэш первого уровня (L1); кэш второго уровня (L2); вероятно, кэш третьего уровня (L3); оперативная память (которая среди специалистов старой школы Unix до сих пор изящно называется основой (core)); и дисковые накопители, на которых располагается область подкачки. Такие технологии, как SMP, кластеры с общей памятью и технология доступа к неоднородной памяти (Nonuniform Memory Access — NUMA) добавляют больше уровней в картину, но только расширяют общий разброс.
Любые виды доступа к данному стеку ускоряются. Циклы процессора являются почти бесплатными, исключая несколько требовательных приложений, таких как моделирование ядерных взрывов или сжатие видео в реальном времени. Однако также по мере возрастания скорости процессора, происходит увеличение соотношения скоростей между уровнями в иерархии хранения. Таким образом, относительная стоимость потерь кэша увеличивается.
Наблюдается интересный парадокс. По мере того как стоимость аппаратных ресурсов резко снижается, ожидаемая стоимость крупных структур данных падает, однако, поскольку разница стоимости между смежными уровнями кэша растет, величина производительности, необходимая для выхода за пределы кэша, также возрастает.
"Малое прекрасно" — эта идея, следовательно, является более убедительной, чем когда-либо, особенно в отношении центральных структур данных, которые должны располагаться в как можно более быстром кэше. Данная рекомендация также применима и к коду; средняя инструкция затрачивает больше времени при загрузке, чем при выполнении.
Это меняет некоторые традиционные советы на прямо противоположные. Оптимизация компилятора, подобная развертке цикла, которая освобождает сравнительно дорогие машинные инструкции в обмен на увеличение общего размера кода, может оказаться более нецелесообразной. Другим примером является предвычисление небольших таблиц — например, таблица значений функции sin(x) от величины угла для оптимизации вращения в ядре 3D графики потребует на современной машине 365×4 байт. До того как процессоры стали быстрее, чем память, чтобы требовать кэширования, это было очевидной оптимизацией скорости. В настоящее время, возможно, быстрее будет пересчитывать результаты каждый раз, чем расплачиваться за дополнительные потери кэша, вызванные хранением таблицы.
Однако в будущем, по мере того как размеры кэша возрастут, все может вернуться на свои места. В общем случае множество видов оптимизации являются временными и могут привести к прямо противоположным результатам по мере изменения соотношения цен. Единственный путь узнать это заключается в измерении и анализе.
12.4. Пропускная способность и задержка
Другим последствием использования быстрых процессоров является то, что производительность обычно ограничивается затратами на I/O-операции и (особенно в случае программ, использующих Internet) затратами на сетевые транзакции. Следовательно, разработчику полезно знать, как проектировать сетевые протоколы для достижения высокой производительности.
Наиболее важной проблемой является максимальное предотвращение полных циклов протокола. Каждая протокольная транзакция, требующая квитирования, превращает любую задержку в соединении в потенциально серьезное замедление. Избежание квитирования не является специфической и традиционной практикой Unix, однако здесь необходимо упомянуть данный практический прием, поскольку из-за квитирования значительно понижается производительность многих протоколов.
О задержке я могу сказать не много. Версия X11 далеко "оторвалась" от Х10 в предотвращении полных циклов обращения: Render-расширение уходит еще дальше. X (и в настоящее время HTTP/1.1) является протоколом потоковой передачи. Например, мой портативный компьютер способен выполнять более 4 млн. прямых запросов (8 млн. холостых запросов) в секунду. Однако полные циклы "запрос-ответ" в сотни или тысячи раз дороже. Каждый раз, когда клиент может выполнить какую-либо операцию, не обращаясь к серверу, является огромным выигрышем.
(Джим Геттис.)
Действительно хорошее практическое правило заключается в том, чтобы проектировать конструкцию с наименьшей возможной задержкой и игнорировать затраты полосы пропускания до тех пор, пока профайлеры не укажут обратное. Проблемы, связанные с полосой пропускания, можно решить позднее при разработке с помощью таких технических приемов, как сжатие данных протокола на лету. Однако освободиться от высокой задержки, встроенной в существующую конструкцию, гораздо труднее (часто практически невозможно).
Несмотря на то, что данный эффект наиболее четко проявляется в конструкции сетевых протоколов, компромисс между пропускной способностью и задержкой является гораздо более общим феноменом. При написании приложений программист иногда сталкивается с необходимостью выбора: однократное выполнение дорогостоящих вычислений в расчете на то, что результаты будут использоваться несколько раз, или выполнение вычислений только в случае действительной необходимости (даже если это означает частое перевычисление результатов). В большинстве подобных случаев правильный подход склоняется в сторону низкой задержки. То есть не следует пытаться выполнить дорогостоящее предвычисление в случае, если нет определенных требований к пропускной способности или если изменения не показывают слишком низкую пропускную способность. Предвычисления могут показаться эффективными, поскольку они минимизируют общее использование процессорных циклов, но процессорные циклы дешевы. Если создается простая программа, а не одно из немногочисленных гигантских приложений с интенсивными вычислениями, например, для анализа больших массивов информации, визуализации анимации или упомянутое выше модулирование взрывов, то обычно наилучший путь — предпочесть небольшое время запуска и быстрый отклик.
В ранние дни Unix данную рекомендацию сочли бы еретической. В то время процессоры были гораздо медленнее, а соотношения затрат сильно отличались. Кроме того, модель использования Unix больше склонялась к серверным операциям. Отчасти отметить значение низкой задержки необходимо потому, что даже более молодые Unix-разработчики иногда наследуют давние культурные предубеждения по поводу оптимизации по пропускной способности. Однако времена изменились.
Разработаны три общие стратегии сокращения задержки: (а) пакетные транзакции, способные распределить начальные затраты, (b) разрешение совмещения транзакций и (с) кэширование.
12.4.1. Пакетные операции
Графические API-интерфейсы часто пишутся в предположении, что фиксированные начальные затраты для обновления физического экрана достаточно высоки. Следовательно, операции записи фактически модифицируют внутренний буфер. Программисту придется решить, когда накоплено достаточное количество обновлений, и использовать вызов, который превратит их в обновление физического экрана. Верный выбор промежутка времени между физическими обновлениями может создавать значительные различия в восприятии графических клиентов. Таким способом организованы как X-сервер, так и библиотека curses(3), используемая в rogue-подобных программах.
Постоянные служебные демоны представляют собой более характерный для Unix пример пакетирования. Существует две причины для написания постоянно работающих демонов (в противоположность CLI-серверам, которые запускаются заново для каждого сеанса) — очевидная и неочевидная. Очевидной причиной является управление обновлениями общего ресурса. Менее очевидная причина, которая имеет место даже для демонов, не обрабатывающих обновления, заключается в том, что при многочисленных запросах сокращаются затраты на чтение в базе данных демона. Идеальным примером такого демона является DNS-служба named(8), которая нередко должна обрабатывать тысячи запросов в секунду, каждый из которых может фактически блокировать загрузку Web-страницы пользователем. Одна из тактик, делающих named(8) быстрой службой, заключается в том, что в ней дорогостоящие операции анализа дисковых текстовых файлов, описывающих DNS-зоны, заменяются доступом к кэшу, который содержится в памяти.
12.4.2. Совмещение операций
В главе 5 сравнивались протоколы POP3 и IMAP для опроса удаленных почтовых серверов. При этом было отмечено, что IMAP-запросы (в отличие от POP3-запросов) маркируются идентификатором запроса, сгенерированным клиентом. Сервер, отправляя обратно ответ, включает в него метку запроса, к которому относится данный ответ.
POP3-запросы должны обрабатываться клиентом и сервером в строгом порядке. Клиент отправляет запрос, ожидает ответ на данный запрос и только после его получения может подготовить и отправить следующий запрос. IMAP-запросы, с другой стороны, маркируются, поэтому их передачу можно совместить. Если IMAP-клиенту известно, что требуется доставить несколько сообщений, то он может отправить IMAP-серверу поток из нескольких запросов на доставку (каждый со своей меткой), не ожидая ответов между ними. Маркированные ответы отправятся обратно, как только сервер будет готов. Ответы на более ранние запросы могут поступить в то время, когда клиент все еще отправляет более поздние запросы.
Описанная стратегия является распространенной не только в области сетевых протоколов. Когда требуется сократить задержку, блокировка или ожидание немедленных результатов — крайне неэффективные методы.
12.4.3. Кэширование результатов операций
Иногда можно получить оба преимущества (низкую задержку и хорошую пропускную способность) путем вычисления дорогостоящих результатов по мере необходимости и их кэширования для последующего использования. Выше было сказано, что в службе named задержка сокращается путем пакетирования. Кроме того, задержка в named уменьшается с помощью кэширования результатов предыдущих транзакций с другими DNS-серверами.
Кэширование имеет собственные проблемы и компромиссные решения, которые хорошо иллюстрируются одним примером: использование двоичного кэша для устранения издержек синтаксического анализа, связанного с файлами текстовых баз данных. В некоторых вариантах операционной системы Unix данная методика использовалась для ускорения доступа к парольной информации (обычным обоснованием было сокращение задержки при регистрации в системе на очень крупных узлах).
Для того чтобы обеспечить соответствующую отдачу от использования данной методики, необходимо чтобы весь код, обращающийся к бинарному кэшу, проверял временные метки на обоих файлах и обновлял кэш в случае, если мастер-текст имеет более позднюю метку. С другой стороны, все изменения мастер-текста должны выполнятся посредством упаковщика, который обновляет двоичный формат.
Несмотря на то, что данный подход оказывается работоспособным, он обладает всеми недостатками, которые можно ожидать при нарушении правила SPOT. Дублирование данных означает, что в результате не будет никакой экономии пространства, т.е. это исключительно оптимизация скорости. Однако реальная проблема данного подхода заключается в том, что код для обеспечения когерентности между кэшем и мастер-текстом печально известен как "текучий" и чреватый ошибками. Очень частое обновление файлов кэша может привести к неочевидной конкуренции просто ввиду односекундного разрешения временных меток.
Но когерентность все-таки можно гарантировать в простых случаях. Одним из них является интерпретатор языка Python, который компилирует и сохраняет на диске файл p-кода с расширением
.pyc, когда файл библиотеки Python импортируется впервые. При последующих проходах кэшированная копия p-кода загружается, в случае если источник с тех пор не изменялся (это позволяет избежать повторного синтаксического анализа исходного кода библиотеки при каждом проходе). Подобная методика используется в Emacs Lisp (файлы
.elи .
.elc). Данная методика работоспособна, так как доступ для чтения и для записи кэша осуществляется посредством одной программы.
Однако, когда модель обновления главных файлов более сложна, код обеспечения синхронизации склонен к утечкам. Unix-варианты, использующие данную методику для ускорения доступа к критически важным системным базам данных, имели дурную репутацию среди системных администраторов.
Как правило, файлы бинарного кэша являются хрупкой методикой, и, вероятно, будет лучше избегать их использования. Усилия, затраченные на реализацию специализированных средств для сокращения задержки, в данном случае было бы целесообразнее направить на совершенствование конструкции приложения, так чтобы в ней не было "бутылочного горлышка", или даже на тонкую настройку для повышения скорости файловой системы или реализации виртуальной памяти.
