|
||||
|
|
Приложение Б. Введение в С++ для программистов Java и С#Данное приложение представляет собой краткое введение в язык С++, предназначенное для разработчиков, знакомых с Java или C#. Предполагается, что вы знакомы с такими концепциями объектно—ориентированного программирования, как наследование и полиморфизм, и хотите обучиться программированию на С++. Чтобы эта книга не стала громоздким 1500—страничным томом, включающим в себя полный учебник по С++ для начинающих, это приложение ограничивается изложением только существенных вопросов. В нем представлены основные понятия и методы, необходимые для понимания программ, приводимых в остальной части книги, и достаточные для того, чтобы, используя Qt, начать разработку межплатформенных приложений с графическим пользовательским интерфейсом. На момент написания книги язык С++ представляет собой единственное реальное средство написания межплатформенных, высокопроизводительных объектно—ориентированных приложений с графическим пользовательским интерфейсом. Недоброжелатели С++ обычно отмечают, что программировать на Java или C#, который отошел от поддержки совместимости с языком С, более приятно; на самом деле Бьерн Страуструп (Bjarne Stroustrup), создатель С++, отмечал в книге «The Design and Evolution of C++» (Дизайн и эволюция С++), что «внутри С++ существует очень компактный и более аккуратный язык, изо всех сил стремящийся получить известность». К счастью, при программировании в рамках Qt мы обычно придерживаемся некоторого подмножества С++, которое сильно приближается к утопическому языку, о котором говорил Страуструп, что позволяет нам сконцентрировать свое внимание непосредственно на текущей проблеме. Более того, Qt в некоторых аспектах расширяет С++ благодаря своему новаторскому механизму «сигналов и слотов», поддержке кодировки Unicode и ключевому слову foreach. В первом разделе данного приложения мы увидим, как можно объединять несколько файлов, содержащих исходный код С++, для получения исполняемой программы. Это приведет нас к изучению таких центральных концепций С++, как единица компиляции, заголовочные файлы, объектные файлы, библиотеки, и ознакомит с препроцессором, компилятором и компоновщиком С++. Затем мы рассмотрим наиболее важные отличия языков С++, Java и C#, связанные с определением классов, использованием указателей и ссылок, перегрузками операторов, применением препроцессора и т.д. Несмотря на то что синтаксис С++ очень похож на синтаксис Java и C#, имеется тонкое отличие базовых концепций. В то же время язык С++, под влиянием которого coздaвaлиcь Java и C#, имеет много общего с этими двумя языками, в частности аналогичные типы данных, те же самые арифметические операторы и одинаковые основные операторы управления. Последней раздел посвящен стандартной библиотеке С++, которая обеспечивает функциональность, готовую к применению в любой программе на С++. Эта библиотека развивалась в течение более 30 лет и поэтому вобрала в себя многие подходы, в том числе процедурный, объектно—ориентированный и функциональный стили программирования, а также макросы и шаблоны. По сравнению с библиoтeкaми Java и C# стандартная библиотека С++ имеет довольно ограниченную область применения; она не поддерживает программирование графического пользовательского интерфейса, многопоточную обработку, базы данных, интернационализацию, работу с сетями, XML и Unicode. Для применения С++ в этих областях предполагается, что разработчики С++ должны использовать различные библиотеки (часто зависимые от платформы). Именно здесь приходит на помощь Qt. Сначала средства разработки Qt представляли собой межплатформенный инструментарий по созданию графического пользовательского интерфейса (набор классов, позволяющий писать переносимые приложения с графическим пользовательским интерфейсом), но затем они быстро превратились в полномасштабную рабочую среду, частично расширяющую и частично заменяющую стандартную библиотеку С++. Хотя эта книга посвящена средствам разработки Qt, полезно знать возможности стандартной библиотеки С++, поскольку вам, возможно, придется работать с программным кодом, использующим эту библиотеку. Первое знакомство с С++Программа С++ состоит из одной или нескольких единиц компиляции. Каждая единица компиляции представляет собой отдельный файл исходного кода, обычно имеющий расширение .cpp (другими распространенными расширениями являются .cc и .cxx); она обрабатывается компилятором за один шаг. Для каждой единицы компиляции компилятор генерирует объектный файл с расширением .obj (в Windows) или .