|
||||
|
|
Глава 4. «Открытый Офис»Хотя «офисные» программы с распространением сетей и коммуникационных программ и перестали быть основным приложением персональных компьютеров, они все еще достаточно популярны, и в учебных планах им отводится значительное (быть может, даже слишком большое) место. К «офисным» программам традиционно относят словарные процессоры, редакторы электронных таблиц и компоновщики мультимедийных презентаций. В пакет «OpenOffice.org» (далее — «OO.o»), которому посвящена эта глава, входят: словарный процессор «OpenWriter»; редактор электронных таблиц «OpenCalc»; компоновщик мультимедийных презентаций «OpenImpress» (в этой книге не рассматривается). Кроме того, в пакет включен: векторный графический редактор «OpenDraw». У «OpenOffice.org» есть масса недостатков — он (версия 1.0) вышел сыроватым (хотя версия 1.1, уже выпущенная в англоязычном и готовящаяся к выпуску в русскоязычном варианте, гораздо более «вылизана»), он достаточно «тяжел» для слабой техники, он неидеально отдокументирован и локализован) — которые постепенно исправляются. У него есть четыре очень серьезных достоинства: 1) он свободен, поставляется конкурентно (с соответствующими ценовыми последствиями) и может быть использован как база для дальнейших разработок (в том числе, специфически учебных); 2) он изначально платформенно-независим, и пользование им не диктует практически никаких ограничений на выбор операционной системы и операционной среды. Более того, навыки работы с ним также в большой степени переносимы. Фактически, «OO.o» выглядит и управляется одинаково под любой стандартной ОС (разработчики говорят о поддержке «ГНУ/Линукс» и «Солярис»; известно об устойчивой работе пакета под FreeBSD, «Дарвин»/«МакОС Х»), а также под «Майкрософт Уиндоуз 9х/Ми» и «Майкрософт Уиндоуз НТ/00/XP»; 3) он использует в качестве языка разметки XML (не только для размеченного текста, но также и для математических формул, т.е. по сути, все его форматы суть приложения международного стандарта разметки текста SGML), соответствующие определения типов документа доступны и отдокументированы. В качестве кодировки используется Unicode, что позволяет забыть про третью (после классических «дураков и дорог») российскую проблему с разнобоем в кодовых таблицах, используемых для представления кириллицы в разных системах, 4) в команде разработчиков есть российские программисты и фирмы, которым небезразличны перспективы его применения в школе. 4.1 Словарный процессор «OpenWriter»И «Обязательный минимум...», и большинство конкретных учебных планов предусматривает знакомство лишь с базовой функциональностью программ манипуляции текстами, и любой из свободных словарных процессоров («AbiWord», «Kword», «OpenWriter») гарантированно и с избытком перекроет требования (так же, как и масса присутствующих на рынке несвободных программ, таких, как «Майкрософт Уорд», «Лексикон», «СтарОфис» или «УордПёрфект»). Поскольку большинство из них так или иначе развивают основные интерфейсные подходы «УордПёрфект», существенного (и могущего быть выявленным в пределах тех немногих часов, что учитель в состоянии уделить этой теме) эргономического различия между ними нет. Значит основания для рационального выбора программы нужно искать не внутри темы манипулирования текстами, а в ее связи с другими учебными темами. У программистов есть такой эмпирический принцип: когда начинаешь путаться в программах, отложи их в сторону и попытайся разобраться со структурами данных — сам удивишься, насколько очевидными и простыми окажутся после этого решения, касающиеся программ. Возможно, этот принцип разумно применять и пользователям. Давайте попробуем отложить в сторону программный инструментарий и разобраться с тем, какого рода данные мы им обрабатываем. «Плоский» и размеченный Водораздел между текстовыми редакторами и word-процессорами проходит по критерию способа отображения размеченного (имеющего некоторые атрибуты, такие, как цвет, начертание и кегль (размер) символов, выключка (выравнивание) и расположение абзацев, оформление страницы и т.п.) текста. Текстовый редактор отображает его как есть, например: <курсив>Предложение, набранное курсивом.</курсив> а word-процессор визуализирует эти атрибуты, например: Предложение, набранное курсивом. Визуализацию иногда путают с так называемым WYSIWYG-принципом (сокращение от «What you see is what you get» — «Что видишь, то и получишь»). Однако в общем случае это неверно: WYSIWYG-идеология унаследована от эпохи персональных компьютеров, когда в ходе «малой компьютеризации» отдельные офисы и рабочие места становились «островами» безбумажных технологий в море бумажной коммуникации, и компьютерное представление мыслилось лишь промежуточной или предварительной формой существования текста или документа. Сегодня большинство документов никогда не попадает на принтер, и нет нужды подстраиваться под архаичный бумажный документооборот. Вполне возможно, что автору или редактору удобнее выделение не курсивом, а подчеркиванием: _Предложение,_набранное_курсивом._ Более того, современные технологии (например, HTML или XML-оформление текстов) изначально предполагают, что читатель документа может устанавливать собственные предпочтения в визуализации, зависящие от особенностей используемого им оборудования (размеров и разрешающей способности монитора и т.п.) или от своих биологических особенностей (слабого зрения, дальтонизма и т.п.), и в общем случае они могут не совпадать с предпочтениями автора или редактора. Таким образом, один и тот же документ может быть отображен с разметкой, с визуализацией, а иногда — и с разметкой и с визуализацией (см. Рис. 4-1). 