Если ситуация на первый взгляд требует использования методики кэширования, то разумно будет взглянуть на уровень глубже и ответить на вопрос: почему вообще понадобилось кэширование? Решение данной проблемы вполне может оказаться не сложнее, чем правильное решение всех граничных случаев в кэширующем программном обеспечении.
13
Сложность: просто, как только возможно, но не проще
Все следует делать так просто, как только возможно, но не проще.
(—Альберт Эйнштейн)
В конце главы 1 философия Unix была сведена к общему принципу — K.I.S.S. (Keep It Simple, Stupid! Будь проще!). В части "Проектирование" данной книги одной из ключевых тем была важность сохранения максимально возможной простоты конструкции и реализации. Однако, что значит "просто, как только возможно"?
Рассмотрение данного вопроса откладывалось до настоящей главы потому, что простота — комплексное понятие. В качестве теоретической основы при изучении данной темы необходимы некоторые идеи, которые были сформулированы ранее в части "Проектирование", особенно в главах 4 и 11.
Важными вопросами в данной главе являются основные предубеждения Unix-традиции. Некоторые из этих предубеждений стали причинами идеологических войн, продолжавшихся в течение десятилетий. Данная глава начинается с рассмотрения установившейся практики и терминологии Unix, а затем несколько выходит за рамки этой тематики. Автор не пытается сформулировать здесь простые ответы на данные вопросы, это невозможно, однако концептуальные средства, описанные в настоящей главе, вероятно, позволят читателям продвинуться дальше в собственном поиске ответов.
13.1. Сложность
Как и в случае рассмотренных выше вопросов модульности и проектирования интерфейсов, Unix-программисты воспринимают ряд отличий, которые они часто усваивают из опыта, даже не зная, как их назвать. Поэтому начинать следует с изложения некоторых терминов.
Раздел начинается с определения того, в чем заключается сложность программного обеспечения. Далее определяются некоторые горизонтальные границы между несколькими разновидностями сложности. Завершается данный раздел определением еще более важных вертикальных различий между видами сложности, с которыми приходится смириться, и видами сложности, которые можно устранить.
13.1.1. Три источника сложности
Вопросы о простоте, сложности и верном размере программного обеспечения вызывают бурные споры в Unix-сообществе. Unix-программисты развили такое мировоззрение, согласно которому простота — это красота, изящество и добро, а сложность — уродство, абсурдность и зло
В основе программистского стремления отстаивать простоту лежит прагматичный факт: сложность дорого обходится. Сложное программное обеспечение труднее анализировать, тестировать, отлаживать, сопровождать, но прежде всего его сложнее изучать и использовать. Издержки сложности, не устраненные во время разработки, резко проявляются после внедрения программы. Сложность создает источники ошибок, из которых они распространяются и создают проблемы на протяжении всего срока службы программного обеспечения.
Тем не менее, остается достаточно факторов, которые "толкают" программистов "в трясину сложности". В предыдущих главах рассматривалось множество неконтролируемых факторов. Два наиболее широко известных — сползание функций и преждевременная оптимизация. Традиционно Unix-программисты отклоняют эти тенденции, провозглашая с религиозной страстью лозунги, осуждающие всякую сложность.
Что конкретно автор называет "сложностью"? Этот момент достоин точного определения ввиду своей важности.
Unix-программисты (как и остальные программисты) склонны фокусировать внимание на сложности реализации — по существу, степени трудности, с которой столкнется программист, пытаясь понять программу, для того чтобы создать ее ментальную модель или отладить.
С другой стороны, потребители и пользователи склонны видеть сложность в самих понятиях сложности интерфейса программы. В главе 11 рассматривалась простота и качество, противоположное ей, т.е. мнемоническая нагрузка. Для пользователя сложность тесно связана с мнемонической нагрузкой. Слабая выразительность и лаконичность также имеют значение, в случае если неразвитый интерфейс вынуждает пользователя выполнять множество чреватых ошибками или просто утомительных низкоуровневых операций вместо нескольких высокоуровневых.
Оба описанных выше вида сложности управляют третьим, более простым: общее количество строк кода в системе, т.е. размер кодовой базы. В понятиях стоимости на протяжении жизненного цикла данный критерий обычно является наиболее важным. Причины, вероятно, связаны с самым важным эмпирическим выводом программной инженерии, который цитировался ранее: плотность дефектов кода, выраженная в количестве ошибок на сотню строк, стремится к постоянному значению независимо от языка реализации. Большее количество строк кода означает большее количество ошибок, а отладка является наиболее дорогостоящей и трудоемкой частью процесса разработки.
Размер кодовой базы, сложность интерфейса и реализации могут возрастать одновременно, что является обычным результатом сползания функций и причиной особенных опасений программистов. Преждевременная оптимизация не склонна увеличивать сложность интерфейса, но оказывает негативное влияние (часто крайне негативное) на сложность реализации и размер кодовой базы. Однако эти доводы против сложности сравнительно просты. Более серьезные трудности начинаются, когда приходится искать компромисс между тремя данными критериями.
Ранее уже упоминалась одна ситуация, при которой два критерия изменяются в противоположных направлениях: пользовательский интерфейс, который разрабатывался в основном для сохранения простоты реализации или небольшого размера кодовой базы, может просто перекладывать низкоуровневые задачи на пользователя. (В качестве грубого примера, едва ли вообразимого Unix-программистом, но слишком распространенного в других средах, можно представить редактор, не имеющий функции глобальной замены.) Хотя такой вид неудачной конструкции является чрезвычайно распространенным, он не имеет традиционного названия. В данной книге он называется ловушкой ручного труда.
Стремление сохранить небольшой размер кодовой базы с помощью чрезвычайно плотных и сложных методик реализации может вызвать нарастание сложности реализации в системе, ведущее к неразберихе, которую невозможно исправить. Ранее такое часто случалось, когда для того чтобы втиснуть программу в очень малую систему, приходилось программировать на ассемблере или использовать такие нетривиальные технические приемы, как самомодифицирующийся код. В наши дни такая проблема не распространена, кроме случаев со встроенными системами, но и в них она быстро становится редкой. Данный вид неудачной конструкции не имеет традиционного названия, однако эту проблему можно назвать ловушкой уплотнения.
Ловушка уплотнения не рассматривается в учебных примерах данной книги, она определена для контраста с противоположной ей проблемой. Вполне возможны ситуации, когда разработчики проекта будут настолько осторожны в вопросе сложности реализации, что постараются отказаться от сложного, но единообразного пути для разрешения целого класса проблем в пользу большого количества дублирующегося специального кода, последовательно решающего каждую задачу. В результате такого подхода увеличивается размер кодовой базы и появляются проблемы сопровождения, более сложные, чем в случае использования унифицированного метода. Например, Web-проект, где для наполнения страниц действительно необходима централизованная реляционная база данных, может вместо этого содержать несколько различных индексированных файлов данных, содержащих информацию, которую необходимо интегрировать заново при каждом создании страницы. Данный вид неудачной конструкции является слишком распространенным. Он не имеет традиционного названия, однако его можно назвать ловушкой специального кода.
Выше описаны три вида сложности, а также некоторые ловушки, в которые попадают разработчики, пытающиеся избежать сложности[110]. Примеры рассматриваются далее в настоящей главе.
13.1.2. Компромиссы между сложностью интерфейса и реализации
Одно из наиболее ярких замечаний о Unix-традиции, сделанных когда-либо сторонним наблюдателем, содержится в статье Ричарда Гэбриэла (Richard Gabriel), которая называется "Lisp: Good News, Bad News, and How to Win Big" [25]. Гэбриэл в течение многих лет является бессменным лидером Lisp-сообщества, и данная статья главным образом была доводом в пользу особого стиля Lisp-конструкции. Однако сам автор статьи признает, что сейчас она вспоминается в основном из-за раздела, который называется "The Rise of Worse Is Better".
В статье утверждалось, что Unix и С обладают характеристиками вирусов и что в эволюционной борьбе конструкций программного обеспечения такие особенности, как простота реализации и переносимость, которые ведут к быстрому распространению (заражаемости), являются более эффективными, чем корректность и завершенность конструкции. Гэбриэл в своем предвидении так близко подошел к влиянию экспертной оценки на программное обеспечение с открытым исходным кодом, что сообщество открытого исходного кода приняло его как одного из своих теоретиков.
Не так часто вспоминается то, что главный аргумент Гэбриэла относился к весьма специфическому компромиссу между сложностью реализации и сложностью интерфейса, который довольно точно вписывается в рассмотренные выше категории. Гэбриэл сопоставляет философию MIT, в которой наиболее ценится простота интерфейса, с философией Нью-Джерси, где выше всего ценится простота реализации. Затем он утверждает, что хотя MIT-философия приводит к появлению программного обеспечения, которое абстрактно лучше, модель Нью-Джерси (худшая) обладает лучшими характеристиками распространения. Со временем люди уделяют больше внимания программному обеспечению, написанному в стиле Нью-Джерси, поэтому оно быстрее улучшается, и худшее становится лучшим.
В действительности, философия MIT и Нью-Джерси имеет аналоги как конфликтующие направления в самой Unix-традиции проектирования. Один тип Unix-мышления придает особое значение небольшим точным инструментам, конструкциям, разработанным с нуля, а также простым и последовательным интерфейсам. Дуг Макилрой решительно отстаивает данную точку зрения. Другой тип мышления акцентирует внимание на простых реализациях, которые работают и быстро распространяются, даже если используются методы грубой силы, а некоторые граничные случаи необходимо устранить. Код Кена Томпсона, а также его принципы программирования часто и очевидно склоняются к этому направлению.
Конфликт между данными подходами возникает именно потому, что иногда программист может получить простой интерфейс, если согласен заплатить за него сложностью реализации, и наоборот. Оригинальный пример Гэбриэла о том, как системные вызовы, выполняющие длительные операции, обрабатывают прерывания, которые не способны удержать или замаскировать, до сих пор остается одним из лучших. В MIT-философии правильный путь заключается в выходе из системного вызова и автоматическом его возобновлении, как только прерывание будет обработано. Данную методику труднее реализовать, однако она ведет к созданию более простого интерфейса. В философии Нью-Джерси системный вызов возвращает ошибку, указывающую на то, что вызов был прерван и пользователь должен перезапустить его. Такой подход значительно проще в реализации, но приводит к программному интерфейсу, который труднее использовать.
На практике применяются оба подхода. Unix-разработчики старой школы немедленно подумают о сравнении System V и BSD-стилей обработки программных сигналов. Последний следует MIT-философии, тогда как System V-стиль происходит из Нью-Джерси. В основе выбора между ними лежит сложный вопрос, который непосредственно не касается распространения программного обеспечения: если цель заключается в ограничении глобальной сложности, что разработчик охотнее всего принесет в жертву? Что ему следует принести в жертву?
Одним эпохальным примером, не упомянутым Гэбриэлом, являются распределенные гипертекстовые системы. Ранние проекты распределенных гипертекстовых систем, такие как NLS и Xanadu, были жестко ограничены предположениями MIT-философии о том, что ссылки, указывающие на несуществующий объект, являются недопустимой неполадкой в пользовательском интерфейсе. Это ограничивало системы либо просмотром только контролируемого, закрытого набора документов (как, например, на одном CD-ROM), либо реализацией различного тиражирования со все возрастающей сложностью, кэширующих и индексирующих методов в попытке предотвратить случайное исчезновение документов. Тим Бернерс-Ли (Tim Berners-Lee) разрубил этот гордиев узел, разрешив проблему в классическом стиле Нью-Джерси. Простота реализации, достигнутая им благодаря разрешению ответа "404: Not Found", была тем, что сделало систему World Wide Web достаточно легковесной, чтобы она могла успешно распространяться.
