|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
ПРИЛОЖЕНИЕ АИзмерение производительности А.1. ВведениеВ основной части книги мы перечислили шесть средств передачи сообщений: ■ неименованные каналы (pipes); ■ именованные каналы (FIFO); ■ очереди сообщений Posix; ■ очереди сообщений System V; ■ двери; ■ SunRPC. Кроме того, мы указали пять типов средств синхронизации: ■ взаимные исключения и условные переменные; ■ блокировки чтения-записи; ■ блокировка записей fcntl; ■ семафоры Posix; ■ семафоры System V. В этом приложении мы разработаем набор простых программ для измерения производительности этих видов IPC, чтобы иметь возможность аргументировать свой выбор одного из этих средств для конкретной задачи. При сравнении средств передачи сообщений нас интересуют два параметра: 1. Полоса пропускания (bandwidth) — скорость передачи данных по каналу IPC. Для измерения этого параметра мы передаем огромное количество данных (миллионы байтов) от одного процесса другому. Этот параметр измеряется для различных объемов данных на операцию (например, write и read для каналов), и мы ожидаем, что полоса пропускания будет увеличиваться вместе с увеличением количества передаваемых за одну операцию данных. 2. Задержка (latency) определяется как время, которое требуется небольшому сообщению, чтобы проделать путь по каналу IPC от одного процесса к другому и обратно. Мы измеряем время задержки для сообщения размером 1 байт. В реальности величина полосы пропускания говорит нам о том, сколько времени будет потрачено на передачу блока данных по каналу IPC, но IPC также используется и для передачи небольших управляющих сообщений. Задержка определяет время, необходимое для передачи этих сообщений. Важными оказываются обе величины. Чтобы измерить скорость работы средств синхронизации, мы изменим программу, увеличивающую значение счетчика в разделяемой памяти. Поскольку увеличение — элементарная операция, время будет тратиться в основном на работу средств синхронизации.
А.2. РезультатыСведем вместе результаты, полученные в этом приложении. Данный раздел может использоваться как справочник при чтении книги. Для проведения измерений использовались две системы: SparcStation 4/110 под управлением Solaris 2.6 и Digital Alpha (DEC 3000 model 300, Pelican) под управлением Digital Unix 4.0В. В файл /etc/system системы Solaris 2.6 были добавлены следующие строки: set msgsys:msginfo_msgmax = 16384 set msgsys:msginfo_msgmnb = 32768 set msgsys:msginfo_msgseg = 4096 Это дает возможность отправлять сообщения размером 16384 байт в очередь сообщений System V (табл. А.2). Те же изменения осуществляются в Digital Unix 4.0B введением следующих строк с помощью программы sysconfig: ipc: msg-max = 16384 msg-mnb = 32768 Результаты измерения полосы пропускания сообщенийВ табл. А.2 приведены результаты измерений на компьютере Sparc под управлением Solaris 2.6, а на рис. А.1 — график этих результатов. Как мы и предполагали, полоса пропускания увеличивается с размером сообщения. Поскольку во многих реализациях очередей сообщений System V ограничение на размер сообщения, установленное в ядре, достаточно мало (раздел 3.8), максимальный размер сообщения в нашей программе имеет значение 16384 байт. Уменьшение полосы для сообщений размером около 4096 байт в Solaris 2.6, возможно, связано с настройкой внутренних ограничений ядра. Для сравнения с [24] мы приводим результаты аналогичных измерений для сокета TCP и доменного сокета Unix. Эти две величины были получены с помощью программ пакета lmbench для сообщений размером 65536 байт. При измерении быстродействия сокета TCP оба процесса выполнялись на одном узле. Результаты измерения задержкиВ табл. А.1 приведены значения задержки в Solaris 2.6 и Digital Unix 4.0B. Таблица А.1. Задержка при передаче сообщения размером 1 байт (в микросекундах)
Рис. А.1. Полоса пропускания средств передачи сообщений в Solaris 2.6. В разделе A.4 мы приведем листинги программ, использованных для получения первых четырех величин, а оставшиеся три получены с помощью пакета lmbench. При измерении скорости работы TCP и UDP оба процесса находились на одном узле. Таблица А.2. Полоса пропускания для разных типов сообщений в Solaris 2.6 (Мбайт/с)
Рис. А.2. Полоса пропускания для различных средств передачи сообщений (Digital Unix 4.0B) Таблица А.З. Полоса пропускания для различных типов сообщения в Digital Unix 4.0B (Мбайт/с)
Результаты синхронизации потоковВ табл. А.4 приведены значения времени, нужного одному или нескольким потокам для увеличения счетчика в разделяемой памяти с использованием различных средств синхронизации в Solaris 2.6, а на рис. А.3 показан график этих значений. Каждый поток увеличивает значение счетчика 1000000 раз, а количество потоков меняется от 1 до 5. В табл. А.5 приведены эти же значения для Digital Unix 4.0В, а на рис. А.4 — график этих значений. Рис. А.З. Время увеличения счетчика в разделяемой памяти (Solaris 2.6) Мы увеличиваем количество потоков, чтобы проверить правильность кода. Кроме того, при добавлении потоков время работы программы может начать расти нелинейно. Блокировка fcntl может использоваться только одним потоком, поскольку эта форма синхронизации предназначена только для использования между несколькими процессами, а не потоками одного процесса. В Digital Unix 4.0B значения для семафоров Posix оказываются непомерно большими, если работает более одного потока, что указывает на наличие какой-то аномалии. На графике мы эти значения не приводим.
Рис.А.4. Время увеличения счетчика в разделяемой памяти (Digital Unix 4.0B) Таблица А.4. Время увеличения счетчика в разделяемой памяти для Solaris 2.6 (в секундах)
Таблица А.5. Время увеличения счетчика в разделяемой памяти в Digital Unix 4.0B (в секундах)
Результаты синхронизации процессовВ табл. А.4 и А.5 и на соответствующих рисунках были приведены результаты синхронизации потоков одного процесса. Интересно посмотреть, как взаимодействуют разные процессы. В табл. А.6 и на рис. А.5 приведены результаты измерения времени увеличения счетчика несколькими процессами в Solaris 2.6, а в табл. А.7 и на рис. А.6 — в Digital Unix 4.0B. Результаты похожи на полученные для потоков, однако в Solaris 2.6 теперь получаются одинаковые результаты для первых двух типов семафоров. Мы приводим на графике только первое значение для fcntl, поскольку последующие слишком велики. Как отмечалось в разделе 7.2, Digital Unix 4.0B не поддерживает атрибут PTHREAD_PROCESS_SHARED, поэтому мы не можем измерить скорость работы взаимных исключений в этой системе. Для семафоров Posix в Digital Unix 4.0B опять наблюдаются аномалии. Рис. А.5. Время увеличения счетчика в разделяемой памяти (Solaris 2.6) 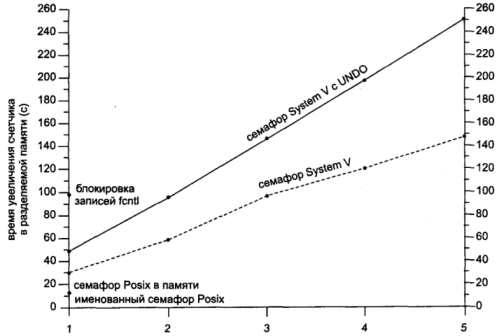 Рис. А.6. Время увеличения счетчика в разделяемой памяти Таблица А.6. Время увеличения счетчика в разделяемой памяти для Solaris 2.6 (в секундах)