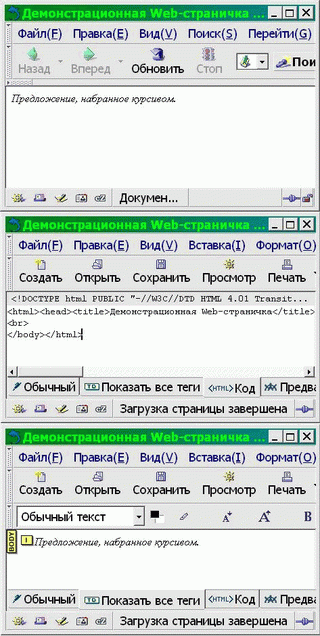 Рис 4-1 Хотя на рисунке нам удалось показать три типа отображения одного и того же документа, не выходя из одного прикладного пакета, это не такой частый случай. На самом деле текстовые редакторы, как правило, не имеют способности непосредственной визуализации вообще или обладают ею лишь в зачатке (как, например, Emacs, способный визуализировать формат Enriched text, но Emacs это не просто редактор, а целая операционная среда), а word-процессоры, в свою очередь, крайне неудобны для редактирования «плоского» текста: слишком разнятся базовая операторика и ожидаемая эргономика этих двух типов прикладных программ. Учащийся сталкивается с задачей манипулирования «плоским» текстом как минимум два раза (при знакомстве с электронной почтой и при изучении основ программирования), соответственно, успевает познакомиться, как правило, с двумя разными текстовыми редакторами (встроенными в почтовую программу и среду программирования, соответственно). Как минимум два раза он сталкивается и с задачей манипулирования размеченным текстом: один раз его знакомят с word-процессором (как правило, в России под руку подворачивается «пиратский» «Майкрософт Уорд», либо бесплатно распространяемый «СтарОфис 5», либо дешевый «Лексикон», исключения единичны), а затем ему преподносят основы HTML. Знакомство с манипулированием текстом, таким образом, оказывается бессистемным и фрагментарным, и, в лучшем случае, автор учебника или учитель сумеют рассказать о том, что сфера это, в общем-то единая, а показать это оказывается весьма затруднительно. Значительным шагом к систематизации опыта, вырабатываемого школьным курсом, на наш взгляд, является использование инструментария, позволяющего демонстрировать возможность работы с размеченным текстом разными средствами. Это значит, что к очевидным требованиям, предъявляемым к «учебному» word-процессору (достаточность функций, локализованность, мультиплатформенность, ценовая доступность), добавляется серьезное пожелание: стандартность формата разметки. Это сильно облегчает выбор. На самом деле, на сегодня всем перечисленным требованиям удовлетворяет, по сути, лишь одна программа. Но сначала — немного о стандартах. Стандарты разметки текста Существуют и доказали свою устойчивость два основных типа языков разметки. Первый из них, это семейство, называемое *ML-языками: на эти две буквы заканчиваются аббревиатуры их названий — GML, SGML, HTML, XML, — а сами по себе эти буквы означают просто «markup language» — «язык разметки». Второй — разработанный выдающимся американским теоретиком и практиком программирования Дональдом Кнутом язык программирования верстки TeX[68] и его расширения (например, LaTeX). Не будучи официальным стандартом, ТеХ постепенно вытесняет и замещает прочие языки разметки, предназначенные для набора и верстки текстов (TeX и системы на его основе плохо приспособлены для верстки т.н. «иллюстрированных изданий» с характерным для них богатым насыщением текста графикой, сложными обводами и наложениями текста на графику и пр., и этот сегмент рынка остается пока не стандартизованным). За пределами этих типов — огромное множество нестандартных (и даже неопубликованных) форматов, зачастую использующих не текстовую, а двоичную форму представления данных (например, файлы «Майкрософт Уорд», «Лексикона» и т.п.). Это исключает возможность применения для работы с такими данными обычных текстовых редакторов и обработку их стандартными текстовыми утилитами, а также сильно затрудняет обратную разработку формата с целью обеспечения импорта и экспорта из независимо написанных программ[69]. Наверное, TeX имеет потенциал к использованию в качестве примера языка разметки (или, точнее, языка генерации разметки), однако вряд ли в средней школе — отчасти потому, что ориентирован на печатную форму в качестве окончательной формы представления содержания, что представляет на сегодня если не экзотическую, то, во всяком случае, достаточно специальную область применения компьютеров, в отличие от *ML-языков, в равной степени ориентированных и на «экран», и на «бумагу». Судьба *ML-языков SGML достаточно давно (с 1986 г.) является стандартом на разметку документов, принятым Международной организацией стандартизации (серия ISO 8879). Парадокс заключается в том, что до недавнего времени даже частичные реализации SGML были сравнительно немногочисленными, и его использование ограничивалось рамками государственных организаций (в массе своей оборонных и научных) и крупных корпораций. Гораздо более широкое распространение получили «похожие на SGML» языки, а именно, HTML различных версий, являющийся одним из технологических столпов WWW. HTML был сознательно создан как «игрушечный SGML»: он не обладал всей гибкостью и мощью последнего, но был очень компактен и легок в реализации и изучении. Одна из сторон «игрушечности» HTML заключается в том, что он подталкивает пользователя к использованию физической, а не логической разметки, и именно поэтому, на наш взгляд, его не стоит изучать в школе. Однако добавление все новых и новых возможностей и конструкций в HTML в ходе его развития привело к тому, что сложность его существенно выросла и приблизилась к сложности SGML-приложений, при сохраняющейся несовместимости с SGML. Параллельное развитие двух близких по назначению языков было очевидно нецелесообразным, поэтому дальнейшее развитие WWW предполагает переход на XML — «расширяемый язык разметки», который превосходит по мощности, гибкости и согласованности HTML и является полноценным SGML-приложением. Уже сегодня наиболее развитые WWW-серверы генерируют HTML именно из XML; непосредственно «понимать» последний постепенно учатся и браузеры. «Молодое поколение выбирает *ML!» На наш взгляд, принципы расширяемой разметки, реализованные в XML, могут и должны стать одной из базовых составляющих компьютерной грамотности и обязательно должны найти свой путь в школьные учебные планы. Это позволит: подвести единую основу и логически связать такие темы, как манипуляция размеченным текстом, гипертекстом и гипермедиа, векторной графикой, электронными таблицами и т.