Сам Гэбриэл придерживался мнения о том, что "худшее" более заразительно и, в конце концов, стремится к победе. Несмотря на это, он неоднократно публично менял свое мнение относительно основополагающего вопроса, связанного со сложностью: сложность — это хорошо или плохо? Его непостоянство отражает множество продолжающихся споров в Unix-сообществе.
Автору данной книги не представляется возможным сформулировать универсальный ответ. Как и большинство других важнейших вопросов в данной главе, хороший вкус и инженерное мышление предполагают различные ответы в разных ситуациях. Важно развить привычку тщательно обдумывать данную проблему для всех и для каждой разрабатываемой конструкции. Как отмечалось ранее при обсуждении модульности программного обеспечения, сложность сопряжена с затратами, которые необходимо весьма тщательно предусматривать.
13.1.3. Необходимая, необязательная и случайная сложность
В идеальном мире Unix-программисты создавали бы только небольшие, совершенные "жемчужины программирования", каждая из которых была бы минимальной, изящной и безупречной. Однако одной из негативных черт реальности является то, что она часто ставит сложные проблемы, требующие сложных решений. Невозможно управлять реактивным лайнером с помощью изящной процедуры из десяти строк кода. Существует слишком много блоков оборудования, множество каналов и интерфейсов, множество различных процессоров, т.е. слишком много различных подсистем, определенных независимыми разработчиками, которые часто не согласны друг с другом даже в фундаментальных вопросах. Даже если предположить, что разработчик добился успеха в изящной реализации всех отдельных частей программного обеспечения для авиационной электронной системы управления, в ходе их интеграции, вероятно, будет создан большой, сложный и нечеткий код с одним достоинством — он действительно будет работать.
Реактивные самолеты обладают необходимой сложностью. Существует довольно четкая грань, за которой невозможно принести в жертву функции в обмен на простоту, поскольку самолет должен оставаться в воздухе. Благодаря самому этому факту, разработчики авиационных электронных систем управления не склонны втягиваться в "религиозные войны" в вопросе сложности, Unix-программисты также часто избегают их.
Конечно, реактивные авиалайнеры не застрахованы от системных сбоев, возникающих из-за чрезмерной сложности. Но вопросы проектирования проще распознать и проанализировать в программном обеспечении, для которого требования более гибкие, а поиски компромисса между предполагаемыми функциями и сложностью просты. (Здесь и далее в настоящей главе понятие "функции" используется в весьма широком смысле, который включает в себя различные элементы, такие как прирост производительности или общая степень изысканности интерфейса.)
Для того чтобы добиться более яркого видения проблемы, необходимо начать с определения отличия между случайной сложностью и необязательной сложностью[111]. Случайная сложность возникает вследствие того, что разработчик не нашел простейшего способа реализации заданного набора функций. Такая сложность преодолевается благодаря хорошему проектированию или хорошему перепроектированию. С другой стороны, необязательная сложность связана с некоторой желаемой функцией. Необязательная сложность может быть устранена только путем изменения целей проекта.
Когда разработчики не могут отличить необязательную сложность от случайной, споры по поводу проекта создают тупиковую ситуацию. Вопросы о том, каковы цели проекта, смешиваются с вопросами об эстетике простоты и о том, кто умнее среди участников спора.
13.1.4. Диаграмма видов сложности
Выше были показаны две различные шкалы для анализа сложности. Данные шкалы фактически перпендикулярны друг другу. Рис. 13.1 может помочь при выяснении связей. В каждом из девяти блоков на рисунке приведен общий источник определенного вида сложности.
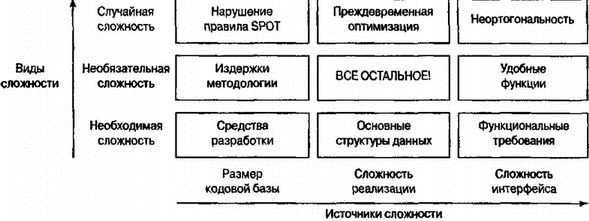
Рис. 13.1. Источники и виды сложности
Некоторые из данных разновидностей сложности уже рассматривались ранее в данной книге, особенно случайная сложность. В главе 4 было показано, что случайная сложность интерфейса часто обусловлена неортогональностью в конструкции интерфейса, т.е. невозможностью тщательной организации интерфейсных операций, так чтобы каждая из них выполняла только одну функцию. Случайная сложность кода (создание более сложного кода, чем это требуется для решения задачи) часто является результатом преждевременной оптимизации. Случайное увеличение кодовой базы часто является результатом нарушения правила SPOT, дублирования кода или его неудачной организации, в которой трудно распознать возможности для повторного использования.
Необходимую сложность интерфейса обычно невозможно уменьшить без сокращения основных функциональных требований к программному обеспечению (данная тема развивается далее в настоящей главе при изучении учебных примеров). Необходимый размер кодовой базы связан с выбором средств разработки, поскольку, если список функций сохраняется постоянным, то наиболее значимым фактором в размере кодовой базы, вероятно, является выбор языка реализации (что следует из главы 8).
Источники необязательной сложности наиболее трудно поддаются наглядному обобщению, поскольку они часто зависят от тонких суждений о том, ради каких функций стоит повышать сложность. Необязательная сложность интерфейса часто связана с добавлением удобных функций, которые облегчают работу пользователей, но не являются существенными для работы программы. Необязательное увеличение размеров кода (в предположении, что список доступных пользователю функций и используемых алгоритмов является постоянным) часто может быть следствием различных практических приемов, направленных на то, чтобы сделать код более сопровождаемым. В число таких приемов входит добавление развернутых комментариев, использование длинных имен переменных и т.д. На необязательную сложность реализации часто влияет все, что касается проекта.
С источниками сложности необходимо бороться различными способами. Размер кодовой базы можно уменьшить с помощью лучших инструментальных средств. Сложность реализации можно уменьшить с помощью более тщательного выбора алгоритмов. Сложность интерфейса необходимо исправлять, тщательнее проектируя взаимодействие программы с пользователем, данный навык предполагает анализ эргономических характеристик и психологии пользователя. Это умение менее широко распространено (и возможно, является более сложным в освоении), чем навык написания кода.
С другой стороны, бороться со сложностью необходимо больше при помощи понимания, чем с помощью различных методов. Разработчик уменьшает случайную сложность, понимая, что существует более простой способ решения задачи. Необязательную сложность можно уменьшить, предметно рассуждая о том, какие функции стоит реализовать. Что же касается необходимой сложности, то ее можно уменьшить только с просветлением, фундаментально переопределяющим решаемую проблему.
13.1.5. Когда простоты не достаточно
Неудачное решение вопроса простоты Unix-программистами заключается в том, что они часто действуют так, будто вся необязательная сложность является случайной. Более того, традиция Unix сильно склоняется к тому, чтобы удалять функции во избежание необязательной сложности.
Тем более, что отстаивать эту позицию не сложно (поистине большая часть данной книги направлена на это). Чистый минимализм позволяет нам порой чувствовать себя виртуозами, а минималистское проектирование — весомое противостояние естественной тенденции программных систем развивать все более сложное сопровождение слабо продуманных функций. Однако вычислительные ресурсы и время размышления человека подобны богатству, и их гораздо интереснее использовать, а не накапливать. Разработчику необходимо определить, когда минимализм в проектировании становится не ценной формой самодисциплины, а просто самоистязанием — способом "приобретения добродетелей" в обмен на отказ от реального использования богатства, необходимого для выполнения работы.
Это сложный вопрос, его просто превратить в аргумент в пользу полного отказа от хорошей проектной дисциплины. Профессионалы старой школы Unix часто избегают его, опасаясь, что неспособность как можно жестче противостоять сложности и раздуванию кода неминуемо приводит к порицанию. Однако данный вопрос также является необходимым. Он будет рассматриваться непосредственно при анализе учебных примеров данной главы.
13.2. Редакторы
Ниже в качестве учебных примеров рассматриваются пять различных Unix-редакторов. При их изучении полезно учитывать набор эталонных задач, перечень которых приводится ниже.
• Редактирование простого текста. Манипулирование простыми ASCII-файлами (или, принимая во внимание эпоху интернационализации, возможно, Unicode-файлами) без известной редактору структуры выше байтового уровня или, возможно, уровня строки.
• Редактирование расширенного текстового формата. Редактирование текста с атрибутами, в число которых можно включить изменения шрифта, цвета или другие виды свойств текстовых диапазонов (такие как создание гиперссылки). Редакторы, способные выполнять данные функции, должны иметь возможности преобразования между формой представления атрибутов в пользовательском интерфейсе и формой дискового представления данных (например, HTML, XML или другие расширенные текстовые форматы).
• Подсветка синтаксиса языков программирования. Редактор с подсветкой синтаксиса "знает" о существовании грамматики входных событий и осуществляет такие функции, как автоматическое изменение уровня отступов, если распознает начало или конец блока в языке программирования. В таких редакторах синтаксис обычно выделяется цветом или различающимися шрифтами.
• Синтаксический анализ вывода неинтерактивных команд. Наиболее распространенный случай данной функции в мире Unix — запуск С-компиляции из редактора, перехват сообщений об ошибках и возможность последующего пошагового выполнения ошибочных блоков без необходимости выхода из редактора.
• Взаимодействие с постоянными вспомогательными подпроцессами, которые поддерживают состояние между командами редактора. Если такая возможность предусмотрена, то это дает следующие преимущества.
• Появляется возможность управлять системой контроля версий из редактора, отмечая файлы и возвращая изменения в систему без перехода в оболочку или отдельную утилиту.
• Появляется возможность подключать редактор в качестве пользовательского интерфейса к символическому отладчику, чтобы (например) при остановке выполнения программы в контрольной точке автоматически открывался соответствующий файл и подсвечивалась строка.
• Появляется возможность редактирования файлов на других машинах, если заставить редактор распознавать ссылки на удаленный узел (распознавание такого синтаксиса как /пользователь@узел:/путь/к_файлу). Если у пользователя редактора имеются соответствующие права доступа, то редактор может автоматически запускать такую утилиту, как scp(1) или ftp(1), для загрузки локальной копии файла, а затем автоматически копировать отредактированную версию обратно на удаленный узел в момент сохранения файла.
Все рассматриваемые ниже редакторы способны редактировать простой текст. (Читателю не следует принимать данную возможность как должное, существует множество программ, именуемых редакторами, такие как "текстовые процессоры", которые слишком специализированы для выполнения данной функции.) Переменные степени необязательной сложности будут очевидны, если проанализировать то, как редакторы выполняют более сложные задачи.
13.2.1. ed
ed(1) представляет собой действительно минималистский Unix-инструмент для редактирования простого текста. Он датируется временем телетайпов[112]. Редактор имеет простой, "аскетический" CLI-интерфейс без экрана. В приведенном ниже листинге компьютерный вывод выделен курсивом.
ed sample.txt
sample.txt: No such file or directory
#Это строка комментария, а не команда.