о (в Unix и Mac OS X). Объектный файл — это бинарный файл, содержащий машинный код для той архитектуры, на которой будет выполняться программа. После компиляции всех файлов .cpp мы можем собрать все объектные файлы для создания исполняемого модуля, используя специальную программу, называемую компоновщиком (linker). Компоновщик соединяет объектные файлы в единое целое и назначает адреса памяти функциям и другим символическим ссылкам, которые содержатся в единицах компиляции. 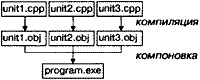 Рис. Б.1. Процесс компиляции программы на С++ (в Windows). При создании программы только одна единица компиляции должна иметь функцию main(), которая является точкой входа в программу. Эта функция не принадлежит никакому классу — она является глобальной функцией. В отличие от Java, где каждый исходный файл должен содержать точно один класс, С++ позволяет организовать единицу компиляции удобным для нас способом. Можно реализовать несколько классов в одном файле .cpp или распространить реализацию класса на несколько файлов .cpp; имена исходных файлов могут быть любыми. При внесении изменений в один конкретный файл .cpp потребуется перекомпилировать этот файл и затем повторно скомпоновать приложение для создания нового исполняемого модуля. Прежде чем мы пойдем дальше, давайте рассмотрим очень простую программу на С++, вычисляющую квадрат целого числа. Эта программа состоит из двух единиц компиляции: main.cpp и square.cpp. Ниже показан файл square.cpp: 01 double square(double n) 02 { 03 return n * n; 04 } Этот файл содержит лишь глобальную функцию с именем square(), которая возвращает квадрат своего параметра. Ниже показан файл main.cpp: 01 #include <cstdlib> 02 #include <iostream> 03 using namespace std; 04 double square(double); 05 int main(int argc, char *argv[]) 06 { 07 if (argc != 2) { 08 cerr << "Usage: square <number>" << endl; 09 return 1; 10 } 11 double n = strtod(argv[1], 0); 12 cout << "The square of " << argv[1] << " is " << square(n) << endl; 13 return 0; 14 } Исходный файл main.cpp содержит определение функции main(). В С++ эта функция принимает в качестве параметров int и char * (массив символьных строк). Имя программы находится в argv[0], а аргументы командной строки — в argv[1], argv[2], … argv[argc — 1]. Параметры имеют стандартные имена argc («argument count» — количество аргументов) и argv («argument values» — значения аргументов). Если программа не использует аргументы командной строки, функцию main() можно определить без параметров. Функция main() использует из стандартной библиотеки С++ функции strtod() («string to double» — преобразование строки в переменную двойной точности), cout (стандартный поток вывода С++) и cerr (стандартный поток вывода сообщений об ошибках С++) для преобразования аргумента командной строки в тип double и для вывода текста на консоль. Строки, числа и маркеры конца строки (endl) выводятся с помощью оператора <<, который также используется для сдвига битов. Чтобы воспользоваться этой стандартной функциональностью, необходимо включить директивы #include, расположенные в строках 1 и 2. Директива using namespace в строке 3 указывает компилятору на то, что мы хотим импортировать в глобальное пространство имен все идентификаторы, объявленные в пространстве имен std. Это позволяет нам пользоваться записью strtod(), cout, cerr и endl вместо указания полных имен: std::strtod(), std::cout, std::cerr и std::endl. В С++ оператор :: разделяет компоненты сложного имени. В строке 4 объявляется прототип функции. Он указывает компилятору на то, что существует функция с данными параметрами и возвращаемым значением. Реальное определение функции может находиться в той же или в другой единице компиляции. Без прототипа функции компилятор не позволил бы нам вызвать эту функцию в строке 12. Имена параметров функции указывать необязательно. Процедура компиляции программы зависит от платформы. Например, для компиляции программы в Solaris с использованием компилятора С++ компании «Sun» мы могли бы задать следующие команды: CC -с main.cpp CC -с square.cpp ld main.o square.o -о square Первые две строки вызывают компилятор, чтобы сгенерировать файлы .