Таблица А.7. Время увеличения счетчика в разделяемой памяти для Digital Unix 4.0B (в секундах)
А.З. Измерение полосы пропускания: программыВ этом разделе приведены тексты трех программ, измеряющих полосу пропускания каналов, очередей сообщений Posix и System V. Результаты работы этих программ приведены в табл. А.2 и А.З. Измерение полосы пропускания каналаНа рис. А.7 приведена схема описываемой программы. Рис. А.7. Схема программы измерения полосы пропускания канала В листинге А.1 приведен текст первой половины программы bw_pipe, измеряющей полосу пропускания канала. Листинг А.1. Функция main, измеряющая полосу пропускания канала//bench/bw_pipe.c 1 #include "unpipc.h" 2 void reader(int, int, int); 3 void writer(int, int); 4 void *buf; 5 int totalnbytes, xfersize; 6 int 7 main(int argc, char **argv) 8 { 9 int i, nLoop, contpipe[2], datapipe[2]; 10 pid_t childpid; 11 if (argc != 4) 12 err_quit("usage: bw_pipe <#loops> <#mbytes> <#bytes/write>"); 13 nloop = atoi(argv[1]); 14 totalnbytes = atoi(argv[2]) * 1024 * 1024; 15 xfersize = atoi(argv[3]); 16 buf = Valloc(xfersize); 17 Touch(buf, xfersize); 18 Pipe(contpipe); 19 Pipe(datapipe); 20 if ((childpid = Fork()) == 0) { 21 writer(contpipe[0], datapipe[1]); /* child */ 22 exit(0); 23 } 24 /* 4parent */ 25 Start_time(); 26 for (i = 0; i < nloop; i++) 27 reader(contpipe[1], datapipe[0], totalnbytes); 28 printf("bandwidth: %.3f MB/sec\n", 29 totalnbytes / Stop_time() * nloop); 30 kill(childpid, SIGTERM); 31 exit(0); 32 }Аргументы командной строки 11-15 Аргументы командной строки задают количество повторов (обычно 5), количество передаваемых мегабайтов (если указать 10, будет передано 10×1024×1024 байт) и количество байтов для каждой операции read и write (которое может принимать значения от 1024 до 65536 в наших измерениях). Выделение буфера и помещение начального значения16-17 Вызов valloc аналогичен malloc, но выделяемая память начинается с границы страницы памяти. Функция touch (листинг А.3) помещает 1 байт данных в каждую страницу буфера, заставляя ядро считать в память все страницы данного буфера. Мы всегда выполняем это перед проведением измерений. Создание двух каналов 18-19 Создаются два канала: contpipe[0] и contpipe[1] используются для синхронизации процессов перед началом передачи, a datapipe[0] и datapipe[1] используются для передачи самих данных. Вызов fork20-31 Создается дочерний процесс, вызывающий функцию writer, а родительский процесс в это время вызывает функцию reader. Функция reader вызывается nlоор раз. Функция start_time вызывается непосредственно перед началом цикла, a stop_time — сразу после его окончания. Эти функции даны в листинге А.З. Полоса пропускания представляет собой количество байтов, переданных за все проходы цикла, поделенное на время, затраченное на передачу (stop_time возвращает количество микросекунд, прошедшее с момент запуска start_time). Затем дочерний процесс завершается сигналом SIGTERM и программа завершает свою работу. Вторая половина программы приведена в листинге А.2. Она состоит из функций reader и writer. Листинг А.2. Функции reader и writer//bench/bw_pipe.cvoid 33 void 34 writer(int contfd, int datafd) 35 { 36 int ntowrite; 37 for(;;) { 38 Read(contfd, &ntowrite, sizeof(ntowrite)); 39 while (ntowrite > 0) { 40 Write(datafd, buf, xfersize); 41 ntowrite –= xfersize; 42 } 43 } 44 } 45 void 46 reader(int contfd, int datafd, int nbytes) 47 { 48 ssize_t n; 49 Write(contfd, &nbytes, sizeof(nbytes)); 50 while ((nbytes > 0) && 51 ((n = Read(datafd, buf, xfersize)) > 0)) { 52 nbytes –= n; 53 } 54 }Функция writer 33-44 Функция writer представляет собой бесконечный цикл, вызываемый дочерним процессом. Он ожидает сообщения родительского процесса о готовности к приему данных, считывая целое число из управляющего канала. Это целое число определяет количество байтов, которое будет записано в канал данных. При получении этого числа дочерний процесс записывает данные в канал, отправляя их родителю. За один вызов write записывается xfersize байтов. Функция reader45-54 Эта функция вызывается родительским процессом в цикле. Каждый раз при вызове функции в управляющий канал записывается целое число, указывающее дочернему процессу на необходимость помещения соответствующего количества данных в канал данных. Затем функция вызывает read в цикле до тех пор, пока не будут приняты все данные. Текст функций start_time, stop_time и touch приведен в листинге А.З. Листинг А.З. Функции start_sime, stop_time и touch//lib/timing.с 1 #include "unpipc.h" 2 static struct timeval tv_start, tv_stop; 3 int 4 start_time(void) 5 { 6 return(gettimeofday(&tv_start, NULL)); 7 } 8 double 9 stop_time(void) 10 { 11 double clockus; 12 if (gettimeofday(&tv_stop, NULL) == –1) 13 return(0.0); 14 tv_sub(&tv_stop, &tv_start); 15 clockus = tv_stop.tv_sec * 1000000.0 + tv_stop.tv_usec; 16 return(clockus); 17 } 18 int 19 touch(void *vptr, int nbytes) 20 { 21 char *cptr; 22 static int pagesize = 0; 23 if (pagesize == 0) { 24 errno = 0; 25 #ifdef _SC_PAGESIZE 26 if ((pagesize = sysconf(_SC_PAGESIZE)) == –1) 27 return(-1); 28 #else 29 pagesize = getpagesize(); /* BSD */ 30 #endif 31 } 32 cptr = vptr; 33 while (nbytes > 0) { 34 *cptr = 1; 35 cptr += pagesize; 36 nbytes –= pagesize; 37 } 38 return(0); 39 } Текст функции tv_sub приведен в листинге А.4. Она осуществляет вычитание двух структур timeval, сохраняя результат в первой структуре. Листинг А.4. Функция tv_sub: вычитание двух структур timeval//lib/tv_sub.c 1 #include "unpipc.h" 2 void 3 tv_sub(struct timeval *out, struct timeval *in) 4 { 5 if ((out->tv_usec –= in->tv_usec) < 0) { /* out –= in */ 6 --out->tv_sec; 7 out->tv_usec += 1000000; 8 } 9 out->tv_sec –= in->tv_sec; 10 } На компьютере Sparc под управлением Solaris 2.6 при выполнении программы пять раз подряд получим следующий результат: solaris % bw_pipe 5 10 65536 bandwidth: 13.722 MB/sec solaris % bw_pipe 5 10 65536 bandwidth: 13.781 MB/sec solaris % bw_pipe 5 10 65536 bandwidth: 13.685 MB/sec solaris % bw_pipe 5 10 65536 bandwidth: 13.665 MB/sec solaris % bw_pipe 5 10 65536 bandwidth: 13.584 MB/sec Каждый раз мы задаем пять циклов, 10 Мбайт за цикл и 65536 байт за один вызов write или read. Среднее от этих пяти результатов даст величину 13,7 Мбайт в секунду, приведенную в табл. А.2. Измерение полосы пропускания очереди сообщений PosixВ листинге А.5 