|
||||||||||||||||||||||||||||
|
|
Глава 7Управление данными В предыдущих главах мы касались темы ограниченности ресурсов. В этой главе мы собираемся рассмотреть сначала способы управления распределением ресурсов, затем методы обработки файлов, к которым обращается много пользователей примерно в одно и то же время, и наконец, одно средство, предоставляемое в системах Linux и позволяющее преодолеть ограничения простых файлов как среды хранения данных. Мы можем представить все эти темы как три способа управления данными: □ управление динамической памятью: что делать и что Linux не разрешит делать; □ блокировка файлов: совместная блокировка, блокируемые области совместно используемых файлов и обход взаимоблокировок; □ база данных dbm: базовая, основанная не на запросах SQL библиотека базы данных, присутствующая в большинстве систем Linux. Управляемая памятьВо всех компьютерных системах память — дефицитный ресурс. Не важно, сколько памяти доступно, ее всегда не хватает. Кажется, совсем недавно считалось, что 256 Мбайт RAM вполне достаточно, а сейчас распространено мнение о том, что 2 Гбайт RAM — это обоснованное минимальное требование даже для настольных систем, а серверам полезно было бы иметь значительно больше. У всех UNIX-подобных операционных систем, начиная с самых первых версий, был ясный подход к управлению памятью, который унаследовала ОС Linux, воплощающая стандарт X/Open. Приложениям в ОС Linux, за исключением нескольких специализированных встроенных приложений, никогда не разрешается напрямую обращаться к физической памяти. Приложению может казаться, что у него есть такая возможность, но самом деле это тщательно управляемая иллюзия. Система Linux снабжает приложения четким представлением огромной прямо адресуемой области оперативной памяти. Кроме того, она обеспечивает защиту приложений друг от друга и позволяет им явно обращаться к объему памяти, большему, чем имеющаяся физическая память в машине, хорошо настроенной и имеющей достаточную область свопинга или подкачки. Простое выделение памятиВы можете выделить память с помощью вызова mallocиз стандартной библиотеки С: #include <stdlib.h> void *malloc(size_t size); Примечание В большинстве систем Linux вы можете выделять большой объем памяти. Давайте начнем с очень простой программы из упражнения 7.1, которая, тем не менее, выигрывает соревнование со старыми программами ОС MS-DOS, поскольку они не могут обращаться к памяти за пределами базовой карты памяти ПК объемом 640 Кбайт. Упражнение 7.1. Простое распределение памятиНаберите следующую программу memory1.с: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #define A_MEGABYTE (1024 * 1024) int main() { char *some_memory; int megabyte = A_MEGABYTE; int exit_code = EXIT_FAILURE; some_memory = (char*)malloc(megabyte); if (some_memory ! = NULL) { sprintf(some_memory, "Hello World\n"); printf("%s", some_memory); exit_code = EXIT_SUCCESS; } exit(exit_code); } Когда вы выполните эту программу, то получите следующий вывод: $ ./memory1 Hello World Как это работает Данная программа запрашивает с помощью библиотечного вызова mallocуказатель на один мегабайт памяти. Вы проверяете, успешно ли завершился вызов malloc, и используете часть памяти, чтобы продемонстрировать ее наличие. Когда вы выполните программу, то увидите вывод фразы "Hello World", показывающий, что mallocдействительно вернул мегабайт используемой памяти. Мы не проверяем наличие мегабайта целиком; мы приняли на веру программный код malloc! Поскольку функция mallocвозвращает указатель типа void*, вы преобразуете результат в нужный вам указатель типа char*. Эта функция возвращает память, выровненную так, что она может быть преобразована в указатель любого типа. Простое основание — современные системы Linux применяют 32-разрядные целые и 32-разрядные указатели, что позволяет задавать до 4 Гбайт. Эта способность задавать адреса с помощью 32-разрядного указателя без необходимости применения регистров сегментов или других приемов, называется простой 32-разрядной моделью памяти. Эта модель также используется и в 32-разрядных версиях ОС Windows ХР и Vista. Тем не менее, никогда не следует рассчитывать на 32-разрядные целые, поскольку все возрастающее количество 64-разрядных версий Linux находится в употреблении. Выделение огромных объемов памятиТеперь, когда вы увидели, что ОС Linux преодолевает ограничения модели памяти ОС MS-DOS, давайте усложним ей задачу. Приведенная в упражнении 7.2 программа запрашивает выделение объема памяти, большего, чем физически есть в машине, поэтому можно предположить, что функция malloc начнет давать сбои при приближении к максимальному объему физической памяти, поскольку ядру и всем остальным выполняющимся процессам также нужна память. Упражнение 7.2. Запрос на всю физическую памятьС помощью программы memory2.с мы собираемся запросить больше памяти, чем физически есть в машине. Вам нужно откорректировать определение PHY_MEM_MEGSв соответствии с физическими ресурсами вашего компьютера. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #define A_MEGABYTE (1024 * 1024) #define PHY_MEM_MEGS 1024 /* Откорректируйте это число должным образом */ int main() { char *some_memory; size_t size_to_allocate = A_MEGABYTE; int megs_obtained = 0; while (megs_obtained < (PHY_MEM_MEGS * 2)) { some_memory = (char *)malloc(size_to_allocate); if (some_memory != NULL) { megs_obtained++; sprintf(somememory, "Hello World"); printf("%s — now allocated %d Megabytes\n", some_memory, megs_obtained); } else { exit(EXIT_FAILURE); } } exit(EXIT_SUCCESS); } Далее приведен немного сокращенный вывод: $ ./memory3 Hello World — now allocated 1 Megabytes Hello World — now allocated 2 Megabytes ... Hello World — now allocated 2047 Megabytes Hello World — now allocated 2048 Megabytes Как это работает Программа очень похожа на предыдущий пример. Это просто циклы, запрашивающие все больше и больше памяти до тех пор, пока не будет выделено памяти вдвое больше, чем заданный вами с помощью корректировки определения PHY_MEM_MEGSобъем памяти, имеющейся у вашего компьютера. Удивительно, что эта программа вообще работает, потому что мы, как оказалось, создали программу, которая использует каждый байт физической памяти на машине одного из авторов. Обратите внимание на то, что в нашем вызове mallocприменяется тип size_t. Другая интересная особенность заключается в том, что, по крайней мере, на данной машине программа выполняется в мгновение ока. Таким образом, мы не только вне сомнения использовали всю память, но и сделали это на самом деле очень быстро. Продолжим исследование и посмотрим, сколько памяти мы сможем выделить на этой машине с помощью программы memory3.c (упражнение 7.3). Поскольку уже понятно, что система Linux способна очень умно обходиться с запросами памяти, мы каждый раз будем выделять память по 1 Кбайт и записывать данные в каждый полученный нами блок. Упражнение 7.3. Доступная памятьДалее приведена программа memory3.c. По своей истинной природе она крайне недружественная по отношению к пользователю и может очень серьезно повлиять на многопользовательскую машину. Если вас беспокоит подобный риск, лучше совсем не запускать ее; если вы окажитесь от выполнения этой программы, усвоению материала это не повредит. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #define ONE_K (1024) int main() { char *some_memory; int size_to_allocate = ONE_K; int megs_obtained = 0; int ks_obtained = 0; while (1) { for (ks_obtained = 0; ks_obtained < 1024; ks_obtained++) { some_memory = (char *)malloc(size_to_allocate); if (some_memory == NULL) exit(EXIT_FAILURE); sprintf(some_memory, "Hello World"); } megs_obtained++; printf("Now allocated %d Megabytes\n", megs_obtained); } exit(EXIT_SUCCESS); } На этот раз вывод, также сокращенный, выглядит следующим образом: $ ./memory3 Now allocated 1 Megabytes ... Now allocated 1535 Megabytes Now allocated 1536 Megabytes Out of Memory: Killed process 2365 Killed После этого программа завершается. Она выполняется несколько секунд и существенно замедляется при приближении к размеру, равному объему физической памяти на компьютере, а также активно использует жесткий диск. Тем не менее программа выделяла и получала доступ к области памяти, большей по размеру объема физической памяти, которая была установлена на машине одного из авторов во время написания этой главы. В конце концов, система защищает себя от этой довольно агрессивной программы и уничтожает ее. В некоторых системах она может тихо закончить выполнение, когда функция mallocзавершается аварийно. Как это работает Память, выделяемая приложению, управляется ядром системы Linux. Каждый раз, когда программа запрашивает память, пытается записывать в память или считывать из памяти, которая была выделена, ядро Linux решает, как обрабатывать этот запрос. Сначала ядро может использовать свободную физическую память для удовлетворения запроса приложения на выделение памяти, но когда физическая память исчерпана, ядро начинает использовать так называемую область свопинга или подкачки. В ОС Linux это отдельная область диска, выделяемая во время инсталляции системы. Если вы знакомы с ОС Windows, функционирование области свопинга в Linux немного напоминает файл подкачки в Windows. Но в отличие от ОС Windows при написании программного кода не нужно беспокоиться ни о локальной, ни о глобальной динамической памяти (heap), ни о выгружаемых сегментах памяти — ядро Linux все организует для вас. Ядро перемещает данные и программный код между физической памятью и областью свопинга так, что при каждом чтении из памяти или записи в нее данные кажутся находящимися в физической памяти, где бы они не находились на самом деле перед вашей попыткой обратиться к ним. Говоря более профессиональным языком, система Linux реализует систему виртуальной памяти с подкачкой страниц по требованию. Вся память, видимая программами пользователя, — виртуальная, т. е. реально не существующая в физическом адресном пространстве, используемом программой. Система Linux делит всю память на страницы, обычно размером 4096 байтов. Когда программа пытается обратиться к памяти, выполняется преобразование виртуальной памяти в физическую, конкретный способ реализации которого и затрачиваемое на преобразование время зависят от конкретного оборудования, применяемого вами. Когда выполняется обращение к области памяти, физически нерезидентной, возникает ошибка страницы памяти и управление передается ядру. Ядро Linux проверяет адрес, к которому обратилась программа, и, если это допустимый для нее адрес, определяет, какую страницу физической памяти сделать доступной. Затем оно либо выделяет память для страницы, если она еще не записывалась ни разу, либо, если страница хранится на диске в области свопинга, считывает страницу памяти, содержащую данные, в физическую память (возможно выгружая на диск имеющуюся в памяти страницу). Затем после преобразования адресов виртуальной памяти в соответствующие физические адреса ядро разрешает пользовательской программе продолжить выполнение. Приложениям в ОС Linux не нужно заботиться об этих действиях, поскольку их реализация полностью скрыта в ядре. В итоге, когда приложение исчерпает и физическую память, и область свопинга или когда она превысит максимальный размер стека, ядро откажется выполнить запрос на дальнейшее выделение памяти, может завершить программу и выгрузить ее. Примечание Но что это означает для прикладного программиста? В основном благую весть. Система Linux очень умело управляет памятью и позволяет приложениям использовать большие области памяти и даже очень большие единые блоки памяти. Но вы должны помнить о том, что выделение двух блоков памяти в результате не приведет к формированию одного непрерывно адресуемого блока памяти. Вы получите то, что просили: два отдельных блока памяти. Означает ли этот, по-видимому, неограниченный источник памяти с последующим прерыванием и уничтожением процесса, что в проверке результата, возвращаемого функцией malloc, нет смысла? Конечно же нет. Одна из самых распространенных проблем в программах на языке С, использующих динамическую память, — запись за пределами выделенного блока. Когда это происходит, программа может не завершиться немедленно, но вы, вероятно, перезапишите некоторые внутренние данные, используемые подпрограммами библиотеки malloc. Обычный результат — аварийное завершение последующих вызовов mallocне из- за нехватки памяти, а из-за повреждения структур памяти. Такие проблемы бывает трудно отследить, и чем быстрее в программах обнаружится ошибка, тем больше шансов найти причину. В главе 10, посвященной отладке и оптимизации, мы обсудим некоторые средства, которые могут помочь вам выявить проблемы, связанные с памятью. Неправильное обращение к памятиПредположим, что вы хотите сделать что-то "плохое" с памятью. В упражнении 7.4 в программе memory4.c вы выделяете некоторую область памяти, а затем пытаетесь записать данные за пределами выделенной области. Упражнение 7.4. Неправильное обращение к вашей памяти#include <stdlib.h> #define ONE_K (1024) int main() { char *some_memory; char *scan_ptr; some_memory = (char *)malloc(ONE_K); if (some_memory == NULL) exit(EXIT_FAILURE); scan_ptr = some_memory; while (1) { *scan_ptr = '\0'; scan_ptr++; } exit(EXIT_SUCCESS); } Вывод прост: $ ./memory4 Segmentation fault Как это работает Система управления памятью в ОС Linux защищает остальную систему от подобного некорректного использования памяти. Для того чтобы быть уверенной в том, что одна плохо ведущая себя программа (как эта) не сможет повредить любые другие программы, система Linux прекратила ее выполнение. Каждая выполняющаяся в системе Linux программа видит собственную карту распределения памяти, которая отличается от карты распределения памяти любой другой программы. Только операционная система знает, как организована физическая память и не только управляет ею в интересах пользовательских программ, но также защищает их друг от друга. Указатель nullСовременные системы Linux, в отличие от ОС MS-DOS, но подобно новейшим вариантам ОС Windows, надежно защищены от записи или чтения по адресу, на который ссылается пустой указатель ( null), хотя реальное поведение системы зависит от конкретной реализации. Выполните упражнение 7.5. Упражнение 7.5. Обращение по указателюnull Давайте выясним, что произойдет, когда мы попытаемся обратиться к памяти по пустому или null-указателю в программе memory5a.c. #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main() { char *some_memory = (char*)0; printf("A read from null %s\n", some_memory); sprintf(some_memory, "A write to null\n"); exit(EXIT_SUCCESS); } Будет получен следующий вывод: $ ./memory5a A read from null (null) Segmentation fault Как это работает Первая функция printfпытается вывести строку, полученную от указателя null; далее sprintfпытается записать по указателю null. В данном случае Linux (под видом библиотеки GNU С) простила чтение и просто предоставила "магическую" строку, содержащую символы (null)\0. Система не столь терпима в случае записи и просто завершила программу. Такое поведение порой полезно при выявлении программных ошибок. Если вы повторите попытку, но не будете использовать библиотеку GNU С, вы обнаружите, что безадресное чтение не разрешено. Далее приведена программа memory5b.c: #include <unistd.h> #include <stdlib.h> #include <stdio.h> int main() { char z = *(const char *)0; printf("I read from location zero\n"); exit(EXIT_SUCCESS); } Вы получите следующий результат: $ ./memory5b Segmentation fault В этот раз вы