о для соответствующих файлов .cpp. Третья строка вызывает компоновщик и формирует исполняемый модуль с именем square, который может запускаться следующим образом: ./square 64 Эта программа выводит на консоль следующее сообщение: The square of 64 is 4096 (Квадрат числа 64 равен 4096) Чтобы скомпилировать программу, вы, возможно, попросите помощи у местного опытного программиста С++. Если это не удастся сделать, можете прочитать остальную часть приложения, ничего не компилируя, и воспользоваться инструкциями в главе 1 по компиляции вашего первого приложения C++/Qt. В Qt предусмотрены утилиты, позволяющие легко создавать приложения на любой платформе. Вернемся к нашей программе. В реальном приложении, как правило, мы размещали бы прототип функции square() в отдельном файле и включали бы этот файл во все единицы компиляции, в которых вызывается эта функция. Такой файл называется заголовочным; он обычно имеет расширение .h (часто встречаются также расширения .hh, .hpp и .hxx). Если переделать наш пример, используя заголовочный файл, то можно было бы создать файл с именем square.h, который содержит следующие строки: 1 #ifndef SQUARE_H 2 #define SQUARE_H 3 double square(double); 4 #endif В начале и в конце заголовочного файла задаются препроцессорные директивы (#ifndef, #define и #endif). Эти директивы гарантируют однократное выполнение заголовочного файла, даже если он несколько раз включается в одну и ту же единицу компиляции (такая ситуация возникает, когда одни заголовочные файлы включают в себя другие заголовочные файлы). По принятым соглашениям используемый для этого препроцессорный символ строится на основе имени файла (в нашем примере это символ SQUARE_H). Позже в этом приложении мы вернемся к рассмотрению препроцессора. Новый файл main.cpp будет иметь следующий вид: 01 #include <cstdlib> 02 #include <iostream> 03 #include "square.h" 04 using namespace std; 05 int main(int argc, char *argv[]) 06 { 07 if (argc != 2) { 08 cerr << "Usage: square <number>" << endl; 09 return 1; 10 } 11 double n = strtod(argv[1], 0); 12 cout << "The square of " << argv[1] << " is " << square(n) << endl; 13 return 0; 14 } Используемая в строке 3 директива #include разворачивает содержимое файла square.h. Директивы, начинающиеся с символа #, рассматриваются препроцессором С++ до фактической компиляции. В прежние дни препроцессор являлся отдельной программой, которую программист вызывал вручную перед выполнением компилятора. В современных компиляторах этап препроцессорной обработки выполняется автоматически. Директивы #include в строках 1 и 2 разворачивают содержимое заголовочных файлов cstdlib и iostream, которые являются частью стандартной библиотеки С++. Стандартные заголовочные файлы не имеют суффикса .h. Угловые скобки вокруг имен файлов говорят о том, что заголовочные файлы располагаются в стандартном месте системы, в то время как кавычки заставляют компилятор просматривать текущий каталог. Директивы #include обычно собирают вместе и располагают в верхней части файла .cpp. В отличие от файлов .cpp, заголовочные файлы сами по себе не являются единицей компиляции и не приводят к созданию объектных файлов. Они могут только содержать объявления, позволяющие различным единицам компиляции взаимодействовать друг с другом. Следовательно, было бы неправильно помещать реализацию функции square() в какой-нибудь заголовочный файл. Если бы мы это сделали в нашем примере, ничего плохого не случилось бы, потому что square.h включается только однажды, однако если бы мы включали square.h в несколько файлов .cpp, то получили бы несколько реализаций функции square() (по одной на каждый файл .cpp, который включает этот заголовочный файл). После этого компоновщик пожаловался бы на существование нескольких (идентичных) определений функции square() и отказался бы генерировать исполняемый модуль. И наоборот, если мы объявляем функцию, но нигде ее не реализуем, компоновщик