приведена функция main программы, измеряющей полосу пропускания очереди сообщений Posix. Листинг А.6 содержит функции reader и writer. Эта программа устроена аналогично предыдущей, измерявшей полосу пропускания канала. Листинг А.5. Функция main для измерения полосы пропускания очереди сообщений Posix //bench/bw_pxmsg.c 1 #include "unpipc.h" 2 #define NAME "bw_pxmsg" 3 void reader(int, mqd_t, int); 4 void writer(int, mqd_t); 5 void *buf; 6 int totalnbytes, xfersize; 7 int 8 main(int argc, char **argv) 9 { 10 int i, nloop, contpipe[2]; 11 mqd_t mq; 12 pid_t childpid; 13 struct mq_attr attr; 14 if (argc != 4) 15 err_quit("usage: bw_pxmsg <#loops> <#mbytes> <#bytes/write>"); 16 nloop = atoi(argv[1]); 17 totalnbytes = atoi(argv[2]) * 1024 * 1024; 18 xfersize = atoi(argv[3]); 19 buf = Valloc(xfersize); 20 Touch(buf, xfersize); 21 Pipe(contpipe); 22 mq_unlink(Px_ipc_name(NAME)); /* error OK */ 23 attr.mq_maxmsg = 4; 24 attr.mq_msgsize = xfersize; 25 mq = Mq_open(Px_ipc_name(NAME), O_RDWR | O_CREAT, FILE_MODE, &attr); 26 if ((childpid = Fork()) == 0) { 27 writer(contpipe[0], mq); /* child */ 28 exit(0); 29 } 30 /* 4parent */ 31 Start_time(); 32 for (i = 0; i < nloop; i++) 33 reader(contpipe[1], mq, totalnbytes); 34 printf("bandwidth: %.3f MB/sec\n", 35 totalnbytes / Stop_time() * nloop); 36 kill(childpid, SIGTERM); 37 Mq_close(mq); 38 Mq_unlink(Px_ipc_name(NAME)); 39 exit(0); 40 }Листинг А.6. Функции reader и writer //bench/bw_pxmsg.c 41 void 42 writer(int contfd, mqd_t mqsend) 43 { 44 int ntowrite; 45 for(;;) { 46 Read(contfd, &ntowrite, sizeof(ntowrite)); 47 while (ntowrite > 0) { 48 Mq_send(mqsend, buf, xfersize, 0); 49 ntowrite –= xfersize; 50 } 51 } 52 } 53 void 54 reader(int contfd, mqd_t mqrecv, int nbytes) 55 { 56 ssize_t n; 57 Write(contfd, &nbytes, sizeof(nbytes)); 58 while ((nbytes > 0) && 59 ((n = Mq_receive(mqrecv, buf, xfersize, NULL)) > 0)) { 60 nbytes –= n; 61 } 62 } Программа измерения полосы пропускания очереди System VВ листинге А.7 приведен текст функции main, измеряющей полосу пропускания очередей сообщений System V, а в листинге А.8 —текст функций reader и writer. Листинг А.7. Функция main для измерения полосы пропускания очереди сообщений System V//bench/bw_svmsg.c 1 #include "unpipc.h" 2 void reader(int, int, int); 3 void writer(int, int); 4 struct msgbuf *buf; 5 int totalnbytes, xfersize; 6 int 7 main(int argc, char **argv) 8 { 9 int i, nloop, contpipe[2], msqid; 10 pid_t childpid; 11 if (argc != 4) 12 err_quit("usage: bw_svmsg <#loops> <#mbytes> <#bytes/write>"); 13 nloop = atoi(argv[1]); 14 totalnbytes = atoi(argv[2]) * 1024 * 1024; 15 xfersize = atoi(argv[3]); 16 buf = Valloc(xfersize); 17 Touch(buf, xfersize); 18 buf->mtype = 1; 19 Pipe(contpipe); 20 msqid = Msgget(IPC_PRIVATE, IPC_CREAT | SVMSG_MODE); 21 if ((childpid = Fork()) == 0) { 22 writer(contpipe[0], msqid); /* дочерний процесс */ 23 exit(0); 24 } 25 Start_time(); 26 for (i = 0; i < nloop; i++) 27 reader(contpipe[1], msqid, totalnbytes); 28 printf("bandwidth: %.3f MB/sec\n", 29 totalnbytes / Stop_time() * nloop); 30 kill(childpid, SIGTERM); 31 Msgctl(msqid, IPC_RMID, NULL); 32 exit(0); 33 }Листинг А.8. Функции reader и writer //bench/bw_svmsg.c 34 void 35 writer(int contfd, int msqid) 36 { 37 int ntowrite; 38 for (;;) { 39 Read(contfd, &ntowrite, sizeof(ntowrite)); 40 while (ntowrite > 0) { 41 Msgsnd(msqid, buf, xfersize – sizeof(long), 0); 42 ntowrite –= xfersize; 43 } 44 } 45 } 46 void 47 reader(int contfd, int msqid, int nbytes) 48 { 49 ssize_t n; 50 Write(contfd, &nbytes, sizeof(nbytes)); 51 while ((nbytes > 0) && 52 ((n = Msgrcv(msqid, buf, xfersize – sizeof(long), 0, 0)) > 0)) { 53 nbytes –= n + sizeof(long); 54 } 55 } Программа измерения полосы пропускания дверейПрограмма измерения полосы пропускания интерфейса дверей сложнее, чем предыдущие, поскольку нам нужно вызвать fork перед созданием двери. Родительский процесс создает дверь и с помощью канала оповещает дочерний процесс о том, что ее можно открывать. Другое изменение заключается в том, что в отличие от рис. А.7 функция reader не принимает данные. Данные принимаются функцией server, которая является процедурой сервера для данной двери. На рис. А.8 изображена схема программы. Рис. А.8. Схема программы измерения полосы пропускания дверей Поскольку двери поддерживаются только в Solaris, мы упростим программу, предполагая наличие двустороннего канала (раздел 4.4). Еще одно изменение вызвано фундаментальным различием между передачей сообщений и вызовом процедуры. В программе, работавшей с очередью сообщений Posix, например, записывающий процесс просто помещал сообщения в очередь в цикле, что осуществляется асинхронно. В какой-то момент очередь будет заполнена или записывающий процесс будет просто приостановлен, и тогда считывающий процесс получит сообщения. Если, например, в очередь помещается 8 сообщений и записывающий процесс помещал в нее 8 сообщений каждый раз, когда получал управление, а считывающий процесс считывал 8 сообщений, отправка N сообщений требовала N/4 переключения контекста. Интерфейс дверей является синхронным: вызывающий процесс блокируется каждый раз при вызове door_call и не может возобновиться до тех пор, пока сервер не завершит работу. Передача N сообщений в этом случае требует N/2 переключений контекста. С той же проблемой мы столкнемся при измерении полосы пропускания вызовов RPC. Несмотря на увеличившееся количество переключений контекста, из рис. А.1 следует, что двери обладают наибольшей полосой пропускания при размере сообщений не более 25 Кбайт. В листинге А.9 приведен текст функции main нашей программы. Функции writer, server и reader приведены в листинге А.10. Листинг А.9. Функция main измерения полосы пропускания интерфейса дверей//bench/bw_door.c 1 #include "unpipc.h" 2 void reader(int, int); 3 void writer(int); 4 void server(void *, char *, size_t, door_desc_t *, size_t); 5 void *buf; 6 int totalnbytes, xfersize, contpipe[2]; 7 int 8 main(int argc, char **argv) 9 { 10 int i, nloop, doorfd; 11 char c; 12 pid_t childpid; 13 ssize_t n; 14 if (argc != 5) 15 err_quit("usage: bw_door <pathname> <#loops> <#mbytes> <#bytes/write>"); 16 nloop = atoi(argv[2]); 17 totalnbytes = atoi(argv[3]) * 1024 * 1024; 18 xfersize = atoi(argv[4]); 19 buf = Valloc(xfersize); 20 Touch(buf, xfersize); 21 unlink(argv[1]); 22 Close(Open(argv[1], O_CREAT | O_EXCL | O_RDWR, FILE_MODE)); 23 Pipe(contpipe); /* предполагается наличие двустороннего канала SVR4 */ 24 if ((childpid = Fork()) == 0) { 25 /* дочерний процесс = клиент */ 26 if ((n = Read(contpipe[0], &c, 1)) != 1) 27 err_quit("child: pipe read