п., приблизить школьную информатику к реальным тенденциям развития информатики и информационной отрасли вообще, вывести ее из закутка «персонального компьютинга», упростить за счет стандартизации задачу выбора (разработки) учебных программ и пакетов. Задача доступного изложения основ XML и приемов работы с ним сама по себе непроста, как дидактически, так и технически (в частности, нужны определения типов документов (DTD) для учебных задач, достаточно развитые для демонстрации возможностей языка, но в то же время достаточно простые для понимания XML-документов «с листа» и низкоуровневого редактирования). Однако одно из основных препятствий на пути использования XML в школе — неразвитость визуализирующих редакторов — уже отпало с появлением офисного пакета «OpenOffice.org». Он сочетает привычные пользователям ПК пользовательские интерфейсы с поддержкой стандартных XML-приложений, таких, как «текстовый документ» (программа «OpenWriter»), «электронная таблица» («OpenCalc»), «презентация» (OpenImpess), «формула» (OpenMath), «гипертекст» (OpenWeb) и, что уже совсем не характерно для «офисного» софта, «векторный рисунок» («OpenDraw»), их взаимного внедрения и связывания. По сути дела, «OO.o» — это «троянский конь», заброшенный в мир «малой компьютеризации»: «снаружи» он похож на «офис», а «изнутри» (или «с изнанки») представляет собой набор XML-инструментов. «Офисной» стороной он обращен к опыту пользователей персональных компьютеров, инструментальной — к современным, постперсональным вычислительно-коммуникационным системам (включая локальные сети и сети Интернет с возможностями безбумажного документооборота и совместной работы над документами). «OpenWriter» «OpenWriter» (далее — OW) — это неофициальное, но уже закрепляющееся название word-процессора из комплекта свободных офисных прикладных программ ОО.о (официальным названием, видимо, следует считать Ooowriter)[70]. 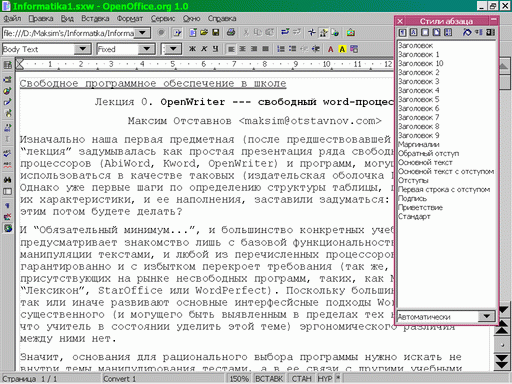 Рис. 4-2 Рис. 4-2Как уже говорилось выше, все словарные процессоры внешне (по функциональности и интерфейсу) похожи друг на друга, и OW (см. рисунок) — не исключение. Он предназначен для набора, редактирования и оформления текстов на естественных языках (включая многоязычные) и поддерживает: физическое и логическое (через механизм стилей) форматирование документа в целом, отдельных страниц, разделов, абзацев и символов; шаблоны (наборы стилей и формы документов); лингвистическую поддержку (корректные переносы, проверку орфографии и грамматики, тезаурус (русского грамматического и тезаурус-модулей пока нет)); внедрение и связывание объектов — как из XML-приложений, так и чужеродных (включая растровую графику и результаты выполнения запросов к базам данных); импорт/экспорт унаследованных нестандартных форматов (в базовую поставку входит модуль только для Microsoft Office), а также плоско-текстовых и гипертекстовых форматов; встроенный макроязык; автоматическую нумерацию элементов, оглавления и указатели; ... (назовите сами). За подробностями отсылаю к[82]. Интересное, однако, начинается, когда мы посмотрим на OW «с изнанки». Файлы с расширением имени «.sfx», создаваемые им — это PKZIP-архивы, содержащие (в простейшем случае) набор XML-файлов, соответствующих (в терминах XML) манифесту, содержанию документов, определению стилей и значениям текущих настроек. Заглянем в файл с содержанием (content.xml). Даже не зная XML, и лишь ориентируясь в синтаксисе языка разметки, можно понять, что файл содержит сначала определения стилей, использованных в документе (даже «жесткое» форматирование имитируется в OW путем создания неявных стилей), а затем размеченного указаниями на эти стили текста. Смотрите, заголовок статьи размечен так (Рис. 4-3).  Рис. 4-3 Рис. 4-3Понятно, что для форматирования использован один стиль абзаца «P2» и три стиля символов «T1», «T2» и «T3». Выше, в определениях стилей можно найти, что, допустим, «T2» — это стиль, определенный на Рис. 4-4.  Рис. 4-4 Рис. 4-4То есть «текстовый» (символьный) стиль, предполагающий набор и отображение полужирным шрифтом. Теперь content.xml может обрабатываться любым XML-инструментом уже без использования «OO.o». Его можно преобразовать в HTML или проиндексировать, вывести на печать, просмотреть браузером, поддерживающим XML. Произвольные определения документов напрямую пока браузерами не поддерживаются, однако текст (неформатированный) можно уже сегодня просмотреть, просто открыв content.xml в «Мозилла» или другом браузере, поддерживающем XML. 4.2 Редактор электронных таблиц «OpenCalc»Слово «компьютер», означающее буквально «вычислитель» и восходящее к лат. computare, сегодня не нуждается в переводе: повсеместно им обозначают электронные вычислительные машины, и оно понятно даже носителям языков, в которых для компьютера есть собственное слово. Однако в английском, из которого оно и начало свое распространение, это слово имеет и более ранее значение: человек, занятый вычислениями. Парадоксально, но сколько-нибудь систематического исследования вопроса о динамике совокупной «вычислительной мощи», которыми располагало человечество до появления автоматических вычислителей, в мировой литературе не существует (по крайней мере, с ходу не находится), хотя само содержание