пожалуется на наличие «неразрешенного символа». До сих пор мы предполагали, что исполняемый модуль состоит только из объектных файлов. На практике они компонуются также с библиотеками, которые реализуют готовую функциональность. Существует два основных типа библиотек: • статические библиотеки непосредственно помещаются в исполняемый модуль, как будто они являются объектными файлами. Это гарантирует невозможность потери библиотеки, но увеличивает размер исполняемого модуля; • динамические библиотеки (называемые также совместно используемыми библиотеками или библиотеками DLL) располагаются в стандартном месте на машине пользователя и автоматически загружаются во время запуска приложения. Программу square мы компонуем со стандартной библиотекой С++, которая реализована как динамическая библиотека на большинстве платформ. Сами средства разработки Qt представляют собой коллекцию библиотек, которые могут создаваться как статические или как динамические библиотеки (по умолчанию они создаются как динамические библиотеки). Основные отличия языковТеперь мы более внимательно рассмотрим области, в которых С++ отличается от Java и C#. Многие языковые различия объясняются особенностями скомпилированных модулей С++ и повышенным вниманием к производительности. Так, С++ не проверяет границы массивов на этапе выполнения программы и не существует сборщика мусора, восстанавливающего неиспользуемую, динамически выделенную память. Для краткости не будут рассматриваться те конструкции С++, которые почти идентичны соответствующим конструкциям Java и C#. Кроме того, здесь не раскрываются некоторые темы С++, потому что их изучение необязательно при программировании с применением Qt. К ним относятся шаблонные классы и функции, определение объединений и использование исключений. Полное описание языка можно найти в таких книгах, как «The С++ Programming Language» (Язык программирования С++) , написанной Бьерном Страуструпом, или «С++ for Java Programmers» (С++ для программистов Java), написанной Марком Аленом Уайссом (Mark Allen Weiss). Элементарные типы данныхПредлагаемые в С++ элементарные типы данных аналогичны тем, которые используются в Java или C#. На рис. Б.2 приводятся список элементарных типов С++ и их определение на платформах, поддерживаемых Qt 4: • bool — булево значение, • char — 8-битовый целый тип, • short — 16-битовый целый тип, • int — 32-битовый целый тип, • long — 32- или 64-битовый целый тип, • long long[9] — 64-битовый целый тип, • float — 32-битовое значение числа с плавающей точкой (IEEE 754), • double — 64 битовое значение числа с плавающей точкой (IEEE 754). По умолчанию short, int, long и long long — типы данных со знаком, т.е. они могут содержать как отрицательные, так и положительные значения. Если необходимо хранить только неотрицательные целые числа, мы можем поставить ключевое слово unsigned (без знака) перед типом. Если тип short может хранить любое значение в промежутке между —32,768 и +32,767, то unsigned short — от 0 до 65 535. Оператор сдвига вправо >> имеет семантику чисел без знака («заполнить нулями»), если один из операндов является типом без знака. Тип bool может принимать значения true и false. Кроме того, числовые типы могут использоваться вместо типа bool; в этом случае 0 соответствует значению false, а любое ненулевое значение означает true. Тип char используется для хранения как символов ASCII, так и 8-битовых целых чисел (байтов). Целое число, представленное этим типом, в зависимости от платформы может иметь или не иметь знак. Типы signed char и unsigned char могут использоваться для однозначной интерпретации типа char. Qt предоставляет тип QChar, который хранит 16-битовые символы в кодировке Unicode. По умолчанию экземпляры встроенных типов не инициализируются. Когда создается переменная типа int, ее значение вполне могло бы быть нулевым, однако с той же вероятностью оно может равняться —209 486 515. К счастью, большинство компиляторов предупреждает нас о попытках чтения неинициализированной переменной, и мы можем использовать такие инструментальные средства, как Rational PurifyPlus и Valgrind, для обнаружения обращений к неинициализированной памяти и других связанных с памятью проблем на этапе выполнения. В