returned %d", n); 28 doorfd = Open(argv[1], O_RDWR); 29 writer(doorfd); 30 exit(0); 31 } 32 /* родительский процесс = сервер */ 33 doorfd = Door_create(server, NULL, 0); 34 Fattach(doorfd, argv[1]); 35 Write(contpipe[1], &c, 1); /* уведомление о готовности двери */ 36 Start_time(); 37 for (i = 0; i < nloop; i++) 38 reader(doorfd, totalnbytes); 39 printf("bandwidth: %.3f MB/sec\n", 40 totalnbytes / Stop_time() * nloop); 41 kill(childpid, SIGTERM); 42 unlink(argv[1]); 43 exit(0); 44 }Листинг A.10. Функции writer, server, reader для интерфейса дверей //bench/bw_door.c 45 void 46 writer(int doorfd) 47 { 48 int ntowrite; 49 door_arg_t arg; 50 arg.desc_ptr = NULL; /* дескрипторы не передаются */ 51 arg.desc_num = 0; 52 arg.rbuf = NULL; /* значения не возвращаются */ 53 arg.rsize = 0; 54 for(;;) { 55 Read(contpipe[0], &ntowrite, sizeof(ntowrite)); 56 while (ntowrite > 0) { 57 arg.data_ptr = buf; 58 arg.data_size = xfersize; 59 Door_call(doorfd, &arg); 60 ntowrite –= xfersize; 61 } 62 } 63 } 64 static int ntoread, nread; 65 void 66 server(void *cookie, char *argp, size_t arg_size, 67 door_desc_t *dp, size_t n_descriptors) 68 { 69 char c; 70 nread += arg_size; 71 if (nread >= ntoread) 72 Write(contpipe[0], &c, 1); /* запись закончена */ 73 Door_return(NULL, 0, NULL, 0); 74 } 75 void 76 reader(int doorfd, int nbytes) 77 { 78 char c; 79 ssize_t n; 80 ntoread = nbytes; /* глобальные переменные процедуры сервера */ 81 nread = 0; 82 Write(contpipe[1], &nbytes, sizeof(nbytes)); 83 if ((n = Read(contpipe[1], &c, 1)) != 1) 84 err_quit("reader: pipe read returned %d", n); 85 } Программа определения полосы пропускания Sun RPCПоскольку вызовы процедур в Sun RPC являются синхронными, для них действует то же ограничение, что и для дверей (см. выше). В данном случае проще создать две программы (клиент и сервер), поскольку они создаются автоматически программой rpcgen. В листинге А.11 приведен файл спецификации RPC. Мы объявляем единственную процедуру, принимающую скрытые данные переменной длины в качестве входного аргумента и ничего не возвращающую. В листинге А.12 приведен текст программы-клиента, а в листинге А.13 — процедура сервера. Мы указываем протокол в качестве аргумента командной строки при вызове клиента, что позволяет нам измерить скорость работы обоих протоколов. Листинг А.11. Спецификация RPC для измерения полосы пропускания RPC//bench/bw_sunrpc.х 1 %#define DEBUG /* сервер выполняется в приоритетном режиме */ 2 struct data_in { 3 opaque data<>; /* скрытые данные переменной длины */ 4 }; 5 program BW_SUNRPC_PROG { 6 version BW_SUNRPC_VERS { 7 void BW_SUNRPC(data_in) = 1; 8 } = 1; 9 } = 0x31230001;Листинг A.12. Клиент RPC для измерения полосы пропускания //bench/bw_sunrpc_client.с 1 #include "unpipc.h" 2 #include "bw_sunrpc.h" 3 void *buf; 4 int totalnbytes, xfersize; 5 int 6 main(int argc, char **argv) 7 { 8 int i, nloop, ntowrite; 9 CLIENT *cl; 10 data_in in; 11 if (argc != 6) 12 err_quit("usage: bw_sunrpc_client <hostname> <#loops>" 13 " <#mbytes> <#bytes/write> <protocol>"); 14 nloop = atoi(argv[2]); 15 totalnbytes = atoi(argv[3]) * 1024 * 1024; 16 xfersize = atoi(argv[4]); 17 buf = Valloc(xfersize); 18 Touch(buf, xfersize); 19 cl = Clnt_create(argv[1], BW_SUNRPC_PROG, BW_SUNRPC_VERS, argv[5]); 20 Start_time(); 21 for (i = 0; i < nloop; i++) { 22 ntowrite = totalnbytes; 23 while (ntowrite > 0) { 24 in.data.data_len = xfersize; 25 in.data.data_val = buf; 26 if (bw_sunrpc_1(&in, cl) == NULL) 27 err_quit("%s", clnt_sperror(cl, argv[1])); 28 ntowrite –= xfersize; 29 } 30 } 31 printf("bandwidth: %.3f MB/sec\n", 32 totalnbytes / Stop_time() * nloop); 33 exit(0); 34 }Листинг A.13. Процедура сервера для измерения полосы пропускания RPC //bench/bw_sunrpc_server.c 1 #include "unpipc.h" 2 #include "bw_sunrpc.h" 3 #ifndef RPCGEN_ANSIC 4 #define bw_sunrpc_1_svc bw_sunrpc_1 5 #endif 6 void * 7 bw_sunrpc_1_svc(data_in *inp, struct svc_req *rqstp) 8 { 9 static int nbytes; 10 nbytes = inp->data.data_len; 11 return(&nbytes); /* должен быть ненулевым, но xdr_void игнорирует */ 12 } А.4. Измерение задержки передачи сообщений: программыПриведем текст трех программ, измеряющих задержку при передаче сообщений по каналам, очередям Posix и очередям System V. Данные о производительности, полученные с их помощью, приведены в табл. А.1. Программа измерения задержки каналаПрограмма для измерения задержки канала приведена в листинге А.14. Листинг А.14. Программа измерения задержки канала//bench/lat_pipe.c 1 #include "unpipc.h" 2 void 3 doit(int readfd, int writefd) 4 { 5 char c; 6 Write(writefd, &c, 1); 7 if (Read(readfd, &c, 1) != 1) 8 err_quit("read error"); 9 } 10 int 11 main(int argc, char **argv) 12 { 13 int i, nloop, pipe1[2], pipe2[2]; 14 char c; 15 pid_t childpid; 16 if (argc != 2) 17 err_quit("usage: lat_pipe <#loops>"); 18 nloop = atoi(argv[1]); 19 Pipe(pipe1); 20 Pipe(pipe2); 21 if ((childpid = Fork()) == 0) { 22 for(;;) { /* дочерний процесс */ 23 if (Read(pipe1[0], &c, 1) != 1) 24 err_quit("read error"); 25 Write(pipe2[1], &c, 1); 26 } 27 ехit(0); 28 } 29 /* родительский процесс */ 30 doit(pipe2[0], pipe1[1]); 31 Start_time(); 32 for (i = 0; i < nloop; i++) 33 doit(pipe2[0], pipe1[1]); 34 printf("latency: %.3f usec\n", Stop_time() / nloop); 35 Kill(childpid, SIGTERM); 36 exit(0); 37 }Функция doit 2-9 Эта функция запускается родительским процессом. Мы измеряем время ее работы. Она помещает 1 байт в канал, из которого читает дочерний процесс, и считывает 1 байт из другого канала, в который сообщение помещается дочерним процессом. При этом измеряется именно то, что мы назвали задержкой, — время передачи небольшого сообщения туда и обратно. Создание каналов19-20 Создаются два канала, после чего вызов fork порождает дочерний процесс. При этом образуется схема, изображенная на рис. 4.6 (но без закрытия неиспользуемых дескрипторов каналов). Для этого теста требуются два канала, поскольку каналы являются односторонними, а мы хотим передавать сообщение в обе стороны. Дочерний процесс отсылает обратно сообщение22-27 Дочерний процесс представляет собой бесконечный цикл, в котором однобайтовое сообщение считывается и отсылается обратно. Измерение времени работы родительского процесса29-34 Родительский процесс вызывает функцию doit для отправки однобайтового сообщения дочернему процессу и получения ответа. После этого мы имеем гарантию, что оба процесса выполняются. Затем функция doit вызывается в цикле с измерением времени задержки. На компьютере Sparc под управлением Solaris 2.6 при запуске программы пять раз подряд мы получим вот что: solaris % lat_pipe 10000 latency: 278.633 usec solaris % lat_pipe 10000 latency: 397.810 usec solaris % lat_pipe 10000 latency: 392.567 usec solaris % lat_pipe 10000 latency: 266.572 usec solaris % lat_pipe 10000 latency: 284.559 usec Среднее для пяти попыток составляет 324 микросекунды, и именно это значение приведено в табл. А.1. Это время учитывает два переключения контекста (от родительского процесса к дочернему и обратно), четыре системных вызова (write, read, write, read) и затраты на передачу 1 байта данных по каналу. Программа измерения задержки очередей сообщений PosixПpoгрaммa измерения задержки для очередей сообщений Posix приведена в листинге А.15. Листинг А. 15. Программа измерения задержки для очереди сообщений Posix//bench/lat_pxmsg.