#Выше указанное сообщение предупреждает о том,
#что только что создан новый файл sample.txt.
а
the quick brown fox
jumped over the lazy dog
.
#Выше была команда присоединения, которая добавляет
#к данному файлу текст.
#Сама по себе точка в строке ограничивает добавление текста,
ls/f[a-z]х/dragon/
#В строке 1 заменить первое вхождение подстроки, соответствующей
#символу f с последующим алфавитным символом в нижнем регистре,
#за которым следует символ х, подстрокой 'dragon'.
#Команда замены допускает использование базовых
#регулярных выражений.
1,$Р
the quick brown dragon
jumped over the lazy dog
#Вывод на экран всех строк с первой до последней.
w
51
#С помощью данной команды файл записывается на диск. Команда
#завершает сеанс редактирования.
q
Читателю это может показаться невероятным, но большая часть первоначального кода операционной системы Unix была написана с помощью данного редактора. Читатель с опытом работы в DOS может узнать в данном случае оригинал, с которого был (грубо) смоделирован редактор EDLIN.
Если задача редактора определяется, как возможность для пользователя создавать и изменять текстовые файлы, то ed(1) полностью соответствует данному определению. Многие Unix-программисты старой школы почти серьезно утверждают (а некоторые верят в это вполне серьезно), что все редакторы с большим количеством функций, чем имеет ed, являются просто раздутыми.
Уместно подчеркнуть, что редактор ed был создан Кеном Томпсоном как продуманное упрощение более раннего редактора qed [71], который был очень похожим (и был первым редактором, использующим регулярные выражения характерным для Unix способом), но имел возможность работать с несколькими буферами, намеренно отброшенную Кеном Томпсоном. Кен Томпсон решил, что данная функция не стоит дополнительной сложности.
Выдающимся свойством редактора ed(1) и всех его потомков является объектный формат его команд (в примере сеанса показан явный диапазон в команде "p"). Существует сравнительно мощный синтаксис для определения диапазонов строк либо в числовом виде, либо с помощью соответствующий регулярных выражений, либо по специальным стенографическим символам для текущей и последней строки. Большая часть операций редактора может быть применена к любому диапазону. Данный редактор представляет собой хороший пример ортогональной конструкции.
В настоящее время редактор ed(1) главным образом используется в качестве программно управляемого инструмента в сценариях. Заметим, что редакторы с более сложными режимами интерактивности для этого непригодны. Существует близкий вариант данного редактора, ех(1), в котором добавлено несколько полезных функций интерактивности, таких как приглашение на ввод команды. Он иногда полезен в редких случаях, когда редактирование необходимо осуществлять посредством медленной последовательной линии, или в необычных ситуациях восстановления системы после сбоев, когда библиотека поддержки, необходимая для работы других редакторов, не доступна. По этим причинам в каждой Unix-системе включена реализация редактора ed, а большинство систем включают в себя также редактор ex.
Потоковый редактор sed(1), упомянутый в главе 9, также близко связан с ed. Многие из основных команд аналогичны, хотя предназначены для вызова с помощью ключей командной строки, а не из стандартного ввода.
Почти все Unix-программисты достаточно отклонились от пути строгих и минималистских достоинств и обычно используют редакторы, которые, как минимум, представляют rogue-подобный экранный интерфейс. Однако тот факт, что культ ed существует, красноречиво говорит о том, что он достоин внимания при изучении Unix-стиля.
13.2.2. vi
Оригинальный редактор vi(1) был первой попыткой надстроить визуальный, rogue-подобный интерфейс на командный набор ed(1). Как и в ed, команды в редакторе vi представлены отдельными нажатиями клавиш, и он особенно хорошо подходит для операторов, владеющих машинописью.
В первоначальной версии vi отсутствовала поддержка мыши, меню редактирования, макросов, назначаемых клавиш или любой другой формы пользовательской настройки. Сохраняя приверженность культу ed, сторонники редактора vi считали отсутствие данных функций достоинством. С этой точки зрения одним из наиболее важных преимуществ vi является то, что пользователь на новой Unix-системе может немедленно приступить к редактированию без необходимости носить с собой настройки или беспокоиться о том, что стандартные привязки команд будут серьезно отличаться от привычных.
Правда одна характерная черта редактора vi не нравится начинающим пользователям. Это связано с его краткими одноклавишными командами. Редактор имеет модальный интерфейс — пользователь либо работает в командном режиме, либо в режиме вставки текста. В режиме вставки текста единственными работающими командами являются нажатия клавиши ESC для выхода из режима и (в более новых версиях) клавиши управления курсором. Ввод текста в командном режиме будет интерпретироваться как команда и приведет к случайным (и, возможно, деструктивным) действиям с содержимым файла.
С другой стороны, поклонники vi особенно восхваляют такое свойство командного набора, как объектный формат операций, унаследованный от ed. Большинство расширенных команд также позволяет естественно оперировать любым строковым диапазоном.
В течение многих лет своего существования редактор vi значительно увеличился в размерах. В современные версии включена поддержка мыши, меню редактирования, возможность отмены неограниченного числа последних операций (оригинальный vi допускал отмену только одной последней операции), возможность редактирования нескольких файлов в отдельных буферах и настройка с помощью конфигурационного файла. Однако использование конфигурационных файлов до сих пор остается необычным и, в противоположность Emacs, в vi никогда не было модным использовать встроенный универсальный язык сценариев. Вместо этого в реализациях vi развились отдельные возможности для выполнения таких операций, как подсветка синтаксиса С-кода и синтаксический анализ сообщений об ошибках C-компилятора путем добавления C-кода непосредственно в vi. Взаимодействие с подпроцессами не поддерживается.
13.2.3. Sam
Редактор Sam[113] был написан Робом Пайком в Bell Labs в середине 1980-х годов. Sam был предназначен для операционной системы Plan 9, обзор которой приводится в главе 20. Несмотря на то, что данный редактор не был широко известен за пределами Bell Labs, его предпочитали многие разработчики оригинальной Unix, которые упорно продолжали работать над Plan 9, включая самого Кена Томпсона.
Sam — явный и непосредственный потомок редактора ed и остается гораздо более близким к нему, чем vi. Sam включает в себя только две новые концепции: текстовый дисплей curses-стиля и возможность выделения текста при помощи мыши.
В каждом сеансе Sam имеется ровно одно командное окно и одно или несколько текстовых окон. В текстовых окнах редактируется текст, а командные окна принимают команды редактирования в стиле ed. Мышь используется для перемещения между окнами и для выделения диапазонов текста внутри текстовых окон. Sam представляет собой четкую, ортогональную, немодальную конструкцию, в которой устранена большая часть интерфейсной сложности vi.
Большинство команд по умолчанию оперируют с выбранным диапазоном, который можно выделить с помощью мыши. Выбор диапазона для команды также можно осуществить путем указания строкового диапазона как в ed, однако Sam получил значительное преимущество, благодаря тому факту, что пользователь может выбрать меньший диапазон, чем диапазон строки. Поскольку с помощью мыши можно осуществлять выбор и быстро перемещать фокус между буферами (включая командный буфер), Sam не нуждается в режиме, эквивалентном стандартному (командному) режиму vi. Сотни расширенных команд vi не нужны, а значит, они исключены. В целом, в редакторе Sam добавлено около десятка команд к примерно семнадцати командам vi, и общее количество команд равно примерно тридцати.
Четыре из новых команд в Sam присоединяются к двум унаследованным от ed(1) и vi(1), как способы применения регулярных выражений в целях выбора обрабатываемых файлов и диапазонов. Эти команды обеспечивают в командном языке ограниченные, но эффективные возможности организации циклов и условных операций. Однако не существует способа для именования или записи в параметрической форме процедур командного языка. Командный язык также не может выполнять интерактивное управление подпроцессом.
Интересной особенностью Sam является то, что он разделен на две части. Серверная часть, которая манипулирует файлами и выполняет поиск, отделена от клиентской части, поддерживающей экранный интерфейс. Данный образец модели "разделения ядра и интерфейса" обладает непосредственным преимуществом — несмотря на то, что программа имеет GUI-интерфейс, она может легко работать на медленном соединении при редактировании файлов на удаленном сервере. Кроме того, клиентская и серверная части могут сравнительно просто перенастраиваться.
Sam, как недавно появившиеся версии vi, обладает функцией бесконечной отмены последних операций. Конструктивно данный редактор не поддерживает ни редактирование текста в расширенном формате, ни синтаксический анализ вывода, ни взаимодействие с подпроцессами.
13.2.4. Emacs
Emacs, без сомнения, самый мощный из существующих редакторов для программистов. Он представляет собой большую, изобилующую различными функциями программу с большой гибкостью и возможностью настройки. Как отмечается в разделе "Emacs Lisp" главы 14, Emacs обладает целым встроенным языком программирования, который может применяться для написания неограниченно мощных функций редактирования.
В отличие от vi, Emacs не имеет режимов интерфейса. Вместо этого команды обычно представлены управляющими символами или предваряются нажатием клавиши ESC. Однако в Emacs возможно связать почти любую клавиатурную последовательность с какой-либо командой, а командами могут быть стандартные или специально написанные Lisp-программы.
Emacs способен редактировать несколько файлов, каждый в отдельном буфере, и поддерживает перемещение текста между буферами. Версии программы, работающие в системе X, обладают собственной поддержкой мыши.
Lisp-программы, связанные с командами Emacs, могут осуществлять производные трансформации текста в буфере. Данная возможность интенсивно используется вместе с другими средствами для определения подсветки синтаксиса и режимов редактирования текста в расширенном формате для десятков различных языков и форматов разметки (начиная с поддержки и выделения цветом C-кода, как в vi, но далеко выходя за эти рамки). Каждый режим представляет собой просто библиотечный файл или Lisp-код, загружаемый по запросу.
Программы на Emacs Lisp способны также интерактивно управлять произвольными подпроцессами. Некоторые примечательные следствия данной возможности были перечислены ранее, включая способность служить в качестве клиентской части для систем контроля версий, отладчиков и тому подобных программ.
Разработчики Emacs[114] создали программируемый редактор, который может иметь развитые логические возможности, которые можно настраивать в нем для сотен различных специализированных задач редактирования. В результате Emacs поддерживает обработку в одном общем контексте всех текстовых данных — файлы, почта, новости, отладочные символы. Данный редактор может служить в качестве настраиваемой клиентской части для любой команды, имеющей интерактивный текстовый интерфейс.
Среди сторонников и противников Emacs бытует анекдот, описывающий его как операционную систему, замаскированную под редактор. Это преувеличение, однако Emacs действительно исполняет роль, отведенную интегрированным средам разработки (Integrated Development Environments — IDE) в He-Unix-системах (рассмотрение данной темы продолжено в главе 15).
Но перечисленные преимущества сопряжены с некоторыми сложностями. Для того чтобы использовать настроенный Emacs, пользователю необходимо иметь при себе Lisp-файлы, определяющие персональные настройки редактора. Изучение настройки Emacs — целое искусство. Соответственно, Emacs сложнее в изучении, чем редактор vi.
13.2.5. Wily
Редактор wily[115] — клон редактора acme[116] из операционной системы Plan 9. Он имеет некоторые общие средства с Sam, но предусмотрен для пользователей с фундаментально отличающимися навыками. Хотя wily, вероятно, распространен менее чем любой другой из рассматриваемых редакторов, он интересен тем, что иллюстрирует отличающийся и, возможно, более близкий к Unix способ реализации Emacs-подобного программируемого редактора.
