|
||||||||||||||||||||||
|
|
Глава 13Связь между процессами: каналы В главе 11 вы видели очень простой способ пересылки сообщений между процессами с помощью сигналов. Вы формировали уведомляющие события, которые могли бы применяться для вызова ответа, но передаваемая информация была ограничена номером сигнала. В этой главе вы познакомитесь с каналами, которые позволяют процессам обмениваться более полезной информацией. В конце этой главы вы примените свои вновь приобретенные знания для новой реализации программы, управляющей базой данных компакт-дисков, в виде клиент-серверного приложения. В данной главе мы обсудим следующие темы: □ определение канала; □ каналы процессов; □ вызовы каналов; □ родительские и дочерние процессы; □ именованные каналы — FIFO; □ замечания, касающиеся клиент-серверных приложений. Что такое канал?Мы применяем термин "канал" для обозначения соединения потока данных одного процесса с другим. Обычно вы присоединяете или связываете каналом вывод одного процесса с вводом другого. Большинство пользователей Linux уже знакомы с идеей конвейера, связывающего вместе команды оболочки так, что вывод одного процесса поставляет данные прямо во ввод другого. В случае команд оболочки это делается с помощью символа конвейера или канала, соединяющего команды следующим образом: cmd1 | cmd2 Командная оболочка организует стандартный ввод и вывод двух команд так, что: □ стандартный ввод cmd1поступает с клавиатуры терминала; □ стандартный вывод cmd1поставляется cmd2как ее стандартный ввод; □ стандартный вывод cmd2подсоединен к экрану терминала. На самом деле командная оболочка заново соединила потоки стандартных ввода и вывода так, что потоки данных проходят с клавиатурного ввода через две команды и выводятся на экран. На рис. 13.1 приведено визуальное представление этого процесса. 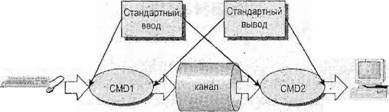 Рис. 13.1 В этой главе вы увидите, как достичь этого эффекта в программе и как можно использовать каналы для связи многих процессов, что позволит создать простую клиент-серверную систему. Каналы процессовВозможно, простейший способ передачи данных между программами — применение функций popenи pclose. У них следующие прототипы: #include <stdio.h> FILE *popen(const char *command, const char *open_mode); int pclose(FILE *stream_to_close); popenФункция popen позволяет программе запустить другую программу как новый процесс и либо передать ей данные, либо получить их из нее. Строка command— это имя программы для выполнения вместе с любыми параметрами, параметр open_modeдолжен быть "r"или "w". Если open_mode— "r", вывод вызванной программы становится доступен вызывающей программе и может быть считан из возвращаемого функцией popenфайлового потока FILE*с помощью обычных функций библиотеки stdio, предназначенных для чтения (например, fread). Но если open_mode— "w", программа может отправить данные вызванной команде с помощью вызова функции fwrite. Далее вызванная программа сможет читать данные из своего стандартного ввода. Обычно вызванная программа не знает, что она считывает данные из другого процесса; она просто читает свой поток стандартного ввода и воздействует на него. Вызов функции popenдолжен задавать "r"или "w"; никакого другого значения стандартной реализацией popen не поддерживается. Это означает, что вы не можете вызвать другую программу и одновременно читать из нее и писать в нее. В случае сбоя popenвозвращает пустой указатель. Если вы хотите создать двунаправленную связь с помощью каналов, стандартное решение — применить два канала: по одному для потока данных каждого направления. pcloseКогда процесс, стартовавший с помощью popen, закончится, вы можете закрыть файловый поток, связанный с ним, с помощью функции pclose. Вызов pcloseвернет управление, только когда процесс, запущенный с помощью popen, завершится. Если он все еще выполняется во время вызова pclose, вызов pcloseбудет ждать окончания процесса. Функция pcloseобычно возвращает код завершения процесса, чей файловый поток она закрывает. Если вызывающий процесс уже выполнил оператор waitперед вызовом pclose, статус завершения будет потерян, поскольку вызванный процесс закончен, и функция pcloseвернет -1 с переменной errno, получившей значение ECHILD. Выполните упражнение 13.1. Упражнение 13.1. Чтение вывода внешней программыДавайте опробуем простой пример popen1.c с функциями popenи pclose. Вы будете применять в программе popenдля доступа к информации из uname. uname— это команда, выводящая системную информацию, включая тип компьютера, имя ОС, версию и выпуск, а также сетевое имя машины. Запустив программу, вы откроете канал к uname; сделаете его читаемым и зададите read_fp, как указатель на вывод. В конце канал, на который указывает read_fp, закрывается. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { FILE *read_fp; char buffer[BUFSIZ +1]; int chars_read; memset(buffer, '\0', sizeof(buffer)); read_fp = popen("uname -a", "r"); if (read_fp ! = NULL) { chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp); if (chars_read > 0) { printf("Output was:-\n%s\n", buffer); } pclose(read_fp); exit(EXIT_SUCCESS); } exit(EXIT_FAILURE); } Когда вы выполните программу, то должны получить вывод, похожий на следующий (полученный на одной из машин авторов): $ ./popen1 Output was:- Linux suse103 2.6.20.2-2-default #1 SMP Fri Mar 9 21:54:10 UTC 2001 i686 i686 i386 GNU/Linux Как это работает Программа применяет функцию popenдля вызова команды unameс параметром -а. Затем она использует возвращенный файловый поток для чтения данных, до BUFSIZсимволов (как задано в директиве #defineиз файла stdio.h), и затем выводит их на экран. Поскольку вы перехватываете вывод команды uname внутри программы, его можно обрабатывать. Отправка вывода в popenТеперь, когда вы рассмотрели пример захвата вывода из внешней программы, давайте познакомимся с отправкой вывода во внешнюю программу. В упражнении 13.2 показана программа popen2.c, передающая по каналу данные другой программе. В этом примере будет использована команда od (от англ. octal dump — восьмеричный дамп). Упражнение 13.2. Пересылка вывода в другую программуВзглянув на следующий программный код, вы увидите, что он очень похож на предыдущий пример, за исключением того, что вы пишете данные в канал вместо чтения данных из него. Далее приведена программа popen2.c. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { FILE *write_fp; char buffer[BUFSIZ + 1]; sprintf(buffer, "Once upon a time, there was...\n"); write_fp = popen("od -c", "w"); if (write_fp != NULL) { fwrite(buffer, sizeof(char), strlen(buffer), write_fp); pclose(write_fp); exit(EXIT_SUCCESS); } exit(EXIT_FAILURE); } После выполнения этой программы вы должны получить следующий вывод: $ ./popen2 0000000 O n c e u p o n a t i m e 0000020 , t h e r e w a s . . . \n 0000037 Как это работает Программа применяет popenс параметром "w" для запуска команды od -стаким образом, что может отправить данные этой команде. Затем она отправляет строку, которую команда od -сполучает и обрабатывает; далее команда od -свыводит результат обработки в своем стандартном выводе. Такой же вывод можно получить из командной строки с помощью следующей команды: $ echo "Once upon a time, there was..." | od -c Передача данных большого объемаМеханизм, применявшийся до сих пор, просто отправляет и получает все данные в одном вызове freadили fwrite. Порой вам может понадобиться отправлять данные меньшими порциями или вы не будете знать размера вывода. Для того чтобы не объявлять слишком большой буфер, можно просто применить множественные вызовы freadили fwriteи обрабатывать данные порциями. В упражнении 13.3 приведена программа popen3.c, читающая все данные из канала. Упражнение 13.3. Чтение из канала данных большого объемаВ этой программе вы читаете данные из вызванного процесса ps ах. У вас нет возможности узнать заранее, какой величины будет вывод, поэтому вы должны разрешить множественные операции чтения из канала. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { FILE * read_fp; char buffer[BUFSIZ + 1]; int chars_read; memset(buffer, '\0' , sizeof(buffer)); read_fp = popen("ps ax", "r"); if(read_fp != NULL) { chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp); while (chars_read > 0) { buffer[chars_read - 1] = '\0'; printf("Reading %d:-\n %s\n", BUFSIZ, buffer); chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp); } pclose(read_fp); exit(EXIT_SUCCESS); } exit(EXIT_FAILURE); } Вывод, отредактированный для краткости, подобен приведенному далее: $ ./popen3 Reading 1024:- PID TTY STAT TIME COMMAND 1 ? Ss 0:03 init [5] 2 ? SW 0:00 [kflushd] 3 ? SW 0:00 [kpiod] 4 ? SW 0:00 [kswapd] 5 ? SW< 0:00 [mdrecoveryd] ... 240 tty2 S 0:02 emacs draft1.txt Reading 1024:- 368 tty1 S 0:00 ./popen 3 369 tty1 R 0:00 ps -ax 370 ... Как это работает Программа применяет функцию popenс параметром "r"аналогично программе popen1.c. В этот раз она продолжает чтение из файлового потока до тех пор, пока в нем есть данные. Учтите, что, хотя программе psнужно некоторое время для выполнения, Linux так организует планирование процессов, что обе программы выполняются, когда могут. Если у читающего процесса popen3 нет входных данных, он приостанавливается до появления доступных данных. Если записывающий процесс psформирует вывод, больший по объему, чем может вместить буфер, он приостанавливается до тех пор, пока считывающий процесс не обработает какой-то объем данных. В этом примере строка Reading:-может не появиться второй раз. Это означает, что BUFSIZбольше объема вывода команды ps. В некоторых (самых современных) системах Linux установлен размер буфера BUFSIZ, равный 8192 байт или даже больше. Для того чтобы проверить корректность работы программы при считывании нескольких порций вывода, попробуйте считывать за один раз меньше символов, чем BUFSIZ, может быть BUFSIZ/10. Как реализован вызов popenВызов popenвыполняет программу, которую вы запросили, прежде всего, вызывая командную оболочку shи передавая ей командную строку как аргумент. У этого процесса две стороны: приятная и не очень. В ОС Linux (как и во всех UNIX-подобных системах) подстановка всех параметров выполняется командной оболочкой, поэтому вызов оболочки для синтаксического анализа командной строки перед вызовом программы дает возможность командной оболочке выполнить любую подстановку, например, определить реальные файлы, на которые ссылается строка *.