общематематического образования и профессиональной подготовки до сих пор наполнено, наряду с теоретическими сведениями о природе и свойствах математических объектов, вполне прагматическими приемами, способами, методами эффективного ручного счета. Такое исследование будет непростым предприятием, учитывая, что в большинстве случаев вычисления были не отдельной профессией, а частью других профессиональных занятий. Бухгалтер, инженер, техник затрачивали существенные усилия на проведение расчетов, являющихся частью их повседневной работы. Компьютер меняет все это: от профессионала по-прежнему требуется умение применить способ расчета, но сами «вычислительные объемы» выполняются все более и более автоматизированно. Лишь в относительно небольшом количестве случаев такие вычисления можно сделать полностью автоматическими и централизованными, свалить их на «числомолотилки», а в большинстве случаев расчеты должны проводиться уместно, в том месте и в тот момент, когда это необходимо. Иными словами, от все большего количества профессионалов ожидается умение программировать вычисления. «Программирование» здесь употреблено не в узком значении, связанном с определенной профессиональной деятельностью, использованием специальных систем нотаций и интеллектуальной дисциплины, а в самом широком, совпадающем с этимологией слова. «Программировать» означает буквально всего лишь «прописывать наперед» те действия, которые должны быть выполнены. «Убойное приложение» ПК У маркетологов есть такое сленговое выражение: «убойное применение», или «убойное приложение» (killer application). Оно означает то применение какой-либо многофункциональной в своей основе вещи, которое формирует основную долю спроса на нее и превращает ее из модной новинки в массовый товар. Появившийся на рубеже семидесятых и восьмидесятых, в сравнении с «настоящим» дорогим компьютером дешевый ПК был всем плох, кроме одного: он быстро выводил данные на экран. Нужно вспомнить, что в те времена относительно дешевые алфавитно-цифровые терминалы соединялись с машиной последовательными интерфейсами (RS-232), скорость передачи данных по которым обычно измерялась в сотнях знаков в секунду, иногда в тысячах. Гораздо быстрее обменивались данными X-терминалы, включенные в сеть, но это оборудование другого класса, стоившее совсем других денег. «Терминал» персонального компьютера — это (не считая клавиатуры и «мыши») адаптер, интегрированный на системной плате или вставленный в разъем шины с параллельной передачей сигнала со скоростью, как минимум в сотни раз превышающей пропускную способность последовательного интерфейса, а на монитор, находящийся всего в десятках сантиметров от компьютера, сигнал передается по аналоговому кабелю. Даже на ранних ПК вывод данных на экран был, в масштабах человеческого восприятия, мгновенным (если не «тормозила», конечно, сама программа). Это позволило относительно дешево реализовать различные приложения, сама идея которых в том, чтобы представить пользователю «живую» презентацию каких-либо данных. К числу таких приложений относится полноэкранное редактирование текстов и, в особенности, работа с электронными таблицами. Электронные таблицы — по большому счету, единственное приложение компьютера, которое было придумано для ПК и впервые реализовано на ПК. Сегодня, разумеется, благодаря многократно возросшей скорости передачи данных, редакторами электронных таблиц можно пользоваться в компьютерных системах и сетях практически любой топологии (упомянутый ниже KSpread без проблем заработал на карманном компьютере Sharp Zaurus). Программирование особого рода Мы придерживаемся отнюдь не общепризнанной точки зрения, согласно которой популярность электронных таблиц как делового приложения компьютера, обусловлена именно простотой решения задач, требующих программирования. Электронная таблица — это двумерный массив, каждый элемент (ячейка) которого может содержать либо значение, либо выражение (формулу), причем выражения в качестве связанных переменных могут содержать ссылки на другие ячейки. (Можно считать значение (константу) частным случаем формулы, однако по историческим и эргономическим соображениям синтаксис этих сущностей различен. Значения, к которым приводятся ячейки, содержащие формулу «=100» (если, как во всех известных нам системах управления электронными таблицами, синтаксис формулы предполагает «=» в первой позиции) и константу 100, равны.) По сути дела, электронная таблица предполагает использование простого функционального языка программирования (точнее, современные системы управления электронными таблицами как правило реализуют язык формул, функциональный в своей основе, но с элементами инфиксной нотации, т.е. с возможностью вместо «=функция1(функция2((сумма(а; произведение(b;c)))))» написать чуть короче: «=функция1(функция2(a+b*c))»). Синтаксис этого языка очевиден для всех, кому ясно, что такое формула в обычном математическом понимании. Кроме того, форма электронной таблицы снимает с пользователя-«программиста» заботу об организации данных (их организует сама таблица, и вместо имен переменных можно использовать координаты ячеек), о вводе-выводе и о связывании отдельных конструкций в программу (вычисление формул происходит по мере необходимости). Таким образом, с помощью электронных таблиц в учебный курс информатики можно вводить «нулевую степень программирования», объясняя, что такое выражение и переменная, но откладывая на потом то, от чего можно абстрагироваться (сущности, перечисленные в предыдущем абзаце, и другие, более сложные). Свободные редакторы электронных таблиц Пробежавшись по каталогам свободных программ (таким, как «кузница