|
||||
|
|
ТЕХНОЛОГИИ: Параллельное программированиеСтояла глухая непроглядная ночь. Редкие огни фонарей освещали безжизненные улицы небольшого городка, отражаясь в раскинувшихся тут и там лужах. Крошечными искрами в их лучах вспыхивали снежинки, медленно падавшие на деревья, улицы и крыши и через минуту исчезавшие без следа. Но люди прижимались к стеклам совсем не для того, чтобы посмотреть на приход зимы. По улицам города, вспарывая тишину, шли покрытые черно-белыми камуфляжными разводами танки. Но вот лязганье траков по брусчатке внезапно поутихло, а затем и вовсе смолкло, - на очередном перекрестке бронеколонну встретил окоп и наспех выстроенная баррикада. Головной танк, прицеливаясь, повернул башню вправо и слегка опустил ствол. Мгновение безмолвия - и ночь пронзает громкий звук… …традиционной ошибки приложения Windows, - моя программа, имитирующая сцену сражения, вылетела с очередным малоинформативным сообщением о несвоевременном обращении в оперативную память по адресу 0x85e54f29. «Когда же это, черт возьми, кончится?» - подумал я, со вздохом запуская отладчик… Введение Как вы уже догадались, эта статья - отнюдь не про войну. Просто мне не хотелось начинать описание технологий параллельного программирования со скучных векторов и систем массового обслуживания, встречающихся в наиболее распространенных параллельных приложениях - всяческих числодробилках типа графических пакетов или кодеров-декодеров и серверах, и я решил остановиться на другом «двигателе прогресса» - на компьютерных играх. С их помощью я попробую объяснить, что такое параллельное программирование, почему оно считается столь трудоемким, почему требует от программиста высокой квалификации и какие инструменты могут облегчить жизнь начинающего (и не только) «параллельного» разработчика. А модельной задачей нам послужит то самое сражение в безымянном городе, с которого начался наш рассказ. Задача Итак, допустим, что мы делаем стратегическую игрушку по мотивам Великой Отечественной войны. У нас есть игровое поле с разбросанными по нему неподвижными объектами, есть какое-то количество движущихся, умирающих и отстреливающихся объектов (юнитов), есть некий модуль искусственного интеллекта, заставляющий юниты охотиться друг на друга и не ломиться сквозь стену, выполняя приказ игрока, а аккуратно объезжать препятствия. Также у нас есть некий программный код - физический движок, обеспечивающий не только красивый и реалистичный разлет обломков юнитов после прямого попадания, но и более приземленные задачи вроде покачивания танка на ухабах, плавный разгон и торможение, модель оружия и повреждений и прочие «детали», придающие сцене естественность. И, конечно же, у нас есть графический движок, который отвечает за отображение творящегося на экране безобразия. Словом, есть все необходимое, и нам остается только собрать все это в единую программу. Для начала рассмотрим «традиционный» подход к программированию, который в нашем модельном примере выглядит следующим образом. Пишется некоторый кусочек кода (назовем его GameTick), который последовательно перебирает все имеющиеся в игре объекты, «вычисляя» события, происходящие с ними в данный момент времени (Tick, тик). Скажем, один объект - солдат в окопе - «поразмыслил» своим модулем AI, принял решение бросить гранату и бросил ее, сгенерировав новый игровой объект - летящую гранату. Другой объект - брошенный другим солдатом секунду назад «коктейль Молотова» - в результате вычислений физического движка изменил свое положение в пространстве, прошел проверку на соприкосновение с броней танка и прекратил существование. Танк, угодивший под бутылку с зажигательной смесью, перешел из состояния «танк обыкновенный» в состояние «танк горящий». Другой танк повернул башню еще на пять градусов влево. На этом игровые объекты, требующие вычислений, закончились, и сцена с игровыми объектами ушла на обработку к графическому движку, который конвертировал абстрактных солдат, танков и игровое поле во вполне осязаемые полигоны и текстуры, понятные видеокарте. При этом на экране появилась описанная выше картинка, сменившая предшествовавший кадр. А меж тем наша программа опросила клавиатуру и мышь (не решил ли пользователь как-то повлиять на ситуацию?) и перешла на уже известный нам участок кода делать очередной GameTick. Добавим сюда музыкальное сопровождение по вкусу - и игра «заработала»[Разумеется, все не так просто, но в первом приближении