пытаетесь прочесть непосредственно из нулевого адреса. Между вами и ядром теперь нет GNU-библиотеки libc, и программа прекращает выполнение. Имейте в виду, что некоторые системы UNIX разрешают читать из нулевого адреса, ОС Linux этого не допускает. Освобождение памятиДо сих пор мы выделяли память и затем надеялись на то, что по завершении программы использованная нами память не будет потеряна, К счастью, система управления памятью в ОС Linux вполне способна с высокой степенью надежности гарантировать возврат памяти в систему по завершении программы. Но большинство программ просто не хотят распределять память, используют ее очень короткий промежуток времени и затем завершаются. Гораздо более распространено динамическое использование памяти по мере необходимости. Программы, применяющие память на динамической основе, должны всегда возвращать неиспользованную память диспетчеру распределения памяти mallocс помощью вызова free. Это позволяет выделить блоки, нуждающиеся в повторном объединении, и дает возможность библиотеке mallocследить за памятью, вместо того, чтобы заставлять приложение управлять ею. Если выполняющаяся программа (процесс) использует, а затем освобождает память, эта освободившаяся память остается выделенной процессу. За кадром система Linux управляет блоками памяти, которые программист использует как набор физических "страниц" в памяти, размером 4 Кбайт каждая. Но если страница памяти в данный момент не используется, диспетчер управления памятью ОС Linux сможет переместить ее из оперативной памяти в область свопинга (это называется обменом страниц), где она слабо влияет на потребление ресурсов. Если программа пытается обратиться к данным на странице, которая была перенесена в область свопинга, Linux на очень короткое время приостанавливает программу, возвращает страницу обратно из области свопинга в физическую память и затем разрешает программе продолжить выполнение так, будто данные все время находились в оперативной памяти. #include <stdlib.h> void free(void *ptr_to_memory); Вызов freeследует выполнять только с указателем на память, выделенную с помощью вызова malloc, callocили realloc. Очень скоро вы встретитесь с функциями callocи realloc. А сейчас выполните упражнение 7.6. Упражнение 7.6. Освобождение памяти Эта программа называется memory6.c. #include <stdlib.h> #include <stdio.h> #define ONE_K (1024) int main() { char *some_memory; int exit code = EXIT_FAILURE; some_memory = (char*)malloc(ONE_K); if (some_memory != NULL) { free(some_memory); printf("Memory allocated and freed again\n"); exit_code = EXIT_SUCCESS; } exit(exit_code); } Вывод программы следующий: $ ./memory6 Memory allocated and freed again Как это работает Эта программа просто показывает, как вызвать функцию freeс указателем, направленным на предварительно выделенную область памяти. Примечание Другие функции распределения памятиДве другие функции распределения или выделения памяти callocи reallocприменяются не так часто, как mallocи free. Далее приведены их прототипы: #include <stdlib.h> void *calloc(size_t number_of_elements, size_t element_size); void *realloc(void *existing_memozy, size_t new_size); Несмотря на то, что функция callocвыделяет память, которую можно освободить с помощью функции free, ее параметры несколько отличаются от параметров функции malloc: она выделяет память для массива структур и требует задания количества элементов и размера каждого элемента массива как параметров. Выделенная память заполняется нулями; и если функция callocзавершается успешно, возвращается указатель на первый элемент. Как и в случае функции malloc, последовательные вызовы не гарантируют возврата непрерывной области памяти, поэтому вы не можете увеличить длину массива, созданного функцией calloc, просто повторным вызовом этой функции и рассчитывать на то, что второй вызов вернет память, добавленную в конец блока памяти, полученного после первого вызова функции. Функция reallocизменяет размер предварительно выделенного блока памяти. Она получает в качестве параметра указатель на область памяти, предварительно выделенную функциями malloc, callocили realloc, и уменьшает или увеличивает эту область в соответствии с запросом. Функция бывает вынуждена для достижения результата в перемещении данных, поэтому важно быть уверенным в том, что к памяти, выделенной после вызова realloc, вы всегда обращаетесь с помощью нового указателя и никогда не используете указатель, установленный ранее до вызова функции realloc. Другая проблема, за которой нужно следить, заключается в том, что функция reallocвозвращает пустой указатель при невозможности изменить размер блока памяти. Это означает, что в приложениях следует избегать кода, подобного приведенному далее: my_ptr = malloc(BLOCK_SIZE); ... my_ptr = realloc(my_ptr, BLOCK_SIZE * 10); Если reallocзавершится аварийно, она вернет пустой указатель; переменная my_ptrбудет указывать в никуда и к первоначальной области памяти, выделенной функцией malloc, больше нельзя будет обратиться с помощью указателя my_ptr. Следовательно, было бы полезно сначала запросить новый блок памяти с помощью malloc, а затем скопировать данные из старого блока памяти в новый блок с помощью функции memcpyи освободить старый блок памяти вызовом free. При возникновении ошибки это позволит приложению сохранить доступ к данным, хранящимся в первоначальном блоке памяти, возможно, на время организации корректного завершения программы. Блокировка файловБлокировка файлов — очень важная составляющая многопользовательских многозадачных операционных систем. Программы часто нуждаются в совместно используемых данных, обычно хранящихся в файлах, и очень важно, что у этих программ есть способ управления файлом. Файл может быть при этом безопасно обновлен или программа может пресечь свои попытки чтения файла, находящегося в переходном состоянии во время записи в него данных другой программой. У системы Linux есть несколько средств, которые можно применять для блокировки файлов. Простейший способ — блокировка файла на элементарном уровне, когда ничего не может произойти при установленной блокировке. Он предоставляет программе метод создания файлов, обеспечивающий уникальность файла и невозможность одновременного создания этого файла другой программой. Второй способ более сложный, он позволяет программам блокировать части файла для получения исключительного права доступа к ним. Есть два метода реализации этого варианта блокировки. Мы рассмотрим подробно только один из них, поскольку второй очень похож и отличается от первого немного иным интерфейсом. Создание файлов с блокировкойМногие приложения нуждаются в возможности создания ресурса в виде файла с блокировкой. Другие программы после этого могут проверить файл, чтобы узнать, есть ли у них право доступах ресурсу. Как правило, эти заблокированные файлы находятся в специальном месте и имеют имена, связанные с управляемыми ими ресурсами. Например, когда используется модем, система Linux создает файл с блокировкой, часто применяя каталог в каталоге /var/spool. Помните о том, что блокировки файлов действуют только как индикаторы; программы должны сотрудничать для их применения. Такие блокировки называют рекомендательными (advisory lock), в отличие от обязательных блокировок (mandatory lock), при которых система инициирует блокирование. Для создания файла с блокировкой (упражнение 7.7) можно использовать системный вызов open, определенный в файле fcntl.h (уже встречавшемся в предыдущих главах) и содержащий набор флагов O_CREATи O_EXCL. Этот способ позволяет проверить, не существует ли уже такой файл, и затем создать его за одну элементарную неделимую операцию. Упражнение 7.7. Создание файла с блокировкой В программе lock1.c вы сможете увидеть файл с блокировкой в действии. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <errno.h> int main() { int file_desc; int save_errno; file_desc = open("/tmp/LCK.test", O_RDWR | O_CREAT | O_EXCL, 0444); if (file_desc == -1) { save errno = errno; printf("Open failed with error %d\n", save_errno); } else { printf("Open succeeded\n"); } exit(EXIT_SUCCESS); } Выполнив программу первый раз, вы получите следующий вывод: $ ./lock1 Open succeeded Но при повторной попытке вы получите результат, приведенный далее: $ ./lock1 Open failed with error 17 Как это работает Для создания файла с именем /tmp/LCK.test программа выполняет вызов, использующий флаги O_CREATи O_EXCL. Во время первого выполнения программы файл не существует, поэтому вызов openзавершается успешно. Последующие запуски программы завершаются аварийно, потому что файл уже существует. Для успешного выполнения этой программы в дальнейшем вы должны вручную удалить файл с блокировкой. В системах Linux, ошибка 17 соответствует константе EEXIST, указывающей на то, что файл уже существует. Номера ошибок определены в файле errno.h или, скорее, в файлах, включаемых этим файлом. В данном случае определение в действительности, находящееся в /usr/include/asm-generic/errno-base.h, гласит #define EEXIST 17 /* File exists */ Это ошибка, соответствующая аварийному завершению вызова open(O_CREAT | O_EXCL). Если программе на короткий период во время выполнения, часто называемый критической секцией, нужно право исключительного доступа к ресурсу, ей следует перед входом в критическую секцию, создать файл с блокировкой с помощью системного вызова open и применить системный вызов unlinkдля удаления этого файла впоследствии, когда она завершит выполнение критической секции. Вы можете увидеть сотрудничество программ, применяющих этот механизм блокировки, написав программу-пример и запустив одновременно две ее копии (упражнение 7.8). В программе будет использован вызов функции getpid, с которой вы встречались в главе 4, она возвращает идентификатор процесса, уникальный номер для каждой выполняющейся в данный момент программы. Упражнение 7.8. Совместная блокировка файлов 1. Далее приведен исходный код тестовой программы lock2.с. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <errno.h> const char *lock_file = "/tmp/LCK.test2"; int main() { int file_desc; int tries = 10; while (--tries) { file_desc = open(lock_file, O_RDWR | O_CREAT | O_EXCL, 0444); if (file_desc == -1) { printf("%d - Lock already present\n", getpid()); sleep(3); } else { 2. Далее следует критическая секция: printf("%d — I have exclusive access\n", getpid()); sleep(1); (void)close(file_desc); (void)unlink(lockfile); 3. В этом месте она заканчивается: sleep(2); } } exit(EXIT_SUCCESS); } Для выполнения программы вам сначала нужно выполнить следующую команду, чтобы убедиться в том, что файла не существует: $ rm -f /tmp/LCK.test2 Затем с помощью приведенной далее команды запустите две копии программы: $ ./lock2 & ./lock2 Она запускает одну копию программы в фоновом режиме, а вторую — как основную программу. Далее приведен вывод: 1284 — I have exclusive access 1283 — Lock already present 1283 — I have exclusive access 1284 — Lock already present 1284 — I have exclusive access 1283 — Lock already present 1283 — I have exclusive access 1284 — Lock already present 1284 — I have exclusive access 1283 — Lock already present 1283 — I have exclusive access 1284 — Lock already present 1284 — I have exclusive access 1283 — Lock already present 1283 — I have exclusive access 1284 — Lock already present 1284 — I have exclusive access 1283 — Lock already present 1283 — I have exclusive access 1284 — Lock already present В приведенном примере показано, как взаимодействуют две выполняющиеся копии одной и той же программы. Если вы попробуете выполнить данный пример, то почти наверняка увидите другие идентификаторы процессов в выводе, но поведение программ будет тем же самым. Как это работает Для демонстрации вы 10 раз выполняете в программе цикл с помощью оператора while. Затем программа пытается получить доступ к дефицитному ресурсу, создав уникальный файл с блокировкой /tmp/LCK.test2. Если эта попытка терпит неудачу из-за того, что файл уже существует, программа ждет короткий промежуток времени и затем снова пытается создать файл. Если ей это удается, она получает доступ к ресурсу и в части программы, помеченной как "критическая секция", выполняет любую обработку, требующую исключительных прав доступа. Поскольку это всего лишь пример, вы ждете очень короткий промежуток времени. Когда программа завершает использование ресурса, она снимает блокировку, удаляя файл с блокировкой. Далее она может выполнить другую обработку (в данном случае это просто функция sleep) прежде, чем попытаться возобновить блокировку. Файлы с блокировкой действуют как двоичный семафор, давая программе ответ "да" или "нет" на вопрос: "Могу ли я использовать ресурс?". В главе 14 вы узнаете больше о семафорах. Примечание Важно уяснить, что это совместное мероприятие, и вы должны корректно писать программы для его работы. Программа, потерпевшая неудачу в создании файла с блокировкой, не может просто удалить файл и попробовать снова, Возможно, в дальнейшем она сумеет создать файл с блокировкой, но у другой программы, уже создавшей такой файл, нет способа узнать о том, что она лишилась исключительного доступа к ресурсу. Блокировка участков файлаСоздание файлов с блокировкой подходит для управления исключительным доступом к ресурсам, таким как последовательные порты или редко используемые файлы, но этот способ не годится для доступа к большим совместно используемым файлам. Предположим, что у вас есть большой файл, написанный одной программой и одновременно обновляемый многими программами. Такая ситуация может возникнуть, если программа записывает какие-то данные, получаемые непрерывно или в течение длительного периода, и обрабатывает их с помощью нескольких разных программ. Обрабатывающие программы не могут ждать, пока программа, записывающая данные, завершится — она работает постоянно, поэтому программам нужен какой-то способ кооперации для обеспечения одновременного доступа к одному и тому же файлу. Урегулировать эту ситуацию можно, блокируя участки файла. При этом конкретная часть файла блокируется, но другие программы могут иметь доступ к другим участкам файла. Это называется блокировкой сегментов или участков файла. У системы Linux есть (как минимум) два способа сделать это: с помощью системного вызова fcntlили системного вызова lockf. Мы рассмотрим интерфейс fcntl, поскольку он наиболее часто применяется. Интерфейс lockfв основном аналогичен, и в ОС Linux он используется как альтернативный интерфейсу fcntl. Однако блокирующие механизмы fcntlи lockfне работают вместе: у них разные низкоуровневые реализации. Поэтому никогда не следует смешивать вызовы этих двух типов; выберите один или другой. Вы встречали вызов fcntl в главе 3. У него следующее определение: #include <fcntl.h> int fcntl(int fildes, int command, ...); Системный вызов fcntlоперирует открытыми дескрипторами файлов и, в зависимости от параметра command, может выполнять разные задачи. Для блокировки файлов интересны три приведенные далее возможные значения параметра command: □ F_GETLK; □ F_SETLK; □ F_SETLKW. Когда вы используете эти варианты, третий аргумент в вызове должен быть указателем на структуру struct flock, поэтому на самом деле прототип вызова выглядит следующим образом:
Структура flock(он англ. file lock) зависит от конкретной реализации, но, как минимум, она будет содержать следующие элементы: □ short l_type; □ short l_whence; □ off_t l_start; □ off_t l_len; □ pid_t l_pid. Элемент l_typeпринимает одно из нескольких значений (табл. 7.1), определенных в файле fcntl.h. Таблица 7.1.