кода» Sourceforge, содержащая тысячи проектов), можно обнаружить более двух десятков программ в категории «электронные таблицы». Большинство из них — незавершенные или более или менее законченные учебные проекты. Работу с электронными таблицами можно, видимо, считать зрелым персонально-компьютерным приложением: оказывается, за полгода-год один программист в состоянии реализовать (разумеется, опираясь на существующие библиотеки) до 90% функциональности, свойственной лидирующим программам в этой категории. Однако знакомство с содержанием коммуникации на форумах поддержки позволяет предположить, что реальную широкую пользовательскую аудиторию получили три свободных проекта: «OpenCalc» — электронно-табличный компонент уже знакомого нам по предыдущим разделам интегрированного прикладного делового пакета «OpenOffice.org»; KSpread — компонент еще одного конкурирующего пакета под названием KOffice, который мы пока обходим вниманием. KSpread сегодня также не будет нами рассматриваться, но по чисто техническим причинам. Ничего плохого мы о нем сказать не можем. И, наконец, Gnumeric — компонент слабоинтегрированного пакета (или, скорее, собрания программ) «Гном» Office, не слишком популярного в России из-за хронических сложностей с кириллической письменностью, свойственных word-процессорному его компоненту, Abiword. Сразу отметим, что, в отличие от последнего, Gnumeric «русофобией» не страдает. Упомянутое выше слово — зрелость самого приложения — ключевая характеристика. Набор ожиданий пользователя, в общем-то, известен, причем не только в части функциональности, но и в части основных эргономических характеристик программы: помимо богатых выразительных возможностей самих функций, для работы с электронными таблицами важна т.н. «остенсивная» операторика, иными словами, возможность «показать пальцем» на объект, с которым нужно произвести те или иные действия. Например, «суммировать значения вот этих ячеек», а не «... ячеек с A5 по D5». В большей, чем в других приложениях, мере очевидны эвристики, которые должны реализовываться программой в качестве «подсказок»; например, если в ячейку, завершающую длинный столбец чисел, пользователь намерен ввести формулу, скорее всего он суммирует значения, а если он начал ряд «1 2 3» или «январь, февраль, март», скорее всего, он продолжит его достаточно прямолинейно.  Рис. 4-5 Рис. 4-5 Рис. 4-6 Рис. 4-6Соответственно, различий можно ожидать лишь в деталях реализации функциональности и эргономики. И действительно, большинство редакторов электронных таблиц, включая и перечисленные, очень похожи. За две недели автор (в обычной жизни не пользующийся этим классом программ), проверяя свои впечатления, «играл» с четырьмя подобными системами, пытаясь решать несложные задачки, которые обычно он решает (ввиду специфики личного профиля навыков) с помощью СУБД, включая 1) элементарные инженерные расчеты (расход материалов и жесткость корпусной мебели), 2) бюджетирование небольшого проекта, 3) бюджетирование личных расходов. Под горячую руку попали и 4) три задачки из учебника алгебры за 11 класс, две из которых даже удалось с ходу решить. 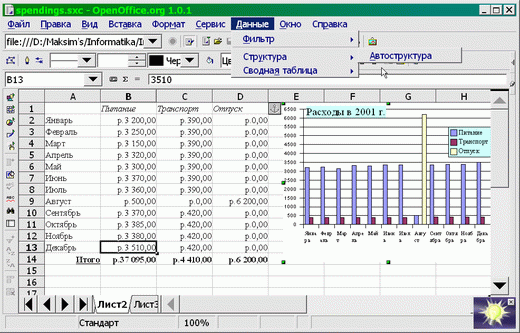 Рис. 4-7 Рис. 4-7В число этих систем вошли три упомянутые свободные программы и, в качестве контрольного образца, очень популярная несвободная «Майкрософт Эксел» (из офисного пакета «Майкрософт Офис 2000»). Вывод: существенной разницы в возможностях и способах их реализации 99% пользователей не обнаружат. Некоторые тонкости: самой «интуитивной» показалась «Ньюмерик», лучше всего документирована «Майкрософт Эксел», у последней также наиболее развиты средства визуализации (построение графиков и диаграмм). Тем не менее, если бы автору предстояло регулярно работать с электронными таблицами, скорее всего, его выбор пал бы на сравнительно «серенькую» «OpenCalc» из-за единства интерфейса и интегрированности с «OpenWriter» и «OpenDraw», которыми он пользуется регулярно. Как и остальные упомянутые программы (за исключением Microsoft Excel), «OpenCalc» определяет особое приложение языка разметки XML, которое и используется для хранения рабочих книг (почему-то workbook переводится как «рабочая книга», хотя вообще-то это обычная «тетрадь») с подшитыми в них листами электронных таблиц. Как и остальные компоненты «OpenOffice.org», «OpenCalc» упаковывает XML-файл с содержимым (а также ряд вспомогательных файлов) в PKZIP-архив, который и является единицей хранения документа. (О важности стандартизации языков представления данных в «офисных» приложениях мы подробно говорили в разделе 4.1, к каковому и отсылаем читателя.) Кроме «родного» формата, «OpenCalc» «понимает» распространенный формат, используемый Microsoft Excel разных версий, экспортирует данные в DIF (Data Interchange Format), форматы ранних версий StarCalc, потомком которых она является, SYLK, импортирует — также из форматов dBase и Lotus 1-2-3. Книгу (workbook) можно с очень приличным качеством экспортировать в гипертекст (html 3.2). Текущая версия (1.0) «OpenCalc» позволяет работать с отдельными таблицами (листами) размером до 255 столбцов (пронумерованных буквами и двухбуквенными сочетаниями, от A до IV) на 32000 строк (пронумерованных числами), чего вполне достаточно для большинства офисных применений и уж, во всяком случае, для любых разумных учебных задач. «OpenCalc» допускает абсолютную и относительную адресацию ячеек и их диапазонов. В «OpenCalc» поддерживается типизация данных с возможностью их интерпретации как чисел, денежных сумм, дат, времени, логических значений и, наконец, просто текста. Возможны и определяемые пользователем типы. Для некоторых типов определены различные форматы представления, задающие способ их отображения или печати. В случае, если ячейка содержит формулу, ее результат также может быть типизован. Библиотека функций OCalc достаточно компактна — их около трех с половиной сотен. Она разбита на ряд категорий: управление БД, работа с датами и временем, финансы, статистика и т.