памяти числовые типы (кроме long) имеют идентичные размеры на различных платформах, поддерживаемых Qt, но их представление меняется в зависимости от принятого в системе порядка байтов. В архитектурах с прямым порядком байтов (например, PowerPC и SPARC) 32-битовое значение 0x12345678 последовательно занимают четыре байта 0х12 0x34 0x56 0х78, в то время как в архитектурах с обратным порядком байтов (например, Intel x86) последовательность байтов будет обратной. Это следует учитывать в программах, копирующих области памяти на диск или посылающих двоичные данные по сети. Класс Qt QDataStream, представленный в главе 12 («Ввод—вывод»), можно использовать для хранения двоичных данных независимым от платформы способом. Определения классаКлассы определяются в С++ аналогично тому, как это делается в Java и C#, однако надо иметь в виду, что существует несколько отличий. Мы рассмотрим эти отличия на нескольких примерах. Начнем с класса, представляющего пару координат (x, у): 01 #ifndef POINT2D_H 02 #define POINT2D_H 03 class Point2D 04 { 05 public: 06 Point2D() { 07 xVal = 0; 08 yVal = 0; 09 } 10 Point2D(double x, double у) { 11 xVal = x; 12 yVal = у; 13 } 14 void setX(double x) { xVal = x; } 15 void setY(double у) { yVal = у; } 16 double x() const { return xVal; } 17 double y() const { return yVal; } 18 private: 19 double xVal; 20 double yVal; 21 }; 22 #endif Представленное выше определение класса обычно оформляется в виде заголовочного файла, типичным названием которого может быть point2d.h. В этом примере проявляются следующие характерные особенности С++: • Определение класса разделяется на секции (открытую, защищенную и закрытую) и заканчивается точкой с запятой. Если не указано ни одной секции, по умолчанию используется закрытая секция. (Для совместимости с языком С в С++ предусмотрено ключевое слово struct, идентичное классу с тем исключением, что по умолчанию используется открытая секция). • Данный класс имеет два конструктора (один без параметров и другой с двумя параметрами). Если в классе вообще не объявляется конструктор, С++ автоматически добавляет конструктор без параметров и с пустым телом. • Функции, получающие данные, x() и y(), объявляются как константные. Это значит, что они не будут (и не смогут) модифицировать переменные—члены или вызывать неконстантные функции—члены (например, setX() и setY().) Указанные выше функции реализовывались бы как встроенные функции, являющиеся частью определения класса. Альтернативный подход заключается в предоставлении в заголовочном файле только прототипов функций и реализации функций в файле .cpp. В этом случае заголовочный файл имел бы следующий вид: 01 #ifndef POINT2D_H 02 #define POINT2D_H 03 class Point2D 04 { 05 public: 06 Point2D(); 07 Point2D(double x, double у); 08 void setX(double x); 09 void setY(double у); 10 double x() const; 11 double y() const; 12 private: 13 double xVal; 14 double yVal; 15 }; 16 #endif Реализация функций выполнялась бы в файле point2d.cpp: 01 #include "point2d.h" 02 Point2D::Point2D() 03 { 04 xVal = 0.0; 05 yVal = 0.0; 06 } 07 Point2D::Point2D(double x, double у) 08 { 09 xVal = x; 10 yVal = у; 11 } 12 void Point2D::setX(double x) 13 { 14 xVal = x; 15 } 16 void Point2D::setY(double у) 17 { 18 yVal = у; 19 } 20 double Point2D::x() const 21 { 22 return xVal; 23 } 24 double Point2D::y() const 25 { 26 return yVal; 27 } Этот файл начинается с включения заголовочного файла point2d.h, потому что прежде чем компилятор будет выполнять синтаксический анализ реализаций функций—членов, он должен иметь определение класса. Затем идут реализации функций, перед именем которых через оператор :: указывается имя класса. Мы узнали, как можно реализовать встроенную функцию и как можно реализовать ее в файле .cpp. Семантически эти два подхода эквивалентны, однако при вызове встроенной функции большинство компиляторов просто разворачивают тело функции вместо формирования реального вызова функции. Обычно это ведет к получению более быстрого кода, но может увеличить размер приложения. По этой причине только очень короткие функции следует делать встроенными; длинные функции всегда следует реализовывать в файле .cpp. Кроме того, если мы забудем реализовать какую-нибудь функцию и попытаемся ее вызвать, компоновщик «пожалуется» на существование неразрешенного символа. Теперь попытаемся использовать этот класс. 