можно довольствоваться и этой моделью]. Танки ездят, снаряды летают, геймер отчаянно дает бойцам указания мышкой, в колонках «бумкает» все, что положено… остается лишь записать свежесотворенный шедевр на DVD и топать к издателю. А теперь представим, что все то же самое мы хотим сделать «параллельно». «Детские трудности» параллельного программирования Зачем? Ну хотя бы затем, что сегодня это модно. И без технологии HyperThreading и оптимизаций под нее нам уже года три как не жить. На самом деле, конечно, причина грядущего перехода к параллельному программированию в том, что крупнейший производитель процессоров для ПК - корпорация Intel - обещает, что к концу следующего года более 70% продаваемых ею процессоров[А стало быть, как минимум половина всех продаваемых x86-совместимых процессоров] будут двухъядерными, - с чуть меньшей производительностью в пересчете на один-единственный поток исполнения, но зато выполняющие два (или даже четыре) потока одновременно[Подробнее о двухъядерных процессорах см. на offline.computerra.ru/2005/594/39218]. Поэтому если программист сумеет хорошо «раскидать» программу на два параллельных потока (сам процессор делать этого не умеет), то он получит на двухъядерном чипе гораздо большую производительность, чем на аналогичном по стоимости одноядерном. А если не сумеет - то получится как в хорошо знакомом всем россиянам изречении о том, что «хотели как лучше…». Таким образом, налицо и кнут (грозящее снижение производительности, если оставить все «как есть»), и пряник (потенциальный прорыв в скорости) - более чем убедительные аргументы за то, чтобы не отставать от технического прогресса. *** 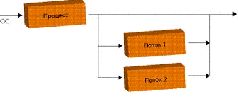 Но как это вообще делается? В классическом варианте - полностью вручную. Главный поток программы (который создала при запуске приложения операционная система) формирует (посредством специальных системных вызовов) несколько новых потоков[В случае Unix-систем при этом происходит весьма нетривиальная вещь: при создании первого потока «главный» поток как бы «замораживается» операционной системой, а в операционной системе возникают еще две сущности - новый поток, запущенный по просьбе «главного», и «наследующий» поток, который продолжает исполнение «главного» кода, но не является собственно процессом], приступающих к выполнению программы с того места, которое указывается в числе параметров вызова. Детали реализации в разных ОС отличаются[Существует два основных стандарта: используемый в мире Open Source стандартный интерфейс pthreads (POSIX Threads) и детище Microsoft - так называемая Win32 Threading model], однако принцип совершенно одинаков: одна программа, одни и те же данные, несколько точек исполнения, одновременно перемещающихся по программе. Таким образом, вместо кода типа Выполнить Действие1( ) Выполнить Действие2( ) мы записываем что-то вроде ЗапуститьПоток(Действие1) ЗапуститьПоток(Действие2) и при этом Действие1 и Действие2 выполняются параллельно и независимо друг от друга. То есть в отличие от «классики», где программа сперва проверяет, попал ли в танк снаряд, а уж затем решает, что этому танку делать дальше, здесь обсчет поведения объектов происходит одновременно. Правда, поскольку действие, как правило, выполняется одно, но над разными данными (скажем, для десятка танков вызывается один и тот же программный код, рассчитывающий физику и новые координаты танка), то гораздо чаще возникает код ЗапуститьПоток(Действие, для Объекта1) ЗапуститьПоток(Действие, для Объекта2) где в самом действии образуется конструкция вида Понять, для каких данных нужно выполнять действие Выполнить действие для этих данных С практической точки зрения это означает, что теперь не только снаряды летают одновременно с перемещением танков, но и танки ездят не «по очереди», а все сразу. И поскольку танков и снарядов у нас довольно много, то, казалось бы, игра не просто параллелится, - она разбивается на сотни потоков и, стало быть, сможет получить дополнительные преимущества даже на будущих двухпроцессорных 32-ядерных системах с поддержкой четырехпоточного HyperThreading. Однако этого не происходит, и вот почему: запуск потока - весьма и весьма дорогая по меркам процессора процедура, которая требует немалого времени, грозящего свести на нет все преимущества параллельной обработки. Переключение между потоками - тоже процесс небыстрый, и если мы разбили исполнение программы на 32 потока, а процессор умеет исполнять только два потока одновременно, то постоянные переключения между шестнадцатью потоками на каждое виртуальное ядро очень сильно «просадят» производительность. А потому программисты зачастую отказываются от «простого» решения и прибегают к более сложной конструкции, когда все необходимые рабочие потоки (причем их число тщательно выбирается, чтобы исключить лишние переключения) запускаются заблаговременно, а в нужных местах «главный» поток «раздает» им текущие задания. Что-то вроде ЗапуститьПоток(Поток1) ЗапуститьПоток(Поток2) ПопроситьПотокСделать(Поток1, Действие, для Объекта1) ПопроситьПотокСделать(Поток2, Действие, для Объекта2) В результате программист уже на начальном этапе вынужден возиться с довольно громоздкими и сложными конструкциями, которые далеко не так просто написать и отладить. И даже на этой первой, самой простой проблеме параллельного программирования многие спотыкаются. Чтобы облегчить жизнь новичкам и облегчить знакомство с параллельным кодом, существуют проекты типа OpenMP. Что такое OpenMP? Первая спецификация компилятора OpenMP (Open specifications for Multi-Processing), являющегося развитием провального и ныне забытого проекта ANSI X3H5, появилась в 1997 году и предназначалась для одного из древнейших языков программирования Fortran, на котором некогда было написано большинство «серьезных» вычислительных приложений. В 1998 году появились варианты OpenMP для языков C/C++; стандарт прижился, получил распространение и к настоящему моменту дорос до версии 2.5. Поддержка спецификации есть во всех компиляторах Intel, начиная с шестой версии (OpenMP 2.0 - с восьмой); в компиляторе Microsoft C/C++, начиная с Visual Studio 2005; буквально на днях стало известно о худо-бедно стандартизованном OpenMP-расширении для GCC[OpenMP для GNU-систем, разумеется, существовал и раньше. Но проект GOMP (GNU OpenMP), обеспечивающий полноценное встраивание поддержки OpenMP непосредственно в GCC, появился только сейчас. 18 ноября пришло сообщение о готовности встроить GOMP в свежие билды GCC - ждем с нетерпением! Для линуксоидов, конечно, вручную параллелить код для pthreads - дело привычное, однако полноценная поддержка OpenMP со стороны GNU Project полностью устранит проблему портирования параллельных приложений между ОС, использующими разные модели потоков]. OpenMP идеально портируется. Он не привязывается к особенностям операционной системы и позволяет создавать переносимые приложения, использующие потоки и объекты синхронизации. Вдобавок большинство OpenMP-директив являются (в терминологии С/C++) «прагмами» (#pragma), а потому попросту игнорируются не понимающим их компилятором[Кстати, программисты, учтите: поддержку OpenMP зачастую требуется явно включать ключом в компиляторе! И еще: далеко не все возможности OpenMP сводятся к прагмам], который генерирует из OpenMP-программ вполне корректные, хотя и однопоточные приложения. OpenMP позволяет работать на нескольких уровнях - либо задавать низкоуровневые объекты вручную, либо указывать, какие переменные являются «общими» и требуют синхронизации, передоверяя собственно синхронизацию компилятору. Благодаря OpenMP программист может вручную определять в коде программы атомные операции. На мой взгляд, этих качеств более чем достаточно, чтобы OpenMP стал таким же стандартом для параллельного программирования, которым является C/C++ для программирования обычного. Недостатков у OpenMP два. Первый - только сейчас появляющаяся поддержка сообщества Open Source. Второй - относительно жесткая модель программирования, навязываемая программисту[К примеру, совсем не очевидно, как заставить OpenMP-программу работать в режиме «системы массового обслуживания», когда некий «главный» поток принимает поступающие извне задания (скажем, запрос к БД или обращение с веб-серверу) по отдельным потокам. А вручную подобная система делается элементарно]. OpenMP В их основу положена идея использования специальных компиляторов («знающих» про параллельное программирование), для которых в коде программы расставляются специальные пометки-примечания, указывающие, что и где следует делать параллельно, а что - последовательно. Программист же пишет что-то вроде # ВыполниЭтотУчастокКодаПараллельно а компилятор пытается по его замечаниям сориентироваться. Скажем, встретив указание «разбей этот цикл по двум потокам» перед кодом, в котором перебором по всем объектам вычисляется физика и AI, компилятор пробует сгенерировать такой код, в котором будет действительно ровно два потока, каждый из них будет выполнять примерно половину общего объема работы. Язык замечаний в OpenMP развит хорошо, и на нем можно внятно растолковывать те или иные особенности исполнения данного участка программы, добиваясь нужного эффекта[OpenMP позволяет делать практически все то же самое, что доступно пользователю при работе непосредственно с операционной системой, и даже немного больше (вплоть до определения атомных операций над участками кода)]. А можно и не растолковывать, положившись целиком на компилятор - к начинающим OpenMP весьма либерален. Прибавьте сюда поддержку этого начинания корпорацией Intel, являющейся одним из ведущих производителей компиляторов для своих CPU, - и вам станет понятно, почему OpenMP превратился в стандарт де-факто, ожидающий утверждения в комитете по стандартизации ANSI. *** 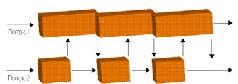 Впрочем, я отвлекся. Обещал рассказать о проблемах параллельного программирования, а рассказываю про то, как все замечательно разрабатывается вместе с OpenMP. Так что дифирамбы ему выношу во врезку и возвращаюсь к нашим баранам. Проблемы параллельного программирования В сущности, главная трудность при параллельном программировании - вовсе не в написании кода, а в том, чтобы заставить его нормально работать. «Граблей» здесь, к сожалению, очень много, и обойти их удается далеко не всегда. Грабли первые, самые простые и очевидные, - это необходимость балансировки загрузки потоков. Скажем, если один поток считает физику, другой - AI, а третий выводит на экран текущую сцену, то вполне возможно, что первые два потока управятся со своими делами гораздо раньше третьего[В играх со сложной графикой так обычно и происходит - «графическая» подсистема тормозит все остальное] и будут вынуждены его дожидаться. И если вычисления в первом потоке составляют 90% общего объема работы, а во втором - 10%, то больше чем 11-процентного увеличения производительности мы от программы не дождемся. Замечание из этой же серии: если 80% программного кода поддаются распараллеливанию, а 20% - нет, то получить больше 40% прироста производительности от добавления второго ядра (равно как и более чем пятикратный выигрыш при любом числе процессоров) невозможно. Прибавьте сюда принципиально неразделимые ресурсы - например, оперативную память[Если программу тормозила в первую очередь она и если 90% времени CPU ожидал, пока в кэш не будет залита очередная порция данных, то установка двух процессоров приведет в лучшем случае к тому, что каждый из CPU будет простаивать 95% времени, а выигрыш в быстродействии составит… 5%], - и сразу станет ясно, почему выжать из двухъядерного процессора двукратное превосходство в производительности даже в специализированных программах удается через раз, а в среднем все ограничивается 40-80%. Это не проблема, а скорее, особенность параллельного программирования; тем не менее следует помнить, что параллельность - отнюдь не панацея и что от порядка распределения данных по потокам может зависеть многое. Грабли вторые - существование разделяемых между потоками данных. Представим простейшую модельную ситуацию, когда танк попадает под обстрел во время ремонта. В текущий тик времени «в танк ударила болванка, вот-вот рванет боекомплект» - с танка снимается 70 единиц «здоровья», гибнет водитель и выходит из строя двигатель. Но в тот же тик механику, вторую минуту заменяющему разбитый трак, удается-таки справиться со своей задачей, поэтому танку добавляется 10 единиц «здоровья» и снимаются все ранее полученные повреждения[Знаю, что звучит дико, но в играх и не такое бывает]. И если все происходит действительно одновременно, то окончательное состояние танка получается недетерминированным - у него с равной вероятностью может и убавиться 70 очков, и прибавиться 10; могут и сохраниться все прежние повреждения, и бесследно сгинуть новые - все зависит только от того, «кто последний» записывал «правильные» по его мнению данные в область памяти, соответствующую танку. Вполне может получиться так, что, к примеру, 70 единиц жизни с танка снимут, а повреждения будут устранены. Или наоборот. И это еще в лучшем случае: а что будет, если в ходе попадания той болванки игра посчитает танк уничтоженным и сотрет его из памяти, а тут откуда ни возьмись прибежит механик и заявит, что несуществующему танку нужно прибавить 10 единиц «здоровья»? Катастрофа и вылет программы! *** 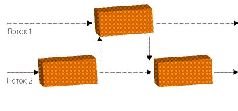 Поэтому для защиты разделяемых между несколькими потоками переменных в параллельных программах вводятся специальные объекты синхронизации, которые позволяют заблокировать изменение того или иного объекта двумя потоками одновременно. Делается это примерно так: объект[Объект синхронизации, но вместе с ним - и весь объект (тот же наш игровой танк, например), который этот объект синхронизации защищает] отдается какому-то одному конкретному потоку, а другие желающие получить объект в пользование ставятся в очередь и ждут, пока нужный объект не освободится. Программисты, забывающие это сделать, как раз и наступают на те самые вторые грабли, обладающие пренеприятным свойством незаметно ломать программу. И ломать так, что она обрушивается не в момент «поломки», а минуты через три, когда «сомнительное место» давным-давно затерялось в пучинах кода, причем происходит это каждый раз в новом месте и в новое время. Грабли третьи: если недостаточное количество объектов синхронизации - зло, ибо программист рискует заполучить время от времени глючащую программу, то переизбыток этих объектов - жуткие вериги на шее проекта. Пусть, скажем, практически любой из наших объектов может изменять игровую землю и стремится получить ее для себя. Поскольку принадлежать двум объектам одновременно земля не сможет, то находится она в каждый момент времени только у одного объекта. Который и будет обрабатываться, а всем остальным потокам придется терпеливо ожидать своей очереди. Получится вот такая картинка (рис. 3), где параллельными вычислениями и не пахнет. С этим успешно борются, беря блокировку ровно на то время, пока она действительно необходима (прочитать состояние земли, проверить его и записать новое состояние), но тогда возникают новые грабли - дедлоки. Предположим, что мы угодили снарядом в землю совсем рядышком от стоящего на ней танка. Пострадала и земля, и танк. Программа добросовестно определяет, что, где и как требуется изменить (поменять рельеф земли и изменить «жизни» у танка), берет первый объект синхронизации «на землю», тянется ко второму объекту синхронизации «на танк»… и тут же виснет. В чем дело? Оказывается, этот танк ждет, когда освободится земля, чтобы внести в нее свои изменения. И пока он земли не дождется, он не отдаст блокировку на самого себя, которая нужна потоку, который «держит» блокировку на ту самую землю. Считаете, что подобный дедлок - надуманная штука? Значит, вы никогда не занимались параллельным программированием: подобные ситуации здесь возникают если не на каждом шагу, то, по крайней мере, очень часто. Еще одна ситуация того же рода - один из потоков взял блокировку на что-то, но забыл освободить, а сторонний поток некстати решил это что-то проверить. Отсюда вытекает второе золотое правило «параллельного» программиста - никогда не пытаться обладать двумя объектами одновременно и тщательно проверять, что все однажды взятые объекты своевременно освобождаются. Неплохой джентльменский набор, не правда ли? А сколько занятных вопросов связано с работой в «параллельном» режиме стандартных библиотек! К примеру, функция GetHostByAddr в стандартном программном интерфейсе Microsoft, активно использующаяся сетевыми программами, одно время грешила тем, что при ее повторных вызовах с разными адресами из разных потоков выдавала обоим потокам указатель на одну и ту же структуру данных, хотя запрашивали они совсем разное. И если производитель клятвенно заверяет вас, что его библиотека совсем-совсем, ну честно-честно является thread-safe[Безопасной для использования в параллельном режиме], - вспомните, что даже Microsoft нет-нет да и ошибается, модифицируя продукт с десятилетней историей. А о трудности отыскания подобных глюков красноречиво свидетельствует то, сколько потребовалось времени, чтобы GetHostByAddr выловить[Исправили его в Windows XP SP1. Сколько лет он жил никем не замеченный, одному богу известно]. Интерфейс MPI Еще один стандарт де-факто в мире параллельных вычислений - пакет MPI (Message Passing Interface), тоже разрабатывавшийся как универсальное средство облегчения жизни разработчику параллельного ПО. Только устроено оно совсем иначе, нежели OpenMP, и ориентировано в основном для других, «более возвышенных» целей. Идея MPI заключается в следующем. OpenMP (да и многие другие системы для разработки параллельного ПО) ориентируется на так называемые системы с общей памятью, когда на компьютере запущена всего одна программа (точнее, один процесс), но внутри этого процесса «живет» несколько потоков исполнения, каждому из которых доступна вся память процесса, а стало быть, и все его данные. MPI исходит из другой предпосылки: на компьютере запущено много-много программ (процессов), которые друг с другом напрямую общаться не могут и вынуждены устанавливать контакт через специальные окна или даже внешние каналы связи. Называется все это IPC (Inter-Process Communication) и, как вы уже, наверное, догадались, сильно изменяется от компьютера к компьютеру и от операционной системе к операционной системе. А MPI - попытка стандартизировать связь между процессами, предоставив всем желающим удобную модель запуска на нескольких процессорах тех программ, которые будут коллективно обрабатывать данные, и обеспечивая «почтовые пересылки» между этими программами. Вот и весь Message Passing Interface. MPI универсален и всеяден. Он не накладывает практически никаких ограничений на приложение, на железо, на каналы, которые используются для связи между компьютерами. Можно в буквальном смысле слова поставить на стол две персоналки с MPI, соединить их Ethernet-кабелем - и кластер на два процессора, на котором можно запускать любое MPI-приложение, - готов! Потому-то этот интерфейс так и любят ученые, реализующие с его помощью программы для самых немыслимых суперкомпьютеров. Впрочем, при желании можно использовать MPI и для обычных двухъядерных процессоров или двухпроцессорных систем - «вотчины» проектов OpenMP. Но, конечно, MPI для таких целей «тяжеловат», - как в плане быстроты исполнения программного кода, которому, в отличие от его OMP-коллег, приходится еще и оплачивать «накладные расходы» на канал связи, так и в плане высокой сложности разработки MPI-приложений. Последние, правда, лишены большинства тех «граблей», которые существуют для обычных систем с распределенной памятью; но зато для написания соответствующего кода от программиста требуется четкое мышление, позволяющее в деталях продумать систему обмена информацией между процессами. Отладка параллельных приложений Это отдельная песня. Я не говорю даже о том, что когда в программе запущен не один, а несколько потоков, то пошаговая отладка превращается в настоящий кошмар: контрольные точки «ловят» все треды подряд, а шаг одного потока запросто может сопровождаться полусотней шагов соседнего. Главная проблема в отладке параллельных приложений заключается в том, что возникающие там глюки уникальны. Зачастую они связаны со случайным совпадением каких-то событий в «жизни» слабо связанных друг с другом потоков, а потому проявляются, как говорится, в соответствии с текущей фазой луны, - возникнут раз-другой и бесследно исчезнут. Мало того, иногда присутствие «наблюдателя» (отладочных средств) изменяет результат измерений, поскольку слегка перестраивает «свойства окружающей среды», - вот и вылавливай после этого какой-нибудь плавающий глюк, обусловленный параллельностью. *** 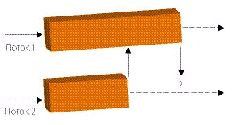 Возможных решений тут всего три. Во-первых, средства, подобные OpenMP, заметно упрощают разработку «параллельных» программ, поскольку устраняют необходимость ручного задания объектов синхронизации. Правда, платить за это приходится еще более суженной функциональностью и производительностью (автоматика особой сообразительностью не отличается), так что изучить объекты синхронизации программисту не помешает. Второй способ - использование «по старинке» большого объема выводимой вручную отладочной информации. И, наконец, третий - использование специальных программ вроде Intel Thread Checker, не только наглядно и доступно отображающих в виде графика ход исполнения программы, но и способных в некоторых случаях находить распространенные ошибки начинающих. Выводы Как ни крути, за параллельными приложениями будущее, - а значит, пришла пора осваивать соответствующие приемы программирования и инструментарий. Компания Intel не только обещает завалить рынок недорогими многоядерными процессорами, но и предоставляет весь необходимый инструментарий для полноценного использования своих разработок. И судя по тому, что новейшие продукты Intel на процессорах AMD зачастую отказываются запускаться - AMD как платформе разработчиков вскоре придется неуютно. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||