с до того, как программа начнет выполняться. Часто это очень полезно и позволяет запускать с помощью popenсложные команды оболочки. Другие функции создания процесса, например execl, гораздо сложнее применять для вызова, поскольку вызывающий процесс должен самостоятельно выполнять подстановки параметров командной оболочки. Нежелательный эффект применения командной оболочки состоит в том, что для каждого вызова popenвместе с требуемой программой вызывается командная оболочка. Далее каждый вызов popenпорождает запуск двух дополнительных процессов, что делает функцию popenнемного расточительной с точки зрения расходования системных ресурсов и вызов нужной команды выполняется медленнее, чем было бы в противном случае. В упражнении 13.4 приведена программа popen4.c, которую можно использовать для демонстрации поведения popen. Вы можете сосчитать количество строк во всех файлах с исходным текстом примеров семейства popen, применив команду catк файлам и затем пересылая по каналу вывод в команду wc -l, которая считает количество строк. В командной строке эквивалентная команда выглядит следующим образом: $ cat popen*.c | wc -l ПримечаниеУпражнение 13.4. Вызов popenзапускает командную оболочку Эта программа применяет в точности предыдущую команду, но с помощью popen, так что она может читать результат. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { FILE *read_fp; char buffer[BUFSIZ +1]; int chars_read; memset(buffer, '\0', sizeof(buffer)); read_fp = popen("cat popen*.с | wc -l", "r"); if (read_fp != NULL) { chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp); while (chars_read > 0) { buffer[chars_read - 1] = '\0'; printf("Reading:-\n %s\n", buffer); chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp); } pclose(read_fp); exit(EXIT_SUCCESS); } exit(EXIT_FAILURE); } Выполнив эту программу, вы получите следующий вывод: $ ./popen4 Reading:- 94 Как это работает Программа показывает, что вызывается командная оболочка для того, чтобы развернуть popen*.св список всех файлов, начинающихся с popenи заканчивающихся .с, а также для обработки символа канала ( |) и отправки вывода команды catв команду wс. Вы вызываете командную оболочку, программы cat и wcи задаете перенаправление — все в одном вызове popen. Программа, вызвавшая команду, видит только заключительный вывод. Вызов pipeВы познакомились с высокоуровневой функцией popen, а теперь пойдем дальше и рассмотрим низкоуровневую функцию pipe. Она предоставляет средства передачи данных между двумя программами без накладных расходов на вызов командной оболочки для интерпретации запрашиваемой команды. Эта функция также позволит вам лучше управлять чтением и записью данных. У функции pipeследующее объявление: #include <unistd.h> int pipe(int file_descriptor[2]); Функции pipeпередается указатель на массив из двух целочисленных файловых дескрипторов. Она заполняет массив двумя новыми файловыми дескрипторами и возвращает 0. В случае неудачи она вернет -1 и установит переменную errnoдля указания причины сбоя. В интерактивном справочном руководстве Linux на странице, посвященной функций pipe(в разделе 2 руководства), определены следующие ошибки: □ EMFILE— процесс использует слишком много файловых дескрипторов; □ ENFILE— системная таблица файлов полна; □ EFAULT— некорректный файловый дескриптор. Два возвращаемых файловых дескриптора подсоединяются специальным образом. Любые данные, записанные в file_descriptor[1], могут быть считаны обратно из file_descriptor[0]. Данные обрабатываются по алгоритму "первым пришел, первым обслужен", обычно обозначаемому как FIFO. Это означает, что если вы записываете байты 1, 2, 3в file_descriptor[1], чтение из file_descriptor[0]выполняется в следующем порядке: 1, 2, 3. Этот способ отличается от стека, который функционирует по алгоритму "последним пришел, первым обслужен", который обычно называют сокращенно LIFO. Примечание В упражнении 13.5 приведена программа pipe1.с, которая использует вызов pipeдля создания канала. Упражнение 13.5 Функция pipe Следующий пример — программа pipe1.c. Обратите внимание на массив file_pipes, который передается функции pipeкак параметр. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { int data_processed; int filepipes[2]; const char some_data[] = "123"; char buffer[BUFSIZ + 1]; memset(buffer, '\0', sizeof(buffer)); if (pipe(file_pipes) == 0) { data_processed = write(file_pipes[1], some_data, strlen(somedata)); printf("Wrote %d bytes\n", data_processed); data_processed = read(file_pipes[0], buffer, BUFSIZ); printf("Read %d bytes: %s\n", data_processed, buffer); exit(EXIT_SUCCESS); } exit(EXIT_FAILURE); } Если вы выполните программу, то получите следующий вывод: $ ./pipe1 Wrote 3 bytes Read 3 bytes: 123 Как это работает Программа создает канал с помощью двух файловых дескрипторов из массива file_pipes[]. Далее она записывает данные в канал, используя файловый дескриптор file_pipes[1], и считывает их обратно из file_pipes[0]. Учтите, что у канала есть внутренняя буферизация, позволяющая хранить данные между вызовами функций writeи read. Следует знать, что реакция на попытку писать с помощью дескриптора file_descriptor[0]или читать с помощью дескриптора file_descriptor[1]не определена, поэтому поведение программы может быть очень странным и меняться без каких-либо предупреждений. В системах авторов такие вызовы заканчивались аварийно и возвращали -1, что, по крайней мере, гарантирует легкость обнаружения такой ошибки. На первый взгляд этот пример использования канала ничего не предлагает такого, чего мы не могли бы сделать с помощью простого файла. Действительные преимущества каналов проявятся, когда вам нужно будет передавать данные между двумя процессами. Как вы видели в главе 11, когда программа создает новый процесс с помощью вызова fork, уже открытые к этому моменту файловые дескрипторы так и остаются открытыми. Создав канал в исходном процессе и затем сформировав с помощью forkновый процесс, вы сможете передать данные из одного процесса в другой через канал (упражнение 13.6). Упражнение 13.6. Каналы через вызов fork 1. Это пример pipe2.c. Он выполняется также как первый до того момента, пока вы не вызовете функцию fork. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { int data_processed; int file_pipes[2]; const char some_data[] = "123"; char buffer[BUFSIZ + 1]; pid_t fork_result; memset(buffer, '0', sizeof(buffer)); if (pipe(file_pipes) == 0) { fork_result = fork(); if (fork_result == -1) { fprintf(stderr, "Fork failure"); exit(EXIT_FAILURE); } 2. Вы убедились, что вызов forkотработал, поэтому, если его результат равен нулю, вы находитесь в дочернем процессе: if (fork_result == 0) { data_processed = read(file_pipes[0], buffer, BUFSIZ); printf("Read %d bytes: %s\n", data_processed, buffer); exit(EXIT_SUCCESS); } 3. В противном случае вы должны быть в родительском процессе: else { data_processed = write(file_pipes[1], some_data, strlen(some_data)); printf("Wrote %d bytes\n", data_processed); } } exit(EXIT_SUCCESS); } После выполнения этой программы вы получите вывод, аналогичный предыдущему: $ ./pipe2 Wrote 3 bytes Read 3 bytes: 123 Вы можете столкнуться с повторным выводом строки приглашения для ввода команды перед завершающим фрагментом вывода, поскольку родительский процесс завершится раньше дочернего, поэтому мы подчистили вывод, чтобы его легче было читать. Как это работает Сначала программа создает канал с помощью вызова pipe. Далее она применяет вызов forkдля создания нового процесса. Если forkзавершился успешно, родительский процесс пишет данные в канал, в то время как дочерний считывает данные из канала. Оба процесса, и родительский, и дочерний, завершаются после одного вызова writeи read. Если родительский процесс завершается раньше дочернего, вы можете увидеть между двумя выводами строку приглашения командной оболочки. Несмотря на то, что программа внешне похожа на первый пример pipe, мы сделали большой шаг вперед, получив возможность использовать разные процессы для чтения и записи (рис. 13.2). 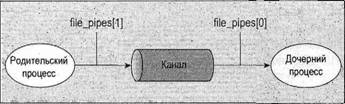 Рис. 13.2 Родительский и дочерний процессыСледующий логический шаг в нашем изучении вызова pipe— разрешить дочернему процессу быть другой программой, отличной от своего родителя, а не просто другим процессом, выполняющим ту же самую программу. Сделать это можно с помощью вызова exec. Единственная сложность заключается в том, что новому процессу, созданному exec, нужно знать, какой файловый дескриптор применять для доступа. В предыдущем примере этой проблемы не возникло, потому что дочерний процесс обращался к своей копии данных file_pipes. После вызова execвозникает другая ситуация, поскольку старый процесс заменен новым дочерним процессом. Эту проблему можно обойти, если передать файловый дескриптор (который, в конце концов, просто число) как параметр программе, вновь созданной с помощью вызова exec. Для того чтобы посмотреть, как это работает, вам понадобятся две программы (упражнение 13.7). Первая — поставщик данных. Она создает канал и затем вызывает дочерний процесс, потребитель данных. Упражнение 13.7. Каналы иexec 1. Для получения первой программы исправьте pipe2.c, превратив ее в pipe3.c. Измененные строки затенены. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { int data_processed; int file_pipes[2]; const char somedata[] = "123"; char buffer[BUFSIZ + 1]; pid_t fork_result; memset(buffer, '\0', sizeof(buffer)); if (pipe(file_pipes) == 0) { fork_result = fork(); if (fork_result == (pid_t)-1) { fprintf(stderr, "Fork failure"); exit(EXIT_FAILURE); } if (fork_result == 0) { sprintf(buffer, "%d", file_pipes[0]); (void)execl("pipe4", "pipe4", buffer, (char*)0); exit(EXIT_FAILURE); } else { data_processed = write(file_pipes[1], some_data, strlen(some_data)); printf ("%d - wrote %d bytes\n", getpid(), data_processed); } } exit(EXIT_SUCCESS); } 2. Программа-потребитель pipe4.c, читающая данные, гораздо проще: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main(int argc, char *argv[]) { int data_processed; char buffer[BUFSIZ + 1]; int file_descriptor; memset(buffer, '\0', sizeof(buffer)); sscanf(argv[1], "%d", &file_descriptor); data_processed = read(file_descriptor, buffer, BUFSIZ); printf("%d — read %d bytes: %s\n", getpid(), data_processed, buffer); exit(EXIT_SUCCESS); } Выполнив pipe3 и помня о том, что она вызывает программу pipe4, вы получите вывод, аналогичный приведенному далее: $ ./pipe3 22460 - wrote 3 bytes 22461 - read 3 bytes: 123 Как это работает Программа pipe3 начинается как предыдущий пример, используя вызов pipeдля создания канала и затем вызов forkдля создания нового процесса. Далее она применяет функцию sprintfдля сохранения в буфере номера файлового дескриптора чтения из канала, который формирует аргумент программы pipe4. Вызов execlприменен для вызова программы pipe4. В нем использованы следующие аргументы: □ вызванная программа; □ argv[0], принимающий имя программы; □ argv[1], содержащий номер файлового дескриптора, из которого программа должна читать; □ (char *)0, завершающий список параметров. Программа pipe4 извлекает номер файлового дескриптора из строки аргументов и затем читает из него данные. Чтение закрытых каналовПрежде чем двигаться дальше, необходимо более внимательно рассмотреть файловые дескрипторы, которые открыты. До этого момента вы разрешали читающему процессу просто читать какие-то данные и завершаться, полагая, что ОС Linux уберет файлы в ходе завершения процесса. В большинстве программ, читающих данные из стандартного ввода, это делается несколько иначе, чем в виденных вами до сих пор примерах. Обычно программы не знают, сколько данных они должны считать, поэтому они, как правило, выполняют цикл — чтение данных, их обработка и затем снова чтение данных и так до тех пор, пока не останется данных для чтения. Вызов readобычно будет задерживать выполнение процесса, т.