п. Имеются средства расширения этого набора. «OpenCalc» реализует такие средства, как: автозаполнение однородных рядов данных; именование ячеек и их групп; сортировка и фильтрация; построение графиков и диаграмм. Мощный механизм стилей оформления, свойственный всем компонентам пакета «OO.o», доступен и в «OpenCalc». Стили оформления могут определяться для отдельных ячеек, их совокупностей, листов и рабочих книг в целом, а также для включаемых элементов, таких как текст или иллюстрации (в том числе, графики и диаграммы). 4.3 Редактор векторной графики «OpenDraw»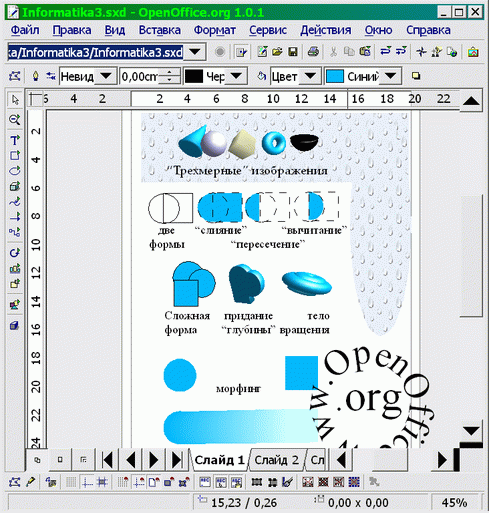 Рис. 4-8 Рис. 4-8Компьютерная графика, чуть более десяти лет назад бывшая если не экзотическим, то довольно специальным приложением компьютера, сегодня повсеместна. Всякий, впервые сталкивающийся с компьютером, уже в самом начале обучения (если курс специально не построен так, чтобы ограничиться на первых порах программами с текстовым или псевдографическим интерфейсом), скорее всего, встретится с графическим терминалом, отображающим различные графические элементы (включая и текстовую информацию, также отображающуюся в графическом режиме средствами компьютерной графики). Элементарная обработка (создание и редактирование) изображений (как векторных, так и растровых) входит в число приложений, перечисленных в «Обязательном минимуме содержания образования по информатике»[81] в качестве обязательных к освоению в курсе средней школы. Предметность обучения предполагает, что учащийся «узнает» в создаваемых или редактируемых им картинках при изучении обработки изображений подобие уже знакомых ему элементов графических интерфейсов. Чтобы это счастливое узнавание произошло, представляется целесообразным включить некоторые первоначальные сведения о компьютерной графике уже во введение в предмет, которым начинается его изучение. К сожалению, не все учебники это реализуют, поэтому преподавателю могут потребоваться некоторые дополнительные усилия, но, на самом деле, небольшие, поскольку наглядный материал «под рукой» в любом компьютерном классе. Способы кодирования графических данных делятся на две категории: растровый (точки равномерно размеченного прямоугольника) и векторный (описания линий и фигур, составляющих изображение). Например, растровое изображение окружности может быть таким: «заполняем квадрат 5х5: белая точка (Б), черная точка (Ч), Ч, Ч, Б, Ч, Б, Б, Б, Ч, Ч, Б, Б, Б, Ч, Ч, Б, Б, Б, Ч, Б, Ч, Ч, Ч, Б». (Более умные «форматы со сжатием», возможно, позволят сократить запись до чего-нибудь, подобного: «заполняем квадрат 5х5: Б, 3Ч, Б, 3(Ч, 3Б, Ч), Б, 3Ч, Б», а то и еще более компактно, но суть не в этом). Векторное ее изображение совсем другое: «черная окружность с центром в (3,3), радиусом 2 и толщиной линии 1». Важно понимать, что большинство компьютерных графических устройств сегодня — и терминалы, и сканеры, и принтеры — по своей природе растровые. Исключение составляют только графопостроители (плотерры) и редко доступные в учебных условиях их промышленные «кузены» (такие, как фрезерный станок с числовым управлением). Соответственно, изображение, вне зависимости от его собственной природы (векторной или растровой), будет при отображении преобразовано в растр и доступно человеческим чувствам в растровой форме (даже если растр почти незаметен, как на дисплеях с высоким разрешением, или вообще имеет сетку ниже порога восприятия, как при печати на качественных струйных или лазерных принтерах). И указанные два способа вполне могут привести к неотличимому результату. Разница может проявиться тогда, когда мы начнем обрабатывать элементы изображения. Векторное изображение может без ущерба масштабироваться (увеличиваться или уменьшаться), причем эта операция обратима. В приведенном примере мы можем без труда увеличить векторную окружность в пять раз: «черная окружность с центром в (15,15), радиусом 10 и толщиной линии 5», и она останется окружностью. А вот растровое изображение при увеличении обнаружит лишь свой растр в увеличенном виде (и на окружность наш пример похож уже будет мало). Более того, операция уменьшения (или увеличения в нецелое число раз) растрового изображения уже не является обратимой: информация при осуществлении такой операции безвозвратно теряется. Кроме того, векторное изображение, содержащее более одного элемента (например, изображение двух пересекающихся окружностей), может быть разъято на элементы без каких-либо потерь. С растровым изображением такое, в общем случае, невозможно: программа «не знает» об элементах изображения и о принадлежности тех или иных точек отдельным элементам. В общем случае, векторное кодирование хорошо подходит для работы с чертежами, схемами, картами, диаграммами, графиками и т.