Редактор wily можно описать как минималистскую IDE-среду, реализацию расширяемости в Emacs-стиле без десятков излишних функций. В Wily даже глобальный поиск и замена, которые являются обязательным условием для Unix-редакторов, осуществляются внешними программами. Встроенные команды связаны почти исключительно с оконными операциями. В конструкции редактора Wily максимальное использование мыши предусмотрено изначально.
Wily пытается заменить не только традиционные редакторы, но также и традиционные терминальные окна, такие как xterm(1). В данном редакторе любой блок текста внутри главного окна (которое содержит множество не перекрывающихся окон Wily) может интерпретироваться как действие или выражение для поиска. Левая кнопка мыши используется для выделения текста, средняя — для выполнения текста как команды (встроенной либо внешней), а правая — для поиска текста либо в буферах редактора, либо в файловой системе. Никаких постоянных или всплывающих окон не требуется.
В редакторе Wily клавиатура используется только для ввода текста. Клавиатурные комбинации реализуются не с помощью специального использования клавиатуры, а одновременным нажатием нескольких клавиш мыши. Данные клавиатурные комбинации всегда эквивалентны использованию средней кнопки для какой-либо встроенной команды.
Wily также может применяться в качестве клиентской части для C-, Python- или Perl-программ, сообщая им всякий раз при изменении окна, выполнении команды или поиска с помощью мыши. Данные подключаемые подпрограммы функционируют аналогично режимам Emacs, но не выполняются в адресном пространстве Wily. Вместо этого они сообщаются с редактором посредством очень простого набора удаленных вызовов процедур. Wily поставляется в одном пакете с аналогом xterm и средством обработки почты, которое использует его как пользовательский интерфейс для редактирования текста.
Так как Wily серьезно зависит от мыши, он не может применяться ни в консольных символьных дисплеях, ни на удаленном канале без передачи X-данных. Как редактор, Wily предназначен для редактирования простого текста. В нем имеется только два шрифта (один пропорциональный и один моноширинный) и отсутствует механизм для поддержки редактирования расширенного текстового формата или подсветки синтаксиса.
13.3. Необходимый и достаточный размер редактора
Ниже приведен анализ учебных примеров с использованием категорий сложности, сформулированных в начале данной главы.
13.3.1. Идентификация проблем сложности
В каждом текстовом редакторе присутствует определенный уровень необходимой сложности. Как минимум, редактор должен поддерживать во внутреннем буфере копию файла или файлов, редактируемых пользователем в текущий момент. Минимальным требованием являются функции для импорта и экспорта файлов данных (обычно с диска и на диск, хотя потоковый редактор sed(1) является примечательным исключением). Необходима поддержка какого-либо способа модификации буфера, однако этот способ невозможно определить без описания специфических функций, которые являются необязательными. За рамками описанных функций четыре рассмотренных выше примера демонстрируют широкий диапазон отличий в уровнях необязательной и случайной сложности.
Из всех рассмотренных редакторов ed(1) обладает наименьшей сложностью. Почти единственной неортогональной функцией в его командном наборе является то, что многие его команды могут принимать суффиксы "р" или "]" для распечатки или вывода результатов выполнения. Даже после трех десятилетий добавления функций существует менее тридцати команд редактирования, а обычный рабочий набор большинства пользователей включает в себя не многим более десятка команд. Не многое можно удалить из редактора в части необязательной сложности, а случайную сложность вообще трудно идентифицировать. Пользовательский интерфейс редактора ed строго компактен.
Оборотной стороной этого является то, что интерфейс редактора ed не вполне подходит даже для таких базовых задач редактирования, как быстрый просмотр текстового файла. Пользователю необходимо довольно жестко ограничить свои цели, для того чтобы ed оказался приемлемым решением для интерактивного редактирования.
Предположим, что в качестве цели добавляется "поддержка визуального просмотра и редактирования множества файлов". В этом случае редактор Sam кажется не очень далеким от минимального ed-расширения, которое могло бы достичь данной цели. Примечателен тот факт, что разработчики не изменили семантики унаследованных ed-команд. Они сохранили существующий, ортогональный набор возможностей и добавили сравнительно небольшое число новых, которые сами по себе являются ортогональными.
Одним крупным увеличением необязательной сложности (сложности реализации) является имеющаяся в редакторе Sam возможность отмены неограниченного числа операций. Другой значительный фактор — новое средство организации циклов и взаимодействия на основе регулярных выражений в командном языке редактора. Данные свойства, а также тот факт, что мышь можно использовать как устройство выбора, — это почти все, что отличает Sam от гипотетического ed с оконным интерфейсом и возможностью использования мыши.
На уровне конструкции в Sam трудно идентифицировать какую-либо случайную сложность, однако в этом нельзя быть уверенным без всестороннего аудита кода. Интерфейс является, как минимум, полукомпактным, а возможно, и строго компактным. Данный редактор функционирует в соответствии с высочайшими стандартами Unix-проектирования, что не удивительно, учитывая его происхождение.
В противоположность Sam, редактор vi выглядит довольно раздутым и недоработанным. В vi имеются сотни команд, многие из которых дублируются, что в лучшем случае является необязательной сложностью, а возможно, и случайной. Предположительно, большинству пользователей известно не более 5 % командного набора. При сравнении данного редактора с примером Sam возникает закономерный вопрос: почему сложность интерфейса vi настолько высока?
В главе 11 описан результат отсутствия стандартных клавиш перемещения курсора в ранних rogue-подобных программах. Редактор vi был одной из таких программ. Когда он появился, его автор знал, что многим пользователям понадобится возможность использовать традиционные для экранных телетайпов Unix клавиши перемещения курсора. Это сделало модальный интерфейс неизбежным. Как только клавиши h, j, k и l получили зависимые от режима значения в буфере редактирования, слишком быстро проявилась привычка добавлять новые команды уникальным способом.
Редактор Sam, с его зависимостью от растрового дисплея с клавишами-стрелками и мышью, может быть гораздо более четким. И является таковым.
Однако нагромождение команд vi является сравнительно поверхностной проблемой. Это интерфейсная сложность, но большинство пользователей могут проигнорировать и игнорируют ее (интерфейс является полукомпактным в том смысле, как это было определено в главе 4). Более глубокой проблемой является ловушка специального кода. За годы своего существования vi постепенно накапливал все больше встроенного узкоспециального C-кода для выполнения таких задач, которые Sam "отказывается" выполнять, а в редакторе Emacs для этих целей используются модули Lisp-кода и управление подпроцессами. Расширения vi, в отличие от расширений Emacs, не являются библиотеками, загружаемыми по мере необходимости. Пользователи постоянно расплачиваются за распухание кода. В результате различие в размерах между современными версиями редакторов vi и Emacs не такое большое, как можно было бы ожидать. В середине 2003 года на Intel-машине GNU Emacs занимал 1500 Кбайт, тогда как vim занимал 900 Кбайт. Эти 900 Кбайт хранят в себе огромную необязательную и случайную сложность.
Для приверженцев vi отсутствие встроенного языка сценариев, то есть отличие от Emacs, стало вопросом индивидуальности, центральной частью общего мифа о том, что vi является легковесным редактором. Поклонники vi любят говорить о буферах фильтрации с внешними программами и сценариями для выполнения тех задач, которые в Emacs выполняют встроенные сценарии. Однако в реальности команда "!" редактора vi не способна фильтровать меньшие диапазоны буфера редактирования, чем диапазон строк (редакторы Sam и Wily, несмотря на то, что управление подпроцессами в них развито не больше, чем в vi, способны, по крайней мере, фильтровать произвольные текстовые диапазоны, а не только диапазоны строк). Если в vi необходима поддержка файловых форматов и синтаксиса, которые отличаются в более мелких деталях (а в большинстве случаев это так), то сведения об этих форматах и синтаксисе должны быть встроены в C-код. Таким образом, вряд ли соотношение размеров кодовых баз между Emacs и vi будет улучшаться в пользу vi, а, вероятнее всего, оно будет только ухудшаться.
Emacs является достаточно большим редактором с достаточно запутанной историей, что значительно усложняет разделение его необязательной и случайной сложности. Начать можно с попытки отделения незначительных случайных свойств конструкции Emacs от ее необходимых основных элементов.
Возможно, наиболее очевидной незначительной частью конструкции Emacs является язык Emacs Lisp. Lisp существенен для работы редактора, он представляет то, что в настоящее время называется встроенным языком написания сценариев, однако если бы данным языком был Python, Java или Perl, то Emacs немногим отличался бы в своих возможностях. Однако в то время, когда был создан Emacs (в 1970-х годах), Lisp был почти единственным языком, обладающим характеристиками (включая неограниченно расширяемые типы и методику сборки мусора), которые позволяли применять его для данной задачи.
Большинство деталей обработки событий в emacs и управления растровым дисплеем (включая поддержку интернационализации) также являются случайными. В истории Emacs они привели к "великому расколу" (разветвление GNU Emacs/XEmacs), который демонстрирует тот факт, что ни одна другая часть конструкции не требует какой-либо модели событий.
С другой стороны, способность связывать произвольные последовательности событий с произвольными встроенными или определенными пользователем функциями является необходимой. Язык сценариев может измениться, как может измениться и событийная модель, однако без полиморфизма в способе их соединения конструкция Emacs была бы неузнаваемой и недееспособной. Расширения должны были бы конкурировать друг с другом за монопольное использование ограниченного множества событий, а активизация нескольких взаимодействующих режимов в одном и том же буфере была бы затруднена или невозможна.
Массивная библиотека расширений, поставляемая с Emacs, также является случайной. Способность создавать такие расширения может быть существенной, но конкретный их набор, имеющийся в настоящее время, — продукт истории и случая. Все они могут быть изменены или заменены, а в результате остался бы узнаваемый Emacs.
Однако взаимодействие с подпроцессами является необходимым свойством. Без него режимы Emacs были бы не способны реализовать ожидаемую IDE-подобную интеграцию и возможность функционировать в качестве интерфейсной части для многих различных инструментальных средств.
Поучительным является опыт небольших редакторов, клонирующих стандартные привязки клавиш и внешний вид Emacs без эмуляции его расширяемости. Существовало несколько таких клонов, наиболее известными из которых являются, вероятно, MicroEmacs и pico, однако ни один из них не получил значительного распространения.
Определение случайных и обязательных свойств в конструкции Emacs позволяет понять, какая часть ее сложности является необязательной, а какая случайной. Однако более важно то, что это позволяет увидеть за поверхностными различиями между Emacs и тремя рассмотренными ранее редакторами действительно важное: тот факт, что цели конструкции Emacs являются гораздо более широкими. Emacs претендует на роль унифицированного интерфейса для всех инструментальных средств обработки текста.
Редактор Wily представляет собой интересную противоположность Emacs. Как в случае с Sam, уровень необязательной сложности в Wily низок. Пользовательский интерфейс редактора может быть кратко, но эффективно описан на одной странице.