Элементы l_whence, l_startи l_lenопределяют участок файла, непрерывную область в байтах. Элемент l_whenceдолжен задаваться одним из следующих значений: SEEK_SET, SEEK_CUR, SEEK_END(из файла unistd.h). Они соответствуют началу, текущей позиции или концу файла соответственно. Элемент l_whenceзадает смещение для первого байта участка файла, определенного элементом l_start. Обычно оно задается константой SEEK_SET, поэтому l_startотсчитывается от начала файла. Параметр l_lenсодержит количество байтов в участке файла. Параметр l_pidприменяется для указания процесса, установившего блокировку; см. следующее далее описание значения F_GETLKпараметра command. Для каждого байта в файле может быть установлена блокировка только одного типа в каждый конкретный момент времени и может быть либо разделяемой блокировкой, либо исключительной или блокировка может отсутствовать. Для системного вызова fcntlсуществует совсем немного комбинаций значений команд и вариантов, поэтому рассмотрим их все по очереди. Значение F_GETLK параметра command Первое значение параметра command — F_GETLK. Эта команда получает информацию о файле, который открыт fildes(первый параметр в вызове). Она не пытается блокировать файл. В процессе вызова передаются сведения о типе блокировки, которую хотелось бы установить, и вызов fcntlс командой F_GETLKвозвращает любую информацию, которая могла бы помешать установке блокировки. Значения, используемые в структуре flock, приведены в табл. 7.2. Таблица 7.2
Процесс может применять вызов с командой F_GETLKдля определения текущего состояния блокировки участка файла. Он должен настроить структуру flock, указав тип требуемой блокировки и определив интересующую его область файла. Вызов fcntlвозвращает в случае успешного завершения значение, отличное от -1. Если у файла уже есть блокировки, препятствующие установке требуемой блокировки, структура flockобновляется соответствующими данными. Если блокировке ничто не мешает, структура flockне изменяется. Если вызов с командой F_GETLKне может получить информацию, он возвращает -1 для обозначения аварийного завершения. Если вызов с командой F_GETLKзавершился успешно (т. е. вернул значение, отличное от -1), вызвавшее его приложение должно проверить, изменено ли содержимое структуры flock. Поскольку значение l_pidсодержит идентификатор блокирующего процесса (если таковой найден), это поле очень удобно для того, чтобы проверить, изменялась ли структура flock. Значение F_SETLK параметра command Эта команда пытается заблокировать или разблокировать участок файла, заданного fildes. В табл. 7.3 приведены значения полей структуры flock(отличающиеся от значений, применяемых командой F_GETLK). Таблица 7.3
Как и в случае F_GETLK, блокируемый участок определяется значениями элементов l_start, l_whenceи l_lenструктуры flock. Если блокировка установлена, вызов fcntlвернет значение, отличное от -1, при аварийном завершении возвращается -1. Вызов завершается немедленно. Значение F_SETLKW параметра command Команда F_SETLKWаналогична команде F_SETLKза исключением того, что при невозможности установки блокировки вызов будет ждать до тех пор, пока такая возможность не представится. После перехода в состояние ожидания вызов завершится только, когда блокировка будет установлена или появится сигнал. Сигналы мы обсудим в главе 11. Все блокировки файла, установленные программой, автоматически очищаются, когда закрывается соответствующий дескриптор файла. То же самое происходит, когда программа завершается. Применение вызовов read и write при наличии блокировкиКогда вы применяете блокировку участков файла, очень важно использовать для доступа к данным низкоуровневые вызовы readи writeвместо высокоуровневых функций freadи fwrite. Это необходимо, поскольку функции freadи fwriteвыполняют внутри библиотеки буферизацию читаемых или записываемых данных, так что при выполнений вызова freadдля считывания 100 байтов из файла может быть (и на самом деле почти наверняка будет), считано более 100 байтов, и дополнительные данные помещаются во внутрибиблиотечный буфер. Если программа применит функцию freadдля считывания следующих 100 байтов, она на самом деле считает данные из буфера и не разрешит низкоуровневому вызову readизвлечь больше данных из файла. Для того чтобы понять, в чем тут проблема, рассмотрим две программы, которые хотят обновить один и тот же файл. Предположим, что файл содержит 200 байтов данных, все нули. Первая программа начинает работу и устанавливает блокировку на запись для первых 100 байтов файла. Затем она применяет функцию freadдля считывания этих 100 байтов. Однако, как было показано в одной из предшествующих глав, freadбудет каждый раз считывать больше, до BUFSIZбайтов, поэтому она на самом деле считает в память целиком весь файл, но программе вернет только первые 100 байтов. Затем стартует вторая программа. Она устанавливает блокировку writeна вторые 100 байтов файла. Это действие завершится успешно, поскольку первая программа заблокировала только первые 100 байтов. Вторая программа записывает двойки в байты с 100-го по 199-й, закрывает файл, снимает блокировку и завершается. В это время первая программа блокирует вторые 100 байтов файла и вызывает функцию freadдля их считывания. Поскольку эти данные были уже занесены библиотекой в буфер, программа увидит 100 байтов нулей, а не 100 двоек, которые на самом деле хранятся в файле на жестком диске. Подобной проблемы не возникает, если вы применяете вызовы readи write. Приведенное описание блокировки файла может показаться сложноватым, но ее труднее описать, чем применить. Поэтому выполните упражнение 7.9. Упражнение 7.9. Блокировка файла с помощью вызоваfcntl Давайте рассмотрим пример работы блокировки файла в программе lock3.с. Для опробования блокировки вам понадобятся две программы: одна для установки блокировки и другая для ее тестирования. Первая программа выполняет блокировку. 1. Начните с файлов includeи объявлений переменных: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> const char *test_file = "/tmp/test_lock"; int main() { int file desc; int byte_count; char *byte_to_write = "A"; struct flock region_1; struct flock region_2; int res; 2. Откройте файловый дескриптор: file_desc = open(test_file, O_RDWR | O_CREAT, 0666); if (!file_desc) { fprintf(stderr, "Unable to open %s for read/write\n", test_file); exit(EXIT_FAILURE); } 3. Поместите данные в файл: for (byte_count = 0; byte_count < 100; byte_count++) { (void)write(file_desc, byte_to_write, 1); } 4. Задайте разделяемую блокировку для участка region 1 с 10-го байта по 30-й: region_1.l_type = F_RDLCK; region_1.l_whence = SEEK_SET; region_1.l_start = 10; region_1.l_len = 20; 5. Задайте исключительную блокировку для участка region_2 с 40-го байта по 50-й: region_2.l_type = F_WRLCK; region_2.l_whence = SEEK_SET; region_2.l_start = 40; region_2.l_len = 10; 6. Теперь заблокируйте файл: printf("Process %d locking file\n", getpid()); res = fcntl(file_desc, F_SETLK, ®ion_1); if (res == -1) fprintf(stderr, "Failed to lock region 1\n"); res = fcntl(file_desc, F_SETLK, ®ion_2); if (res = fprintf(stderr, "Failed to lock region 2\n"); 7. Подождите какое-то время: sleep(60); printf ("Process %d closing file\n", getpid()); close(file_desc); exit(EXIT_SUCCESS); } Как это работает Сначала программа создает файл, открывает его для чтения и записи и затем заполняет файл данными. Далее задаются два участка: первый с 10-го по 30-й байт для разделяемой блокировки и второй с 40-го по 50-й байт для исключительной блокировки. Затем программа выполняет вызов fcntlдля установки блокировок на два участка файла и ждет в течение минуты, прежде чем закрыть файл и завершить работу. На рис. 7.1 показан этот сценарий с блокировками в тот момент, когда программа переходит к ожиданию. 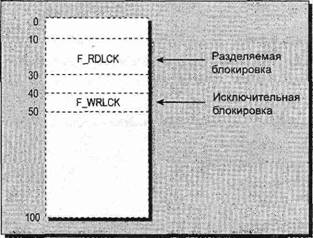 Рис. 7.1 Сама по себе эта программа не очень полезна. Вам нужна вторая программа lock4.c для тестирования блокировок (упражнение 7.10). Упражнение 7.10. Тестирование блокировок файлаВ этом примере вы напишете программу, проверяющую блокировки разных типов, установленные для различных участков файла. 1. Как обычно, начнем с заголовочных файлов и объявлений: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> const char *test_file = "/tmp/test_lock"; #define SIZE_TO_TRY 5 void show_lock_info(struct flock *to_show); int main() { int file_desc; int res; struct flock region_to_test; int start_byte; 2. Откройте дескриптор файла: file_desc = open(test_file, O_RDWR | O_CREAT, 0666); if (!file_desc) { fprintf(stderr, "Unable to open %s for read/write", test_file); exit(EXIT_FAILURE); } for (start_byte = 0; start_byte < 99; start_byte += SIZE_TO_TRY) { 3. Задайте участок файла, который хотите проверить: region_to_test.l_type = F_WRLCK; region_to_test.l_whence = SEEK_SET; region_to_test.lstart = start_byte; region_to_test.l_len = SIZE_TO_TRY; region_to_test.l_pid = -1; printf("Testing F_WRLCK on region from %d to %d\n", start_byte, start_byte + SIZE_TO_TRY); 4. Теперь проверьте блокировку файла: res = fcntl(file_desc, F_GETLK, ®ion_to_test); if (res == -1) { fprintf(stderr, "F_GETLK failed\n"); exit(EXIT_FAILURE); } if (region_to_test.l_pid != -1) { printf("Lock would fail. F_GETLK returned:\n"); showlockinfo(®ion_to_test); } else { printf("F_WRLCK - Lock would succeed\n"); } 5. Далее повторите тест с разделяемой блокировкой (на чтение). Снова задайте участок файла, который хотите проверить: region_to_test.l_type = F_RDLCK; region_to_test.l_whence = SEEK_SET; region_to_test.l_start = start_byte; region_to_test.l_len = SIZE_TO_TRY; region_to_test.l_pid = -1; printf("Testing F_RDLCK on region from %d to %d\n", start_byte, start_byte + SIZE_TO_TRY); 6. Еще раз проверьте блокировку файла: res = fcntl(file_desc, F_GETLK, ®ion_to_test); if (res == -1) { fprintf(stderr, "F_GETLK failed\n"); exit(EXIT_FAILURE); } if (region_to_test.l_pid != -1) { printf("Lock would fail. F_GETLK returned:\n"); show_lock_info(®ion_to_test); } else { printf("F_RDLCK — Lock would succeed\n"); } } close(file_desc); exit(EXIT_SUCCESS); } void show_lock_info(struct flock *to_show) { printf("\tl_type %d, ", to_show->l_type); printf("l_whence %d, ", to_show->l_whence); printf("l_start %d, (int)to_show->l_start); printf("l_len %d, ", (int)to_show->l_len); printf("l_pid %d\n", to_show->l_pid); } Для проверки блокировки сначала запустите программу lock3, затем выполните программу lock4, чтобы протестировать заблокированный файл. Сделайте это, запустив программу lock3 в фоновом режиме с помощью следующей команды: $ ./lock3 & $ process 1534 locking file На экране появится приглашение для ввода команд, поскольку lock3 выполняется в фоновом режиме. Далее сразу же запустите программу lock4 с помощью следующей команды: $ ./lock4 Вы получите вывод, приведенный далее с некоторыми пропусками для краткости: Testing F_WRLCK on region from 0 to 5 F_WRLCK — Lock would succeed Testing F_RDLCK on region from 0 to 5 F_RDLCK - Lock would succeed ... Testing F_WRLCK on region from 10 to 15 Lock would fail. F_GETLK returned: l_type 0, l_whence 0, l_start 10, l_len 20, l_pid 1534 Testing F_RDLCK on region from 10 to 15 F_RDLCK — Lock would succeed Testing F_WRLCK on region from 15 to 20 Lock would fail. F_GETLK returned: l_type 0, l_whence 0, l_start 10, l_len 20, l_pid 1534 Testing F_RDLCK on region from 15 to 20 F_RDLCK — Lock would succeed ... Testing F_WRLCK on region from 25 to 30 Lock would fail. F_GETLK returned: l_type 0, l_whence 0, l_start 10, l_len 20, l_pid 1534 Testing F_RDLCK on region from 25 to 30 F_RDLCK — Lock would succeed ... Testing F_WRLCK on region from 40 to 45 Lock would fail. F_GETLK returned: l_type 1, l_whence 0, l_start 40, l_len 10, l_pid 1534 Testing F_RDLCK on region from 40 to 45 Lock would fail. F_GETLK returned: l_type 1, l_whence 0, l_start 40, l_len 10, l_pid 1534 ... Testing F_RDLCK on region from 95 to 100 F_RDLCK - Lock would succeed Как это работает Для каждой группы из пяти байтов в файле программа lock4 задает структуру участка файла для тестирования блокировок, которую она потом применяет для определения того, может ли этот участок быть заблокирован для чтения или записи. Возвращаемая информация показывает байты, относящиеся к участку файла, смещение от нулевого байта, которое могло бы вызвать аварийное завершение запроса на блокировку. Поскольку поле l_pidвозвращаемой структуры содержит идентификатор программы, владеющей в данный момент заблокированным файлом, программа задает ему значение -1 (некорректное значение) и затем проверяет, изменилось ли оно после завершения вызова fcntl. Если участок в данный момент не заблокирован, поле l_pidне изменится. Для того чтобы понять вывод, следует заглянуть в заголовочный файл fcntl.h (обычно /usr/include/fcntl.h) и увидеть, что поле l_type, равное 1, вытекает из определения F_WRLCKкак 1, а равное 0 из определения F_RDLCKкак 0. Таким образом, поле l_type, равное 1, говорит о том, что блокировка не будет установлена, поскольку существует блокировка на запись, а поле l_type, равное 0, свидетельствует о существовании блокировки на чтение. Для тех участков файла, которые не заблокировала программа lock3, могут быть установлены и разделяемая, и исключительная блокировки. Для байтов с 10-го по 30-й возможна установка разделяемой блокировки, поскольку блокировка, установленная программой lock3, не исключительная, а разделяемая. Для участка с 40-го по 50-й байт нельзя установить оба типа блокировки, поскольку lock3 задала исключительную ( F_WRLCK) блокировку для этого участка. После завершения программы lock4 необходимо немного подождать, чтобы программа lock3 завершила вызов sleepи закончила выполнение. Конкурирующие блокировкиТеперь, когда вы увидели, как проверять существующие блокировки файла, давайте посмотрим, что произойдет, когда две программы состязаются за получение блокировки для одного и того же участка файла. Вы воспользуетесь снова программой lock3 для блокировки файла и новой программой lock5 для попытки установить новую блокировку файла. В завершение вы добавите в программу lock5 несколько вызовов для снятия блокировки (упражнение 7.11). Упражнение 7.11. Конкурирующие блокировкиДалее приведена программа lock5.