с 1 #include "unpipc.h" 2 #define NAME1 "lat_pxmsg1" 3 #define NAME2 "lat_pxmsg2" 4 #define MAXMSG 4 /* место для 4096 байт в очереди */ 5 #define MSGSIZE 1024 6 void 7 doit(mqd_t mqsend, mqd_t mqrecv) 8 { 9 char buff[MSGSIZE]; 10 Mq_send(mqsend, buff, 1.0); 11 if (Mq_receive(mqrecv, buff, MSGSIZE, NULL) != 1) 12 err_quit("mq_receive error"); 13 } 14 int 15 main(int argc, char **argv) 16 { 17 int i, nloop; 18 mqd_t mq1, mq2; 19 char buff[MSGSIZE]; 20 pid_t childpid; 21 struct mq_attr attr; 22 if (argc != 2) 23 err_quit("usage: lat_pxmsg <#loops>"); 24 nloop = atoi(argv[1]); 25 attr.mq_maxmsg = MAXMSG; 26 attr.mq_msgsize = MSGSIZE; 27 mq1 = Mq_open(Px_ipc_name(NAME1), O_RDWR | O_CREAT, FILE_MODE, &attr); 28 mq2 = Mq_open(Px_ipc_name(NAME2), O_RDWR | O_CREAT, FILE_MODE, &attr); 29 if ((childpid = Fork()) == 0) { 30 for(;;) { /* дочерний процесс */ 31 if (Mq_receive(mq1, buff, MSGSIZE, NULL) != 1) 32 err_quit("mq_receive error"); 33 Mq_send(mq2, buff, 1.0); 34 } 35 exit(0); 36 } 37 /* родительский процесс */ 38 doit(mq1, mq2); 39 Start_time(); 40 for (i = 0; i < nloop; i++) 41 doit(mq1, mq2); 42 printf("latency: %.3f usec\n", Stop_time() / nloop); 43 Kill(childpid, SIGTERM); 44 Mq_close(mq1); 45 Mq_close(mq2); 46 Mq_unlink(Px_ipc_name(NAMED); 47 Mq_unlink(Px_ipc_name (NAME2)); 48 exit(0); 49 } 25-28 Создаются две очереди сообщений, каждая из которых используется для передачи данных в одну сторону. Хотя для очередей Posix можно указывать приоритет сообщений, функция mq_receive всегда возвращает сообщение с наивысшим приоритетом, поэтому мы не можем использовать лишь одну очередь для данного приложения. Измерение задержки очередей сообщений System VВ листинге А.16 приведен текст программы измерения времени задержки для очередей сообщений System V. Листинг А.16. Программа измерения времени задержки для очередей сообщений System V//bench/lat_svmsg.c 1 #include "unpipc.h" 2 struct msgbuf p2child = { 1, { 0 } }; /* type = 1 */ 3 struct msgbuf child2p = { 2, { 0 } }; /* type = 2 */ 4 struct msgbuf inbuf; 5 void 6 doit(int msgid) 7 { 8 Msgsnd(msgid, &p2child, 0, 0); 9 if (Msgrcv(msgid, &inbuf, sizeof(inbuf.mtext), 2, 0) != 0) 10 err_quit("msgrcv error"); 11 } 12 int 13 main(int argc, char **argv) 14 { 15 int i, nloop, msgid; 16 pid_t childpid; 17 if (argc != 2) 18 err_quit("usage: lat_svmsg <#loops>"); 19 nloop = atoi(argv[1]); 20 msgid = Msgget(IPC_PRIVATE, IPC_CREAT | SVMSG_MODE); 21 if ((childpid = Fork()) == 0) { 22 for(;;) { /* дочерний процесс */ 23 if (Msgrcv(msgid, &inbuf, sizeof(inbuf.mtext), 1, 0) != 0) 24 err_quit("msgrcv error"); 25 Msgsnd(msgid, &child2p, 0, 0); 26 } 27 exit(0); 28 } 29 /* родительский процесс */ 30 doit(msgid); 31 Start_time(); 32 for (i = 0; i < nloop; i++) 33 doit(msgid); 34 printf("latency: %.3f usec\n", Stop_time() / nloop); 35 Kill(childpid, SIGTERM); 36 Msgctl(msgid, IPC_RMID, NULL); 37 exit(0); 38 } Мы создаем одну очередь, по которой сообщения передаются в обоих направлениях. Сообщения с типом 1 передаются от родительского процесса дочернему, а сообщения с типом 2 — в обратную сторону. Четвертый аргумент при вызове msgrcv в функции doit имеет значение 2, что обеспечивает получение сообщений только данного типа. Аналогично в дочернем процессе четвертый аргумент msgrcv имеет значение 1.
Программа измерения задержки интерфейса дверейПpoгрaммa измерения задержки для интерфейса дверей дана в листинге А.17. Дочерний процесс создает дверь и связывает с ней функцию server. Родительский процесс открывает дверь и вызывает door_call в цикле. В качестве аргумента передается 1 байт данных, и ничего не возвращается. Листинг А.17. Программа измерения задержки интерфейса дверей//bench/lat_door.c 1 #include "unpipc.h" 2 void 3 server(void *cookie, char *argp, size_t arg_size, 4 door_desc_t *dp, size_t n_descriptors) 5 { 6 char c; 7 Door_return(&c, sizeof(char), NULL, 0); 8 } 9 int 10 main(int argc, char **argv) 11 { 12 int i, nloop, doorfd, contpipe[2]; 13 char c; 14 pid_t childpid; 15 door_arg_t arg; 16 if (argc != 3) 17 err_quit("usage: lat_door <pathname> <#loops>"); 18 nloop = atoi(argv[2]); 19 unlink(argv[1]); 20 Close(Open(argv[1], O_CREAT | O_EXCL | O_RDWR, FILE_MODE)); 21 Pipe(contpipe); 22 if ((childpid = Fork()) == 0) { 23 doorfd = Door_create(server, NULL, 0); 24 Fattach(doorfd, argv[1]); 25 Write(contpipe[1], &c, 1); 26 for(;;) /* дочерний процесс = сервер */ 27 pause(); 28 exit(0); 29 } 30 arg.data_ptr = &c; /* родительский процесс = клиент */ 31 arg.data_size = sizeof(char); 32 arg.desc_ptr = NULL; 33 arg.desc_num = 0; 34 arg.rbuf = &c; 35 arg.rsize = sizeof(char); 36 if (Read(contpipe[0], &c, 1) != 1) /* ждем создания */ 37 err_quit("pipe read error"); 38 doorfd = Open(argv[1], O_RDWR); 39 Door_call(doorfd, &arg); /* запуск */ 40 Start_time(); 41 for (i = 0; i < nloop; i++) 42 Door_call(doorfd, &arg); 43 printf("latency: %.3f usec\n", Stop_time() / nloop); 44 Kill(childpid, SIGTERM); 45 unlink(argv[1]); 46 exit(0); 47 } Программа измерения времени задержки Sun RPCДля измерения времени задержки Sun RPC мы напишем две программы: клиент и сервер, аналогично измерению полосы пропускания. Мы используем старый файл спецификации RPC, но на этот раз клиент вызывает нулевую процедуру сервера. Вспомните упражнение 16.11: эта процедура не принимает никаких аргументов и ничего не возвращает. Это именно то, что нам нужно, чтобы определить задержку. В листинге А.18 приведен текст клиента. Как и в решении упражнения 16.11, нам нужно воспользоваться clnt_call для вызова нулевой процедуры; в заглушке клиента отсутствует необходимая заглушка для этой процедуры. Листинг А.18. Клиент Sun RPC для измерения задержки//bench/lat_sunrpc_client.