01 #include "point2d.h" 02 int main() 03 { 04 Point2D alpha; 05 Point2D beta(0.666, 0.875); 06 alpha.setX(beta.y()); 07 beta.setY(alpha.x()); 08 return 0; 09 } В С++ переменные любого типа можно объявлять без непосредственного использования оператора new. Первая переменная инициализируется с помощью стандартного конструктора Point2D (т.е. конструктора без параметров). Вторая переменная инициализируется с использованием второго конструктора. Обращение к члену объекта осуществляется с использованием оператора . (точка). Объявленные таким образом переменные ведут себя как элементарные типы Java и C# (такие, как int и double). Например, при использовании оператора присваивания копируется содержимое переменной, а не ссылка на объект. И если позже переменная будет модифицирована, значение всех других переменных, к которым присваивалась первая переменная, не изменится. С++, как объектно—ориентированный язык, поддерживает наследование и полиморфизм. Для иллюстрации этих свойств мы рассмотрим пример абстрактного класса Shape (фигура) и подкласса Circle (окружность). Начнем с базового класса: 01 #ifndef SHAPE_H 02 #define SHAPE_H 03 #include "point2d.h" 04 class Shape 05 { 06 public: 07 Shape(Point2D center) { myCenter = center; } 08 virtual void draw() = 0; 09 protected: 10 Point2D myCenter; 11 }; 12 #endif Определение класса создается в заголовочном файле с именем shape.h. Поскольку в этом определении делается ссылка на класс Point2D, мы включаем заголовочный файл point2d.h. Класс Shape не имеет базового класса. В отличие от Java и C#, в С++ не предусмотрен обобщенный класс Object, который наследуется всеми другими классами. Qt предоставляет QObject в качестве естественного базового класса для объектов всех типов. Объявление функции draw() имеет две интересные особенности. Она содержит ключевое слово virtual и завершается равенством = 0. Ключевое слово virtual означает, что данная функция может быть переопределена в подклассах. Подобно C# функции—члены в С++ по умолчанию не могут переопределяться. Странное приравнивание = 0 указывает на то, что данная функция — чисто виртуальная функция, которая не имеет реализации по умолчанию, и она должна быть реализована в подклассах. Концепция «интерфейса» в Java и C# соответствует в С++ классу, содержащему только чисто виртуальные функции. Ниже приводится определение подкласса Circle: 01 #ifndef CIRCLE_H 02 #define CIRCLE_H 03 #include "shape.h" 04 class Circle : public Shape 05 { 06 public: 07 Circle(Point2D center, double radius = 0.5) 08 : Shape(center) { 09 myRadius = radius; 10 } 11 void draw() { 12 // здесь выполняются какие-то действия 13 } 14 private: 15 double myRadius; 16 }; 17 #endif Класс Circle наследует класс Shape в открытой форме, т.е. все открытые члены класса Shape остаются открытыми в Circle. С++ поддерживает также защищенное и закрытое наследование, которое ограничивает доступ к открытым и защищенным членам базового класса. Конструктор принимает два параметра. Второй параметр необязателен, по умолчанию он принимает значение 0.5. Конструктор передает параметр center конструктору базового класса, для чего используется специальный синтаксис списка инициализации между сигнатурой функции и телом функции. В теле функции мы инициализируем переменную—член myRadius. Инициализацию этой переменной можно было сделать в той же строке, где инициализируется конструктор базового класса: Circle(Point2D center, double radius = 0.5) : Shape(center), myRadius(radius) { } С другой стороны, С++ не позволяет инициализировать переменную—член в определении класса, поэтому следующий программный код неверен: // НЕ БУДЕТ КОМПИЛИРОВАТЬСЯ private: double myRadius = 0.5; }; Сигнатура функции draw() совпадает с сигнатурой виртуальной функции draw(), определенной в классе Shape. Она здесь переопределяется и будет вызываться полиморфно, когда draw() вызывается экземпляром Circle через ссылку или указатель на Shape. С++ не имеет ключевого слова override, доступного в C#. С++ также не имеет ключевых слов super и base, ссылающихся на базовый класс. Если требуется вызвать базовую реализацию функции, можно перед именем функции указать имя базового класса и оператор ::. Например: 01 class LabeledCircle : public Circle 02 { 03 public: 04 void draw() { 05 Circle::draw(); 06 drawLabel(); 07 } 08 }; С++ поддерживает множественное наследование, т.