с, которая пытается заблокировать уже заблокированные участки файла вместо того, чтобы проверить состояние блокировки других частей файла. После директив #include и объявлений откройте дескриптор файла. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> const char *test_file = "/tmp/test_lock"; int main() { int file_desc; struct flock region_to_lock; int res; file_desc = open(test_file, O_RDWR | O_CREAT, 0666); if (!file_desc) { fprintf(stderr, "Unable to open %s for read/write\n", test_file); exit(EXIT_FAILURE); } В оставшейся части программы задаются разные участки файла, и делается попытка установить для них блокировки разных типов: region_to_lock.l_type = F_RDLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.l_start = 10; region_to_lock.l_len = 5; printf("Process %d, trying F_RDLCK, region %d to %d\n", getpid(), (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(file_desc, F_SETLK, ®ion_to_lock); if (res == -1) { printf("Process %d - failed to lock region\n", getpid()); } else { printf("Process %d — obtained lock region\n", getpid()); } region_to_lock.l_type = F_UNLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.l_start = 10; region_to_lock.l_len = 5; printf("Process %d, trying F_UNLCK, region %d to %d\n", getpid(), (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(file_desc, F_SETLK, ®ion_to_lock); if (res == -1) { printf("Process %d — failed to unlock region\n", getpid()); } else { printf("Process %d — unlocked region\n", getpid()); } region_to_lock.l_type = F_UNLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.l_start = 0; region_to_lock.l_len = 50; printf("Process %d, trying F_UNLCK, region %d to %d\n", getpid()", (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(file_desc, F_SETLK, ®ion_to_lock); if (res == -1) { printf("Process %d — failed to unlock region\n", getpid()); } else { printf("Process %d — unlocked region\n", getpid()); } region_to_lock.l_type = F_WRLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.lstart = 16; region_to_lock.l_len = 5; printf("Process %d, trying F_WRLCK, region %d to %d\n", getpid(), (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(file_desc, F_SETLK, ®ion_to_lock); if (res == -1) { printf("Process %d — failed to lock region\n", getpid()); } else { printf("Process %d — obtained lock on region\n", getpid()); } region_to_lock.l_type = F_RDLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.l_start = 40; region_to_lock.l_len = 10; printf("Process %d, trying F_RDLCK, region %d to %d\n", getpid(), (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(filedesc, F_SETLK, ®ion_to_lock); if (res == -1) { printf("Process %d — failed to lock region\n", getpid()); } else { printf("Process %d — obtained lock on region\n", getpid()); } region_to_lock.l_type = F_WRLCK; region_to_lock.l_whence = SEEK_SET; region_to_lock.l_start = 16; region_to_lock. l_len = 5; printf("Process %d, trying F_WRLCK with wait, region %d to %d\n", getpid(), (int)region_to_lock.l_start, (int)(region_to_lock.l_start + region_to_lock.l_len)); res = fcntl(file_desc, F_SETLKW, ®ion_to_lock); if (res == -1) { printf("Process %d — failed to lock region\n", getpid()); } else { printf("Process %d — obtained lock, on region\n", getpid()); } printf ("Process %d ending\n", getpid()); close(file_desc); exit(EXIT_SUCCESS); } Если вы сначала запустите программу lock3 в фоновом режиме, далее сразу запускайте новую программу: $ ./lock3 & $ process 227 locking file $ ./lock5 Вы получите следующий вывод: Process 227 locking file Process 228, trying F_RDLCK, region 10 to 15 Process 228 — obtained lock on region Process 228, trying F_UNLCK, region 10 to 15 Process 228 — unlocked region Process 228, trying F_UNLCK, region 0 to 50 Process 228 — unlocked region Process 228, trying F_WRLCK, region 16 to 21 Process 228 — failed to lock on region Process 228, trying F_RDLCK, region 4 0 to 50 Process 228 - failed to lock on region Process 228, trying F_WRLCK with wait, region 16 to 21 Process 227 closing file Process 228 — obtained lock on region Process 228 ending Как это работает Сначала программа пытается заблокировать участок с 10-го по 15-й байты с помощью разделяемой блокировки. Эта область уже заблокирована блокировкой того же типа, но одновременные разделяемые блокировки допустимы, и установка блокировки завершается успешно. Затем программа снимает свою разделяемую блокировку с участка файла, и эта операция тоже завершается успешно. Далее она пытается разблокировать первые 50 байтов файла, даже если у них нет никакой блокировки. Это действие тоже завершается успешно, потому что, несмотря на то, что программа не установила блокировок на этот участок, конечный результат запроса на снятие блокировки заключается в констатации того, что для первых 50 байтов данная программа не поддерживает никаких блокировок. Далее программа пытается заблокировать участок с 16-то по 21-й байты исключительной блокировкой. Эта область уже заблокирована разделяемой блокировкой, поэтому новая попытка блокировки завершается аварийно, т.к. не может быть создана исключительная блокировка. После этого программа пробует установить разделяемую блокировку на участок с 40-го по 50-й байты. Эта область уже заблокирована исключительной блокировкой, поэтому данная операция снова завершается аварийно. В заключение программа опять пытается получить исключительную блокировку для участка с 16-го по 21-й байты, но в этот раз она применяет команду F_SETLKW, позволяющую ждать до тех пор, пока блокировка не будет установлена. В выводе наступает долгая пауза, длящаяся, пока программа lock3, заблокировавшая этот участок, завершает вызов sleepи закрывает файл, тем самым снимая все установленные блокировки. Программа lock5 возобновляет выполнение, успешно блокирует участок файла и затем тоже завершается. Другие команды блокировокЕсть второй метод блокировки файлов — функция lockf. Она тоже действует, используя дескрипторы файлов. У функции следующий прототип: #include <unistd.h> int lockf(int fildes, int function, off_t size_to_lock); Параметр functionможет принимать следующие значения: □ F_ULOCK— разблокировать; □ F_LOCK— заблокировать монопольно; □ F_TLOCK— проверить и заблокировать монопольно; □ F_TEST— проверить наличие блокировок других процессов. Параметр size_to_lockсодержит количество обрабатываемых байтов, отсчитываемых в файле от текущей величины смещения. У функции lockfболее простой интерфейс, чем у вызова fcntlв основном потому, что у нее меньше функциональных возможностей и гибкости. Для применения функции вы должны найти начало участка, который хотите заблокировать, затем вызвать функцию, указав количество блокируемых байтов. Как и в случае вызова fcntl, все блокировки только рекомендательные; они на самом деле не могут помешать чтению из файла или записи в файл. За проверку имеющихся блокировок отвечают программы. Эффект от смешивания блокировок с помощью fcntlи блокировок с помощью lockfнепредсказуем, поэтому вам следует решить, какой способ выбрать, и строго его придерживаться. ВзаимоблокировкиОбсуждение блокировок не было бы законченным без упоминания об опасности взаимоблокировок или тупиков. Предположим, что две программы хотят обновить один и тот же файл. Им обеим нужно обновить байт 1 и байт 2 одновременно. Программа А выбирает первым обновление байта 2, затем байта 1. Программа В пытается обновить сначала байт 1, затем байт 2. Обе программы стартуют одновременно. Программа А блокирует байт 2, а программа В — байт 1. Программа А пытается установить блокировку для байта 1. Поскольку он уже заблокирован программой В, программа А ждет. Программа В пытается заблокировать байт 2. Поскольку он уже заблокирован программой А, программа В тоже ждет. Ситуация, в которой ни одна программа не может выполняться, называется взаимоблокировкой или тупиковой ситуацией. Эта проблема очень распространена в работающих с базами данных приложениях, в которых многие пользователи часто пытаются получить доступ к одним и тем же данным. Многие коммерческие реляционные базы данных обнаруживают взаимоблокировки и устраняют их автоматически; ядро Linux этого не делает. Для устранения возникшего непорядка требуется внешнее вмешательство, возможно, принудительно завершающее выполнение одной из программ. Программистам стоит опасаться подобных ситуаций. Если у вас есть несколько программ ждущих установки блокировок, нужно быть очень внимательным и рассмотреть возможность возникновения тупиковой ситуации. В данном примере этого легко избежать: обе программы просто должны блокировать нужные им байты в одном и том же порядке или использовать область большего размера для блокировки. Примечание Базы данныхВы научились использованию файлов для хранения данных, зачем применять для этого базы данных? Очень просто, в некоторых обстоятельствах средства баз данных предоставляют лучший способ решения проблем. Применение базы данных лучше, чем хранение файлов, по двум причинам: □ вы можете хранить записи данных переменного размера, что довольно трудно реализовать с помощью простых неструктурированных файлов; □ базы данных эффективнее хранят и извлекают данные, применяя индекс. Это большое преимущество, потому что этот индекс должен быть не просто номером записи, который легко было бы реализовать в обычном файле, а произвольной строкой. База данных dbmВсе версии Linux и большая часть вариантов систем UNIX поставляются с базовым, но очень эффективным набором подпрограмм для хранения данных, называемым базой данных dbm. База данных dbm отлично подходит для хранения индексированных данных, которые относительно статичны. Некоторые консерваторы в области баз данных могут возразить, что dbm — вовсе не база данных, а просто система хранения индексных файлов. Стандарт X/Open, тем не менее, называет dbm базой данных, поэтому в книге мы будем продолжать называть ее так же. Введение в базу данных dbmНесмотря на взлет свободно распространяемых реляционных баз данных, таких как MySQL и PostgreSQL, база данных dbm продолжает играть важную роль в системе Linux. Дистрибутивы, использующие RPM, например, Red Hat и SUSE, применяют dbm как внутреннее хранилище для данных устанавливаемых пакетов. Реализация LDAP с открытым кодом, Open LDAP (Lightweight Directory Access Protocol, облегченный протокол доступа к каталогу), также может применять dbm как механизм хранения. Преимущества dbm по сравнению с более сложными базами данных, такими как MySQL, в ее "легковесности" и возможности более простого встраивания в распределенный двоичный код (distributed binary), поскольку не требуется установка отдельного сервера базы данных. Во время написания книги программы Sendmail и Apache использовали dbm. База данных dbm позволяет хранить структуры данных переменного размера с помощью индекса и затем извлекать структуру либо используя индекс, либо просто последовательно просматривая базу данных. Базу данных dbm лучше всего применять для данных, к которым часто обращаются, но которые редко обновляются, поскольку она довольно медленно