е. он заставит процесс ждать до тех пор, пока не появятся данные. Если другой конец канала был закрыт, следовательно, нет ни одного процесса, имеющего канал для записи, и вызов readблокируется. Поскольку это не очень полезно, вызов read, пытающийся читать из канала, не открытого для записи, возвращает 0 вместо блокирования. Это позволит читающему процессу обнаружить канальный эквивалент метки "конец файла" и действовать соответствующим образом. Учтите, что это не то же самое, что чтение некорректного дескриптора файла, которое вызов read считает ошибкой и обозначает возвратом -1. Если вы применяете канал с вызовом fork, есть два файловых дескриптора, которые можно использовать для записи в канал: один в родительском, а другой в дочернем процессах. Вы должны закрыть файловые дескрипторы записи в канал в обоих этих процессах, прежде чем канал будет считаться закрытым и вызов readдля чтения из канала завершится аварийно. Мы рассмотрим пример этого позже, когда вернемся к данной теме, для того чтобы подробно обсудить флаг O_NONBLOCKи каналы FIFO. Каналы, применяемые как стандартные ввод и выводТеперь, когда вы знаете, как заставить вызов read, примененный к пустому каналу, завершиться аварийно, можно рассмотреть более простой метод соединения каналом двух процессов. Вы устраиваете так, что у одного из файловых дескрипторов канала будет известное значение, обычно стандартный ввод, 0, или стандартный вывод, 1. Его немного сложнее установить в родительском процессе, но при этом значительно упрощается программа дочернего процесса. Одно неоспоримое достоинство заключается в том, что вы можете вызывать стандартные программы, которым не нужен файловый дескриптор как параметр. Для этого вам следует применить функцию dup, с которой вы встречались в главе 3. Существуют две тесно связанные версии функции dup, которые объявляются следующим образом: #include <unistd.h> int dup(int file_descriptor); int dup2(int file_descriptor_one, int file_descriptor_two); Назначение вызова dup— открыть новый дескриптор файла, немного похоже на то, как это делает вызов open. Разница в том, что файловый дескриптор, созданный dup, ссылается на тот же файл (или канал), что и существующий файловый дескриптор. В случае вызова dupновый файловый дескриптор всегда имеет самый маленький доступный номер, а в случае dup2— первый доступный дескриптор, больший чем значение параметра file_descriptor_two. Примечание Итак, как же dupпомогает в обмене данными между процессами? Хитрость кроется в знании того, что дескриптор стандартного файла ввода всегда 0 и что dupвсегда возвращает новый файловый дескриптор, применяя наименьший доступный номер. Сначала закрыв дескриптор 0, а затем вызвав dup, вы получите новый файловый дескриптор с номером 0. Поскольку новый файловый дескриптор — это дубликат существующего, стандартный ввод изменится и получит доступ к файлу или каналу, файловый дескриптор которого вы передали в функцию dup. В результате вы создадите два файловых дескриптора, которые ссылаются на один и тот же файл или канал и один из них будет стандартным вводом. Управление файловым дескриптором с помощью close и dup Легче всего понять, что происходит, когда вы закрываете файловый дескриптор 0 и затем вызываете dup, если рассмотреть состояние первых четырех файловых дескрипторов, изменяющихся последовательно друг за другом (табл. 13.1). Таблица 13.1
А теперь выполните упражнение 13.8. Упражнение 13.3. Каналы иdup Давайте вернемся к предыдущему примеру, но на этот раз вы измените дочернюю программу, заменив в ней файловый дескриптор stdin концом считывания readсозданного вами канала. Вы также выполните некоторую реорганизацию файловых дескрипторов, чтобы дочерняя программа могла правильно определить конец данных в канале. Как обычно, мы пропустили некоторые проверки ошибок для краткости. Превратите программу pipe3.c в pipe5.c с помощью следующего программного кода: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> int main() { int data_processed; int file pipes[2]; const char some_data[] = "123"; pid_t fork_result; if (pipe(file_pipes) == 0) { fork_result = fork(); if (fork_result == (pid_t)-1) { fprintf(stderr, "Fork failure"); exit(EXIT_FAILURE); } if (fork_result == (pid_t)0) { close(0); dup(file_pipes[0]; close(file_pipes[0]); close(file_pipes[1]); execlp("od", "od", "-c", (char*)0); exit(EXIT_FAILURE); } else { close(file_pipes[0]); data_processed = write(file_pipes[1], some_data, strlen(some_data)); close(file_pipes[1]); printf("%d — wrote %d bytes\n", (int)getpid(), data_processed); } } exit(EXIT_SUCCESS); } У этой программы следующий вывод: $ ./pipe5 22495 - wrote 3 bytes 0000000 1 2 3 0000003 Как это работает Как и прежде, программа создает канал, затем выполняет вызов fork, создавая дочерний процесс. В этот моменту обоих процессов, родительского и дочернего, есть файловые дескрипторы для доступа к каналу, по одному для чтения и записи, т.е. всего четыре открытых файловых дескриптора. Давайте первым рассмотрим дочерний процесс. Он закрывает свой стандартный ввод с помощью close(0)и затем вызывает dup(file_pipes[0]). Этот вызов дублирует файловый дескриптор, связанный с концом readканала, как файловый дескриптор 0, стандартный ввод. Далее дочерний процесс закрывает исходный файловый дескриптор для чтения из канала, file_pipes[0]. Поскольку этот процесс никогда не будет писать в канал, он также закрывает файловый дескриптор для записи в канал, file_pipes[1]. Теперь у дочернего процесса единственный файловый дескриптор, связанный с каналом, файловый дескриптор 0, его стандартный ввод. Далее дочерний процесс может применить execдля вызова любой программы, которая читает стандартный ввод. В данном случае мы используем команду od. Команда odбудет ждать, когда данные станут ей доступны, как если бы она ждала ввода с терминала пользователя. В действительности без специального программного кода, позволяющего непосредственно выяснить разницу, она не будет знать, что ввод приходит из канала, а не с терминала. Родительский процесс начинает с закрытия конца чтения канала, file_pipes[0], потому что он никогда не будет читать из канала. Затем он пишет данные в канал. Когда все данные записаны, родительский процесс закрывает конец записи в канал и завершается. Поскольку теперь нет файловых дескрипторов, открытых для записи в канал, программа odсможет считать три байта, записанных в канал, но последующие операции чтения далее будут возвращать 0 байтов, указывая на конец файла. Когда readвернет 0, программа odзавершится. Это аналогично выполнению команды od, введенной с терминала, и последующему нажатию комбинации клавиш <Ctrl>+<D> для отправки признака конца файла команде od. На рис. 13.3 показан результат вызова pipe, на рис. 13.4 — результат вызова fork, а на рис. 13.5 представлена программа, когда она готова к передаче данных.  Рис. 13.3  Рис. 13.4 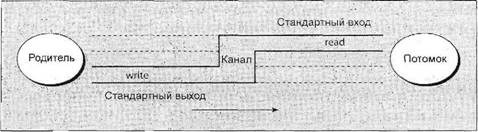 Рис. 13.5 Именованные каналы: FIFOДо сих пор вы могли передавать данные только между связанными программами, т.е. программами, которые стартовали из общего процесса-предка. Часто это очень неудобно, хотелось бы, чтобы и у несвязанных процессов была возможность обмениваться данными. Вы можете сделать это с помощью каналов FIFO, часто называемых именованными каналами. Именованный канал — это файл специального типа (помните, что в ОС Linux все, что угодно, — файл!), существующий в виде имени в файловой системе, но ведущий себя как неименованные каналы, которые вы уже встречали. Вы можете создавать именованные каналы из командной строки и внутри программы. С давних времен программой создания их в командной строке была команда mknod: $ mknod имя_файла p Однако команды mknodнет в списке команд X/Open, поэтому она включена не во все UNIX-подобные системы. Предпочтительнее применять в командной строке $ mkfifo имя_файла Примечание Внутри программы можете применять два разных вызова: #include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *filename, mode_t mode); int mknod(const char* filename, mode_t mode | S_IFIFO, (dev_t)0); Помимо команды mknodвы можете использовать функцию mknodдля создания файлов специальных типов. Единственный переносимый вариант применения этой функции, создающий именованный канал, — использование значения 0 типа dev_tи объединений с помощью операции or режима доступа к файлу и S_IFIFO. В примерах мы будем применять более простую функцию mkfifo. Итак, выполните упражнение 13.9. Упражнение 13.9. Создание именованного каналаДалее приведен исходный текст примера fifo1.c. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <sys/types.h> #include <sys/stat.h> int main() { int res = mkfifo("/tmp/my_fifo", 0777); if (res == 0) printf ("FIFO created\n"); exit(EXIT_SUCCESS); } Вы можете создать канал и заглянуть в него: $ ./fifo1 FIFO created $ ls -lF /tmp/my_fifo prwxr-xr-x 1 rick users 0 2007-06-16 17:18 /tmp/my_fifo| Обратите внимание на то, что первый символ вывода — р, обозначающий канал. Символ |в конце добавлен опцией -Fкоманды lsи тоже обозначает канал. Как это работает Программа применяет функцию mkfifoдля создания специального файла. Несмотря на то, что запрашиваете режим 0777, он заменяется пользовательской маской ( umask), устанавливаемой (в данном случае 022) точно так же, как при создании обычного файла, поэтому у результирующего файла режим 755. Если ваша umaskустановлена иначе, например, ее значение 0002, вы увидите другие права доступа у созданного файла. Удалить FIFO можно как традиционный файл с помощью команды rmили внутри программы посредством системного вызова unlink. Доступ к FIFOУ именованных каналов есть одно очень полезное свойство: поскольку они появляются в файловой системе, их можно применять в командах на месте обычного имени файла. Прежде чем вы продолжите программирование с использованием созданного вами файла FIFO, давайте исследуем поведение такого файла с помощью обычных команд для работы с файлом (упражнение 13.10). Упражнение 13.10. Организации доступа к файлу FIFO1. Сначала попробуйте прочесть (пустой) файл FIFO: $ cat < /tmp/my_fifo 2. Теперь попытайтесь записать в FIFO. Вам придется использовать другой терминал, поскольку первая команда в данный момент "зависла" в ожидании появления каких-нибудь данных в FIFO: $ echo "Hello World" > /tmp/my_fifo Вы увидите вывод команды cat. Если не посылать никаких данных в канал FIFO, команда catбудет ждать до тех пор, пока вы не прервете ее выполнение, традиционно комбинацией клавиш <Ctrl>+<C>. 