с 1 #include "unpipc.h" 2 #include "lat_sunrpc.h" 3 int 4 main(int argc, char **argv) 5 { 6 int i, nloop; 7 CLIENT *cl; 8 struct timeval tv; 9 if (argc != 4) 10 err_quit("usage: lat_sunrpc_client <hostname> <#loops> <protocol>"); 11 nloop = atoi(argv[2]); 12 cl = Clnt_create(argv[1], BW_SUNRPC_PROG, BW_SUNRPC_VERS, argv[3]); 13 tv.tv_sec = 10; 14 tv.tv_usec = 0; 15 Start_time(); 16 for (i = 0; i < nloop; i++) { 17 if (clnt_call(cl, NULLPROC, xdr_void, NULL, 18 xdr_void, NULL, tv) != RPC_SUCCESS) 19 err_quit("%s", clnt_sperror(cl, argv[1])); 20 } 21 printf("latency: %.3f usec\n", Stop_time() / nloop); 22 exit(0); 23 } Мы компилируем сервер с функцией, приведенной в листинге А.13, но она все равно не вызывается. Поскольку мы используем rpcgen для построения клиента и сервера, нам нужно определить хотя бы одну процедуру сервера, но мы не обязаны ее вызывать. Причина, по которой мы используем rpcgen, заключается в том, что она автоматически создает функцию main сервера с нулевой процедурой, которая нам нужна. А.5. Синхронизация потоков: программыДля измерения времени, уходящего на синхронизацию при использовании различных средств, мы создаем некоторое количество потоков (от одного до пяти, согласно табл. А.4 и А.5), каждый из которых увеличивает счетчик в разделяемой памяти большое количество раз, используя различные формы синхронизации для получения доступа к счетчику. Взаимные исключения PosixВ листинге А.19 приведены глобальные переменные и функция main пpoгрaммы, измеряющей быстродействие взаимных исключений Posix. Листинг А.19. Глобальные переменные и функция main для взаимных исключений Posix//bench/incr_pxmutex1.с 1 #include "unpipc.h" 2 #define MAXNTHREADS 100 3 int nloop; 4 struct { 5 pthread_mutex_t mutex; 6 long counter; 7 } shared = { 8 PTHREAD_MUTEX_INITIALIZER 9 }; 10 void *incr(void *); 11 int 12 main(int argc, char **argv) 13 { 14 int i, nthreads; 15 pthread_t tid[MAXNTHREADS]; 16 if (argc != 3) 17 err_quit("usage: incr_pxmutex1 <#loops> <#threads>"); 18 nloop = atoi(argv[1]); 19 nthreads = min(atoi(argv[2]), MAXNTHREADS); 20 /* блокировка взаимного исключения */ 21 Pthread_mutex_lock(&shared.mutex); 22 /* создание потоков */ 23 Set_concurrency(nthreads); 24 for (i = 0; i < nthreads; i++) { 25 Pthread_create(&tid[i], NULL, incr, NULL); 26 } 27 /* запуск таймера и разблокирование взаимного исключения */ 28 Start_time(); 29 Pthread_mutex_unlock(&shared.mutex); 30 /* ожидание завершения работы потоков */ 31 for (i = 0; i < nthreads; i++) { 32 Pthread_join(tid[i], NULL); 33 } 34 printf("microseconds: %.0f usec\n", Stop_time()); 35 if (shared.counter != nloop * nthreads) 36 printf("error: counter = %ld\n", shared, counter); 37 exit(0); 38 }Общие данные 4-9 Совместно используемые потоками данные состоят из взаимного исключения и счетчика. Взаимное исключение инициализируется статически. Блокирование взаимного исключения и создание потоков20-26 Основной поток блокирует взаимное исключение перед созданием прочих потоков, чтобы ни один из них не получил это исключение до тех пор, пока все они не будут созданы. Вызывается функция set_concurrency, создаются потоки. Каждый поток выполняет функцию incr, текст которой будет приведен позже. Запуск таймера и разблокирование взаимного исключения27-36 После создания всех потоков главный поток запускает таймер и освобождает взаимное исключение. Затем он ожидает завершения всех потоков, после чего останавливает таймер и выводит полное время работы. В листинге А.20 приведен текст функции incr, выполняемой каждым из потоков. Листинг А.20. Функция incr, выполняемая потоками//bench/incr_pxmutex1.c 39 void * 40 incr(void *arg) 41 { 42 int i; 43 for (i = 0; i < nloop; i++) { 44 Pthread_mutex_lock(&shared.mutex); 45 shared.counter++; 46 Pthread_mutex_unlock(&shared.mutex); 47 } 48 return(NULL); 49 }Увеличение счетчика — критическая область кода 44-46 Операция увеличения счетчика осуществляется после получения блокировки на взаимное исключение. После этого взаимное исключение разблокируется. Блокировки чтения-записиПpoгрaммa, использующая блокировки чтения-записи, является слегка измененной версией программы с взаимными исключениями Posix. Поток должен установить блокировку файла, прежде чем увеличивать общий счетчик.
В листинге А.21 приведен текст функции main, а в листинге А.22 — текст функции incr. Листинг А.21. Функция main для блокировок чтения-записи//bench/incr_rwlock1.c 1 #include "unpipc.h" 2 #include <synch.h> /* Заголовочный файл для Solaris */ 3 void Rw_wrlock(rwlock_t *rwptr); 4 void Rw_unlock(rwlock_t *rwptr); 5 #define MAXNTHREADS 100 6 int nloop; 7 struct { 8 rwlock_t rwlock; /* тип данных Solaris */ 9 long counter; 10 } shared; /* инициализация О –> USYNC_THREAD */ 11 void *incr(void *); 12 int 13 main(int argc, char **argv) 14 { 15 int i, nthreads; 16 pthread_t tid[MAXNTHREADS]; 17 if (argc != 3) 18 err_quit("usage: incr_rwlockl <#loops> <#threads>"); 19 nloop = atoi(argv[1]); 20 nthreads = min(atoi(argv[2]), MAXNTHREADS); 21 /* получение блокировки на запись */ 22 Rw_wrlock(&shared.rwlock); 23 /* создание всех потоков */ 24 Set_concurrency(nthreads); 25 for (i = 0; i < nthreads; i++) { 26 Pthread_create(&tid[i], NULL, incr, NULL); 27 } 28 /* запуск таймера и снятие блокировки */ 29 Start_time(); 30 Rw_unlock(&shared.rwlock); 31 /* ожидание завершения всех потоков */ 32 for (i = 0; i < nthreads; i++) { 33 Pthread_join(tid[i], NULL); 34 } 35 printf("microseconds: %.0f usec\n", Stop_time()); 36 if (shared.counter != nloop * nthreads) 37 printf("error: counter = %ld\n", shared.counter); 38 exit(0); 39 }Листинг А.22. Увеличение общего счетчика с использованием блокировок чтения-записи //bench/incr_rwlock1.c 40 void * 41 incr(void *arg) 42 { 43 int i; 44 for (i = 0; i < nloop; i++) { 45 Rw_wrlock(&shared.rwlock); 46 shared.counter++; 47 Rw_unlock(&shared.rwlock); 48 } 49 return(NULL); 50 } Семафоры Posix, размещаемые в памятиМы измеряем скорость работы семафоров Posix (именованных и размещаемых в памяти). В листинге А.24 приведен текст функции main, а в листинге А.23 — текст функции incr. Листинг А.23. Увеличение счетчика с использованием семафоров Posix в памяти//bench/incr_pxsem1.с 37 void * 38 incr(void *arg) 39 { 40 int i; 41 for (i = 0; i < nloop; i++) { 42 Sem_wait(&shared.mutex); 43 shared.counter++; 44 Sem_post(&shared.mutex); 45 } 46 return(NULL); 47 }Листинг А.24. Функция main для семафоров Posix, размещаемых в памяти //bench/incr_pxsem1.