создает элементы, но быстро извлекает их. В данный момент мы сталкиваемся с небольшой проблемой: в течение многих лет было сформировано несколько версий базы данных dbm с разными API и средствами. Существует исходный набор dbm, "новый" набор dbm, называемый ndbm, и реализация проекта GNU gdbm. Реализация GNU может эмулировать интерфейсы более старой версии dbm и версии ndbm, но ее собственный интерфейс существенно отличается от других реализаций. Различные дистрибутивы Linux поставляются с библиотеками разных версий dbm, но самый популярный вариант — поставка с библиотекой gdbm и установка ее с возможностью эмуляции интерфейсов двух других типов. В книге мы собираемся сосредоточиться на интерфейсе ndbm, поскольку он стандартизован X/OPEN и его применять легче, чем непосредственно интерфейс реализации gdbm. Получение dbmСамые широко распространенные дистрибутивы Linux приходят с уже установленной версией gdbm, хотя в некоторых из них вам придется применить соответствующий диспетчер пакетов (package manager) для установки нужных библиотек разработки. Например, в дистрибутиве Ubuntu вам может понадобиться диспетчер пакетов Synaptic для установки пакета libgdbm-dev, если он не установлен по умолчанию. Если вы хотите просмотреть исходный код или используете дистрибутив, в который не включен встроенный пакет разработки, реализацию GNU можно найти по адресу www.gnu.org/software/gdbm/gdbm.html. Устранение неполадок и повторная установка dbmЭта глава написана в расчете на то, что у вас установлена реализация GNU gdbm, укомплектованная библиотеками совместимости с ndbm. Это обычный вариант для дистрибутивов Linux, однако, как упоминалось ранее, возможно, вам придется явно устанавливать пакет библиотеки разработки для того, чтобы компилировать файлы с использованием подпрограмм ndbm. К сожалению, требуемые библиотеки директив includeи компоновки слегка различаются в разных дистрибутивах, поэтому, несмотря на их установку, вам, возможно, придется поэкспериментировать немного, чтобы выяснить, как компилировать исходные файлы с использованием ndbm. Наиболее частый вариант — база данных gdbm установлена и поддерживает по умолчанию режим совместимости с версией ndbm. Дистрибутивы, например Red Hat, как правило, делают это. В этом случае вам нужно выполнить следующие шаги: 1. Включите в ваш файл на языке С файл ndbm.h. 2. Включите каталог заголовочного файла /usr/include/gdbm с помощью опции -I/usr/include/gdbm. 3. Скомпонуйте программу с библиотекой gdbm, используя опцию -lgdbm. Если программа не работает, обычная альтернатива, принятая в новейших версиях дистрибутивов Ubuntu и SUSE, — устанавливается база данных gdbm, но при необходимости явно запрашивается совместимость с базой данных ndbm, и вы должны компоновать программу сначала с библиотекой совместимости, а затем с основной библиотекой. В этом случае надо выполнить следующие шаги: 1. Вместо файла ndbm.h включите в ваш файл на С файл gdbm-ndbrh.h. 2. Включите каталог заголовочного файла /usr/include/gdbm с помощью опции -I/usr/include/gdbm. 3. Скомпонуйте программу с дополнительной библиотекой совместимости gdbm, используя опцию -lgdbm_compat -lgdbm. Загружаемый Makefile и С-файлы dbm установлены с первым вариантом, принятым по умолчанию, но содержат комментарии о том, как их отредактировать, чтобы можно было легко выбрать второй вариант. В оставшейся части главы мы полагаем, что в вашей системе совместимость с ndbm — характеристика, принятая по умолчанию. Подпрограммы dbmКак и библиотека curses, обсуждавшаяся нами в главе 6, средство dbm состоит из заголовочного файла и библиотеки, которая должна компоноваться с программой во время компиляции последней. Библиотека называется просто dbm, но поскольку мы обычно применяем в системе Linux реализацию GNU, необходимо компоновать с этой реализацией, используя в строке компиляции опцию -lgdbm. Заголовочный файл — ndbm.h. Прежде чем мы попытаемся описать каждую функцию, важно понять чего старается достичь база данных dbm. Когда вы поймете это, гораздо легче будет уяснить, как применять функции dbm. Основной элемент базы данных dbm — блок данных, предназначенных для хранения, связанный с блоком данных, действующих как ключ для извлечения данных. У всех баз данных dbm должны быть уникальные ключи для каждого хранящегося блока данных. Значение ключа используется как индекс хранящихся данных. Нет ограничений на ключи или данные и не определено никаких ошибок при использовании данных или ключей слишком большого размера. Стандарт допускает реализацию, ограничивающую размер ключа/данных величиной 1023 байта, но, как правило, ограничений не существует, поскольку реализации оказались более гибкими, чем требования, предъявляемые к ним. Для манипулирования этими блоками как данными в заголовочном файле ndbm.h определен новый тип данных, названный datum. Конкретное содержимое этого типа зависит от реализации, но он должен, как минимум, включать следующие элементы: void *dptr; size_t dsize Здесь datum— тип, который будет определяться оператором typedef. В файле ndbm.h также дано определение dbm, представляющее собой структуру, применяемую для доступа к базе данных, и во многом похожее на определение FILE, используемое для доступа к файлам. Внутреннее содержимое dbm typedefзависит от реализации и никогда не должно использоваться. Для ссылки на блок данных при использовании библиотеки dbm вы должны объявить datum, задать указатель dptrдля указания на начало данных, а также задать параметр dsize, содержащий размер данных. На хранящиеся данные и индекс, применяемый для доступа к ним, всегда нужно ссылаться с помощью типа datum. О типе DBMлучше всего думать как об аналоге типа FILE. Когда вы открываете базу данных dbm, обычно создаются два физических файла: один с расширением pag, а другой с расширением dir. Возвращается один указатель dbm, который применяется для обращения к обоим файлам как к паре. Файлы никогда не следует непосредственно читать и в них не нужно писать; они предназначены для доступа через стандартные операции dbm. Примечание Если вы знакомы с базами данных SQL, то заметите, что в случае базы данных dbm не существует структур таблиц или столбцов. Эти структуры не нужны, т.к. dbm не задает фиксированного размера элементов сохраняемых данных и не требует описания внутренней структуры для них. Библиотека dbm работает с блоками неструктурированных двоичных данных. Функции доступа dbmТеперь, когда мы рассказали об основах работы библиотеки dbm, можем поподробнее рассмотреть функции. Далее приведены прототипы основных функций dbm. #include <ndbm.h> DBM *dbm_open(const char* filename, int file_open_flags, mode_t file_mode); int dbm_store(DBM *database_descriptor, datum key, datum content, int store_mode); datum dbm_fetch(DBM* database descriptor, datum key); void dbm_close(DBM *database descriptor);dbm_open Эта функция применяется для открытия имеющихся баз данных и для создания новых баз данных. Аргумент filename— имя файла базы данных без расширения dir или pag. Остальные параметры такие же, как второй и третий параметры функции open, с которой вы встречались в главе 3. Вы можете использовать те же директивы #define. Второй аргумент управляет возможностью чтения базы данных, записью в нее или обеими операциями. Если создается новая база данных, флаги должны быть двоичными O_READс O_CREAT, чтобы разрешить создание файлов. Третий аргумент задает начальные права доступа к файлам, которые будут созданы. Функция dbm_openвозвращает указатель на тип DBM. Он применяется во всех последующих обращениях к базе данных. В случае аварийного завершения возвращается (DBM*)0. dbm_store Эту функцию применяют для ввода данных в базу данных. Как упоминалось ранее, все данные должны сохраняться с уникальным индексом. Для определения данных, которые вы хотите сохранить, и индекса, используемого для ссылки на них, следует задать два типа datum: один для ссылки на индекс, а другой — на реальные данные. Последний параметр store_modeуправляет действиями, совершаемыми при попытке сохранить какие-либо данные с применением ключа, который уже существует. Если установлено значение параметра dbm_insert, сохранение завершается аварийно и функция dbm_storeвозвращает 1. Если установлено значение параметра dbm_replace, новые данные заменяют существующие и dbm_storeвозвращает 0. При возникновении других ошибок функция dbm_storeвозвращает отрицательные числа. dbm_fetch Подпрограмма dbm_fetchприменяется для извлечения данных из базы данных. Она принимает в качестве параметра указатель dbm, возвращенный предшествующим вызовом функции dbm_openи тип datum, который должен быть задан как указатель на ключ. Тип datumвозвращается, если данные, относящиеся к используемому ключу, найдены в базе данных, возвращаемая структура datumбудет иметь значения dptrи dsize, ссылающиеся на возвращенные данные. Если ключ не найден, dptrбудет равен null. Примечаниеdbm_close Эта подпрограмма закрывает базу данных, открытую функцией dbm_open, и должна получить указатель DBM, возвращенный предшествующим вызовом dbm_open. А теперь выполните упражнение 7.12. Упражнение 7.12. Простая база данных dbmПознакомившись с основными функциями базы данных dbm, теперь вы знаете, как написать вашу первую программу для работы с dbm (dbm1.c). В этой программе применяется структура, названная test_data. 1. Первыми представлены файлы #include, директивы #define, функция mainи объявление структуры test_data: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <ndbm.h> /* В некоторых системах вам нужно заменить вышестоящую строку строкой #include <gdbm-ndbm.h>*/ #include <string.h> #define TEST_DB_FILE "/tmp/dbm1_test" #define ITEMS_USED 3 struct test_data { char misc_chars[15]; int any_integer; char more_chars[21]; }; int main() { 2. В функции mainзадайте элементы структур items_to_storeи items_received, строку keyи типы datum: struct test_data items_to_store[ITEMS_USED]; struct test_data item_retrieved; char key_to_use[20]; int i, result; datum key_datum; datum data_datum; DBM *dbm_ptr; 3. Объявив указатель на структуру типа DBM, откройте вашу тестовую базу данных для чтения и записи, создав ее при необходимости: dbm_ptr = dbm_open(TEST_DB_FILE, O_RDWR | O_CREAT, 0666); if (!dbm_ptr) { fprintf (stderr, "Failed to open database\n"); exit(EXIT_FAILURE); } 4. Теперь добавьте данные в структуру items_to_store: memset(items_to_store, '\0', sizeof(items_to_store)); strcpy(items_to_store[0].misc_chars, "First! "); items_to_store[0].any_integer = 47; strcpy(items_to_store[0].more_chars, "foo"); strcpy(items_to_store[1].misc_chars, "bar"); items_to_store[1].any_integer = 13; strcpy(items_to_store[1].more_chars, "unlucky? "); strcpy(items_to_store[2].misc_chars, "Third"); items_to_store[2].any_integer = 3; strcpy(items_to_store[2].more_chars, "baz"); 5. Для каждого элемента необходимо сформировать ключ для будущих ссылок в виде первой буквы каждой строки и целого числа. Этот ключ затем будет обозначен key_datum, когда data_datumсошлется на элемент items_to_store. Далее вы сохраняете данные в базе данных: for (i = 0; i < ITEMS_USED; i++) { sprintf(key_to_use, "%c%c%d", items_to_store[i].misc_chars[0], items_to_store[i].more_chars[0], items_to_store[i].any_integer); key_datum.dptr = (void*)key_to_use; key_datum.dsize = strlen(key to_use); data_datum.dptr = (void*)&items_to_store[i]; data_datum.dsize = sizeof(struct.test_data); result = dbm_store(dbm_ptr, key_datum, data_datum, DBM_REPLACE); if (result != 0) { fprintf(stderr, "dbm_store failed on key %s\n", key_to_use); exit(2); } } 6. Далее посмотрите, сможете ли вы извлечь эти новые данные, и в заключение следует закрыть базу данных: sprintf(key_to_use, "bu%d", 13); key_datum.dptr = key_to_use; key_datum.dsize = strlen(key_to_use); data_datum = dbm_fetch(dbm_ptr, key_datum); if (data_datum.dptr) { printf("Data retrieved\n"); memcpy(&item_retrieved, data_datum.dptr, data_datum.dsize); printf("Retrieved item — %s %d %s\n", item_retrieved.misc_chars, item_retrieved.any_integer, item_retrieved.more_chars); } else { printf("No data found for key %s\n", key_to_use); } dbm_close(dbm_ptr); exit(EXIT_SUCCESS); } Когда вы откомпилируете и выполните программу, вывод будет следующим: $ gcc -о dbm1 -I/usr/include/gdtm dbm1.с -lgdbm $ ./dbm1 Data retrieved Retrieved item — bar 13 unlucky? Вы получите приведенный вывод, если база данных gdbm установлена в режиме совместимости. Если компиляция не прошла, возможно, вам придется изменить директиву include, как показано в файле, для использования заголовочного файла gdbm-ndbm.h вместо файла ndbm.h и задать в строке компиляции библиотеку совместимости перед основной библиотекой, как показано в следующей строке: $ gcc -о dbm1 -I/usr/include/gdbm dbm1.