Однако за это изящество приходится платить. Не существует возможности привязать функции к каким-либо комбинациям клавиш или входным жестам, кроме ограниченного набора аккордов с использованием мыши. Вместо этого каждая функция редактора, кроме самых основных операций вставки и удаления текста, должна быть реализована с помощью внешней программы — в виде отдельного сценария, либо специализированного процесса-симбионта, прослушивающего входные события Wily. (Первая методика основывается на запусках внешней программы, достаточно быстрых, чтобы не вызывать заметной интерфейсной задержки, а это было совсем не так, ни в среде, где появился Emacs, ни в Unix-системах, на которые он был впервые перенесен.)
Необязательная сложность, которая в Emacs реализуется в режимах Lisp-расширений, в Wily распределена по специализированным симбионтам, каждый из которых должен быть совместимым со специальным интерфейсом сообщений данного редактора. Преимущество данного подхода заключается в то, что такие симбионты могут быть написаны на любом выбранном пользователем языке. В дополнение к этому, симбионты (ввиду того, что они запускаются вне редактора) не могут неблагоприятно повлиять друг на друга или на ядро Wily (в отличие от режимов Emacs). Недостатком является то, что сам Wily вообще не способен непосредственно взаимодействовать с обычными инструментальными средствами Unix, вызванными как подпроцессы.
Таким образом, распределенные сценарии wily не являются таким же мощным средством, как встроенный язык сценариев в Emacs. Соответственно, рамки технических требований к Wily значительно сужены. Создатели редактора, в частности, отказываются от какой бы то ни было поддержки подсвечивания синтаксиса или редактирования расширенного текстового формата, и ни Wily, ни его потомок в Plan 9, acme, не могут выполнять данные функции.
Все вышесказанное заставляет более четко сформулировать центральный вопрос данной главы: когда большие цели оправдывают создание большой программы?
13.3.2. Компромиссы не действуют
Сопоставление редакторов Sam и vi явно указывает на то, что, по крайней мере, если рассматривать редакторы, попытки достичь компромисса между минимализмом ed и всеохватывающей полнотой Emacs не имеют значительного успеха. Такие попытки предпринимались разработчиками vi, в результате редактор утратил преимущества минималистской конструкции, но не приобрел достоинств Emacs. Напротив, vi попадает в ловушку специального кода. Этой ловушки избежал редактор Wily, но он не может сравниться с мощностью Emacs и для выполнения серьезных функций требует нестандартного интерфейса сопряжения от каждого из его интерактивных симбионтов.
Очевидно, существует проблема, толкающая редакторы в направлении увеличения сложности. В случае с vi данную проблему идентифицировать не сложно: это стремление к удобству. Несмотря на то, что теоретически адекватным может быть редактор ed, весьма немногие пользователи (кроме, возможно, самого Кена Томпсона) отказались бы от экранного редактирования в стремлении препятствовать раздуванию кода.
В более широком смысле программы-посредники между пользователем и внешним миром особенно богаты функциями. В число таких программ входят не только редакторы, но и Web-браузеры, программы для чтения почты и новостей, а также другие коммуникационные программы. Все они стремятся развиваться в соответствии с законом охвата программ (Law of Software Envelopment), известным также как закон Завински, который гласит: "Каждая программа пытается расширяться до тех пор, пока не сможет читать почту. Программы, которые не могут расширяться до такой степени, заменяются теми, которые могут".
Джейми Завински (Jamie Zawinski), автор этого утверждения (и один из ведущих разработчиков Web-браузеров Netscape и Mozilla), в более широком смысле утверждает, что все действительно полезные программы склонны превращаться в нечто подобное "швейцарскому армейскому ножу". Коммерческий успех крупных, интегрированных пакетов приложений за пределами мира Unix часто подтверждает данную теорию и откровенно ставит под сомнение Unix-философию минимализма.
В пределах своей корректности закон Завински означает, что некоторые программы стремятся быть малыми, а некоторые большими, но средняя масса нестабильна. Поверхностные проблемы vi можно отнести к истории, но более глубокие являются результатом постоянной необходимости добавления функций и одновременного неприятия встроенных сценариев и функций управления подпроцессами, которые у приверженцев vi ассоциируются с чрезмерным размером программы. На другом уровне принятие двух режимов в интерфейсе (командного режима и режима вставки) открыло "банку с червями" — стало гораздо проще добавлять новые команды, не принимая во внимание их влияние на сложность конструкции в целом.
Примеры Emacs и Wily далее подсказывают, почему некоторые программы стремятся быть большими: для того, чтобы в одном контексте можно было объединить несколько связанных задач. Редактирование и контроль версий (или редактирование и обработка почты, редактирование и отладка и т.д.) являются отдельными задачами с точки зрения разработчиков, однако пользователи часто предпочитают иметь одну большую среду, позволяющую им выделять блоки текста, а не тратить время и отвлекаться, перепрыгивая между несколькими программами, каждой из которых необходимо передать одно то же имя файла или содержимое некоторого буфера обмена.
В более широком смысле предположим, что рассматривается вся Unix-среда как единое произведение сообщества. Тогда культ "небольших точных инструментов" и стремление сохранять низкий уровень сложности интерфейса и размер кодовой базы могут привести прямо к ловушке ручного труда — пользователю приходится обслуживать весь общий контекст самостоятельно, поскольку инструменты не делают этого.
Возвращаясь к специфике редакторов, Sam показывает, что конструкция vi не верна. Wily — смелая попытка предотвратить крайность Emacs, которая не достигла цели, поскольку Wily не способен поддерживать подсветку синтаксиса. Однако Wily или некоторая реализация конструктивных идей Emacs, очищенных и освобожденных от исторического груза, — возможно, правильное решение. Значение необязательной сложности зависит от целей, определяемых разработчиком, а способность распределения контекста среди всех инструментов, ориентированных на обработку текста и связанных с задачей, является весьма ценной.
13.3.3. Является ли Emacs доводом против Unix-традиции?
Традиционное для Unix видение мира, однако, настолько привязано к минимализму, что в нем не слишком хорошо различаются проблемы специализированного кода vi и необязательная сложность Emacs.
Причиной того, что vi и Emacs никогда не привлекали Unix-программистов старой школы, является то, что эти редакторы уродливы. Возможно, это обвинение — мнение "старой Unix", но если бы оно не защищало своеобразный стиль старой Unix, то "новой Unix" не существовало бы.
(Дуг Макилрой.)
Нападки пользователей vi на Emacs, наряду с нападками на vi со стороны все еще привязанных к ed радикальных представителей старой школы, — лишь эпизоды в крупном споре, противостоянии изобилия богатства и добродетелей аскетизма. Данный спор связан с конфликтом между стилями Unix старой и новой школ.
"Своеобразный стиль старой Unix" являлся отчасти следствием бедности, точно так же, как японский минимализм, — человек учится делать больше и более эффективно, имея немногое, когда у него нет другого выбора. Однако Emacs (и Unix новой школы, воссозданная на мощных PC-компьютерах и скоростных сетях) — порождение богатства.
Иной была Unix старой школы. В Bell Labs были достаточные ресурсы, поэтому Кен не был ограничен требованиями срочного создания продукта. Вспомним оправдание Паскаля за написание длинного письма ввиду того, что у него не было времени, достаточного для написания короткого.
(Дуг Макилрой.)
С тех пор Unix-программисты поддерживают традицию, в которой изящное превозносится над чрезмерным.
С другой стороны, массивная конструкция Emacs появилась не в Unix, а была создана Ричардом М. Столлменом внутри весьма отличающейся культуры, процветающей в 1970-х годах в лаборатории искусственного интеллекта (Artificial Intelligence Lab) Массачусетского технологического института (MIT). Лаборатория AI MIT была одним из богатейших подразделений академии компьютерных наук Люди учились рассматривать вычислительные ресурсы как дешевые, предвосхищая позицию, которая в течение последующих пятнадцати лет была бы нежизнеспособной в каком-либо другом месте. Столлмен был равнодушен к минимализму, он искал максимальную мощность и простор для своего кода.
Центральный конфликт в Unix-традиции всегда был и остается между двумя подходами — делать больше с меньшими ресурсами и делать больше с большими. Конфликт снова возникает во множестве различных ситуаций, часто как борьба между конструкциями, имеющими качество четкого минимализма, и конструкциями, в которых выразительность и мощь выбираются даже ценой высокой сложности. Аргументы обеих сторон ("за" или "против" Emacs) иллюстрируют данное напряжение с тех пор, как эта программа в начале 1980-х годов была впервые перенесена на Unix.
Такие же полезные и крупные программы, как Emacs, ставят Unix-программистов в неудобное положение именно потому, что они заставляют сталкиваться с этим конфликтом. Примеры таких программ подсказывают, что минимализм старой школы Unix ценен как наука, но так можно впасть в крайность догматизма.
Существует два пути решения данной проблемы. Один — отрицать, что большая программа действительно является большой. Другой путь состоит в развитии способа анализа сложности, который не является догмой.
Мысленный эксперимент с заменой Lisp и библиотек расширения дает возможность по-новому взглянуть на частое обвинение, что Emacs раздут, потому что его библиотека расширений столь велика. Возможно, это так же несправедливо, как заявление о том, что файл /bin/sh раздут, поскольку велика коллекция всех сценариев в системе. Emacs можно было бы считать виртуальной машиной или конструкцией вокруг коллекции небольших, точных инструментов (режимов), которые были написаны на Lisp.
С такой точки зрения главное отличие между shell и Emacs заключается в том, что дистрибьюторы Unix не поставляют вместе с shell все существующие в мире сценарии. Неприязнь к Emacs из-за того, что наличие в нем универсального языка выглядит как распухание кода, приблизительно столь же неразумна, как отказ от использования сценариев ввиду того, что в shell имеются условные операции и циклы. Так же как для использования shell-сценариев не требуется изучать shell, нет необходимости изучать язык Lisp, для того чтобы пользоваться редактором Emacs. Если в Emacs имеется проблема проектирования, то она связана не столько с Lisp-интерпретатором (структурная часть), сколько с тем, что библиотека режимов представляет собой беспорядочное "нагромождение исторических наростов". Однако пользователи могут пренебречь данным источником сложности, так как неиспользуемые компоненты не влияют на их работу.
Этот аргумент весьма удобен. Его можно применять к другим конструкциям, интегрирующим инструментальные средства, таким как (неудобно большие) проекты настольных интегрированных пакетов GNOME и KDE. Что-то в нем притягивает. Кроме того, не следует доверять какой-либо "перспективе", предлагающей столь искусно разрешить все сомнения. Она может оказаться рационализацией и не решить основную проблему.
Поэтому необходимо избегать крайностей отрицания или принятия того, что Emacs является полезной и большой программой — это и есть аргумент против минимализма Unix. Что кроме этого предлагает анализ видов сложности? И существует ли причина верить, что данные уроки сводятся к общим законам?
13.4. Необходимый размер программы
Для Unix-идеологии использования небольших, точных инструментов характерна скрытая двойственность; фон настолько неявный, что многие Unix-практики не замечают его или замечают не больше, чем рыба замечает воду, в которой плавает. Этим фоном являются интегрирующие структуры приложений (frameworks).
Небольшие точные инструменты в Unix-стиле сталкиваются с трудностями при совместном использовании данных, если они не находятся внутри структуры, облегчающей их взаимодействие. Emacs является примером такой структуры, а единообразное управление общим контекстом достигается ценой необязательной сложности Emacs. Практическое влияние единообразного управления общим контекстом заключается в том, что пользователь не обременен проблемами низкоуровневого присваивания имен и управления ресурсами.