3. Можно выполнить обе команды одновременно, переведя первую в фоновый режим: $ cat < /tmp/my_fifo & [1] 1316 $ echo "Hello World" > /tmp/my_fifo Hello World [1]+ Done cat </tmp/my_fifo $ Как это работает Поскольку в канале FIFO не было данных, обе команды, catи echo, приостанавливают выполнение, ожидая, соответственно, поступления каких-нибудь данных и какого-либо процесса для их чтения. На третьем шаге процесс catс самого начала заблокирован в фоновом режиме. Когда echoделает доступными некоторые данные, команда catчитает их и выводит в стандартный вывод. Обратите внимание на то, что она затем завершается, не дожидаясь дополнительных данных. Программа catне блокируется, т.к. канал уже закрылся, когда завершилась вторая команда, поместившая данные в FIFO, поэтому вызовы readв программе catвернут 0 байтов, обозначая этим конец файла. Теперь, когда вы посмотрели, как ведут себя каналы FIFO при обращении к ним с помощью программ командной строки, давайте рассмотрим более подробно программный интерфейс, предоставляющий больше возможностей управления операциями чтения и записи при организации доступа к FIFO. ПримечаниеОткрытие FIFO с помощью open Основное ограничение при открытии канала FIFO состоит в том, что программа не может открыть FIFO для чтения и записи с режимом O_RDWR. Если программа нарушит это ограничение, результат будет непредсказуемым. Это очень разумное ограничение, т.к., обычно канал FIFO применяется для передачи данных в одном направлении, поэтому нет нужды в режиме O_RDWR. Процесс стал бы считывать обратно свой вывод, если бы канал был открыт для чтения/записи. Если вы действительно хотите передавать данные между программами в обоих направлениях, гораздо лучше использовать пару FIFO или неименованных каналов, по одному для каждого направления передачи, или (что нетипично) явно изменить направление потока данных, закрыв и снова открыв канал FIFO. Мы вернемся к двунаправленному обмену данными с помощью каналов FIFO чуть позже в этой главе. Другое различие между открытием канала FIFO и обычного файла заключается в использовании флага open_flag(второй параметр функции open) со значением O_NONBLOCK. Применение этого режима openизменяет способ обработки не только вызова open, но и запросов readи writeдля возвращаемого файлового дескриптора. Существует четыре допустимых комбинации значений O_RDONLY, O_WRONLYи O_NONBLOCKфлага. Рассмотрим их все по очереди. open(const char *path, O_RDONLY); В этом случае вызов openблокируется, он не вернет управление программе до тех пор, пока процесс не откроет этот FIFO для записи. Это похоже на первый пример с командой cat. open(const char *path, O_RDONLY | O_NONBLOCK); Теперь вызов openзавершится успешно и вернет управление сразу, даже если канал FIFO не был открыт для записи каким-либо процессом. open(const char *path, O_WRONLY); В данном случае вызов openбудет заблокирован до тех пор, пока процесс не откроет тот же канал FIFO для чтения. open(const char *path, O_WRONLY | O_NONBLOCK); Этот вариант вызова всегда будет возвращать управление немедленно, но если ни один процесс не открыл этот канал FIFO для чтения, openвернет ошибку, -1, и FIFO не будет открыт. Если есть процесс, открывший FIFO для чтения, возвращенный файловый дескриптор может использоваться для записи в канал FIFO. Примечание Выполните упражнение 13.11. Упражнение 13.11. Открытие файлов FIFOТеперь рассмотрим, как можно использовать поведение вызова openс флагом, содержащим O_NONBLOCK, для синхронизации двух процессов. Вместо применения нескольких программ-примеров вы напишите одну тестовую программу fifo2.c, которая позволит исследовать поведение каналов FIFO при передаче ей разных параметров. 1. Начните с заголовочных файлов, директивы #defineи проверки правильности количества предоставленных аргументов командной строки: #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <fcntl.h> #include <sys/types.h> #include <sys/stat.h> #define FIFO_NAME "/tmp/my_fifo" int main(int argc, char *argv[]) { int res; int open_mode = 0; int i; if (argc < 2) { fprintf(stderr, "Usage: %s <some combination of\ O_RDONLY O_WRONLY O_NONBLOCK>\n", *argv); exit(EXIT_FAILURE); } 2. Полагая, что программа передает тестовые данные, вы задаете параметр open_modeиз следующих аргументов: for(i = 1; i <argc; i++) { if (strncmp(*++argv, "O_RDONLY", 8) == 0) open_mode |= O_RDONLY; if (strncmp(*argv, "O_WRONLY", 8) == 0) open_mode |= O_WRONLY; if (strncmp(*argv, "O_NONBLOCK", 10) == 0) open_mode |= O_NONBLOCK; } 3. Далее проверьте, существует ли канал FIFO, и при необходимости создайте его. Затем FIFO открывается, и пока программа засыпает на короткое время, выполняется результирующий вывод. В заключение FIFO закрывается. if (access(FIFO_NAME, F_OK) == -1) { res = mkfifo(FIFO_NAME, 0777); if (res != 0) { fprintf(stderr, "Gould not create fifo %s\n", FIFO_NAME); exit(EXIT_FAILURE); } } printf("Process %d opening FIF0\n", getpid()); res = open(FIFO_NAME, open_mode); printf("Process %d result %d\n", getpid(), res); sleep(5); if (res != -1) (void)close(res); printf("Process %d finished\n", getpid()); exit(EXIT_SUCCESS); } Как это работает Эта программа позволяет задать в командной строке комбинации значений O_RDONLY, O_WRONLYи O_NONBLOCK, которые вы хотите применить. Делается это сравнением известных строк с параметрами командной строки и установкой (с помощью |=) соответствующего флага при совпадении строки. В программе используется функция access, проверяющая, существует ли уже файл FIFO, и создающая его при необходимости. Никогда не уничтожайте FIFO, т.к. у вас нет способа узнать, не использует ли FIFO другая программа. O_RDONLY и O_WRONLY без O_NONBLOCKТеперь у вас есть тестовая программа, и вы можете проверить комбинации пар. Обратите внимание на то, что первая программа, считыватель, помещена в фоновый режим. $ ./fifo2 O_RDONLY & [1] 152 Process 152 opening FIFO $ ./fifo2 O_WRONLY Process 153 opening FIFO Process 152 result 3 Process 153 result 3 Process 152 finished Process 153 finished Это, наверное, самое распространенное применение именованных каналов. Оно позволяет читающему процессу стартовать и ждать в вызове open, а затем разрешает обеим программам продолжить выполнение, когда вторая программа откроет канал FIFO. Обратите внимание на то, что и читающий, и пишущий процессы были синхронизированы вызовом open. ПримечаниеO_RDONLY с O_NONBLOCK и O_WRONLY В следующем примере читающий процесс выполняет вызов openи немедленно продолжается, даже если нет ни одного пишущего процесса. Пишущий процесс тоже немедленно продолжает выполняться после вызова open, потому что канал FIFO уже открыт для чтения. $ ./fifо2 O_RDONLY O_NONBLOCK & [1] 160 Process 160 opening fifo $ ./fifo2 O_WRONLY Process 161 opening FIFO Process 160 result 3 Process 161 result 3 Process 160 finished Process 161 finished [1]+ Done ./fifo2 O_RDONLY O_NONBLOCK Эти два примера — вероятно, самые распространенные комбинации режимов open. Не стесняйтесь использовать программу-пример для экспериментов с другими возможными комбинациями. Чтение из каналов FIFO и запись в них Применение режима O_NONBLOCKвлияет на поведение вызовов readи writeв каналах FIFO. Вызов read, применяемый для чтения из пустого блокирующего FIFO (открытого без флага O_NONBLOCK), будет ждать до тех пор, пока не появятся данные, которые можно прочесть. Вызов read, применяемый в неблокирующем FIFO, напротив, при отсутствии данных вернет 0 байтов. Вызов writeдля записи в полностью блокирующий канал FIFO будет ждать до тех пор, пока данные не смогут быть записаны. Вызов write, применяемый к FIFO, который не может принять все байты, предназначенные для записи, либо: □ будет аварийно завершен, если был запрос на запись PIPE_BUFбайтов или меньше и данные не могут быть записаны; □ запишет часть данных, если был запрос на запись более чем PIPE_BUFбайтов, и вернет количество реально записанных байтов, которое может быть и 0. Размер FIFO — очень важная характеристика. Существует накладываемый системой предел объема данных, которые могут быть в FIFO в любой момент времени. Он задается директивой #define PIPE_BUF, обычно находящейся в файле limits.h. В ОС Linux и многих других UNIX-подобных системах он обычно равен 4096 байт, но в некоторых системах может быть и 512 байт. Система гарантирует, что операции записи PIPE_BUF или меньшего количества байтов в канал FIFO, который был открыт O_WRONLY(т.е. блокирующий), запишут или все байты, или ни одного. Несмотря на то, что этот предел не слишком важен в простом случае с одним записывающим каналом FIFO и одним читающим FIFO, очень распространено использование одного канала FIFO, позволяющего разным программам отправлять запросы к этому единственному каналу FIFO. Если несколько разных программ попытаются писать в FIFO в одно и то же время, жизненно важно, чтобы блоки данных из разных программ не перемежались друг с другом, т. е. каждая операция write должна быть "атомарной". Как это сделать? Если вы ручаетесь, что все ваши запросы writeадресованы блокирующему каналу FIFO и их размер меньше PIPE_BUFбайтов, система гарантирует, что данные никогда не будут разделены. Вообще это неплохая идея — ограничить объем данных, передаваемых через FIFO блоком в PIPE_BUFбайтов, если вы не используете единственный пишущий и единственный читающий процессы. Выполните упражнение 13.12. Упражнение 13.12. Связь процессов с помощью каналов FIFOДля того чтобы увидеть, как несвязанные процессы могут общаться с помощью именованных каналов, вам понадобятся две отдельные программы fifo3.c и fifo4.c. 1. Первая программа — поставщик. Она создает канал, если требуется, и затем записывает в него данные как можно быстрее. Примечание #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <fcntl.h> #include <limits.h> #include <sys/types.h> #include <sys/stat.h> #define FIFO_NAME "/tmp/my_fifo" #define BUFFER_SIZE PIPE_BUF #define TEN_MEG (1024 * 1024 * 10) int main() { int pipe_fd; int res; int open_mode = O_WRONLY; int bytes_sent = 0; char buffer[BUFFER_SIZE + 1]; if (access(FIFO_NAME, F_OK) == -1) { res = mkfifo(FIFO_NAME, 0777); if (res != 0) { fprintf(stderr, "Could not create fifo %s\n", FIFO_NAME); exit(EXIT_FAILURE); } } printf("Process %d opening FIFO O_WRONLY\n", getpid()); pipe_fd = open(FIFO_NAME, open_name); printf("Process %d result %d\n", getpid(), pipe_fd); if (pipe_fd != -1) { while (bytes_sent < TEN_MEG) { res = write(pipe_fd, buffer, BUFFER_SIZE); if (res == -1) { fprintf(stderr, "Write error on pipe\n); exit(EXIT_FAILURE); } bytes_sent += res; } (void)close(pipe_fd); } else { exit(EXIT_FAILURE); } printf("Process %d finished\n", getpid()); exit(EXIT_SUCCESS); } 2. Вторая программа, потребитель, гораздо проще. Она читает и выбрасывает данные из канала FIFO. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <fcntl.h> #include <limits.h> #include <sys/types.h> #include <sys/stat.h> #define FIFO_NAME "/tmp/my_fifo" #define BUFFER_SIZE PIPE_BUF int main() { int pipe_fd; int res; int open_mode = O_RDONLY; char buffer[BUFFER_SIZE - 1]; int bytes_read = 0; memset(buffer, '\0', sizeof(buffer)); printf("Process %d opening FIFO O_RDONLY\n", getpid()); pipe_fd = open(FIFO_NAME, open_mode); printf("Prосеss %d result %d\n", getpid(), pipe_fd); if (pipe_fd != -1) { do { res = read(pipe_fd, buffer,BUFFER_SIZE); bytes_read += res; } while (res > 0); (void)close(pipe_fd); } else { exit(EXIT_FAILURE); } printf("Process %d finished, %d bytes read\n", getpid(), bytes_read); exit(EXIT_SUCCESS); } Когда вы выполните эти программы одновременно, с использованием команды timeдля хронометража читающего процесса, то получите следующий (с некоторыми пропусками для краткости) вывод: $ ./fifo3 & [1] 375 Process 375 opening FIFO O_WRONLY $ time ./fifo4 Process 377 opening FIFO O_RDONLY Process 375 result 3 Process 377 result 3 Process 375 finished Process 377 finished, 10485760 bytes read real 0m0.053s user 0m0.020s sys 0m0.040s [1]+ Done ./fifo3 Как это работает Обе программы применяют FIFO в режиме блокировки. Вы запускаете первой программу fifo3 (пишущий процесс/поставщик), которая блокируется, ожидая, когда читающий процесс откроет канал FIFO. Когда программа fifo4 (потребитель) запускается, пишущий процесс разблокируется и начинает записывать данные в канал. В это же время читающий процесс начинает считывать данные из канала. Примечание Вывод команды timeпоказывает, что читающему процессу потребовалось гораздо меньше одной десятой секунды для считывания 10 Мбайт данных в процесс. Это свидетельствует о том, что каналы, по крайней мере, их реализация в современных версиях Linux, могут быть эффективным средством обмена данными между программами. Более сложная тема: применение каналов FIFO в клиент-серверных приложенияхЗаканчивая обсуждение каналов FIFO, давайте рассмотрим возможность построения очень простого клиент-серверного приложения, применяющего именованные каналы. Вы хотите, чтобы один серверный процесс принимал запросы, обрабатывал их и возвращал результирующие данные запрашивающей стороне — клиенту. Вам нужно разрешить множественным клиентским процессам отправлять данные серверу. Для простоты предположим, что данные, которые нужно обработать, можно разбить на блоки, каждый из которых меньше PIPE_BUFбайтов. Конечно, реализовать такую систему можно разными способами, но мы рассмотрим только один, как иллюстрацию применения именованных каналов. Поскольку сервер будет обрабатывать только один блок данных в каждый момент времени, кажется логичным создать один канал FIFO, который читается сервером и в который записывают всё клиенты. Если открыть FIFO в блокирующем режиме, сервер и клиенты будут при необходимости блокироваться. Возвращать обработанные данные клиентам немного сложнее. Вам придется организовать второй канал для возвращаемых данных, один для каждого клиента. Если передавать идентификатор (PID) процесса-клиента в исходных данных, отправляемых на сервер, обе стороны смогут использовать его для генерации уникального имени канала с возвращаемыми данными. Выполните упражнение 13.13. Упражнение 13.13. Пример клиент-серверного приложения1. Прежде всего, вам нужен заголовочный файл client.h, в котором определены данные, общие для серверных и клиентских программ. В приложение также для удобства включены требуемые системные заголовочные файлы. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <fcntl.h> #include <limits.h> #include <sys/types.h> #include <sys/stat.h> #define SERVER_FIFO_NAME "/tmp/serv_fifo" #define CLIENT_FIFO_NAME "/tmp/cli_%d_fifo" #define BUFFER_SIZE 20 struct data_to_pass_st { pid_t client_pid; char some_data[BUFFER_SIZE - 1]; }; 2. Теперь займемся серверной программой server.c. В этом разделе вы создаете и затем открываете канал сервера. Он задается в режиме "только для чтения" и с блокировкой. После засыпания (из демонстрационных соображений) сервер читает данные от клиента, у которого есть структура типа data_to_pass_st. #include "client.h" #include <ctype.h> int main() { int server_fifo_fd, client fifo_fd; struct data_to_pass_st my_data; int read_res; char client_fifo[256]; char *tmp_char_ptr; mkfifo(SERVER_FIFO_NAME, 0777); server_fifo_fd = open(SERVER_FIFO_NAME, O_RDONLY); if (server_fifo_fd == -1) { fprintf(stderr, "Server fifo failure\n"); exit(EXIT_FAILURE); } sleep(10); /* для целей демонстрации разрешает клиентам создать очередь */ do { read_res = read(server_fifo_fd, &my_data, sizeof(my_data)); if (read res > 0) { 3. На следующем этапе вы выполняете некоторую обработку данных, только что полученных от клиента: преобразуете все символы в некоторых данных в прописные и соединяете CLIENT_FIFO_NAMEс полученным идентификатором client_pid. tmp_char_ptr = my_data.some_data; while (*tmp_char_ptr) { *tmp_char_ptr = toupper(* tmp_char_ptr); tmp_char_ptr++; } sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid); 4. Далее отправьте обработанные данные назад, открыв канал клиентской программы в режиме "только для записи" и с блокировкой. В заключение закройте серверный FIFO с помощью закрытия файла и отсоединения FIFO. client_fifo_fd = open(client_fifo, O_WRONLY); if (client_fifo_fd ! = -1) { write(client_fifo_fd, &my_data, sizeof(my_data)); close(client_fifo_fd); } } } while (read_res > 0); close(server_fifo_fd); unlink(SERVER_FIFO_NAME); exit(EXIT_SUCCESS); } 5. Далее приведена клиентская программа client.с. В первой части этой программы FIFO сервера, если он уже существует, открывается как файл. Далее программа получает идентификатор собственного процесса, который формирует некие данные, которые будут отправляться на сервер. Создается FIFO клиента, подготовленный для следующего раздела. #include "client.h" #include <ctype.h> int main() { int server_fifo_fd, client_fifo_fd; struct data_to_pass_st my_data; int times_to_send; char client_fifo[256]; server_fifo_fd = open(SERVER_FIFO_NAME, O_WRONLY); if (server_fifo_fd == -1) { fprintf (stderr, "Sorry, no server\n"); exit(EXIT_FAILURE); } my_data.client_pid = getpid(); sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid); if (mkfifo(client_fifo, 0777) == -1) { fprintf(stderr, "Sorry, can't make %s\n", client_fifo); exit(EXIT_FAILURE); } 6. В каждом из пяти проходов цикла клиентские данные отправляются на сервер. Далее клиентский FIFO открывается (в режиме "только для чтения" с блокировкой) и данные считываются обратно. В конце серверный FIFO закрывается, а клиентский FIFO удаляется из файловой системы. for (times_to_send = 0; times_to_send < 5; times_to_send++) { sprintf(my_data.some_data, "Hello from %d", my_data.client_pid); printf("%d sent %s, ", my_data.client_pid, my_data.some_data); write(server_fifo_fd, &my_data, sizeof(my_data)); client_fifo_fd = open(client_fifo, O_RDONLY); if (client_fifo_fd != -1) { if (read(client_fifo_fd, &my_data, sizeof(my_data)) > 0) { printf("received: %s\n", my_data.some_data); } close(client_fifo_fd); } } close(server_fifo_fd); unlink(client_fifo); exit(EXIT_SUCCESS); } Для тестирования этого приложения вам необходимо запустить единственную копию сервера и несколько клиентов. Для того чтобы запустить их приблизительно в одно и то же время, примените следующие команды командной оболочки. $ ./server & $ for i in 1 2 3 4 5 do ./client & done $ Они запускают один серверный процесс и пять клиентских. Вывод клиентских программ, отредактированный для краткости, выглядит следующим образом: 531 sent Hello from 531, received: HELLO FROM 531 532 sent Hello from 532, received: HELLO FROM 532 529 sent Hello from 529, received: HELLO FROM 529 530 sent Hello from 530, received: HELLO FROM 530 531 sent Hello from 531, received: HELLO FROM 531 532 sent Hello from 532, received: HELLO FROM 532 Как видно из данного вывода, запросы разных клиентов перемежаются, но каждый клиент получает соответствующим образом обработанные и возвращаемые ему данные. Имейте в виду, что вы можете увидеть или не увидеть чередование запросов, т.к. порядок получения клиентских запросов может меняться от машины к машине и даже в разных сеансах работы приложения на одной машине. Как это работает Теперь мы обсудим последовательность клиентских и серверных операций во взаимодействии, чего не делали до сих пор. Сервер создает свой канал FIFO в режиме "только чтение" и блокируется. Он делает это до тех пор, пока первый клиентский процесс не подсоединится, открыв тот же FIFO для записи. В этот момент серверный процесс разблокируется и выполняется вызов sleep, поэтому вызовы writeклиентов образуют очередь. (В реальном приложении вызов sleepможет быть удален, мы применяем его только чтобы продемонстрировать корректное функционирование программы с множественными одновременно действующими клиентами.) Между тем, после того как клиентский процесс открыл серверный канал FIFO, он создает собственный FIFO с уникальным именем для считывания данных с сервера. Только после этого клиент записывает данные на сервер (причем, если канал полон или сервер все еще спит, клиентская программа блокируется) и затем блокирует для вызова readсвой собственный канал FIFO, ожидая ответа. Получив данные от клиента, сервер обрабатывает их, открывает клиентский канал для записи и записывает в него данные, что снимает блокировку клиентского процесса. Когда клиент разблокирован, он может читать из своего канала данные, записанные туда сервером. Процесс повторяется полностью до тех пор, пока последний клиент не закроет канал сервера, вызывая аварийное завершение серверного вызова read (возвращение 0), поскольку ни у одного процесса нет серверного канала, открытого для записи. Если бы это был реальный серверный процесс, вынужденный ожидать будущих клиентов, возможно, вам пришлось бы изменить его, выбрав одно из двух: □ открыть файловый дескриптор собственного серверного канала, чтобы вызов readвсегда его блокировал, а не возвращал 0; □ закрыть и повторно открыть серверный канал, когда readвернет 0 байтов, чтобы серверный процесс блокировался вызовом open, ожидая клиента, так, как он это делал, стартуя первый раз. Оба эти метода проиллюстрированы в новом варианте приложения для работы с базой данных компакт-дисков, использующем именованные каналы. Приложение для работы с базой данных