с -lgdbm_compat -lgdbm Как это работает Сначала вы открываете базу данных, при необходимости создавая ее. Затем вы заполняете три элемента структуры items_to_store, чтобы использовать их как тестовые данные. Для каждого из трех элементов вы создаете индексный ключ. Чтобы он оставался простым, используйте первые символы каждой из двух строк плюс сохраненное целое. Далее вы задаете две структуры типа datum, одну для ключа и другую для сохраняемых данных. Сохранив три элемента в базе данных, вы конструируете новый ключ и настраиваете структуру типа datumтак, чтобы она указывала на него. Затем вы применяете данный ключ для извлечения данных из базы данных. Убедитесь в успехе, проверив, что dptrв возвращенном datumне равен null. Получив подтверждение, вы можете копировать извлеченные данные (которые могут храниться внутри библиотеки dbm) в вашу собственную структуру, применяя возвращенный размер dbm_fetch(если этого не сделать, при наличии данных переменного размера вы можете скопировать несуществующие данные). В заключение извлеченные данные выводятся на экран, чтобы продемонстрировать корректность их извлечения. Дополнительные функции dbmПосле знакомства с основными функциями библиотеки dbm приведем несколько оставшихся функций, применяемых при работе с базой данных dbm: int dbm_delete(DBM *database_descriptor, datum key); int dbm_error(DBM *database_descriptor); int dbm_clearerr(DBM *database_dascriptor); datum dbm_firstkey(DBM *database_descriptor); datum dbm_nextkey(DBM *database_descriptor);dbm_delete Функция dbm_deleteприменяется для удаления элементов из базы данных. Она принимает ключ типа datumточно так же, как функция dbm_fetch, но вместо извлечения данных она удаляет их. В случае успешного завершения функция возвращает 0. dbm_error Функция dbm_errorпросто проверяет базу данных на наличие ошибок, возвращая 0 при их отсутствии. dbm_clearerr Функция dbm_clearerr очищает любой флаг ошибочной ситуации, который может быть установлен в базе данных. dbm_firstkey и dbm_nextkeyЭти подпрограммы обычно используются вместе для просмотра ключей всех элементов базы данных. Далее приведена структура требуемого для просмотра цикла: DBM *db_ptr; datum key; for (key = dbm_firstkey(db_ptr); key.dptr; key = dbm_nextkey(db_ptr)); Выполните упражнение 7.13. Упражнение 7.13. Извлечение и удалениеВ этом примере вы улучшите файл dbm1.с с помощью описанных новых функций и создадите новый файл dbm2.c. 1. Сделайте копию dbm1.с и откройте его для редактирования. Отредактируйте строку #define TEST_DB_FILE. #unclude <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <ndbm.h> #include <string.h> #define TEST_DB_FILE "/tmp/dbm2_test" #define ITEMS_USED 3 2. Теперь вам нужно внести изменения только в секцию извлечения: /* теперь попытайтесь удалить некоторые данные */ sprintf(key_to_use, "bu%d", 13); key_datum.dptr = key_to_use; key_datum.dsize = strlen(key_to_use); if (dbm_delete(dbm_ptr, key_datum) == 0) { printf("Data with key %s deleted\n", key_to_use); } else { printf("Nothing deleted for key %s\n", key_to_use); } for (key_datum = dbm_firstkey(dbm_ptr); key_datum.dptr; key_datum = dbm_nextkey(dbm_ptr)) { data_datum = dbm_fetch(dbm_ptr, key_datum); if (data_datum.dptr) { printf("Data retrieved\n"); memcpy(&item_retrieved, data_datum.dptr, data_datum.dsize); printf("Retrieved item - %s %d %s\n", item_retrieved.misc_chars, item_retrieved.any_integer, item_retrieved.more_chars); } else { printf("No data found for key %s\n", key_to_use); } } } Далее приведен вывод: $ ./dbm2 Data with key bu13 deleted Data retrieved Retrieved item — Third 3 baz Data retrieved Retrieved item - First! 47 foo Как это работает Первая часть программы, идентичная предыдущему примеру, просто сохраняет данные в базе данных. Затем вы формируете ключ, соответствующий второму элементу, и удаляете этот элемент из базы данных. Далее программа применяет функции dbm_firstkeyи dbm_nextkeyдля обращения к каждому значению ключа по очереди и для извлечения соответствующих ключу данных. Обратите внимание на то, что данные извлекаются не по порядку. Перебор ключей по очереди не определяет никакого порядка извлечения данных, это просто способ просмотра всех элементов в базе данных; Приложение для работы с коллекцией компакт-дисковТеперь, когда вы узнали об окружении и управлении данными, самое время обновить приложение. Кажется, что база данных dbm хорошо подходит для хранения информации о компакт-дисках, поэтому воспользуйтесь ею как основой новой реализации. Обновление проектного решенияПоскольку обновление предполагает значительную корректировку, сейчас самое время взглянуть на проектные решения, чтобы выяснить, не нуждаются ли они в пересмотре. Использование файлов с запятыми в качестве разделителей полей для хранения информации, хотя и обеспечивает легкую реализацию средствами командной оболочки, оказывается связанным со многими ограничениями. Во множестве заголовков компакт-дисков и дорожек встречаются запятые. Вы можете полностью отказаться от этого метода разделения, применив dbm, таким образом, у нас появился один компонент проектного решения, который придется менять. Разделение информации на заголовки и дорожки с применением отдельного файла для хранения каждого вида данных кажется хорошим решением, поэтому вы можете сохранить эту логическую структуру. В обеих предыдущих реализациях части приложения, относящиеся к доступу к данным, до некоторой степени смешаны с частями пользовательского интерфейса, нельзя сказать, что незначительно, потому что все приложение реализовано как единый файл. В данной реализации вы примените заголовочный файл для описания данных и подпрограммы для доступа к ним и разделите пользовательский интерфейс и манипулирование данными на два отдельных файла. Несмотря на то, что вы могли бы сохранить реализацию пользовательского интерфейса средствами библиотеки curses, вы вернетесь к построчной системе. Такой подход позволит сохранить часть приложения, связанную с пользовательским интерфейсом, маленькой и простой и сосредоточиться на других аспектах реализации. С базой данных dbm вы не сможете применять язык SQL, но опишите новую базу данных с помощью более формальных терминов, используя терминологию языка SQL. Не волнуйтесь, если вы не знакомы с этим языком, мы поясним все определения, а в главе 8 вы узнаете о нем больше. В программном коде таблица может быть описана следующим образом: CREATE TABLE cdc_entry ( catalog CHAR(30) PRIMARY KEY REFERENCES cdt_entry(catalog), title CHAR(70), type CHAR(30), artist CHAR(70) ); CREATE TABLE cdt_entry ( catalog CHAR(30) REFERENCES cdc_entry(catalog), track_no INTEGER, track_txt CHAR(70), PRIMARY KEY(catalog, track_no) ); Это очень краткое описание сообщает имена и размеры полей. В таблице cdc_entryу каждого элемента есть уникальный столбец каталога catalog. В таблице cdt_entryномер дорожки не может быть нулевым и комбинация столбцов catalogи track_noуникальна. Вы увидите их определение в виде структур typedef structв следующем разделе программного кода. Приложение управления базой данных компакт-дисков, использующее dbmСейчас заново вы создадите приложение, использующее базу данных dbm для хранения нужной вам информации, в виде файлов cd_data.h, app_ui.c и cd_access.c (упражнения 7.14–7.16). Вы также перепишите пользовательский интерфейс в виде программы с вводом команд. Позже в этой книге интерфейс базы данных и части пользовательского интерфейса будут пересмотрены, когда будет рассматриваться реализация вашего приложения с помощью различных клиент-серверных механизмов и затем как приложения, к которому можно обращаться по сети, используя Web-обозреватель. Преобразование интерфейса в более простой строковый интерфейс позволит сосредоточиться не на нем, а на более важных частях приложения. ПримечаниеУпражнение 7.14. Файл cd_data.h Начните с заголовочного файла для определения структуры ваших данных и подпрограмм, которые будут использоваться для доступа к данным. 1. Далее приведено определение структуры данных для базы данных компакт-дисков. В него включено определение структур и размеров двух таблиц, формирующих базу данных. Начните с задания размеров некоторых полей, которые вы будете применять, и двух структур: одной для элемента каталога, а другой для элемента дорожки. /* Таблица catalog */ #define CAT_CAT_LEN 30 #define CAT_TITLE_LEN 70 #define CAT_TYPE_LEN 30 #define CAT_ARTIST_LEN 70 typedef struct { char catalog[CAT_CAT_LEN + 1]; char title[CAT_TITLE_LEN + 1]; char type [CAT_TYPE_LEN + 1]; char artist[CAT_ARTIST_LEN + 1]; } cdc_entry; /* Таблица дорожек, по одному элементу на дорожку */ #define TRACK_CAT_LEN CAT_CAT_LEN #define TRACK_TTEXT_LEN 70 typedef struct { char catalog[TRACK_CAT_LEN + 1]; int track_no; char track_txt[TRACK_TTEXT_LEN + 1]; } cdt_entry; 2. Теперь, имея структуры данных, можно определить нужные вам подпрограммы доступа. Функции с префиксом cdc_в имени предназначены для элементов каталога, с префиксом cdt_— для элементов-дорожек. Примечание /* Функции инициализации и завершения */ int database_initialize(const int new_database); void database_close(void); /* Две функции для простого извлечения данных */ cdc_entry get_cdc_entry(const char *cd_catalog_ptr); cdt_entry get_cdt_entry(const char *cd_catalog_ptr, const int track_no); /* Две функции для добавления данных */ int add_cdc_entry(const cdc_entry entry_to_add); int add_cdt_entry(const cdt_entry entry_to_add); /* Две функции для удаления данных */ int del_cdc_entry(const char *cd_catalog_ptr); int del_cdt_entry(const char *cd_catalog_ptr, const int track_no); /* Одна функция поиска */ cdc_entry search_cdc_entry(const char *cd_catalog_ptr, int *first_call_ptr);Упражнение 7.15. Файл app_ui.c Теперь перейдем к пользовательскому интерфейсу. Вам предлагается простая программа, с помощью которой вы сможете обращаться к функциям вашей базы данных. Интерфейс реализуется в отдельном файле. 1. Как обычно, начните с некоторых заголовочных файлов: #define _XOPEN_SOURCE #include <stdlib.h> #include <unistd.h> #include <stdio.h> #include <string.h> #include "cd_data.h" #define TMP_STRING_LEN 125 /* это число должно быть больше самой длинной строки в структуре базы данных */ 2. Опишите пункты вашего меню с помощью typedef. Этот вариант лучше применения констант, заданных в директивах #define, т.к. позволяет компилятору проверить типы переменных, задающих пункт меню. typedef enum { mo_invalid, mo_add_cat, mo_add_tracks, mo_del_cat, mo_find_cat, mo_list_cat_tracks, mo_del_tracks, mo_count_entries, mo_exit } menu_options; 3. Теперь введите прототипы локальных функций. Помните о том, что прототипы функций, обеспечивающих реальный доступ к базе данных, включены в файл cd_data.h. static int command_mode(int argc, char *argv[]); static void announce(void); static menu_options show_menu(const cdc_entry *current_cdc); static int get_confirm(const char *question); static int enter_new_cat_entry(cdc_entry *entry_to_update); static void enter_new_track_entries(const cdc_entry* entry_to_add_to); static void del_cat_entry(const cdc_entry *entry_to_delete); static void del_track_entries(const cdc_entry *entry_to_delete); static cdc_entry find_cat(void); static void list_tracks(const cdc_entry *entry_to_use); static void count_all_entries(void); static void display_cdc(const cdc_entry *cdc_to_show); static void display_cdt(const cdt_entry *cdt_to_show); static void strip_return(char *string_to_strip); 4. И наконец, вы добрались до функции main. Она начинается с проверки того, что текущий элемент current_cdc_entry, который применяется для сохранения дорожки выбранного в данный момент элемента каталога компакт-дисков, инициализирован. Также проводится грамматический разбор командной строки, выдается оповещение о том, какая программа выполняется, и инициализируется база данных. void main(int argc, char *argv[]) { menu_options current_option; cdc_entry current_cdc_entry; int command_result; memset(¤t_cdc_entry, '\0', sizeof(current_cdc_entry)); if (argc >1) { command_result = command_mode(argc, argv); exit(command_result); } announce(); if (!database_initialize(0)) { fprintf(stderr, "Sorry, unable to initialize database\n"); fprintf(stderr, "To create a new database use %s -i\n", argv[0]); exit(EXIT_FAILURE); } 5. Теперь вы готовы обрабатывать ввод пользователя. Вы остаетесь в цикле, запрашивая пункт меню и обрабатывая его до тех пор, пока пользователь не выберет выход. Обратите вниманий на то, что вы передаете структуру current_cdc_entryв функцию