п., а растровое — для обработки фотографий и рисунков. Векторное изображение может быть без ущерба для восприятия преобразовано в растр, в то время, как обратное преобразование в общем случае проблематично (хотя есть программы, позволяющие с той или иной точностью распознавать графические образы). Векторное кодирование часто компактнее растрового, но его отображение требует больших вычислительных ресурсов[71]. Пример, который всегда перед глазами пользователя компьютера — шрифты. Когда точно известен масштаб, в котором будет отображаться текст, часто используются растровые («фиксированные») шрифты, представляющие собой набор растровых изображений отдельных букв и других символов используемого алфавита (например, растровые шрифты используются видеокартой, работающей в текстовом режиме, но также часто и как элемент графического интерфейса). Их применение позволяет отображать символы с недостижимой иным способом четкостью, но, если нужно более одного размера шрифта, потребуется трудоемкая работа по разработке нескольких таких шрифтов. Когда необходимо свободное масштабирование шрифтов, используются векторные шрифты (на самом деле, большинство масштабируемых шрифтов — это библиотеки программ, «рисующих» соответствующие буквы, часто — с учетом важности их отдельных элементов для восприятия; но разница в данном случае несущественна). Качество отображения мелкого кегля или на экране с низкой разрешающей способностью у них ниже, но они универсальнее. Прочие элементы графических пользовательских интерфейсов также используют как векторную (большинство органов управления и большинство элементов оформления окон), так и растровую (пиктограммы-«значки») графику. Из множества свободных программ, предназначенных для редактирования векторно-графических файлов, разумные потребности большинства учебных курсов может удовлетворить любая из следующих: очень простой векторный редактор Xfig для оконной системы XFree86, sodipodi (обычно поставляется со всеми операционными системами, включающими среду «Гном»), Kontour (компонент популярного «офисного» пакета KOffice) и, наконец, «OpenDraw» (входящая в пакет «OpenOffice.org»). Рекомендуется при возможности хотя бы вкратце ознакомиться с каждой из них, чтобы понять, какая лучше подходит для конкретного учебного курса. В этом разделе далее будет обсуждаться «OpenDraw», исходя из уже описанных преимуществ, но это ни в коей мере не означает непригодность для учебных целей прочего из перечисленного. Как и остальные компоненты пакета «OO.o», «OpenDraw» использует в качестве «родного» формата специально разработанное XML-приложение (об XML и о том, почему ориентация на этот стремительно набирающий популярность формат данных важна при выборе учебных программ, см. раздел 4.1). Этот пакет доступен для популярных стандартных («ГНУ/Линукс», «Солярис») и нестандартных («Майкрософт Уиндоуз») операционных систем и прилично (хотя и не идеально) локализован. Самым же существенным недостатком «OpenDraw» являются относительно высокие требования к аппаратным ресурсам, поэтому его использование затруднительно на старых или маломощных компьютерах (для комфортной работы над несложными учебными упражнениями должно быть достаточно Intel P-II, Celeron или K6-2 с частотой от 500 МГц или G3 с частотой от 350 МГц при памяти от 64 MБ). Если нужна демонстрация векторно-графических возможностей на таких компьютерах, мы рекомендуем sodipodi или еще более «легкую» XFig. Сохранение в «чужих» векторных форматах (экспорт) на сегодня реализовано только для ранних версий предшественника «OpenOffice.org» пакета StarOffice (и StarDraw как отдельной программы). Зато импорт (чтение «чужих» форматов) возможен не только из универсальных векторных форматов, но и из DXF, используемого в популярных системах автоматизированного проектирования (САПР). «OpenDraw» также позволяет экспортировать рисунок во многие растровые форматы или в гипертекстовую страницу. Следует понимать, что StarDraw, на основе которого разработана программа, задумывалась как «офисный» графический редактор, прежде всего предназначенный для создания и редактирования графических элементов оформления документооборота (сопровождающих документы рисунков, карт, диаграмм, графиков и пр.). Поэтому действия, типичные для такой работы, максимально облегчены и «вынесены на первый план», и «OpenDraw» содержит массу готовых деталей, широко употребимых в «офисной» графике (например, готовых стрелок и множества соединительных линий, часто используемых в таких случаях). Для технического черчения и схемотехники «OpenDraw» не приспособлена (хотя при случае в ней можно создать простой чертеж или электронную схему). Документ «OpenDraw» называется «рисунком», что несколько дезориентирует, поскольку на самом деле он может содержать целую «пачку» отдельных изображений, называемых слайдами. Каждый слайд, в свою очередь, может содержать один или более слоев . Рисунок сохраняется в файле, который технически представляет собой PKZip-архив, включающий стилевые определения и собственно содержание документа на языке XML. Какой-либо инструментарий, специально предназначенный для обработки «OpenDraw» XML, нам не известен. Как и остальные компоненты «OpenOffice.org», «OpenDraw» в высшей степени конфигурируемая и настраиваемая под конкретное применение программа. Для использования в учебном контексте может оказаться полезным предварительно настроить ее для некоторого сокращения обилия непосредственно доступных пользователю функций, чтобы ученик в них не затерялся. Функциональность «OpenDraw» сопоставима с большинством других редакторов векторной графики и включает: cоздание, форматирование и преобразование объектов-графических примитивов: отрезков и стрелок; квадратов и прямоугольников; окружностей, эллипсов, дуг, сегментов и секторов; кривых Безье, «свободных» кривых, ломаных и многоугольников; cоздание, форматирование и редактирование объектов-текстовых надписей (при вводе или редактировании текстов доступна большая часть функциональности word-процессора OpenWord (см. раздел 4.1)). На самом деле, текст может содержаться в любом замкнутом контуре. В состав «OpenDraw» также входит декоративная функция FontWork, позволяющая расположить текст «фигурно» (вдоль дуги или окружности); импорт растрово-графических объектов (в том числе, и в качестве текстур заливки векторно-графических примитивов). Преобразование объектов включает: изменение характеристик линий контура (они могут быть разного цвета, сплошными, пунктирными, двойными и т.