компакт-дисковТеперь, зная, как применять именованные каналы для реализации простой клиент-серверной системы, вы можете пересмотреть приложение для работы с базой данных компакт-дисков и соответствующим образом переработать его. Вы включите в него также некоторую обработку сигналов, позволяющую выполнить кое-какие действия по наведению порядка при прерывании процесса. Будет использоваться более ранняя версия приложения с dbm и интерфейсом командной строки, чтобы исходный текст программы был максимально простым и понятным. Прежде чем подробно рассматривать эту новую версию, необходимо откомпилировать приложение. Если вы взяли исходный код с Web-сайта, примените make-файл для его компиляции и получения серверной и клиентской программ. Примечание Выполнение команды server -iпозволяет программе инициализировать новую базу данных компакт-дисков. Нет нужды говорить о том, что клиент не выполнится, пока сервер не установится и не запустится. Далее приведен make-файл, показывающий, как совмещаются программы: all: server client CC=cc CFLAGS= -pedantic -Wall # Для отладки удалите знак комментария в следующей строке # DFLAGS=-DDEBUG_TRACE=1 -g # Где и какую версию dbm мы применяем. # Предполагается, что gdbm предустановлена в стандартном месте, но мы # собираемся применять подпрограммы, совместимые с gdbrn, которые # заставляют ее эмулировать ndbm. Делается это потому, что ndbm — 'самая # стандартная' из версий dbm. Возможно, вам потребуется внести изменения # в соответствии с вашим дистрибутивом. DBM_INC_PATH=/usr/include/gdbm DBM_LIB_PATH=/usr/lib DBM_LIB_FILE=-lgdbm # В некоторых дистрибутивах может понадобиться изменить предыдущую # строку, чтобы включить библиотеку совместимости, как показано далее. # DBM_LIB_FILE=-lgdbm_compat -lgdbm .с.о: $(CC) $(CFLAGS) -I$(DBM_INC_PATH) $(DFLAGS) -с $< app_ui.o: app_ui.c cd_data.h cd_dbm.o: cd_dbm.c cd_data.h client_f.o: client_f.c cd_data.h cliserv.h pipe_imp.o: pipe_imp.c cd_data.h cliserv.h server.о: server.с cd_data.h cliserv.h client: app_ui.o clientif.o pipe_imp.o $(CC) -o client $(DFLAGS) app_ui.о clientif.o pipe_imp.o server: server.о cd_dbm.o pipe_imp.o $(CC) -o server -L$(DBM_LIB_PATH) $(DFLAGS) server.о cd_dbm.o pipe_imp.o -l$(DBM_LIB_FILE) clean: rm -f server client_app *.o *~ ЦелиНаша задача — отделить часть приложения, работающую с базой данных, от пользовательского интерфейса приложения. Вам также необходимо выполнять один серверный процесс, но разрешить одновременное выполнение множества клиентских процессов и при этом сократить до минимума изменения, вносимые в существующий программный код. Везде, где это возможно, вы сохраните исходный текст приложения неизменным. Для простоты у вас должна быть возможность создавать (и удалять) каналы внутри приложения, не заставляя администратора системы создавать именованные каналы перед тем, как вы сможете их применять. Важно также не использовать состояние "активного ожидания", чтобы не тратить времени ЦП на ожидание события. Как вы видели, ОС Linux позволяет приостанавливать выполнение в ожидании событий без потребления значительных ресурсов. Следует применять блокирующие свойства каналов для гарантии эффективного использования ЦП. В конце концов, теоретически сервер может ждать в течение многих часов поступления запроса. РеализацияВ предыдущей версии приложения, реализованного в виде единого процесса, с которой вы познакомились в главе 7, для управления данными применялся набор подпрограмм доступа к данным. К ним относились следующие подпрограммы: int database_initialize(const int new_database); void database_close(void); cdc_entry get_cdc_entry(const char *cd_catalog_ptr); cdt_entry get_cdt_entry(const char *cd_catalog_ptr, const int track_no); int add_cdc_entry(const cdc_entry entry_to_add); int add_cdt_entry(const cdt_entry entry_to_add); int del_cdc_entry(const char *cd_catalog_ptr); int del_cdt_entry(const char *cd_catalog_ptr, const int track_no); cdc_entry search_cdc_entry(const char *cd_catalog_ptr, int *first_call_ptr); В этих функциях очень удобно провести резкую границу между клиентом и сервером. В реализации в виде единого процесса вы можете разделить приложение на две части (рис. 13.6), несмотря на то, что оно компилировалось как единая программа. 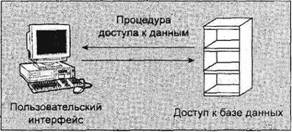 Рис. 13.6 В клиент-серверную версию приложения вы хотите включить несколько именованных каналов и сопроводительный программный код для связи двух основных частей приложения. На рис. 13.7 показана необходимая структура. 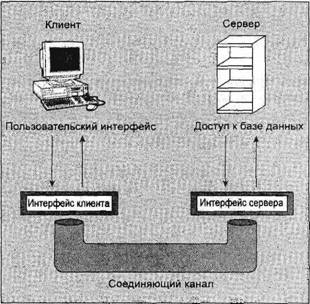 Рис. 13.7 В данной реализации подпрограммы интерфейса и клиента, и сервера помещены в один файл pipe_imp.c. Это сохраняет в едином файле весь программный код, зависящий от применения именованных каналов в клиент-серверной реализации. Форматирование и упаковка передаваемых данных хранятся отдельно от подпрограмм, реализующих именованные каналы. В результате у вас появятся дополнительные файлы исходного текста программы, но с более логичным разделением. Структура вызовов в приложении показана на рис. 13.8. 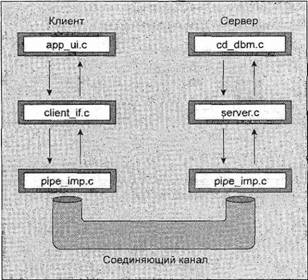 Рис. 13.8 Файлы арр_ui.c, client_if.c и pipe_imp.c компилируются и компонуются вместе для получения клиентской программы. Файлы cd_dbm.c, server.c и pipe_imp.c компилируются и компонуются вместе для создания серверной программы. Заголовочный файл cliserv.h действует как заголовочный файл общих определений для связывания обеих программ. В файлы app_ui.c и cd_dbm.c внесены очень незначительные изменения, в принципе позволяющие разделить приложение на две программы. Поскольку теперь приложение очень большое и существенная часть программного кода не изменилась по сравнению с предыдущей версией, здесь мы покажем только файлы cliserv.h, сlient_if.c и pipe_imp.c. Заголовочный файл cliserv.hСначала рассмотрим cliserv.h. Этот файл определяет клиент-серверный интерфейс. Он необходим и клиентской, и серверной программам. 1. Далее приведены необходимые директивы #include. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <limits.h> #include <sys/types.h> #include <sys/stat.h> 2. Затем вы определяете именованные каналы. Используйте один канал для сервера и по одному каналу для каждого клиента. Поскольку клиентов может быть несколько, клиентская программа включает идентификатор процесса в имя, таким образом, обеспечивая уникальность канала. #define SERVER_PIPE "/tmp/server_pipe" #define CLIENT_PIPE "/tmp/client_%d_pipe" #define ERR_TEXT_LEN 80 3. Реализуйте команды как перечислимые типы, а не как директивы #define. Примечание Первый оператор typedefзадает тип запроса, отправляемого на сервер; второй описывает тип серверного ответа клиенту. typedef enum { s_create_new_database = 0, s_get_cdc_entry, s_get_cdt_entry, s_add_cdc_entry, s_add_cdt_entry, s_del_cdc_entry, s_del_cdt_entry, s_fmd_cdc_entry } client_request_e; typedef enum { r_success = 0, r_failure, r_find_no_more } server_response_e; 4. Далее объявите структуру, которая будет формировать сообщение, передаваемое между двумя процессами в обоих направлениях. Примечание typedef struct { pid_t client_pid; client_request_e request; server_response_e response; cdc_entry cdc_entry_data; cdt_entry cdt_entry_data; char error_text[ERR_TEXT_LEN + 1]; } message_db_t; 5. В заключение приведены функции интерфейса канала, выполняющие передачу данных и содержащиеся в файле pipe_imp.c. Они делятся на функции серверной и клиентской стороны, в первом и втором блоках соответственно. int server_starting(void); void server_ending(void); int read_request_from_client(message_db_t *rec_ptr); int start_resp_to_client(const message_db_t mess_to_send); int send_resp_to_client(const message_db_t mess_to_send); void end_resp_to_client(void); int client_starting(void); void client_ending(void); int send_mess_to_server(message_db_t mess_to_send); int start_resp_from_server(void); int read_resp_from_server(message_db_t *rec_ptr); void end_resp_from_server(void); Мы разделим последующее обсуждение на функции клиентского интерфейса и детали серверных и клиентских функций, хранящихся в файле pipe_imp.c, и при необходимости будем обращаться к исходному программному коду. Функции интерфейса клиентаРассмотрим файл clientif.c. Он предоставляет "поддельные" версии подпрограмм доступа к базе данных. Они кодируют запрос в структуре message_db_tи затем применяют подпрограммы из файла pipe_imp.c для передачи запроса серверу. Такой подход позволит вам внести минимальные изменения в первоначальный файл app_ui.c. Интерпретатор клиента 1. В этом файле реализовано девять функций для работы с базой данных, объявленных в файле cd_data.h. Делает он это передачей запросов серверу и затем возвратом ответа сервера из функции, действуя как посредник. Файл начинается с файлов #includeи констант. #define _POSIX_SOURCE #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <limits.h> #include <sys/types.h> #include <sys/stat.h> #include "cd_data.h" #include "cliserv.h" 2. Статическая переменная mypidуменьшает количество вызовов getpid, требуемых в противном случае. Мы применяем локальную функцию read_one_responseдля устранения дублирующегося программного кода. static pid_t mypid; static int read_one_response(message_db_t *rec_ptr); 3. Подпрограммы database_initializeи closeвсе еще вызываются, но теперь используются, соответственно, для инициализации клиентского интерфейса каналов и удаления лишних именованных каналов, когда клиент завершил выполнение. int database_initialize(const int new_database) { if (!client_starting()) return(0); mypid = getpid(); return(1); } /* инициализация базы данных */ void database_close(void) { client_ending(); } 4. Подпрограмма get_cdc_entryвызывается для получения элемента каталога из базы данных по заданному названию компакт-диска в каталоге. В ней вы кодируете запрос в структуре message_db_tи передаете его на сервер. Далее вы считываете обратно ответ в другую структуру типа message_db_t. Если элемент найден, он включается в структуру message_db_tкак структура типа cdc_entry, поэтому вы можете передать соответствующую часть структуры. cdc_entry get_cdc_entry(const char *cd_catalog_ptr) { cdc_entry ret_val; message_db_t mess_send; message_db_t mess_ret; ret_val.catalog[0] = '\0'; mess_send.client_pid = mypid; mess_send.request = s_get_cdc_entry; strcpy(mess_send.cdc_entry_data.catalog, cd_catalog_ptr); if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { ret_val = mess_ret.cdc_entry_data; } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(ret_val); } 5. Далее приведен исходный текст функции read_one_response, которая используется для устранения дублирующегося программного кода. static int read_one_response(message_db_t *rec_ptr) { int return_code = 0; if (!rec_ptr) return(0); if (start_resp_from_server()) { if (read_resp_from_server(rec_ptr)) { return_code = 1; } end_resp_from_server(); } return(return_code); } 6. Остальные подпрограммы get_xxx, del_xxxи add_xxxреализованы аналогично функции get_cdc_entryи приводятся здесь для полноты картины. Сначала функция для извлечения дорожек компакт-диска. cdt_entry get_cdt_entry(const char *cd_catalog_ptr, const int track no) { cdt_entry ret_val; message_db_t mess_send; message_db_t mess_ret; ret_val.catalog[0] = '\0'; mess_send.client_pid = mypid; mess_send.request = s_get_cdt_entry; strcpy(mess_send.cdt_entry_data.catalog, cd_catalog_ptr); mess_send.cdt_entry_data.track_no = track_no; if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { ret_val = mess_ret.cdt_entry_data; } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(ret_val); } 7. Далее две функции для вставки данных, первая для добавления элемента каталога, а вторая — дорожек в базу данных. int add_cdc_entry(const cdc_entry entry_to_add) { message_db_t mess_send; message_db_t mess_ret; mess_send.client_pid = mypid; mess_send.request = s_add_cdc_entry; mess_send.cdc_entry_data = entry_to_add; if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { return(1); } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(0); } int add_cdt_entry(const cdt_entry entry_to_add) { message_db_t mess_send; message_db_t mess_ret; mess_send.client_pid = mypid; mess_send.request = s_add_cdt_entry; mess send.cdt_entry data = entry_to_add; if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { return(1); } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(0); } 8. В заключение две функции для удаления данных. int del_cdc_entry(const char *cd_catalog_ptr) { message_db_t mess_send; message_db_t mess_ret; mess_send.client_pid = mypid; mess_send.request = s_del_cdc_entry; strcpy(mess_send.cdc_entry_data.catalog, cd_catalog_ptr); if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { return(1); } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(0); } int del_cdt_entry(const char *cd_catalog_ptr, const int track no) { message_db_t mess_send; message_db_t mess_ret; mess_send.client_pid = mypid; mess_send.request = s_del_cdt_entry; strcpy(mess_send.cdt_entry_data.catalog, cd_catalog_ptr); mess_send.cdt_entry_data.track_no = track_no; if (send_mess_to_server(mess_send)) { if (read_one_response(&mess_ret)) { if (mess_ret.response == r_success) { return(1); } else { fprintf(stderr, "%s", mess_ret.error_text); } } else { fprintf(stderr, "Server failed to respond\n"); } } else { fprintf(stderr, "Server not accepting requests\n"); } return(0); }Поиск в базе данных Функция поиска по ключу компакт-диска сложнее. Пользователь этой функции рассчитывает вызвать ее один раз для начала поиска. Мы удовлетворили его ожидания в главе 7, задавая параметр *first_call_ptrравным trueпри первом вызове функции, и функция в этом случае возвращает первое найденное совпадение. При последующих вызовах функции поиска указатель *first_call_ptrравен falseи возвращаются дальнейшие совпадения, по одному на каждый вызов. Теперь, когда вы разделили приложение на два процесса, нельзя разрешать поиску обрабатывать по одному элементу на сервере, потому что другой клиент может запросить у сервера иной поиск, когда выполняется ваш поиск. Вы не можете заставить серверную часть хранить отдельно содержимое (как далеко продвинулся поиск) для поиска каждого клиента, т.к. клиент может просто остановить поиск на полпути, когда найден нужный компакт-диск или клиент "упал". Можно либо изменить алгоритм поиска, либо, как показано в приведенном далее программном коде, спрятать сложность в подпрограмме интерфейса. Данный код вынуждает сервер возвращать все возможные совпадения с искомым значением и затем сохраняет их во временном файле до тех пор, пока клиент не запросит их. 1. Эта функция не так сложна, как кажется, просто в ней вызываются три функции канала send_mess_to_server, start_resp_from_serverи read_resp_fromserver, которые будут рассмотрены в следующем разделе. cdc_entry search_cdc_entry(const char *cd_catalog_ptr, int *first_call_ptr) { message_db_t mess_send; message_db_t mess_ret; static FILE *work_file = (FILE *)0; static int entries_matching = 0; cdc_entry ret_val; ret_val.catalog[0] = '\0'; if (!work_file && (*first_call_ptr == 0)) return(ret_val); 2. Далее показан первый вызов для поиска с указателем *first_call_ptr, равным true. Он немедленно приравнивается false, на случай, если вы забыли. Создается временный файл work_fileи инициализируется структура сообщения клиенту. if (*first_call_ptr) { *first_call_ptr = 0; if (work_file) fclose(work_file); work_file = tmpfile(); if (!work_file) return(ret_val); mess_send.client_pid = mypid; mess_send.request = s_find_cdc_entry; strcpy(mess_send.cdc_entry_data.catalog, cd_catalog_ptr); 3. Теперь приводится проверка условий с тремя уровнями вложенности, заставляющая вызывать функции из файла pipe_imp.c. Если сообщение успешно отправлено на сервер, клиент ждет ответа от сервера. Пока считывания с сервера успешны, совпадения с искомой величиной возвращаются в work_fileклиента и наращивается счетчик entries_matching. if (send_mess_to_server(mess_send)) { if (start_resp_from_server()) { while (read_resp_from_server(&mess_ret)) { if (mess_ret.response == r_success) { fwrite(&mess_ret.cdc_entry_data, sizeof(cdc_entry), 1, work_file); entries_matching++; } else { break; } } /* while */ } else { fprintf(stderr, "Server not responding\n"); } } else { fprintf (stderr, "Server not accepting requests\n"); } 4. Следующая проверка ищет, есть ли совпадения с заданным значением. Далее вызов fseekпереводит указатель в файле work_fileна место записи следующей порции данных. if (entries_matching == 0) { fclose(work_file); work_file = (FILE *)0; return(ret_val); } (void)fseek(work_file, 0L, SEEK_SET); 5. Если это не первый вызов функции поиска для данного конкретного элемента, программа проверяет, были ли уже найдены совпадения. В заключение в структуру ret_valчитается следующий совпадающий элемент. Предшествующие проверки гарантируют наличие совпадающего элемента. } else { /* не *first_call_ptr */ if (entries_matching == 0) { fclose(work_file); work_file = (FILE *)0; return(ret_val); } } fread(&ret_val, sizeof(cdc_entry), 1, work_file); entries_matching--; return(ret_val); } Интерфейс сервера server.cЕсли у клиента есть интерфейс для обращения к программе app_ui.c, серверу также нужна программа для управления (переименованной) программой cd_access.c, теперь cd_dbm.c. Далее приведена функция main сервера. 1. Начните с объявления нескольких глобальных переменных, прототипа функции process_commandи функции перехвата сигнала для обеспечения чистого завершения. #include <unistd.h> #include <stdlib.h> #include <stdio.h> #include <fcntl.h> #include <limits.h> #include <signal.h> #include <string.h> #include <errno.h> #include <sys/types.h> #include <sys/stat.h> #include "cd_data.h" #include "cliserv.h" int save errno; static int server_running = 1; static void process_command(const message_db_t mess_command); void catch_signals() { server_running = 0; } 2. Теперь переходите к функции main. После проверки успешного завершения подпрограмм захвата сигнала программа проверяет, передали ли вы -iв командной строке. Если да, она создаст новую базу данных. Если вызов подпрограммы database_initializeв файле cd_dbm.c завершится аварийно, будет выведено сообщение об ошибке. Если все хорошо и сервер работает, любые запросы от клиента направляются функции process_command, которую вы вскоре увидите. int main(int argc, char *argv[]) { struct sigaction new_action, old_action; message_db_t mess command; int database_init_type = 0; new_action.sa_handler = catch_signals; sigemptyset(&new_action.sa_mask); new_action.sa_flags = 0; if ((sigaction(SIGINT, &new_action, &old_action) != 0) || (sigaction(SIGHUP, &new_action, &old_action) != 0) || (sigaction(SIGTERM, &new_action, &old_action) != 0)) { fprintf(stderr, "Server startup error, signal catching failed\n"); exit(EXIT_FAILURE); } if (argc > 1) { argv++; if (strncmp("-i", *argv, 2) == 0) database_init_type = 1; } if (!database_initialize(database_init_type)) { fprintf(stderr, "Server error :-\ could not initialize database\n"); exit (EXIT_FAILURE); } if (!server starting()) exit(EXIT_FAILURE); while(server_running) { if (read_request_from_client(&mess_command)) { process_command(mess_command); } else { if (server_running) fprintf(stderr, "Server ended — can not read pipe\n"); server_running = 0; } } /* while */ server_ending(); exit(EXIT_SUCCESS); } 3. Любые сообщения клиентов направляются в функцию process_command, где они обрабатываются в операторе case, который выполняет соответствующие вызовы из файла cd_dbm.c. static void process_command(const message_db_t comm) { message_db_t resp; int first_time = 1; resp = comm; /* копирует команду обратно, затем изменяет resp, как требовалось */ if (!start_resp_to_client(resp)) { fprintf(stderr, "Server Warning: start_resp_to_client %d failed\n", resp.client_pid); return; } resp.response = r_success; memset(resp.error_text, '\0', sizeof(resp.error_text)); save_errno = 0; switch(resp.request) { case s_create_new_database: if (!database initialize(1)) resp.response = r_failure; break; case s_get_cdc_entry: resp.cdc_entry_data = get_cdc_entry(comm.cdc_entry_data.catalog); break; case s_get_cdt_entry: resp.cdt_entry_data = get_cdt_entry(comm.cdt_entry_data.catalog, comm.cdt_entry_data.track_no); break; case s_add_cdc_entry: if (!add_cdc_entry(comm.cdc_entry_data)) resp.response = r_failure; break; case s_add_cdt_entry: if (!add_cdt_entry(comm.cdt_entry_data)) resp.response = r_failure; break; case s_del_cdc_entry: if (!del_cdc_entry(comm.cdc_entry_data.catalog)) resp.response = r_failure; break; case s_del_cdt_entry: if (!del_cdt_entry(comm.cdt_entry_data.catalog, comm.cdt_entry_data.track_no)) resp.response = r_failure; break; case s_find_cdc_entry: do { resp.cdc_entry_data = search_cdc_entry(comm.cdc_entry_data.catalog, &first_time); if (resp.cdc_entry_data.catalog[0] != 0) { resp.response = r_success; if (!send_resp_to_client(resp)) { fprintf(stderr, "Server Warning:- failed to respond to %d\n", resp.client_pid); break; } } else { resp.response = r_find_no_more; } } while (resp.response == r_success); break; default: resp.response = r_failure; break; } /* switch */ sprintf(resp.error_text, "Command failed:\n\t%s\n", strerror(save_errno)); if (!send_resp_to_client(resp)) { fprintf(stderr, "Server Warning:- failed to respond to %d\n", resp.client_pid); } end_resp_to_client(); return; } Прежде чем рассматривать действующую реализацию канала, давайте обсудим последовательность событий, которые должны произойти для передачи данных между клиентским и серверным процессами. На рис. 13.9 показан запуск обоих, и клиентского, и серверного, процессов, а также то, как они образуют петлю во время обработки команд и ответов. В этой реализации ситуация немного сложнее, т.