show_menu, чтобы разрешить изменять варианты пунктов меню, когда выбран текущий элемент каталога: while (current_option != mo_exit) { current_option = show_menu(¤t_cdc_entry); switch(current_option) { case mo_add_cat: if (enter_new_cat_entry(¤t_cdc_entry)) { if (!add_cdc_entry(current_cdc_entry)) { fprintf(stderr, "Failed to add new entry\n"); memset(¤t_cdc_entry, '\0', sizeof(current_cdc_entry)); } } break; case mo_add_tracks: enter_new_track_entries(¤t_cdc_entry); break; case mo_del_cat: del_cat_entry(¤t_cdc_entry); break; case mo_find_cat: current_cdc_entry = find_cat(); break; case mo_list_cat_tracks: list_tracks(¤t_cdc_entry); break; case mo_del_tracks: del_track_entries(¤t_cdc_entry); break; case mo_count_entries: count_all_entries(); break; case mo_exit: break; case mo_invalid: break; default: break; } /* switch */ } /* while */ 6. Когда цикл в функции mainзавершится, закройте базу данных и вернитесь в окружение. Функция announceвыводит приглашающее предложение: database_close(); exit(EXIT_SUCCESS); } /* main */ static void announce(void) { printf("\n\nWelcome to the demonstration CD catalog database \ program\n"); } 7. Здесь вы реализуете функцию show_menu. Эта функция проверяет, выбран ли текущий элемент каталога, используя первый символ имени в каталоге. Если элемент каталога выбран, становятся доступными дополнительные пункты меню: static menu_options show_menu(const cdc_entry *cdc_selected) { char tmp_str[TMP_STRING_LEN + 1]; menu_options option_chosen = mo_invalid; while (option_chosen == mo_invalid) { if (cdc_selected->catalog[0]) { printf("\n\nCurrent entry: "); printf("%s, %s, %a, %s\n", cdc_selected->catalog, cdc_selected->title, cdc_selected->type, cdc_selected->artist); printf("\n"); printf("1 - add new CD\n"); printf("2 — search for a CD\n"); printf("3 — count the CDs and tracks in the database\n"); printf("4 — re-enter tracks for current CD\n"); printf("5 - delete this CD, and all its tracks\n"); printf("6 - list tracks for this CD\n"); printf("q — quit\n"); printf("\nOption: "); fgets(tmp_str, TMP_STRING_LEN, stdin); switch(tmp_str[0]) { case '1': option_chosen = mo_add_cat; break; case '2': option_chosen = mo_find_cat; break; case '3': option_chosen = mo_count_entries; break; case '4': option_chosen = mo_add_tracks; break; case '5': option_chosen = mo_del_cat; break; case '6': option_chosen = mo_list_cat_tracks; break; case 'q': option_chosen = mo_exit; break; } } else { printf("\n\n"); printf("1 - add new CD\n"); printf("2 - search for a CD\n"); printf("3 — count the CDs and tracks in the database\n"); printf("q — quit\n"); printf("\nOption: "); fgets(tmp_str, TMP_STRING_LEN, stdin); switch(tmp_str[0]) { case '1': option_chosen = mo_add_cat; break; case '2': option_chosen = mo_find_cat; break; case '3': option_chosen = mo_count_entries; break; case 'q': option_chosen = mo_exit; break; } } } /* while */ return(option_chosen); } Примечание 8. В программе есть несколько участков, в которых хотелось бы спросить пользователя о том, уверен ли он в своем запросе. Вместо того чтобы вставлять в эти места программный код, задающий вопрос, поместим его в отдельную функцию get_confirm: static int get_confirm(const char *question) { char tmp_str[TMP_STRING_LEN + 1]; printf("%s", question); fgets(tmp_str, TMP_STRING_LEN, stdin); if (tmp_str[0] == 'Y' || tmp_str[0] = 'y') { return(1); } return(0); } 9. Функция enter_new_cat_entryпозволяет вводить новый элемент каталога. Вам не нужно сохранять перевод строки, который возвращает функция fgets, поэтому отбросьте его: static int enter_new_cat_entry(cdc_entry *entry_to_update) { cdc_entry new_entry; char tmp_str[TMP_STRING_LEN + 1]; memset(&new_entry, '\0', sizeof(new_entry)); printf("Enter catalog entry: "); (void)fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); strncpy(new_entry.catalog, tmp_str, CAT_CAT_LEN - 1); printf("Enter title: "); (void)fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); strncpy(new_entry.title, tmp_str, CAT_TITLE_LEN - 1); printf("Enter type: "); (void)fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); strncpy(new_entry.type, tmp_str, CAT_TYPE_LEN - 1); printf("Enter artist: "); (void)fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); strncpy(new_entry.artist, tmp_str, CAT_ARTIST_LEN - 1); printf("\nNew catalog entry entry is :-\n"); display_cdc(&new_entry); if (get_confirm("Add this entry ? ")) { memcpy(entry_to_update, &new_entry, sizeof(new_entry)); return(1); } return(0); } Примечание 10. Теперь вы переходите к функции enter_new_track_entriesдля ввода информации о дорожке. Эта функция немного сложнее функции ввода элемента каталога, поскольку вы разрешаете существующему элементу-дорожке оставаться неизменным: static void enter_new_track_entries(const cdc_entry *entry_to_add_to) { cdt_entry new_track, existing_track; char tmp_str[TMP_STRING_LEN + 1]; int track_no = 1; if (entry_to_add_to->catalog[0] == '\0') return; printf("\nUpdating tracks for %s\n", entry_to_add_to->catalog); printf("Press return to leave existing description unchanged, \n"); printf(" a single d to delete this and remaining tracks, \n"); printf(" or new track description\n"); while(1) { 11. Сначала вы должны проверить, существует ли уже дорожка с текущим номером дорожки. В зависимости от результатов проверки меняется строка приглашения: memset(&new_track, '\0', sizeof(new_track)); existing_track = get_cdt_entry(entry_to_add_to->catalog, track_no); if (existing_track.catalog[0]) { printf("\tTrack %d: %s\n", track_no, existing_track.track_txt); printf("\tNew text: "); } else { printf("\tTrack %d description: ", track_no); } fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); 12. Если для данной дорожки не существует элемент и пользователь его не добавил, предположите, что больше нет дорожек, которые надо добавить: if (strlen(tmp_str) == 0) { if (existing_track.catalog[0] == '\0') { /* Нет в наличии элемента, поэтому вставка завершается */ break; } else { /* Оставляем существующий элемент, переходам к следующей дорожке */ track_no++; continue; } } 13. Если пользователь введет единичный символ d, это приведет к удалению текущей дорожки и дорожек с большими номерами. Функция del_cdt_entryвернет false, если не сможет найти дорожку, которую следует удалить: if ((strlen(tmp_str) == 1) && tmp_str[0] == 'd') { /* Удаляет эту и оставшиеся дорожки */ while (del_cdt_entry(entry_to_add_to->catalog, track_no)) { track_no++; } break; } 14. В этом пункте приводится код для вставки новой дорожки или обновления существующей. Вы формируете элемент cdt_entryструктуры new_trackи затем вызываете функцию базы данных add_cdt_entryдля того, чтобы включить его в базу данных: strncpy(new_track. track_txt, tmp_str, TRACK_TTEXT_LEN - 1); strcpy(new_track.catalog, entry_to_add_to->catalog); new_track.track_no = track_no; if (!add_cdt_entry(new_track)) { fprintf(stderr, "Failed to add new track\n"); break; } track_no++; } /* while */ } 15. Функция del_cat_entryудаляет элемент каталога. Никогда не разрешайте хранить дорожки для несуществующего элемента каталога. static void del_cat_entry(const cdc_entry *entry_to_delete) { int track_no = 1; int delete_ok; display_cdc(entry_to_delete); if (get_confirm("Delete this entry and all it's tracks? ")) { do { delete_ok = del_cdt_entry(entry_to_delete->catalog, track_no); track_no++; } while(delete_ok); if (!del_cdc_entry(entry_to_delete->catalog)) { fprintf(stderr, "Failed to delete entry\n"); } } } 16. Следующая функция — утилита для удаления всех дорожек элемента каталога: static void del_track_entries(const cdc_entry *entry_to_delete) { int track_no = 1; int delete_ok; display_cdc(entry_to_delete); if (get_confirm("Delete tracks for this entry? ")) { do { delete_ok = del_cdt_entry(entry_to_delete->catalog, track_no); track_no++; } while(delete_ok); } } 17. Создайте очень простое средство поиска, в котором разрешите пользователю ввести строку и затем поищите элементы каталога, содержащие строку. Поскольку может быть несколько элементов с такой строкой, просто по очереди предлагаются пользователю все найденные: static cdc_entry find_cat(void) { cdc_entry item_found; char tmp_str[TMP_STRING_LEN + 1]; int first_call = 1; int any_entry_found = 0; int string ok; int entry_selected = 0; do { string_ok = 1; printf("Enter string to search for in catalog entry: "); fgets(tmp_str, TMP_STRING_LEN, stdin); strip_return(tmp_str); if (strlen(tmp_str) > CAT_CAT_LEN) { fprintf(stderr, "Sorry, string too long, maximum %d \ characters\n", CAT_CAT_LEN); string_ok = 0; } } while (!string_ok); while (!entry_selected) { item_found = search_cdc_entry(tmp_str, &firstcall); if (item_found.catalog[0] != '\0') { any_entry_found = 1; printf("\n"); display_cdc(&item_found); if (get_confirm("This entry? ")) { entry_selected = 1; } } else { if (any_entry_found) printf("Sorry, no more matches found\n"); else printf("Sorry, nothing found\n"); break; } } return(item_found); } 18. Функция list_tracks— утилита, которая выводит все дорожки для заданного элемента каталога: static void list_tracks(const cdc_entry *entry_to_use) { int track_no = 1; cdt_entry entry_found; display_cdc(entry_to_use); printf("\nTracks\n"); do { entry_found = get_cdt_entry(entry_to_use->catalog, track_no); if (entry_found.catalog[0]) { display_cdt(&entry_found); track_no++; } } while(entry_found.catalog[0]); (void)get_confirm("Press return"); } /* list_tracks */ 19. Функция count_all_entriesподсчитывает все дорожки: static void count_all_entries(void) { int cd_entries_found = 0; int track_entries_found = 0; cdc_entry cdc_found; cdt_entry cdt_found; int track_no = 1; int first_time = 1; char *search_string = ""; do { cdc_found = search_cdc_entry(search_string, &first_time); if (cdc_found.catalog[0]) { cd_entries_found++; track_no = 1; do { cdt_found = get_cdt_entry(cdc_found.catalog, track_no); if (cdt_found.catalog[0]) { track_entries_found++; track_no++; } } while (cdt_found.catalog[0]); } } while (cdc_found.catalog[0]); printf("Found %d CDs, with a total of %d tracks\n", cd_entries_found, track_entries_found); (void)get_confirm("Press return"); } 20. Теперь у вас есть утилита display_cdcдля вывода элемента каталога: static void display_cdc(const cdc_entry *cdc_to_show) { printf("Catalog: %s\n", cdc_to_show->catalog); printf("\ttitle: %s\n", cdc_to_show->title); printf("\ttype: %s\n", cdc_to_show->type); printf("\tartist: %s\n", cdc_to_show->artist); } и утилита display_cdtдля отображения элемента-дорожки: static void display_cdt(const cdt_entry *cdt_to_show) { printf("%d: %s\n", cdt_to_show->track_no, cdt_to_show->track_txt); } 21. Служебная функция strip_returnудаляет завершающий строку символ перевода строки. Помните о том, что Linux, как и UNIX, использует один символ перевода строки для обозначения конца строки. static void strip_return(char *string_to_strip) { int len; len = strlen(string_to_strip); if (string_to_strip[len - 1] == '\n') string_to_strip[len - 1] = '\0'; } 22. Функция command_modeпредназначена для синтаксического анализа аргументов командной строки. Функция getopt— хороший способ убедиться в том, что ваша программа принимает аргументы, соответствующие стандартным соглашениям, принятым в системе Linux. static int command_mode(int argc, char *argv[]) { int c; int result = EXIT_SUCCESS; char *prog_name = argv[0]; /* Эти внешние переменные используются функцией getopt */ extern char *optarg; extern optind, opterr, optopt; while ((c = getopt(argc, argv, ":i")) != -1) { switch(c) { case 'i': if (!database_initialize(1)) { result = EXIT_FAILURE; fprintf(stderr, "Failed to initialize database\n"); } break; case ':': case '?': default: fprintf(stderr, "Usage: %s [-i]\n", prog_name); result = EXIT_FAILURE; break; } /* switch */ } /* while */ return(result); }Упражнение 7.16. Файл cd_access.c Теперь переходите к функциям доступа к базе данных dbm. 1. Как обычно, начните с нескольких файлов #include. Далее примените директивы #defineдля задания файлов, которые будут использоваться для хранения данных: #define _XOPEN_SOURCE #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <string.h> #include <ndbm.h> /* В некоторых дистрибутивах файл в предыдущей строке может быть придется заменить на gdbm-ndbm.h */ #include "cd_data.h" #define CDC_FILE_BASE "cdc_data" #define CDT_FILE_BASE "cdt_data" #define CDC_FILE_DIR "cdc_data.dir" #define CDC_FILE_PAG "cdc_data.pag" #define CDT_FILE_DIR "cdt_data.dir" #define CDT_FILE_PAG "cdt_data.pag" 2. Используйте эти две переменные области действия файла для отслеживания текущей базы данных: static DBM *cdc_dbm_ptr = NULL; static DBM *cdt_dbm_ptr = NULL; 3. По умолчанию функция database_initializeоткрывает существующую базу данных, но передав ненулевой (т.