п.) и заливки (заполнения; оно возможно отдельным цветом, цветовым градиентом (переходом) и даже растровым изображением) замкнутого контура; перемещение, изменение размеров и поворот; группирование (превращение нескольких в один) и разгруппирование объектов; комбинирование и раскомбинирование объектов (разница между группированием и комбинированием слишком тонка для нашего обзора); вращение и зеркальное отображение; преобразование примитивов — линий и контуров — в произвольные кривые или ломаные; выравнивание и равномерное распределение (по вертикали или горизонтали, относительно края или центра); специальные операции, некоторые из которых описаны ниже. Большинство описанных операций преобразования доступны как посредством меню (к пунктам которого могут быть привязаны «горячие» клавиши), так и на пиктографических палитрах инструментов, наряду с палитрой цвета присутствующих (по желанию) в главном окне программы. Точное позиционирование объектов облегчает возможность отобразить сетку разметки слайда, а также команды выравнивания объектов относительно узлов этой сетки, края или центра листа (слайда), а также относительно друг друга. Особенно полезно это при создании достаточно формализованных объектов. Важной особенностью «OpenDraw» является использование механизма стилей для форматирования графических элементов. Использование стилей в векторной графике вполне сопоставимо с использованием того же механизма при оформлении размеченного текста (см. раздел 4.1) и имеет те же преимущества перед «жестким» форматированием/оформлением. Этот прием позволяет серьезно облегчить вариантное оформление рисунков, отказавшись от «жесткого» (такого, при котором для каждого объекта или группы объектов характеристики задаются вручную) форматирования объектов. Например, при подготовке схемы оргструктуры учреждения можно создать стиль, которым оформляются изображения подразделений, допустим, с голубой заливкой в черном контуре в 3 пункта толщиной. Если позднее потребуется изобразить те же подразделения желтыми прямоугольниками без рамки, не нужно будет помечать их вручную (представьте, насколько это может быть трудоемко даже для относительно простой организации типа средней школы), достаточно будет лишь изменить параметры стиля. Более того, можно определить стиль и для стрелок, показывающих связи между подразделениями, с «наследованием» цвета от цвета стиля подразделений, если предполагается, что их цвет должен совпадать. Стиль можно определить и для слайда в целом, что позволяет единообразно оформлять серию рисунков. Набор стилей можно объединить в шаблон (сохраняемый в отдельном файле), если предполагается регулярное его использование. «Логические операции» над объектами, «3D» и морфинг Интересной функцией «OpenDraw» является наличие так называемых логических операций над объектами. Два или более заполненных контура могут быть скомбинированы особым образом, что порождает новый объект, являющийся объединением форм, их пересечением или «вычитанием» одной формы из другой. Еще одной интересной особенностью программы является встроенная в нее базовая функциональность имитации трехмерной графики (3D-функции). Она ограничена 1) конструированием тел вращения, 2) преобразованием в тела вращения произвольных двумерных фигур, а также 3) экструзией (приданием последним «глубины»). Трудно понять необходимость рутинного конструирования тел вращения в «офисной» графике, однако для школы возможность такой демонстрации возможностей компьютерной графики может быть весьма полезна. Двумерный морфинг (плавное перетекание фигур) реализован в «OpenDraw» не лучшим с точки зрения эстетического результата образом, однако интересным дидактически: на самом деле, программа просто группирует заданное (в качестве «количества шагов» морфинга) количество «промежуточных» (по форме и цвету) фигур между морфируемыми фигурами. Созданную таким образом группу можно разгруппировать и посмотреть, что и как, собственно, программа сделала. Векторизация растровых изображений  Рис. 4-9 Рис. 4-9Выше уже было замечено, что, хотя преобразование векторного изображения в растр — элементарная техническая задача, гарантированное обратное преобразование в общем случае невозможно. Тем не менее, существуют программы, которые пытаются это сделать. «OpenDraw» обладает функцией векторизации, «спрятанной» в меню «Преобразовать» под кличкой «В многоугольник». Если применить данный пункт меню к импортированному растровому изображению, появится окно предпросмотра с возможностью задать некоторые параметры и увидеть результат. Ничего мистического в этой функции нет: программа ищет связные области, залитые одним или близкими цветами, и описывает их контур как многоугольник. Затем она группирует полученные фигуры одного цвета и переходит к следующему цвету или группе цветов. Результирующий векторный объект представляет собой группу, в свою очередь состоящую из цветовых групп. Более глубокого анализа программа не проводит (в принципе, можно было бы каждый выделенный объект пытаться аппроксимировать с заданной точностью отрезком, коническим сечением или кривой Безье; это позволило бы распознать элементарные геометрические фигуры, например, просканировав простой рисунок). Эта функция предусматривает слишком мало параметров, чтобы быть особенно полезной на практике, однако для демонстрации того, в чем состоит процесс векторизации, она вполне подходит. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||