В Unix старой школы единственной интегрирующей структурой были конвейеры, перенаправление и shell. Интеграция осуществлялась с помощью сценариев, а общим контекстом была (по существу) сама файловая система. Однако на этом развитие не закончилось.
Программа Emacs объединила файловую систему с множеством текстовых буферов и вспомогательных процессов, почти совершенно оставляя структуру shell позади. Редактор Wily также предполагает использование буферов и вспомогательных процессов, но содержит в себе структуру shell. Современные настольные среды предоставляют GUI-интерфейсам структуру для обмена данными и тоже оставляют структуру shell позади. Каждая интегрирующая структура приложений имеет свои сильные и слабые стороны. Структуры приложений стали "жилищами" для множества инструментальных средств — shell для сценариев, Emacs для Lisp-режимов, а настольные среды для групп приложений, обменивающихся данными в GUI как посредством технологии "перетащить и отпустить", так и с помощь более "эзотерических" способов, таких как объектные брокеры.
Это выдвигает правило минимальности: необходимо выбирать общий контекст, которым требуется управлять, и создавать настолько малые программы, насколько позволяют данные границы. То есть "так просто, как только возможно, но не проще", но основное внимание в данном случае уделяется выбору общего контекста. Правило применимо не только к структурам, но и к приложениям и программным системам.
Однако очень легко ошибиться при определении необходимых размеров общего контекста. Над разработчиком довлеет сила, выраженная законом Завински, - склонность приложений к совместному использованию контекста в целях удобства использования. Вовсе нетрудно, в конце концов, получить чрезмерный размер, слишком большое количество предположений и писать большие программы с излишней сложностью. Так, URL
mailto:(типичный пример 1990-х годов) вызвал рост количества крупных почтовых клиентов, встроенных в Web-браузеры.
Средство исправления данной тенденции приходит прямо из "священных книг" Unix — правило экономии: писать большую программу следует только в том случае, когда после демонстрации становится ясно, что ничего другого не остается, т.е. когда попытки расчленить проблему были предприняты, но потерпели неудачу. Данный принцип предполагает строгий скептицизм в отношении больших программ и стратегию, позволяющую избежать их создания: прежде всего, следует искать решение на основе небольшой программы. Если одна небольшая программа не решает задачу, необходимо попытаться создать инструментарий, состоящий из небольших взаимодействующих программ внутри существующей структуры. И только в том случае, если оба подхода оказались безуспешными, традиции Unix позволяют разработчику создать крупную программу (или новую структуру приложения), не чувствуя себя при этом побежденным сложностью проектной задачи.
При написании интегрирующей структуры приложений необходимо помнить правило разделения. Структуры приложений должны быть механизмом и заключать в себе как можно меньше политики. В большинстве случаев вообще без политики. Необходимо выделять как можно больше поведения в модули, которые используют структуру приложений. Одним из преимуществ написания или повторного использования структуры является то, что она позволяет выделить код, который в противном случае состоял бы из огромных монолитов политики, в отдельные модули, режимы или инструментальные средства, т.е. блоки, которые можно полезно комбинировать с другими.
Данные правила эмпирические, однако конфликт в сердце Unix-традиции не может быть разрешен несколькими априорными рецептами по оптимальному размеру любого заданного проекта. Обстоятельства изменяют решения, а гармония правильного мышления и хорошего стиля — основная задача разработчиков программного обеспечения. Аналогично тому, как в Дзэн путешествие является целью, "просветления" приходится каждый раз достигать заново путем повседневной практики.
Примечания:
1
Три с половиной десятилетия между 1969 и 2003 гг. — это время исторической эволюции ОС Unix, воплотившей достижения более 50 млн. человеко-лет.
4
С его именем неразрывно связаны такие понятия, как расстояние Хемминга (Hamming distance) и код Хемминга (Hamming code).
5
Джим Геттис, один из архитекторов системы X (и человек, внесший свой вклад в данную книгу), в статье "The Two-Edged Sword" [29] глубоко размышляет о том, как стиль невмешательства X может продуктивно развиваться дальше. В этом эссе представлен ряд специфических рекомендаций и выражен характерный для Unix образ мышления.
6
Другие операционной системы в общем случае копируют или клонируют Unix-реализации TCP/IP. Их ошибка заключается в том, что они обычно не заимствуют имеющиеся в Unix прочные традиции экспертной оценки, примерами которых являются такие документы, как RFC 1025 (TCP and IP Bake Off).
7
Первоначально это было сказано Стефаном С. Джонсоном (Stephen С. Johnson), который, вероятно, более известен как автор программы yacc, об оснастке TSO в операционной системе IBM MVS.
8
Здесь представлено оригинальное дополнение Пайка (см. книгу Брукса, стр. 102). Ссылка указывает на раннее издание книги "The Mythical Man-Month" [8]: "Покажите мне ваши блок-схемы, скройте таблицы, и я буду озадачен, покажите мне ваши таблицы и, скорее всего, блок-схемы мне не потребуются; они будут очевидны".
9
Джонатан Постел (Jonathan Postel) был первым редактором серии Internet-стандартов RFC и одним из главных архитекторов Internet. Памятная страница <http://www.postel.org/postel.html> поддерживается Центром Постела по экспериментальным сетям (Postel Center for Experimental Networking).
10
Полная цитата такова: "Нам следует забывать о небольшой эффективности, например, в 97% случаев: преждевременная оптимизация — корень всех зол". Сам Кнутт приписывал эту цитату Ч. Хоару (Charles Antony Richard Hoare). - Прм. авт.
11
Одним замечательным примером является статья Батлера Лампсона (Butler Lampson) "Рекомендации по проектированию компьютерных систем" (Hints for Computer System Design) [43], которые были обнаружены позднее в процессе подготовки данной книги. В статье не только выражены многие афоризмы Unix в формах, которые были открыты независимо, но и используется множество тех же ключевых фраз для их иллюстрации.
40
Закон Брукса гласит, что подключение к запаздывающему проекту новых программистов еще больше замедляет работу, В более широком смысле рост затрат и количества ошибок можно выразить квадратом числа, соответствующего количеству программистов, которые были задействованы в проекте.
41
Согласно модели Хаттона, небольшие различия в максимальном размере элемента кода, который программист может держать в краткосрочной памяти, непосредственно влияют на эффективность работы программиста.
42
В основном труде по рассматриваемой теме, а именно "Refactoring" [21], автор фактически указывает, что принципиальная цель рефакторинга состоит в усилении ортогональности. Однако ввиду недостаточно развитой концепции он может только аппроксимировать данную идею из необходимости устранения дублирования кода и других нежелательных явлений, многие из которых являются следствием нарушения ортогональности.
43
Типичным примером плохой организации кэширования является директива
rehashв csh(1); введите
man 1 cshдля получения более подробных сведений. Другой пример приведен в разделе 12.4.3.
44
Последний пример "переплетения" Unix и Дзэн приведен в приложении Г.
45
Архитектурный выбор порядка интерпретации битов в машинном слове — "обратный" и "прямой" (big-endian и little-endian). Хотя канонический адрес отсутствует, поиск в Web по фразе "On Holy Wars and a Plea for Peace" позволит найти классическую и интересную статью по данной теме.
46
Широко распространенное мнение о том, что автоинкрементная и автодекрементная функции вошли в С, поскольку они представляли машинные команды PDP-11, — это не более чем миф. Согласно воспоминаниям Денниса Ритчи, данные операции были предусмотрены в предшествующем языке В еще до появления PDP-11.
47
Наличие глобальных переменных также означает, что повторно использовать данный код невозможно, то есть, множество экземпляров в одном процессе, вероятно, препятствуют работе друг друга.
48
Много лет назад я узнал из книги Кернигана и Плоджера "The Elements of Programming Style" полезное правило: писать однострочный комментарий немедленно после прототипа функции, причем для вся без исключения функций.
49
Простейший способ сбора данных сведений заключается в анализе тег-файлов, сгенерированных с помощью таких утилит, как etags(1) или ctags(1).
50
Существует легенда о том, что в некоторых ранних системах резервирования билетов на авиарейсы для учета количества пассажиров самолета выделялся ровно 1 байт. Очевидно, они были весьма озадачены появлением Boeing 747, первого самолета, который мог разместить на борту более 255 пассажиров.
51
Файлы паролей обычно считываются один раз в течение пользовательского сеанса во время регистрации в системе, а после этого иногда утилитами файловой системы, такими как ls(1), которые должны преобразовывать числовые идентификаторы пользователей и групп в имена.
52
Не следует путать рассматриваемую здесь прозрачность конструкции с прозрачностью пикселей, которая поддерживается в PNG-изображениях.
53
Одним из пережитков этой предшествующей Unix истории является то, что Internet-протоколы обычно используют в качестве ограничителя строк последовательность CR-LF вместо принятой в Unix LF.
54
Документ RFC 3117: <ftp://ftp.frc-editor.org/in-notes/rfc3117.txt>.
55
Документ RFC 3205: <http://www.faqs.org/rfcs/rfc3205.html>.
56
См. RFC 2324 и RFC 2325 на страницах <http//www.ietf.org/rfc/rfc2324.txt> и <http//www.ietf.org/rfc/rfс2325.txt> соответственно.
57
Коллега, мыслящий экономическими категориями, комментирует: "Воспринимаемость относится к уменьшению входных барьеров, а прозрачность — к сокращению стоимости жизни в данном коде".
58
При разработке ядра Linux предпринимается множество попыток добиться воспринимаемости, включая подкаталог документации в архиве исходного кода ядра и значительное количество учебных пособий на Web-сайтах и в книгах. Скорость, с которой изменяется ядро, препятствует этим попыткам — документация хронически отстает.
59
Возвратное тестирование (regression testing) представляет собой метод для обнаружения ошибок, появляющихся по мерс модификации программного обеспечения. Оно состоит в периодической проверке вывода изменяющегося программного обеспечения для некоторого фиксированного тестового ввода по сравнению со снимком вывода, взятого на ранней стадии данного процесса. Известно (или предполагается) что данный снимок корректен.
60
Фактически переменная
TERMустанавливается системой во время регистрации пользователя. Для реальных терминалов на последовательных линиях преобразование из tty-строк в значения TERM, устанавливается из системного конфигурационного файла во время загрузки системы; детали весьма различаются в разных Unix-системах. Эмуляторы терминалов, такие как xterm(1), устанавливают данную переменную самостоятельно.
61
Ранним предком таких проверочных программ в операционной системе Unix была утилита lint, программа проверки C-кода, обособленная от компилятора С. Хотя GCC включает в себя ее функции, приверженцы старой школы Unix до сих пор склонны называть процесс запуска такой программы "линтингом" (linting), а ее имя сохранилось в названии таких утилит, как xmllint.
62
Инвариантным является свойство конструкции программного обеспечения, которое сохраняется при каждой операции в нем. Например, в большинстве баз данных инвариантным свойством является то, что никакие две записи не могут иметь один и тот же ключ. В С-программе, корректно обрабатывающей строки, каждый строковый буфер должен содержать завершающий NUL-байт на выходе из каждой строковой функции. В системах инвентаризации пи один счетчик частей не может быть отрицательным.