с 1 #include "unpipc.h" 2 #define MAXNTHREADS 100 3 int nloop; 4 struct { 5 sem_t mutex; /* размещаемый в памяти семафор */ 6 long counter; 7 } shared; 8 void *incr(void *); 9 int 10 main(int argc, char **argv) 11 { 12 int i, nthreads; 13 pthread_t tid[MAXNTHREADS]; 14 if (argc != 3) 15 err_quit("usage: incr_pxseml <#loops> <#threads>"); 16 nloop = atoi(argv[1]); 17 nthreads = min(atoi(argv[2]), MAXNTHREADS); 18 /* инициализация размещаемого в памяти семафора 0 */ 19 Sem_init(&shared.mutex, 0, 0); 20 /* создание всех потоков */ 21 Set_concurrency(nthreads); 22 for (i = 0; i < nthreads; i++) { 23 Pthread_create(&tid[i], NULL, incr, NULL); 24 } 25 /* запуск таймера и разблокирование семафора */ 26 Start_time(); 27 Sem_post(&shared.mutex); 28 /* ожидание завершения всех потоков */ 29 for (i = 0; i < nthreads; i++) { 30 Pthread_join(tid[i], NULL); 31 } 32 printf("microseconds: %.0f usec\n", Stop_time()); 33 if (shared.counter != nloop * nthreads) 34 printf("error: counter = %ld\n", shared.counter); 35 exit(0); 36 } 18-19 Создается семафор, инициализируемый значением 0. Второй аргумент в вызове sem_init, имеющий значение 0, говорит о том, что семафор используется только потоками вызвавшего процесса. 20-27 После создания всех потоков запускается таймер и вызывается функция sem_post. Именованные семафоры PosixВ листинге А.26 приведен текст функции main, измеряющей быстродействие именованных семафоров Posix, а в листинге А.25 — соответствующая функция incr. Листинг А.25. Увеличение общего счетчика с использованием именованного семафора Posix//bench/incr_pxsem2.c 40 void * 41 incr(void *arg) 42 { 43 int i; 44 for (i = 0; i < nloop; i++) { 45 Sem_wait(shared.mutex); 46 shared.counter++; 47 Sem_post(shared.mutex); 48 } 49 return(NULL); 50 }Листинг А.26. Функция main для измерения быстродействия именованных семафоров Posix //bench/incr_pxsem2.с 1 #include "unpipc.h" 2 #define MAXNTHREADS 100 3 #define NAME "incr_pxsem2" 4 int nloop; 5 struct { 6 sem_t *mutex; /* указатель на именованный семафор */ 7 long counter; 8 } shared; 9 void *incr(void *); 10 int 11 main(int argc, char **argv) 12 { 13 int i, nthreads; 14 pthread_t tid[MAXNTHREADS]; 15 if (argc != 3) 16 err_quit("usage: incr_pxsem2 <#loops> <#threads>"); 17 nloop = atoi(argv[1]); 18 nthreads = min(atoi(argv[2]), MAXNTHREADS); 19 /* инициализация именованного семафора 0 */ 20 sem_unlink(Px_ipc_name(NAME)); /* ошибка – OK */ 21 shared.mutex = Sem_open(Px_ipc_name(NAME), O_CREAT | O_EXCL, FILE_MODE, 0); 22 /* создание всех потоков */ 23 Set_concurrency(nthreads); 24 for (i = 0; i < nthreads; i++) { 25 Pthread_create(&tid[i], NULL, incr, NULL); 26 } 27 /* запуск таймера и разблокирование семафора */ 28 Start_time(); 29 Sem_post(shared.mutex); 30 /* ожидание завершения всех потоков */ 31 for (i = 0; i < nthreads; i++) { 32 Pthread_join(tid[i], NULL); 33 } 34 printf("microseconds: %.0f usec\n", Stop_time()); 35 if (shared.counter != nloop * nthreads) 36 printf("error: counter = %ld\n", shared.counter); 37 Sem_unlink(Px_ipc_name(NAME)); 38 exit(0); 39 } Семафоры System VФункция main программы, измеряющей быстродействие семафоров System V, приведена в листинге А.27, а функция incr показана в листинге А.28. Листинг А.27. Функция main для измерения быстродействия семафоров System V//bench/incr_svsem1.c 1 #include "unpipc.h" 2 #define MAXNTHREADS 100 3 int nloop; 4 struct { 5 int semid; 6 long counter; 7 } shared; 8 struct sembuf postop, waitop; 9 void *incr(void *); 10 int 11 main(int argc, char **argv) 12 { 13 int i, nthreads; 14 pthread_t tid[MAXNTHREADS]; 15 union semun arg; 16 if (argc != 3) 17 err_quit("usage: incr_svseml <#loops> <#threads>"); 18 nloop = atoi(argv[1]); 19 nthreads = min(atoi(argv[2]), MAXNTHREADS); 20 /* создание семафора и инициализация его значением 0 */ 21 shared.semid = Semget(IPC_PRIVATE, 1, IPC_CREAT | SVSEM_MODE); 22 arg.val =0; 23 Semctl(shared.semid, 0, SETVAL, arg); 24 postop.sem_num = 0; /* инициализация двух структур semop */ 25 postop.sem_op = 1; 26 postop.sem_flg = 0; 27 waitop.sem_num = 0; 28 waitop.sem_op = –1; 29 waitop.sem_flg = 0; 30 /* создание всех потоков */ 31 Set_concurrency(nthreads); 32 for (i = 0; i < nthreads; i++) { 33 Pthread_create(&tid[i], NULL, incr, NULL); 34 } 35 /* запуск таймера и разблокирование семафора */ 36 Start_time(); 37 Semop(shared.semid, &postop, 1); /* up by 1 */ 38 /* ожидание завершения всех потоков */ 39 for (i = 0; i < nthreads; i++) { 40 Pthread_join(tid[i], NULL); 41 } 42 printf("microseconds: %.0f usec\n", Stop_time()); 43 if (shared.counter != nloop * nthreads) 44 printf("error: counter = %ld\n", shared, counter); 45 Semctl(shared.semid, 0, IPC_RMID); 46 exit(0); 47 }Листинг А.28. Увеличение общего счетчика с использованием семафоров System V //bench/incr_svsem1.c 48 void * 49 incr(void *arg) 50 { 51 int i; 52 for (i = 0; i < nloop; i++) { 53 Semop(shared.semid, &waitop, 1); 54 shared.counter++; 55 Semop(shared.semid, &postop, 1); 56 } 57 return(NULL); 58 } 20-23 Создается семафор с одним элементом, значение которого инициализируется нулем. 24-29 Инициализируются две структуры semop: одна для увеличения семафора, а другая для ожидания его изменения. Обратите внимание, что поле sem_flg в обеих структурах имеет значение 0: флаг SEM_UNDO не установлен. Семафоры System V с флагом SEM_UNDOЕдинственное отличие от пpoгрaммы из листинга А.27 заключается в том, что поле sem_flg структур semop устанавливается равным SEM_UNDO, а не 0. Мы не приводим в книге новый листинг с этим небольшим изменением. Блокировка записей fcntlПоследняя пpoгрaммa использует fcntl для синхронизации. Функция main приведена в листинге А.30. Эта программа будет выполняться успешно только в том случае, если количество потоков равно 1, поскольку блокировка fcntl предназначена для использования между процессами, а не между потоками одного процесса. При указании нескольких потоков каждый из них всегда имеет возможность получить блокировку (то есть вызовы writew_lock не приводят к остановке потока, потому что процесс уже является владельцем блокировки), и конечное значение счетчика оказывается неправильным. Функция incr, использующая блокировку записей, приведена в листинге А.29. Листинг А.29. Увеличение общего счетчика с использованием блокировки записей fcntl//bench/incr_fcntl1.e 44 void * 45 incr(void *arg) 46 { 47 int i; 48 for (i = 0; i < nloop; i++) { 49 Writew_lock(shared.fd, 0, SEEK_SET, 0); 50 shared.counter++; 51 Un_lock(shared.fd, 0, SEEK_SET, 0); 52 } 53 return(NULL); 54 }Листинг А.30. Функция main для измерения производительности блокировки fcntl //bench/incr_fcntl1.e 4 #include "unpipc.h" 5 #define MAXNTHREADS 100 6 int nloop; 7 struct { 8 int fd; 9 long counter; 10 } shared; 11 void *incr(void *); 12 int 13 main(int argc, char **argv) 14 { 15 int i, nthreads; 16 char *pathname; 17 pthread_t tid[MAXNTHREADS]; 18 if (argc != 4) 19 err_quit("usage: incr_fcntll <pathname> <#loops> <#threads>"); 20 pathname = argv[1]; 21 nloop = atoi(argv[2]); 22 nthreads = min(atoi(argv[3]), MAXNTHREADS); 23 /* создание файла и получение блокировки на запись */ 24 shared.fd = Open(pathname, O_RDWR | O_CREAT | O_TRUNC, FILE_MODE); 25 Writew_lock(shared.fd, 0, SEEK_SET, 0); 26 /* создание всех потоков */ 27 Set_concurrency(nthreads); 28 for (i = 0; i < nthreads; i++) { 29 Pthread_create(&tid[i], NULL, incr, NULL); 30 } 31 /* запуск таймера и снятие блокировки на запись */ 32 Start_time(); 33 Un_lock(shared.fd, 0, SEEK_SET, 0); 34 /* ожидание завершения всех потоков */ 35 for (i = 0; i < nthreads; i++) { 36 Pthread_join(tid[i], NULL); 37 } 38 printf("microseconds: %.0f usec\n", Stop_time()); 39 if (shared.counter != nloop * nthreads) 40 printf("error: counter = %ld\n", shared.counter); 41 Unlink(pathname); 42 exit(0); 43 } 15-19 Полное имя создаваемого и используемого для блокировки файла принимается в качестве аргумента командной строки. Это позволяет измерять скорость работы для разных файловых систем. Можно ожидать, что программа будет работать гораздо медленнее при использовании NFS (если она вообще будет работать, то есть если сервер и клиент NFS поддерживают блокировку записей NFS). А.6. Синхронизация процессов: программыВ программах предыдущего раздела счетчик использовался несколькими потоками одного процесса. При этом он представлял собой глобальную переменную. Теперь нам нужно изменить эти программы для измерения скорости синхронизации различных процессов. Для разделения счетчика между родительским процессом и дочерними мы помещаем его в разделяемую память, выделяемую функцией my_shm, показанной в листинге А.31. Листинг А.31. Выделение разделяемой памяти под родительский и дочерние процессы//lib/my_shm.c 1 #include "unpipc.h" 2 void * 3 my_shm(size_t nbytes) 4 { 5 void *shared; 6 #if defined(MAP_ANON) 7 shared = mmap(NULL, nbytes, PROT_READ | PROT_WRITE, 8 MAP_ANON | MAP_SHARED, –1, 0); 9 #elif defined(HAVE_DEV_ZERO) 10 int fd; 11 /* отображение в память файла /dev/zero */ 12 if ((fd = open("/dev/zero", O_RDWR)) == –1) 13 return(MAP_FAILED); 14 shared = mmap(NULL, nbytes, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); 15 close(fd); 16 #else 17 # error cannot determine what type of anonymous shared memory to use 18 #endif 19 return(shared); /* ошибка отображения в память */ 20 } Если система поддерживает флаг MAP_ANON (раздел 12.4), мы используем этот тип разделяемой памяти. В противном случае используется отображение в память файла /dev/zero (раздел 12.5). Последующие изменения зависят от средства синхронизации и от того, что происходит с лежащим в основе этого средства типом данных при вызове fork. Детали описаны в разделе 10.12. ■ Взаимное исключение Posix: должно храниться в разделяемой памяти (вместе со счетчиком) и инициализироваться с установленным атрибутом PTHREAD_ PROCESS_SHARED. Код программы будет приведен ниже. ■ Блокировка чтения-записи Posix: должна храниться в разделяемой памяти (вместе со счетчиком) и инициализироваться с установленным атрибутом PTHREAD_PROCESS_SHARED. ■ Семафоры Posix, размещаемые в памяти: семафор должен храниться в разделяемой памяти (вместе со счетчиком), и вторым аргументом при вызове sem_init должна быть единица (указывающая на то, что семафор используется несколькими процессами). ■ Именованные семафоры Posix: следует либо вызывать sem_open из родительского и дочерних процессов по отдельности, либо вызывать sem_open в родительском процессе, учитывая, что семафор станет общим после вызова fork. ■ Семафоры System V: никакого специального кодирования не требуется, поскольку эти семафоры всегда могут использоваться как процессами, так и потоками. Дочерним процессам достаточно знать идентификатор семафора. ■ Блокировка записей fcntl: изначально предназначена для использования несколькими процессами. Мы приведем код только для программы с взаимными исключениями Posix. Взаимные исключения Posix между процессамиФункция main первой программы использует взаимное исключение Posix для обеспечения синхронизации. Текст ее приведен в листинге А.32. Листинг А.32. Функция main для измерения быстродействия взаимных исключений между процессами//bench/incr_pmutex5.с 1 #include "unpipc.h" 2 #define MAXNPROC 100 3 int nloop; 4 struct shared { 5 pthread_mutex_t mutex; 6 long counter; 7 } *shared; /* указатель, сама структура в общей памяти */ 8 void *incr(void *); 9 int 10 main(int argc, char **argv) 11 { 12 int i, nprocs; 13 pid_t childpid[MAXNPROC]; 14 pthread_mutexattr_t mattr; 15 if (argc != 3) 16 err_quit("usage: incr_pxmutex5 <#loops> <#processes>"); 17 nloop = atoi(argv[l]); 18 nprocs = min(atoi(argv[2]), MAXNPROC); 19 /* получение разделяемой памяти для родительского и дочерних процессов */ 20 shared = My_shm(sizeof(struct shared)); 21 /* инициализация взаимного исключения и его блокировка */ 22 Pthread_mutexattr_init(&mattr); 23 Pthread_mutexattr_setpshared(&mattr, PTHREAD_PROCESS_SHARED); 24 Pthread_mutex_init(&shared->mutex, &mattr); 25 Pthread_mutexattr_destroy(&mattr); 26 Pthread_mutex_lock(&shared->mutex); 27 /* порождение дочерних процессов */ 28 for (i = 0; i < nprocs; i++) { 29 if ((childpid[i] = Fork()) == 0) { 30 incr(NULL); 31 exit(0); 32 } 33 } 34 /* родительский процесс: запуск таймера и разблокирование взаимного исключения */ 35 Start_time(); 36 Pthread_mutex_unlock(&shared->mutex); 37 /* ожидание завершения всех дочерних процессов */ 38 for (i = 0; i < nprocs; i++) { 39 Waitpid(childpid[i], NULL, 0); 40 } 41 printf("microseconds: %.0f usec\n", Stop_time()); 42 if (shared->counter != nloop * nprocs) 43 printf("error: counter = %ld\n", shared->counter); 44 exit(0); 45 } 19-20 Поскольку мы запускаем несколько процессов, структура shared должна располагаться в разделяемой памяти. Мы вызываем функцию my_shm, текст которой приведен в листинге А.31. 21-26 Поскольку взаимное исключение помещено в разделяемую память, мы не можем статически инициализировать его, поэтому мы вызываем pthread_mutex_init после установки атрибута PTHREAD_PROCESS_SHARED. Взаимное исключение блокируется. 27-36 После создания дочерних процессов и запуска таймера блокировка снимается. 37-43 Родительский процесс ожидает завершения всех дочерних, после чего останавливает таймер. Листинг А.33. Увеличение счетчика с использованием взаимных исключений между процессами//bench/incr_pxmutex5.с 46 void * 47 incr(void *arg) 48 { 49 int i; 50 for (i = 0; i < nloop; i++) { 51 Pthread_mutex_lock(&shared->mutex); 52 shared->counter++; 53 Pthread_mutex_unlock(&shared->mutex); 54 } 55 return(NULL); 56 } |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||