к. в запросе на поиск клиент передает серверу одну команду и затем ждет один или несколько ответов от сервера. Это усложняет программу, особенно клиентскую часть. 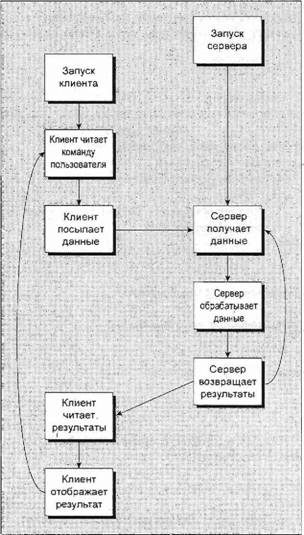 Рис. 13.9 КаналДалее показан файл реализации канала pipe_imp.с, в котором содержатся клиентские и серверные функции. ПримечаниеЗаголовочный файл для реализации канала 1. Прежде всего, директивы #include: #include "cd_data.h" #include "cliserv.h" 2. Вы также определяете в файле программы несколько значений, нужных вам в разных функциях: static int server_fd = -1; static pid_t mypid = 0; static char client_pipe_name[PATH_MAX + 1] = {'\0'}; static int client_fd = -1; static int client_write_fd = -1;Функции серверной стороны Далее нужно рассмотреть функции серверной стороны. В следующем разделе показаны функции, открывающие и закрывающие именованный канал и читающие сообщения от клиентов. В следующем за ним разделе приведен программный код, который открывает и закрывает клиентские каналы и пересылает по ним сообщения, основываясь на идентификаторе процесса, который клиент включает в свое сообщение. Функции сервера1. Подпрограмма server_startingсоздает именованный канал, из которого сервер будет считывать команды. Далее она открывает канал для чтения. Этот вызов openбудет блокировать выполнение, пока клиент не откроет канал для записи. Используйте режим блокировки для того, чтобы сервер мог выполнить блокировку вызовов readв канале в ожидании отправляемых ему команд. int server_starting(void) { #if DEBUG_TRACE printf("%d server_starting()\n", getpid()); #endif unlink(SERVER_PIPE); if (mkfifo(SERVER_PIPE, 0777) == -1) { fprintf(stderr, "Server startup error, no FIFO created\n"); return(0); } if ((server_fd = open(SERVER_PIPE, O_RDONLY)) == -1) { if (errno == EINTR) return(0); fprintf(stderr, "Server startup error, no FIFO opened\n"); return(0); } return(1); } 2. Когда сервер завершает работу, он удаляет именованный канал, для того чтобы клиенты могли установить, что нет действующего сервера. void server_ending(void) { #if DEBUG_TRACE printf("%d:- server_ending()\n", getpid()); #endif (void)close(server_fd); (void)unlink(SERVER_PIPE); } 3. Функция read_request_from_clientбудет блокировать чтение в серверном канале до тех пор, пока клиент не запишет в него сообщение. int read_request_from_client(message_db_t *rec_ptr) { int return_code = 0; int read_bytes; #if DEBUG_TRACE printf("%d :- read_request_from_client()\n", getpid()); #endif if (server_fd != -1) { read_bytes = read(server_fd, rec_ptr, sizeof(*rec_ptr)); ... } return(return_code); } 4. В особом случае, когда ни у одного клиента нет канала, открытого для записи, вызов readвернет 0, т.е. он обнаружит EOF (метку конца файла). Затем сервер закроет канал и откроет его снова так, что канал блокируется до тех пор, пока клиент также не откроет канал. Выполняется то же, что и при первом запуске сервера; вы инициализировали сервер повторно. Вставьте этот программный код в предыдущую функцию. if (read_bytes == 0) { (void)close(server_fd); if ((server_fd = open(SERVER_PIPE, O_RDONLY)) == -1) { if (errno != EINTR) { fprintf(stderr, "Server error, FIFO open failed\n"); } return(0); } read_bytes = read(server_fd, rec_ptr, sizeof(*rec_ptr)); } if (read_bytes == sizeof(*rec_ptr)) return_code = 1; Сервер — это единственный процесс, способный одновременно обслуживать множество клиентов. Поскольку каждый клиент применяет свой канал для получения ответов, адресованных ему, сервер, для того чтобы отправить ответы разным клиентам, должен писать в разные каналы. Поскольку файловые дескрипторы — это ограниченный ресурс, сервер открывает клиентский канал для записи только тогда, когда у него есть данные для отправки. В программном коде открытие клиентского канала, запись в него и закрытие канала разделены на три отдельные функции. Когда вы возвращаете многочисленные результаты поиска, такой подход необходим, для того чтобы можно было открыть канал один раз, записать в него множество ответов и затем снова закрыть канал. Прокладка каналов1. Сначала откройте канал клиента. int start_resp_to_client(const message_db_t mess_to_send) { #if DEBUG_TRACE printf("%d :- start_resp_to_client()\n", getpid()); #endif (void)sprintf(client_pipe_name, CLIENT_PIPE, mess_to_send.client_pid); if ((client_fd = open(client_pipe_name, O_WRONLY)) == -1) return(0); return(1); } 2. Все сообщения отправляются с помощью данной функции. Соответствующие клиентские функции, которые принимают сообщение, вы увидите позже. int send_resp_to_client(const message_db_t mess_to_send) { int write_bytes; #if DEBUG_TRACE printf("%d :- send_resp_to_client()\n", getpid()); #endif if (client_fd == -1) return(0); write_bytes = write(client_fd, &mess_to_send, sizeof(mess_to_send)); if (write_bytes != sizeof(mess_to_send)) return(0); return(1); } 3. В заключение закройте клиентский канал. void end resp_to_client(void) { #if DEBUG_TFACE printf("%d :- end_resp_to_client()\n", getpid()); #endif if (client_fd != -1) { (void)close(сlient_fd); client_fd = -1; } }Функции на стороне клиента Дополнение к серверу — клиентские функции в файле pipe_imp.c. Они очень похожи на серверные функции за исключением функции с интригующим именем send_mess_to_server. Клиентские функции 1. После проверки доступности сервера функция client_startingинициализирует канал клиентской стороны. int client_starting(void) { #if DEBUG_TFACE printf("%d client_starting\n", getpid()); #endif mypid = getpid(); if ((server_fd = open(SERVER_PIPE, O_WRONLY)) == -1) { fprintf(stderr, "Server not running\n"); return(0); } (void)sprintf(client pipe name, CLIENT_PIPE, mypid); (void)unlink(client_pipe_name); if (mkfifo(client_pipe_name, 0777) == -1) { fprintf(stderr, "Unable to create client pipe %s\n", client_pipe_name); return(0); } return(1); } 2. Функция client_endingзакрывает файловые дескрипторы и удаляет ненужный теперь именованный канал. void client_ending(void) { #if DEBUG_TRACE printf("%d client_ending()\n", getpid()); #endif if (client_write_fd != -1) (void)close(client_write_fd); if (client_fd != -1) (void)close(client_fd); if (server_fd != -1) (void)close(server_fd); (void)unlink(client_pipe_name); } 3. Функция send_mess_to_serverпередает запрос через канал сервера. int send_mess_to_server(message_db_t mess_to_send) { int write_bytes; #if DEBUG_TRACE printf("%d send_mess_to_server()\n", getpid()); #endif if (server_fd == -1) return(0); mess_to_send.client_pid = mypid; write_bytes = write(server_fd, &mess_to_send, sizeof(mess_to_send)); if (write_bytes != sizeof(mess_to_send)) return(0); return(1); } Как и в серверных функциях, клиент получает назад результаты от сервера с помощью трех функций, обслуживающих множественные результаты поисков. Получение результатов с сервера1. Данная клиентская функция запускается для ожидания ответа сервера. Она открывает канал клиента только для чтения и затем повторно открывает файл канала только для записи. Чуть позже в этом разделе вы поймете почему. int start_resp_from_server(void) { #if DEBUG_TRACE printf("%d :- start_resp_from_server()\n", getpid()); #endif if (client_pipe_name[0] == '\0') return(0); if (client_fd != -1) return(1); client_fd = open(client_pipe_name, O_RDONLY); if (client_fd != -1) { client_write_fd = open(client_pipe_name, O_WRONLY); if (client_write_fd != -1) return(1); (void)close(client_fd); client_fd = -1; } return(0); } 2. Далее приведена основная операция read, которая получает с сервера совпадающие элементы базы данных. int read_resp_from_server(message_db_t *rec_ptr) { int read_bytes; int return_code = 0; #if DEBUG_TRACE printf("%d :- reader_resp_from_server()\n", getpid()); #endif if (!rec_ptr) return(0); if (client_fd = -1) return(0); read_bytes = read(client_fd, rec_ptr, sizeof(*rec_ptr)); if (read_bytes = sizeof(*rec_ptr)) return_code = 1; return(return_code); } 3. И в заключение приведена клиентская функция, помечающая конец ответа сервера. void end_resp_from_server(void) { #if DEBUG_TRACE printf("%d :- end_resp_from_server()\n", getpid()); #endif /* В реализации канала эта функция пустая */ } Второй дополнительный вызов openканала клиента для записи в start_resp_from_server client_write_fd = open(client_pipe_name, O_WRONLY); применяется для защиты от ситуации гонок, когда серверу необходимо быстро откликаться на несколько запросов клиента, Для того чтобы стало понятнее, рассмотрим такую последовательность событий: 1. Клиент пишет запрос к серверу. 2. Сервер читает запрос, открывает канал клиента и отправляет обратно ответ, но приостанавливает выполнение до того, как успеет закрыть канал клиента. 3. Клиент открывает канал для чтения, читает первый ответ и закрывает свой канал. 4. Далее клиент посылает новую команду и открывает клиентский канал для чтения. 5. Сервер возобновляет работу, закрывая свой конец клиентского канала. К сожалению, в этот момент клиент пытается считать из канала ответ на свой следующий запрос, но readвернет 0 байтов, поскольку ни один процесс не открыл клиентский канал для записи. Разрешив клиенту открыть канал как для чтения, так и для записи, и устранив тем самым необходимость повторного открытия канала, вы избежите подобной ситуации гонок. Учтите, что клиент никогда не пишет в канал, поэтому нет опасности считывания ошибочных данных. Резюме, касающееся приложенияВы разделили приложение, управляющее базой данных компакт-дисков, на клиентскую и серверную части, что позволило разрабатывать независимо пользовательский интерфейс и внутреннюю технологию работы с базой данных. Как видите, четко определенный интерфейс базы данных дает возможность каждому важному элементу приложения наилучшим образом использовать машинные ресурсы. Если пойти чуть дальше, можно было бы заменить реализацию с помощью каналов на сетевой вариант и применить выделенный компьютер для сервера базы данных. В главе 15 вы узнаете больше об организации сети. РезюмеВ этой главе вы рассмотрели передачу данных между процессами с помощью каналов. Сначала вы познакомились с неименованными каналами, которые создаются вызовом popenили pipe, и посмотрели, как, применяя канал и вызов dup, можно передать данные из одной программы в стандартный ввод другой. Далее вы перешли к именованным каналам и узнали, как можно передавать данные между несвязанными программами. В заключение вы реализовали простой пример клиент- серверного приложения, используя каналы FIFO для обеспечения не только синхронизации процессов, но и организации двунаправленного потока данных. |
|
||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||
|
|
||||||||||||||||||||||