63
См. результаты, приведенные в "Improving Context Switching Performance of Idle Tasks under Linux" [1].
64
setuid-программа выполняется не с привилегиями вызвавшего ее пользователя, а с привилегиями владельца исполняемого файла. Эту особенность можно использовать для предоставления ограниченного, программно-управляемого доступа к таким элементам, как файлы паролей, непосредственное изменение которых должно быть разрешено только администраторам.
65
То есть, лучшие достижения, выраженные в количестве прорывов безопасности относительно общего времени работы в Internet.
66
Распространенная ошибка в программировании с созданием подоболочек заключается в том, что программист забывает блокировать сигналы в родительском процессе при работающем подпроцессе. Без такой предосторожности прерывание подпроцесса может иметь нежелательные побочные эффекты для родительского процесса.
67
По сути, это излишнее упрощение. Дополнительная информация представлена при обсуждении переменных
EDITORи
VISUALв главе 10.
68
В справочной странице less(1) сказано, что less противоположна more.
69
Распространенная ошибка заключается в использовании вместо
“$@”выражения
$*. Это приводит к негативным последствиям при передаче имени файла, содержащего пробелы.
70
Стандартный ввод и стандартный вывод программы qmail-popup представляют собой сокеты, а стандартная ошибка (дескриптор файла 2) отправляется в log-файл. Гарантируется, что дескриптор файла 3 будет следующим выделенным дескриптором. В одном печально известном комментарии к ядру было сказано: "Никто и не ждет, что вы это поймете".
71
Коллега, порекомендовавший этот учебный пример, прокомментировал его так: "Да, можно выйти из положения с помощью этой методики..., если имеется всего несколько легко распознаваемых блоков информации, поступающих обратно от подчиненного процесса, а также есть щипцы и противорадиационный костюм".
72
Особенно опасным вариантом этой атаки является вход в именованный Unix-сокет, где программы, создающие и использующие данные, пытаются найти временный файл.
73
"Конкуренция" (race condition) представляет собой класс проблем, в которых корректное поведение системы зависит от двух независимых событий, происходящих в правильном порядке, однако отсутствует механизм, для того чтобы гарантировать фактическое возникновение этих событий. Конкуренция приводит к появлению периодических проблем с временной зависимостью, которые могут создавать значительные трудности при отладке.
74
Средство STREAMS было гораздо более сложным. Деннису Ритчи приписывают следующее высказывание: "Слово "streams" означает нечто другое, если его прокричать".
75
Разработчики основного конкурирующего с GNOME пакета KDE вначале использовали технологию CORBA, но отказались от нес в версии 2.0. С тех пор они ищут более легковесные IPC-методы.
76
Лес Хаттон в письме, где речь идет о его очередной книге, Software Failure, сообщает: "Если для измерения плотности дефектов учитывать только выполняемые строки, то плотность дефектов в зависимости от языка почти на порядок меньше плотности дефектов в зависимости от квалификации инженера".
77
Для менее технически подготовленных читателей: скомпилированная форма C-программы производится из ее исходного C-кода путем компиляции и связывания. PostScript-версия troffрументов troff-документа является производной от исходного troff-кода; чтобы осуществить это преобразование используется команда troff. Существует множество других видов производных. Почти все они могут быть выражены с помощью make-файлов.
78
Любой язык Тьюринга мог бы теоретически использоваться для универсального программирования и теоретически является в точности таким же мощным, как любой другой язык Тьюринга. На практике некоторые языки Тьюринга были бы слишком сложными для использования за пределами специфической или узкой предметной области.
79
Стандарт POSIX для регулярных выражений вводит некоторые символьные диапазоны, такие как
[[:lower:]]и
[[:digit:]]. Кроме того, отдельные специфические средства используют дополнительные символы-шаблоны, не описанные здесь. Однако для интерпретации большинства регулярных выражений приведенных примеров достаточно.
80
Для тех, кто не является Unix-программистом: инструментарий X представляет собой графическую библиотеку, которая предоставляет GUI-объекты (такие как надписи, кнопки и выпадающие меню) подключенным к ней программам. В большинстве других операционных систем с графическим интерфейсом предоставляется только один инструментарий, используемый всеми. Unix и сервер X поддерживают несколько инструментариев. Это является частью разделения политики и механизма, которое в главе 1 было названо целью проектирования X-сервера. GTK и Qt являются двумя наиболее популярными X-инструментариями с открытым исходным кодом.
81
Однако неочевидно, что XSLT мог бы быть несколько проще при тех же функциональных возможностях, поэтому его нельзя охарактеризовать как плохую конструкцию.
82
Концепции и практическое применение XSL <http://nwalsh.com/docs/tutorials/xsl/xsl/slides.html>.
83
http://www.netlib.org/
84
Включать собственные иллюстрации как примеры кода также весьма традиционно для книг по Unix, в которых описывается программа pic(1).
85
# Цитата принадлежит Алану Перлису (Alan Perils), который провел ряд передовых работ по модульности программного обеспечения приблизительно в 1970 году. Двоеточие в данном случае означало разделитель или ограничитель операторов в различных потомках языка Algol, включая Pascal и С.
86
Для читателей, никогда не программировавших на современных языках сценариев: словарь представляет собой таблицу поиска связей ключ-значение, часто реализуемую посредством хэш-таблицы. C-программисты тратят большую часть времени кодирования, реализуя словари различными сложными способами.
87
Когда-то я сам был мастером awk, но кто-то напомнил мне, что данный язык применим к проблеме создания HTML-документов, поэтому единственный awk-пример в данной книге связан именно с ней.
88
Существует сайт проекта GhostScript <http://www.cs.wise.edu/~ghost/>.
89
Первое руководство по PostScript <http://www.cs.indiana.edu/docproject/programming/postscript/postscript.html>.
90
Реализации JavaScript с открытыми исходными кодами на С и Java доступны на сайте <http://www.mozilla.org/js/>.
91
16 20 миллионов — сдержанная оценка, основанная на графиках Linux Counter и других источниках по состоянию на середину 2003 года.
92
17 Программа Kmail, которая рассматривалась в главе 6, по этой причине даже не отслеживает внешние ссылки в HTML-документах.
93
Дальнейшее развитие этой точки зрения приведено в книге [3].
94
Языки сценариев часто решают данную проблему более изящно, чем С. Для того чтобы понять, как именно они это делают, следует изучить методику потоковых документов (here documents) в shell и конструкцию тройных кавычек в Python.
95
Здесь CGI означает не Computer Graphic Imagery, а технологию Common Gateway Interface (интерфейс общего шлюза), которая применяется для создания интерактивных Web-документов.
96
Для отображения скрытых файлов используется параметр -а утилиты ls(1).
97
Суффикс "rc" связан с системой, предшествующей Unix, CTSS. В ней присутствовала функция сценария команд, которая называлась "runcom". В ранних Unix-системах имя "rc" использовалось для загрузочного сценария операционной системы как дань runcom в CTSS.
98
Никто не знает действительно изящного способа представить эти распределенные данные о настройках. Переменные среды, вероятно, не являются этим способом, однако для всех известных альтернатив характерны одинаково неприятные проблемы.
99
4 В действительности, большинство Unix-программ вначале проверяют переменную
VISUAL, и только если она не установлена, обращаются к переменной EDITOR. Это пережиток того времени, когда пользователи имели различные настройки для строковых и визуальных редакторов.
100
См. стандарты GNU-программирования на странице <http://www.gnu.org/prep/standards.html>.
101
Файл
.xinitrcявляется аналогом каталога автозагрузки в Windows и других операционных системах.
102
Диспетчер окон (window manager) поддерживает связи между окнами на экране и запущенными заданиями. Диспетчер окон управляет такими функциями, как расположение, отображение заголовков, свертывание, развертывание, перемещение, изменение размеров и затенение окон.
103
Такой взгляд на проблему характерен для нетехнического конечного пользователя.
104
Исходные коды данной программы и других конвертеров с подобными интерфейсами доступны на странице <http://ww.cdrom.com/pub/png>.
105
Управляющая программа (harness programm) представляет собой упаковщик, предназначенный для того, чтобы предоставлять вызываемым им программам доступ к некоторому специальному ресурсу. Данный термин часто употребляется при характеристике средств тестирования, которые предоставляют тестовые нагрузки и (часто) примеры корректного вывода для проверки фактического вывода тестируемых программ.
106
СтраницаScript-Fu <http://www.xcf.Berkeley.edu/~gimp/script-fu/script-fu.html>.
107
Если в системе поддерживаются подсвечиваемые всплывающие окна, которые "мало вторгаются" между пользователем и приложением, используйте их.
108
Для читателей, не знакомых с О-нотацией: она представляет собой способ указания зависимости между средним временем выполнения алгоритма и размерами его входных данных. Алгоритм O(1) выполняется за постоянное время. Алгоритм О(n) выполняется за время, которое можно вычислить по формуле: An + С, где А — некоторый неизвестный постоянный коэффициент пропорциональности, а С — неизвестная константа, представляющая время установки. Линейный поиск определенного значения в списке представляет собой алгоритм типа О(n). Алгоритм О(n²) выполняется за время An² плюс величина более низкого порядка (которая может быть линейной либо логарифмической или любой другой функцией ниже квадратичной). Поиск повторяющихся значений в списке (примитивным методом, без сортировки списка) является алгоритмом О(n²). Аналогично, алгоритмы порядка О(n³) имеют среднее время выполнения, вычисляемое по кубической формуле. Такие алгоритмы часто слишком медленны для практического применения. Порядок O(log n) типичен для поиска по дереву. Взвешенный выбор алгоритма часто может сократить время выполнения с O(п²) до О(log n). Иногда, когда требуется рассчитать использование алгоритмом памяти, можно заметить, что оно изменяется как O(1) или О(n), или O(n²). Как правило, алгоритмы с использованием памяти О(n²) или более высокого порядка являются непрактичными.
109
Удвоение мощности в течение каждых 18 месяцев, обычно цитируемое в контексте закона Мура, подразумевает, что можно достичь 26% прироста производительности просто путем приобретения нового аппаратного обеспечения через 6 месяцев.
110
Термины, введенные здесь для обозначения проблем проектирования, происходят из устоявшегося жаргона хакеров, описанного в книге [66].
111
Разделение случайной и необязательной сложности означает, что рассматриваемые здесь категории не являются тем же, что сущность и случайность в очерке Фреда Брукса "No Silver Bullet" [8], однако в философском смысле они имеют одинаковое происхождение.
112
Молодые читатели могут не знать, что раньше терминалы печатали (на бумаге и очень медленно).
113
http://plan9.bell-labs.com/sys/doc/sam/sam.html
114
Разработчиками Emacs были Ричард М. Столлмен (Richard М. Stallman) и Берни Гринберг (Bernie Greenberg). Первоначальный редактор Emacs был изобретением Столлмена, первая версия со встроенным языком Lisp была создана Гринбергом, а окончательная на сегодняшний день версия создана Столлменом на основе версии Гринберга. К 2003 году нет полного изложения истории разработки редактора, но эту тему освещает статья Гринберга "Multics Emacs: The History, Design, and Implementation", которую можно найти в Web по ключевым словам.
115
http://www.cs.yorku.ca/~oz/wily
116
http://plan9.bell-labs.com/sys/doc/acme/acme.html
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх