|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Глава 2 Математические основы криптографии Большое влияние на развитие криптографии оказали появившиеся в середине нашего века работы американского математика Клода Шеннона. В этих работах были заложены основы теории информации, а также был разработан математический аппарат для исследований во многих областях науки, связанных с информацией. В данной главе мы кратко ознакомим вас с основополагающими математическими понятиями и идеями, без знания которых успешная работа в области криптографии невозможна. 2.1. Приведение любой информации к двоичному виду  Для того, чтобы доказывать математические теоремы, нужно четко определить объекты, с которыми мы имеем дело. При шифровании текста необходимо, в первую очередь, знать, какие символы могут в нем встречаться, или, проще говоря, знать алфавит. Но алфавитов существует великое множество. Передаваемая информация может состоять и просто из наборов цифр, скажем, номера счетов в банке и деланные по ним выплаты. Поэтому естественно работать с некоторым обобщенным алфавитом — тогда одну и ту же теорему не нужно будет отдельно доказывать, например, для текстов на русском и на английском языке. В теоретической криптографии принято работать с универсальным алфавитом, состоящим из всех двоичных слов некоторой длины. Двоичное слово длины n — это набор из n нулей и единиц. Соответствующий алфавит состоит из 2n символов. Выбор такого алфавита объясняется многими соображениями. При использовании компьютеров удобно представлять информацию в виде последовательностей нулей и единиц. Это, в частности, обусловлено применяемыми техническими средствами: в компьютере используются элементы, которые могут находиться в одном из двух состояний. Одно из них обозначается «0», а другое — «1». С другой стороны, слова в любом алфавите можно легко перевести в двоичные слова. Пусть мы имеем дело с текстами на русском языке и пусть буквы «е» и «ё», а также «и» и «й» не различаются, а пробел между словами считается отдельной буквой (обозначение: _). Тогда наш алфавит состоит из тридцати двух символов. Рассмотрим теперь телеграфный код — старое техническое применение двоичной системы счисления. Он состоит тоже из 32 символов — двоичных слов длины 5. (Подробно о двоичной и других системах счисления можно прочитать в брошюре С.В. Фомина «Системы счисления» из серии «Популярные лекции по математике».) Сопоставим каждой букве двоичное слово длины 5 следующим образом: _ → 00000, A → 00001, Б → 00010, B → 00011, Г → 00100, Д → 00101, ... , Ю → 11110, Я → 11111. Заменив в тексте каждую букву на соответствующее двоичное слово, получим двоичный вид нашей информации — некоторую последовательность нулей и единиц (или, как принято говорить, битов). Подобным образом можно поступить и с любым другим алфавитом. На практике создаются специальные устройства, которые позволяют автоматически переводить вводимую человеком текстовую информацию в двоичную. Более того, в настоящее время практически любая информация — речь, телевизионные сигналы, музыка и др. — может храниться и пересылаться в двоичном виде. Для работы с такой информацией используют специальные устройства: например, АЦП и ЦАП (аналого-цифровой и цифро-аналоговый преобразователи), устройства для цифровой записи и воспроизведения музыки. Таким образом, двоичные слова и двоичные последовательности — типовые объекты в криптографических исследованиях. Подумайте сами: 1. Докажите, что каждое натуральное число n единственным образом представляется в виде n=2k+ak−12k−1+...+a12+a0, где k — некоторе целое неотрицательное число, а каждое из чисел ak−1, ..., a0 — либо 0, либо 1. 2.2. Случайность и закономерность в двоичных последовательностях Понятие последовательности известно еще со школьных лет. Однако последовательности, которые там изучались, были детерминированными — они однозначно восстанавливались по их нескольким элементам. Так, арифметическая и геометрическая прогрессии восстанавливаются по любым двум своим подряд идущим членам. Значения многочлена в целых точках также образуют детерминированную последовательность: она определяется любыми n+1 своими членами, где n — степень данного многочлена (докажите это!). Но существуют и другие последовательности, так называемые случайные. Для них, в отличие от детерминированных, вообще говоря, нельзя определить очередной член последовательности, зная предыдущие. Опишем простейший способ получения двоичной случайной последовательности.  Пусть мы подбрасываем «правильную» монету. В зависимости от того, как она падает, полагаем очередной член последовательности равным 0 (орел) или 1 (решка). Как показывает опыт, обычно нельзя угадать, как монета упадет в очередной раз. Однако, если подбрасывать монету достаточно долго, примерно в половине случаев выпадет орел, а в половине — решка. Говорят, что монета падает случайным образом, причем в каждом подбрасывании с одинаковой вероятностью ½ выпадает орел (0) или решка (1). Однако бывают ситуации («кривая монета»), когда орел и решка выпадают с разной вероятностью — p и q соответственно (p≠q). Отметим, что p+q=1! В случайной двоичной последовательности, полученной на основе подбрасывания «кривой монеты», p можно считать частотой появления нуля, а q — частотой появления единицы. Для тех кто изучал пределы, уточним: если обозначить через S0(k) число нулей, а через S1(k) — число единиц среди k первых членов нашей последовательности, то тогда предел отношения S0(k)/k равен p и предел отношения S1(k)/k равен q при k стремящемся к бесконечности. 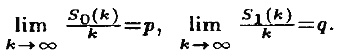 Контрольный вопрос. Пусть мы случайным образом подбрасываем монету, причём p=q=½ и первые сто членов соответствующей последовательности равны 1 (100 раз подряд выпала решка). Чему равно вероятность того, что 101-ым членом этой последовательности снова будет 1? Правильный ответ на этот вопрос: ½. Так как q=½, а случайность нашей последовательности как раз и означает, что каждый очередной её член равен 1 с вероятностью q независимо от того, какими были предыдущие её члены. Обычно последовательности, с которыми на практике приходится иметь дело, вообще говоря, не строго случайные (неслучайные). Изучение случайных и неслучайных двоичных последовательностей имеет важное значение для криптографии. Например, выявление закономерностей в шифрованных сообщениях очень полезно при вскрытии шифра (см. этюд 2.7). В этюде 2.5 вы также узнаете, что для построения абсолютно стойкого шифра необходимо уметь получать совершенно случайный ключ. Задачам различения случайной и неслучайной последовательностей, а также выявления закономерностей в неслучайных последовательностях посвящено много исследований в различных областях математики. Так, например, один из основных разделов математической статистики — это проверка статистических гипотез, в котором, в частности, разрабатываются методы различения гипотез о природе и характеристиках наблюдаемых последовательностей. Другой пример — это активно изучаемый в современной теоретической криптографии гипотетический объект — псевдослучайный генератор. При изучении этого объекта используются многочисленные результаты теории сложности алгоритмов и вычислений. Говоря неформально, псевдослучайный генератор вырабатывает такие последовательности, которые трудно отличить от случайных и из которых трудно извлечь закономерности. Строгие определения необходимых понятий выходят за рамки нашей книги. Близким по духу, но более простым и хорошо известным, особенно для программистов, является такой объект, как датчик случайных чисел. Это — некоторое устройство или программа, которая вырабатывает псевдослучайные последовательности. Псевдослучайные последовательности в некоторых ситуациях считают неотличимыми от случайных, причем для разных ситуаций и задач подбирают подходящие датчики. Чем более сильные требования накладываются на случайность вырабатываемых последовательностей, тем более сложным является соответствующий датчик случайных чисел. Многие шифрмашины можно считать датчиками случайных чисел, удовлетворяющими очень высоким требованиям на качество вырабатываемых последовательностей. Опишем, например, один простейший датчик, предложенный в 1949 году Д.Х. Лемером и в дальнейшем получивший название линейного конгруэнтного метода. Для заданного начального числа a0 он вырабатывает бесконечную последовательность натуральных чисел {ak} по следующему рекуррентному закону: ak=d+ak−1 ∙ ℓ(modN). Здесь параметры датчика d, ℓ, N — некоторые целые числа. Запись a=b(modN), вообще говоря, означает, что a−b делится на число N; в данном случае в качестве ak берется остаток от деления d+ak−1 ∙ ℓ на N. Поскольку все члены последовательности {ak} — неотрицательные целые числа, не превосходящие N−1, то среди них найдутся два одинаковых, скажем ai и ai+t. Тогда, как легко видеть, ai=ai+t для k≥i, т.е. последовательность — периодическая с длиной периода t. Конечно, периодичность не вполне согласуется с нашими представлениями о случайности, но, оказывается, можно подбирать такие параметры датчика, чтобы период был достаточно большим и у последовательности были многие признаки случайности. Следует отметить, что «хорошей во всех отношениях случайной последовательности» практически не существует: насколько «хорошей» является случайная последовательность, зависит от ее назначения. Подумайте сами: 1. Докажите следующее утверждение: вероятность того, что при k подбрасываниях кривой монеты ℓ раз выпадет орёл, равняется: 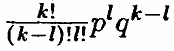 2. Придумайте такие числа d, ℓ и N, чтобы N было не слишком маленьким и длина периода последовательности, полученной линейным конгруэнтным методом, была близка к N. 3. Придумайте какой-нибудь свой датчик случайных чисел. 2.3. Что такое алгоритм и его сложность  Под алгоритмом, если говорить неформально, можно понимать четко описанную последовательность действий, приводящую к определенному результату. Понятие алгоритма очень долго оставалось интуитивным понятием. Только в 30-е годы XX века в работах выдающихся математиков Д. Гильберта, А. Черча, С. Клини, Э. Поста и А. Тьюринга были предложены формальные определения алгоритма на основе понятия рекурсивной функции и на основе описания алгоритмического процесса. Тем самым формировалась теория алгоритмов — новое направление в математике, которое стало впоследствии теоретической основой развития вычислительной техники. В настоящее время теория алгоритмов бурно развивается, многие ее понятия проясняются и уточняются (доказуемость, разрешимость, эффективность и др.). С нематематическими алгоритмами мы постоянно встречаемся в жизни (таковыми можно считать, например, рецепт приготовления борща или инструкцию о проведении экзамена в школе). Простейшим примером математического алгоритма может служить хорошо известный алгоритм Евклида, при помощи которого можно найти наибольший общий делитель двух чисел. А такой вид деятельности, как программирование — это постоянная работа с алгоритмами. Очень важным понятием в математике (интуитивно ясным, но не очень просто формализуемым) является сложность алгоритма. Приведем простой пример. Пусть требуется угадать задуманное число, про которое известно, что оно натуральное и не превосходит 1000. Разрешается задавать вопросы, на которые можно ответить «да» или «нет». Одним из способов (алгоритмов) угадывания может быть такой: последовательно перебираются все числа от 1 до 1000 до тех пор, пока нужное число не будет найдено. В худшем случае для этого потребуется 999 вопросов. Однако можно предложить и другой алгоритм, позволяющий угадать число за 10 вопросов: сначала выясняется, больше ли угаданное число 500 или нет, если да, то больше 750 или нет и т.д. С каждым шагом число возможных кандидатов уменьшается в два раза. Здесь сложностью алгоритма можно считать число вопросов. Тогда первый алгоритм в 100 раз «сложнее» второго. Если алгоритм проводит серии вычислений, сложностью алгоритма можно считать число совершаемых операций. При этом, если в алгоритме встречаются только умножение и сложение, под сложностью часто понимается только число умножений, поскольку эта операция требует существенно большего времени. На практике необходимо также учитывать стоимость операций, выполняемых алгоритмом, и т.п. В математической теории сложности вычислений рассматриваются алгоритмы решения не конкретных задач, а так называемых массовых задач. Массовую задачу удобно представлять себе в виде бесконечной серии индивидуальных задач. Индивидуальная задача характеризуется некоторым размером, т.е. объемом входных данных, требуемых для описания этой задачи. Если размер индивидуальной задачи — некоторое натуральное число n, тогда сложность алгоритма решения массовой задачи становится функцией от n. Приведем два примера. Рассмотрим алгоритм простого перебора всех двоичных ключей длины n. Ясно, что таких ключей — 2n, и поэтому в данном алгоритме 2n шагов, т.е. его сложность равна 2n. Это — простейший пример экспоненциального алгоритма (его сложность выражается через n экспонентой). Большинство экспоненциальных алгоритмов — это просто варианты полного перебора. Рассмотрим теперь алгоритм умножения столбиком двух n-значных чисел. Он состоит из n2 умножений однозначных чисел, т.е. его сложность, измеренная количеством таких умножений, равна n2. Это — простейший пример полиномиального алгоритма (его сложность выражается через n полиномом). Достаточно очевидно, что для решения одной и той же математической задачи могут быть предложены различные алгоритмы. Поэтому под сложностью задачи понимают минимальную сложность алгоритмов ее решения. Возвращаясь теперь к этюду 1.6, можно сказать в новых терминах, что стойкость шифра — это сложность задачи его вскрытия. В математике есть много задач, для решения которых пока не удалось построить полиномиальный алгоритм. К ним относится, например, задача коммивояжера: есть n городов, соединенных сетью дорог, и для каждой дороги указана стоимость проезда по ней; требуется указать такой маршрут, проходящий через все города, чтобы стоимость проезда по этому маршруту была минимальной. Подумайте сами: 1. Можете ли вы предложить алгоритм умножения двух n-значных чисел, требующий меньшего числа умножений однозначных чисел, чем при умножении столбиком? 2.4. Шифры замены и перестановки В своей работе «Математическая теория секретной связи» Клод Шеннон обобщил накопленный до него опыт разработки шифров. Оказалось, что даже в сложных шифрах в качестве типичных компонентов можно выделить шифры замены, шифры перестановки или их сочетания. Эти шифры можно считать как бы базовыми.  Шифр замены является простейшим, наиболее популярным шифром. Типичными примерами являются шифр Цезаря, «цифирная азбука» Петра Великого и «пляшущие человечки» А. Конан-Дойля. Как видно из самого названия, шифр замены осуществляет преобразование замены букв или других «частей» открытого текста на аналогичные «части» шифрованного текста. Понятно, что, увеличив алфавиты, т.е. объявив «части» буквами, можно любой шифр замены свести к замене букв. Теперь уже легко дать математическое описание шифра замены. Пусть X и Y — два алфавита открытого и соответственно шифрованного текстов, состоящие из одинакового числа символов. Пусть также g : X → Y — взаимно-однозначное отображение X в Y. Это значит, что каждой букве x алфавита X сопоставляется однозначно определенная буква y алфавита Y, которую мы обозначаем символом g(x), причем разным буквам сопоставляются разные буквы. Тогда шифр замены действует так: открытый текст x1x2...xn преобразуется в шифрованный текст g(x1)g(x2)...g(xn). К вопросу о вскрытии шифра замены мы вернемся в этюде 2.8.  Шифр перестановки, как видно из названия, осуществляет преобразование перестановки букв в открытом тексте. Типичным и древнейшим примером шифра перестановки является шифр «Сциталь». Обычно открытый текст разбивается на отрезки равной длины, и каждый отрезок шифруется (т.е. в нем переставляются буквы) независимо. Пусть, например, длина отрезков равна n и σ — взаимно-однозначное отображение множества {1,2, ..., n} в себя. Тогда шифр перестановки действует так: отрезок открытого текста x1...xn преобразуется в отрезок шифрованного текста xσ(1)...xσ(n). Важной проблемой при практическом использовании шифров замены и перестановки является проблема удобного запоминания отображений g и σ. Ясно, что легко запоминать некоторые отображения: например, отображения «небольших» размеров, отображения, реализуемые каким-нибудь предметом (сциталь в шифре «Сциталь» и т.п.). Если же отображение «большого» размера, то процесс запоминания сильно усложняется. Например, широко известны биграммные шифры. В них преобразовывались биграммы (пары букв). Поскольку количество биграмм превышает 1000, то на практике биграммные шифры выглядят как специальные книжки. Для облегчения запоминания отображений g и σ изобретались различные хитроумные способы. Правда, «расплатой» за это было упрощение используемых отображений и тем самым уменьшение стойкости шифров. Популярным способом запоминания отображения σ, т.е. шифра перестановки, является следующий. Пусть, например, n=20. Берем прямоугольную таблицу размера 4x5, вписываем в нее открытый текст «по строкам», а шифрованный текст считываем «по столбцам». Возможны и более хитрые способы вписывания и считывания. Подумайте сами: 1. Выпишите отображение g для шифра Цезаря. 2. Выпишите отображение σ для описанного шифра перестановки — прямоугольника 4×5. 2.5. Возможен ли абсолютно стойкий шифр Да, и единственным таким шифром является какая-нибудь форма так называемой ленты однократного использования, в которой открытый текст «объединяется» с полностью случайным ключом такой же длины, Этот результат был доказан К. Шенноном с помощью разработанного им теоретико-информационного метода исследования шифров. Мы не будем здесь останавливаться на этом подробно, но заинтересованному читателю рекомендуем изучить работу К. Шеннона, она указана в списке литературы. Обсудим особенности строения абсолютно стойкого шифра и возможности его практического использования. Типичным и наиболее простым примером реализации абсолютно стойкого шифра является шифр Вернама, который осуществляет побитовое сложение n-битового открытого текста и n-битового ключа: yi=x1⊕ki, i=1, ..., n. Здесь x1, ..., xn — открытый текст, k1, ..., kn — ключ, y1, ..., yn — шифрованный текст; символы складываются по таким правилам: 0⊕0=0, 0⊕1=1⊕0=1, 1⊕1=0. Подчеркнем теперь, что для абсолютной стойкости существенным является каждое из следующих требований к ленте однократного использования: 1) полная случайность (равновероятность) ключа (это, в частности, означает, что ключ нельзя вырабатывать с помощью какого-либо детерминированного устройства); 2) равенство длины ключа и длины открытого текста; 3) однократность использования ключа. В случае нарушения хотя бы одного из этих условий шифр перестает быть абсолютно стойким и появляются принципиальные возможности для его вскрытия (хотя они могут быть трудно реализуемыми). Но, оказывается, именно эти условия и делают абсолютно стойкий шифр очень дорогим и непрактичным. Прежде чем пользоваться таким шифром, мы должны обеспечить всех абонентов достаточным запасом случайных ключей и исключить возможность их повторного применения. А это сделать необычайно трудно и дорого. Как отмечал Д. Кан: «Проблема создания, регистрации, распространения и отмены ключей может показаться не слишком сложной тому, кто не имеет опыта передачи сообщений по каналам военной связи, но в военное время объем передаваемых сообщений ставит в тупик даже профессиональных связистов. За сутки могут быть зашифрованы сотни тысяч слов. Создание миллионов ключевых знаков потребовало бы огромных финансовых издержек и было бы сопряжено с большими затратами времени. Так как каждый текст должен иметь свой собственный, единственный и неповторимый ключ, применение идеальной системы потребовало бы передачи, по крайней мере, такого количества знаков, которое эквивалентно всему объему передаваемой военной информации». В силу указанных причин, абсолютно стойкие шифры применяются только в сетях связи с небольшим объемом передаваемой информации, обычно это сети для передачи особо важной государственной информации.  2.6. Стойкость теоретическая и практическая Теперь мы уже понимаем, что чаще всего для защиты своей информации законные пользователи вынуждены применять неабсолютно стойкие шифры. Такие шифры, по крайней мере теоретически, могут быть вскрыты. Вопрос только в том, хватит ли у противника сил, средств и времени для разработки и реализации соответствующих алгоритмов. Обычно эту мысль выражают так: противник с неограниченными ресурсами может вскрыть любой неабсолютно стойкий шифр. Как же должен действовать в этой ситуации законный пользователь, выбирая для себя шифр? Лучше всего, конечно, было бы доказать, что никакой противник не может вскрыть выбранный шифр, скажем, за 10 лет и тем самым получить теоретическую оценку стойкости. К сожалению, математическая теория еще не дает нужных теорем — они относятся к нерешенной проблеме нижних оценок сложности задач. Поэтому у пользователя остается единственный путь — получение практических оценок стойкости. Этот путь состоит из следующих этапов: — понять и четко сформулировать, от какого противника мы собираемся защищать информацию; необходимо уяснить, что именно противник знает или сможет узнать о системе шифра, какие силы и средства он сможет применить для его вскрытия; — мысленно стать в положение противника и пытаться с его позиций атаковать шифр, т.е. разрабатывать различные алгоритмы вскрытия шифра; при этом необходимо в максимальной мере обеспечить моделирование сил, средств и возможностей противника; — наилучший из разработанных алгоритмов использовать для практической оценки стойкости шифра. Здесь полезно для иллюстрации упомянуть о двух простейших методах вскрытия шифра: случайного угадывания ключа (он срабатывает с маленькой вероятностью, зато имеет маленькую сложность) и перебора всех подряд ключей вплоть до нахождения истинного (он срабатывает всегда, зато имеет очень большую сложность). 2.7. Всегда ли нужна атака на ключ Нет, для некоторых шифров можно сразу, даже не зная ключа, восстанавливать открытый текст по шифрованному.  Эту мысль удобнее всего проиллюстрировать на примере шифра замены, для которого уже давно разработаны методы вскрытия. Напомним, что шифр замены математически описывается с помощью некоторой подстановки g (см. этюд 2.4). Такой шифр преобразует открытый текст в шифрованный по следующему правилу: каждая буква x заменяется на букву g(x). Вскрытие шифра основано на двух следующих закономерностях: 1) в осмысленных текстах любого естественного языка различные буквы встречаются с разной частотой, а действие подстановки g «переносит» эту закономерность на шифрованный текст; 2) любой естественный язык обладает так называемой избыточностью, что позволяет с большой вероятностью «угадывать» смысл сообщения, даже если часть букв в сообщении неизвестна. Приведем для примера относительные частоты букв алфавита русского языка.
Подобные таблицы используются для вскрытия шифра простой замены следующим образом. Составляем таблицу частот встречаемости букв в шифртексте. Считаем, что при замене наиболее частые буквы переходят в наиболее частые. Последовательно перебирая различные варианты, пытаемся либо прийти к противоречию с законами русского языка, либо получить читаемые куски сообщения. Далее по возможности продляем читаемые куски либо по смыслу, либо по законам русского языка. Подробный разбор даже одного примера может занять слишком много места. Любознательным читателям рекомендуем проделать это самостоятельно для какого-нибудь своего шифра замены. Можно также прочитать подробное описание трех примеров: — в рассказе Э. По «Золотой жук»; — в рассказе А. Конан-Дойля «Пляшущие человечки»; — в книге М.Н. Аршинова и Л.Е. Садовского «Коды и математика». 2.8. Криптография, комбинаторные алгоритмы и вычислительная техника  Зададимся теперь вопросом: от прогресса в каких областях науки зависят оценки практической стойкости шифров? Внимательный читатель сам из предыдущего изложения ответит на этот вопрос: в первую очередь это — теория сложности алгоритмов и вычислений, а также сложность реализации алгоритмов на вычислительной технике. В последние годы эти области бурно развиваются, в них получены интересные результаты, которые, в частности, влияют на оценки практической стойкости шифров. Многие полезные результаты носят характер «ухищрений» для ускорения алгоритмов и поэтому быстро входят в массовую практику программистов. Особенно это относится к области комбинаторных алгоритмов, выросшей из хорошо известных типичных задач быстрого поиска и сортировки данных. Систематическое подробное изложение этих вопросов содержится в популярном трехтомнике Д. Кнута «Искусство программирования для ЭВМ». Отметим, что к области комбинаторных алгоритмов относятся также алгоритмы для хорошо известных игр-головоломок типа «кубика Рубика». Алгоритмы вскрытия шифров, как правило, используют большое количество различных приемов сокращения перебора ключей (или других элементов шифра), а также поиска, сравнения и отбраковки данных. Поэтому в оценки стойкости шифров входят различные оценки из теории комбинаторных алгоритмов. Подумайте сами: 1. Докажите, что наименьший элемент среди чисел {x1, ..., xn} нельзя найти меньше, чем за n−1 сравнение. 2. Предложите алгоритм расположения чисел {x1, ..., xn} в порядке возрастания, использующий меньше, чем n(n−1)/2 сравнений (т.е. более эффективный, чем тривиальный алгоритм последовательного сравнения каждого числа с каждым). 3. На полке в беспорядке стоят n томов собрания сочинений. Хозяин, увидев два тома, стоящие в неправильном порядке, меняет их местами. Докажите, что не позднее, чем через n2 таких перестановок, тома будут расставлены по порядку. 4. На сортировочной станции имеется несколько поездов. Разрешается либо расцепить поезд, состоящий из нескольких вагонов, на два поезда, либо удалить поезд, если в нём всего один вагон. Докажите, что, выполняя эти действия в произвольном порядке, мы рано или поздно удалим все вагоны. 5. Задумано и введено в компьютер n натуральных чисел a1, ..., an. За один шаг разрешается ввести в компьютер любые n других натуральных чисел b1, ..., bn. После этого компьютер вычисляет сумму a1b1+ ...+ anbn и выводит результат на экран. Ясно, что этот результат содержит некоторую информацию о задуманных числах. За какое минимальное число шагов всегда можно угадать задуманные числа? |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||