е. true) параметр new_database, вы можете заставить ее создать новую (пустую) базу данных, при этом существующая база данных удаляется. Если база данных успешно инициализирована, также инициализированы и два ее указателя, указывающие на то, что база данных открыта. int database_initialize(const int new_database) { int open_mode = O_CREAT | O_RDWR; /* Если открыта какая-либо имеющаяся база данных, закрывает ее */ if (cdc_dbm_ptr) dbm_close(cdc_dbm_ptr); if (cdt_dbm_ptr) dbm_close(cdt_dbm_ptr); if (new_database) { /* Удаляет старые файлы */ (void)unlink(CDC_FILE_PAG); (void)unlink(CDC_FILE_DIR); (void)unlink(CDT_FILE_PAG); (void)unlink(CDT_FILE_DIR); } /* Открывает несколько новых файлов, создавая их при необходимости */ cdc_dbm_ptr = dbm_open(CDC_FILE_BASE, open_mode, 0644); cdt_dbm_ptr = dbm_open(CDT_FILE_BASE, open_mode, 0644); if (!cdc_dbm_ptr || !cdt_dbm_ptr) { fprintf(stderr, "Unable to create database\n"); cdc_dbm_ptr = cdt_dbm_ptr = NULL; return (0); } return (1); } 4. Функция database_closeпросто закрывает базу данных, если она была открыта и устанавливает указатели базы данных в null, чтобы показать, что нет открытой базы данных: void database_close(void) { if (cdc_dbm_ptr) dbm_close(cdc_dbm_ptr); if (cdt_dbm_ptr) dbm_close(cdt_dbm_ptr); cdc_dbm_ptr = cdt_dbm_ptr = NULL; } 5. Далее у вас появляется функция, извлекающая единственный элемент каталога, когда передан указатель на строку текста из каталога. Если элемент не найден, у возвращенных данных пустое поле каталога: cdc_entry get_cdc_entry(const char *cd_catalog_ptr) { cdc_entry entry_to_return; char entry_to_find[CAT_CAT_LEN + 1]; datum local data datum; datum local_key_datum; memset(&entry_to_return, '\0', sizeof(entry_to_return)); 6. Начните с некоторых имеющих смысл проверок, чтобы убедиться в том, что база данных открыта, и вы передали приемлемые параметры, т.е. ключ поиска содержит только допустимую строку и значения null: if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (entry_to_return); if (!cd_catalog_ptr) return (entry_to_return); if (strlen(cd_catalog_ptr) >= CAT_CAT_LEN) return (entry_to_return); memset(&entry_to_find, '\0', sizeof(entry_to_find)); strcpy(entry_to_find, cd_catalog_ptr); 7. Задайте структуру datum, нужную функциям базы данных dbm, и используйте функцию dbm_fetchдля извлечения данных. Если не извлечены никакие данные, вы возвращаете пустую структуру entry_to_return, которая была инициализирована ранее: local_key_datum.dptr = (void *) entry_to_find; local_key_datum.dsize = sizeof(entry_to_find); memset(&local_data_datum, '\0', sizeof(local_data_datum)); local_data_datum = dbm_fetch(cdc_dbm_ptr, local_key_datum); if (local_data_datum.dptr) { memcpy(&entry_to_return, (char*)local_data_datum.dptr, local_data_datum.dsize); } return (entry_to_return); } /* get_cdc_entry */ 8. Было бы неплохо иметь возможность получать также и одиночный элемент-дорожку, именно этим занимается следующая функция аналогично функции get_cdc_entry, но с указателем на строку каталога и номер дорожки в качестве параметров: cdt_entry get_cdt_entry(const char *cd_catalog_ptr, const int track_no) { cdt_entry entry_to_return; char entry_to_find[CAT_CAT_LEN + 10]; datum local_data_datum; datum local_key_datum; memset(&entry_to_return, '\0', sizeof(entry_to_return)); if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (entry_to_return); if (!cd_catalog_ptr) return (entry_to_return); if (strlen(cd_catalog_ptr) >= CAT_CAT_LEN) return (entry_to_return); /* Устанавливает ключ поиска, представляющий собой комбинацию элемента каталога и номера дорожки */ memset(&entry_to_find, '\0', sizeof(entry_to_find)); sprintf(entry_to_find, "%s %d", cd_catalog_ptr, track_no); local_key_datum.dptr = (void*)entry_to_find; local_key_datum.dsize = sizeof(entry_to_find); memset(&local_data_datum, '\0', sizeof(local_data_datum)); local_data_datum = dbm_fetch(cdt_dbm_ptr, local_key_datum); if (local_data_datum.dptr) { memcpy(&entry_to_return, (char*)local_data_datum.dptr, local_data_datum.dsize); } return (entry_to_return); } 9. Следующая функция add_cdc_entryдобавляет новый элемент каталога: int add_cdc_entry(const cdc_entry entry_to_add) { char key_to_add[CAT_CAT_LEN + 1]; datum local_data_datum; datum local_key_datum; int result; /* Проверяет инициализацию базы данных и корректность параметров */ if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (0); if (strlen(entry_to_add.catalog) >= CAT_CAT_LEN) return (0); /* Гарантирует включение в ключ поиска только корректной строки и значений null */ memset(&key_to_add, '\0', sizeof(key_to_add)); strcpy(key_to_add, entry_to_add.catalog); local_key_datum.dptr = (void*)key_to_add; local_key_datum.dsize = sizeof(key_to_add); local_data_datum.dptr = (void*)&entry_to_add; local_data_datum.dsize = sizeof(entry_to_add); result = dbm_store(cdc_dbm_ptr, local_key_datum, local_data_datum, DBM_REPLACE); /* dbm_store() применяет 0 для успешного завершения */ if (result == 0) return (1); return (0); } 10. Функция add_cdt_entryдобавляет новый элемент-дорожку. Ключ доступа — это комбинация строки из каталога и номера дорожки: int add_cdt_entry(const cdt_entry entry_to_add) { char key_to_add[CAT_CAT_LEN + 10]; datum local_data_datum; datum local_key_datum; int result; if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (0); if (strlen(entry_to_add.catalog) >= CAT_CAT_LEN) return (0); memset(&key_to_add, '\0 ', sizeof(key_to_add)); sprintf(key_to_add, "%s %d", entry_to_add.catalog, entry_to_add.track_no); local_key_datum.dptr = (void*)key_to_add; local_key_datum.dsize = sizeof(key_to_add); local_data_daturn.dptr = (void*)&entry_to_add; local_data_datum.dsize = sizeof(entry_to_add); result = dbm_store(cdt_dbm_ptr, local_key_datum, local_data_datum, DBM_REPLACE); /* dbm_store() применяет 0 в случае успешного завершения и отрицательные числа для обозначения ошибок */ if (result == 0) return (1); return (0); } 11. Если вы можете вставлять строки, было бы лучше, если вы могли бы и удалять их. Следующая функция удаляет элементы каталога; int del_cdc_entry(const char *cd_catalog_ptr) { char key_to_del[CAT_CAT_LEN +1]; datum local_key_datum; int result; if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (0); if (strlen(cd_catalog_ptr) >= CAT_CAT_LEN) return (0); memset(&key_to_del, '\0', sizeof(key_to_del)); strcpy(key_to_del, cd_catalog_ptr); local_key_datum.dptr = (void*)key_to_del; local_key_datum.dsize = sizeof(key_to_del); result = dbm_delete(cdc_dbm_ptr, local_key_datum); /* dbm_delete() применяет 0 в случае успешного завершения */ if (result == 0) return (1); return (0); } 12. Далее приведена аналогичная функция для удаления дорожки. Помните о том, что ключ дорожки — это сложный индекс, состоящий из строки, принадлежащей элементу каталога, и номера дорожки: int del_cdt_entry(const char *cd_catalog_ptr, const int track_no) { char key_to_del[CAT_CAT_LEN + 10]; datum local_key_datum; int result; if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (0); if (strlen(cd_catalog_ptr) >= CAT_CAT_LEN) return (0); memset(&key_to_del, '\0', sizeof(key_to_del)); sprintf(key_to_del, "%s %d", cd_catalog_ptr, track_no); local_key_datum.dptr = (void*)key_to_del; local_key_datum.dsize = sizeof(key_to_del); result = dbm_delete(cdt_dbm_ptr, local_key_datum); /* dbm_delete() применяет 0 в случае успешного завершения */ if (result == 0) return (1); return (0); } 13. И последнее, но не по значимости, у вас есть простая функция поиска. Она не очень замысловата, но, тем не менее, показывает, как просматривать элементы dbm, если ключи заранее неизвестны. Поскольку вы не знаете наперед, сколько будет элементов, вы создаете такую функцию, которая будет возвращать один элемент после каждого вызова. Если ничего не найдено, элемент будет пустым. Для просмотра всей базы данных начните с вызова этой функции с указателем на целое число *first_call_ptr, которое должно равняться 1 при первом вызове функции. Благодаря этому функция знает, что должна начать поиск с начала базы данных. В последующих вызовах переменная равна 0 и функция возобновляет поиск следом за последним найденным элементом. Когда вы хотите перезапустить поиск, возможно, указав другой элемент каталога, вы должны снова вызвать эту функцию с параметром *first_call_ptr, равным true, что приведет к выполнению нового поиска. Между вызовами функция хранит некоторую внутреннюю информацию о состоянии. Это скрывает от клиента сложность продолжения поиска и защищает секреты реализации функции поиска. Если искомый текст указывает на символ null, все элементы считаются удовлетворяющими критериям поиска. cdc_entry search_cdc_entry(const char *cd_catalog_ptr, int *first_call_ptr) { static int local_first_call = 1; cdc_entry entry_to_return; datum local_data_datum; static datum local_key_datum; /* обратите внимание, должна быть static */ memset(&entry_to_return, '\0', sizeof(entry_to_return)); 14. Как всегда, начните с имеющих смысл проверок: if (!cdc_dbm_ptr || !cdt_dbm_ptr) return (entry_to_return); if (!cd_catalog_ptr || !first_call_ptr) return (entry_to_return); if (strlen(cd_catalog_ptr) >= CAT_CAT_LEN) return (entry_to_return); /* Защита от пропуска вызова с *first_call_ptr, равным true */ if (local_first_call) { local_first_call = 0; *first_call_ptr = 1; } 15. Если эта функция была вызвана с параметром *first_call_ptr, равным true, вы должны продолжить (или заново начать) поиск от начала базы данных. Если *first_call_ptrне равен true, просто переходите к следующему ключу в базе данных: if (*first_call_ptr) { *first_call_ptr = 0; local_key_datum = dbm_firstkey(cdc_dbm_ptr); } else { local_key_datum = dbm_nextkey(cdc_dbm_ptr); } do { if (local_key_datum.dptr != NULL) { /* Элемент был найден */ local_data_datum = dbm_fetch(cdc_dhm_ptr, local_key_datum); if (local_data_datum.dptr) { memcpy(&entry_to_return, (char*)local_data_datum.dptr, local_data_datum, dsize); 16. Функция поиска включает очень простую проверку, позволяющую увидеть, входит ли строка поиска в текущий элемент каталога. /* Проверяет, входит ли строка в текущий элемент */ if (!strstr(entry_to_return.catalog, cd_catalog_ptr)) { memset(&entry_to_return, '\0', sizeof(entry_to_return)); local_key_datum = dbm_nextkey(cdc_dbm_ptr); } } } } while (local_key_datum.dptr && local_data_datum.dptr && (entry_to_return.catalog[0] == '\0')); return (entry_to_return); } /* search_cdc_entry */ Теперь вы готовы собрать все вместе с помощью следующего make-файла или файла сборки. Не слишком углубляйтесь в него сейчас, поскольку мы обсудим его работу в следующей главе. В данный момент просто наберите его и сохраните как Makefile. all: application INCLUDE=/usr/include/gdbm LIBS=gdbm # В некоторых дистрибутивах вам, возможно, придется изменить предыдущую # строку, чтобы включить библиотеку совместимости, как показано далее # LIBS= -lgdbm_compat -lgdbm CFIAGS= app_ui.о: app_ui.с cd_data.h gcc $(CFLAGS) -c app_ui.c access.о: access.с cd_data.h gcc $(CFLAGS) -I$(INCLUDE) -c access.с application: app_ui.o access.о gcc $(CFLAGS) -o application app_ui.o access.о -l$(LIBS) clean: rm -f application *.o nodbmfiles: rm -f *.dir *.pag Для компиляции вашего нового приложения управления коллекцией компакт- дисков наберите следующую команду в командной строке: $ make Если все пройдет нормально, выполняемый файл application будет откомпилирован и помещен в текущий каталог. РезюмеВ этой главе вы узнали о трех аспектах управления данными. Сначала вы познакомились с системой управления памятью в ОС Linux, и убедились в простоте ее применения, несмотря на то, что на низком уровне в нее включена реализация виртуальной памяти с подкачкой страниц. Вы также увидели, как она защищает операционную систему и другие программы от попыток несанкционированного доступа к памяти. Затем мы перешли к рассмотрению того, как блокировка файлов позволяет многочисленным программам сотрудничать при получении доступа к данным. Сначала вы познакомились с простой двоичной схемой семафора и затем более сложной ситуацией, в которой вы блокируете участки файла, устанавливая разделяемый или исключительный доступ. Далее вы рассмотрели библиотеку dbm и ее возможности хранения и эффективного извлечения блоков данных благодаря очень гибкому механизму индексирования. В заключение, применив dbm как средство хранения данных, мы переработали проектное решение и заново переписали пример приложения, управляющего базой данных компакт-дисков. |
|
||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||