е. возможность создавать класс, производный сразу от нескольких других классов. При этом используется следующий синтаксис: class DerivedClass : public BaseClass1, public BaseClass2, …, public BaseClassN { … }; По умолчанию функции и переменные, объявленные в классе, связываются с экземплярами этого класса. Мы можем объявлять статические функции—члены и статические переменные—члены, которые могут использоваться без экземпляра. Например: 01 #ifndef TRUCK_H 02 #define TRUCK_H 03 class Truck 04 { 05 public: 06 Truck() { ++counter; } 07 ~Truck() { --counter; } 08 static int instanceCount() { return counter; } 09 private: 10 static int counter; 11 }; 12 #endif Статическая переменная—член счетчика counter отслеживает количество экземпляров truck, которые существуют в любой момент времени. Конструктор truck его увеличивает на единицу. Деструктор, опознаваемый по префиксу ~, уменьшает счетчик на единицу. В С++ деструктор автоматически вызывается, когда статически распределенная переменная выходит из области видимости или когда удаляется переменная, память для которой выделяется при помощи оператора new. Это аналогично тому, что делается в методе finalize() в Java, за исключением того, что мы можем рассчитывать на его вызов в определенный момент времени. Статическая переменная—член существует в единственном экземпляре для класса — такие переменные являются «переменными класса», а не «переменными экземпляра». Каждая статическая переменная—член должна определяться в файле .cpp (но без повторения ключевого слова static). Например: #include "truck.h" int Truck::counter = 0; Если этого не сделать, компоновщик выдаст сообщение об ошибке из-за наличия «неразрешенного символа». Обращаться к статической функции instanceCount() можно за пределами класса, указывая имя класса перед ее именем. Например: 01 #include <iostream> 02 #include "truck.h" 03 using namespace std; 04 int main() 05 { 06 Truck truck1; 07 Truck truck2; 08 cout << Truck::instanceCount() << " equals 2" << endl; 09 return 0; 10 } УказателиУказатель в С++ — это переменная, содержащая не сам объект, а адрес памяти, где располагается объект. Java и C# имеют аналогичную концепцию «ссылки» при другом синтаксисе. Мы начнем с рассмотрения придуманного нами примера, иллюстрирующего применение указателей: 01 #include "point2d.h" 02 int main() 03 { 04 Point2D alpha; 05 Point2D beta; 06 Point2D *ptr; 07 ptr = α 08 ptr->setX(1.0); 09 ptr->setY(2.5); 10 ptr = β 11 ptr->setX(4.0); 12 ptr->setY(4.5); 13 ptr = 0; 14 return 0; 15 } В этом примере используется класс Point2D из предыдущего подраздела. В строках 4 и 5 определяется два объекта типа Point2D. Эти объекты инициализируются в значение (0, 0) стандартным конструктором Point2D. В строке 6 определяется указатель на объект Point2D. Для обозначения указателя здесь используется звездочка перед именем переменной. Поскольку мы не инициализируем указатель, он будет содержать произвольный адрес памяти. Эта ситуация изменяется в строке 7, в которой адрес alpha присваивается этому указателю. Унарный оператор & возвращает адрес памяти, где располагается объект. Адрес обычно представляет собой 32-битовое или 64-битовое целое число, задающее смещение объекта в памяти. В строках 8 и 9 мы обращаемся к объекту alpha с помощью указателя ptr. Поскольку ptr является указателем, а не объектом, необходимо использовать оператор -> (стрелка) вместо оператора . (точка). В строке 10 указателю присваивается адрес beta. С этого момента любая выполняемая нами операция с этим указателем будет воздействовать на объект beta. В строке 13 указатель устанавливается в нулевое значение. С++ не имеет ключевого слова для представления указателя, который не ссылается ни на один объект; вместо этого мы используем значение 0 (или символическую константу NULL, которая разворачивается в 0). Попытка применения нулевого указателя приведет к краху приложения с выводом такого сообщения об ошибке, как «Segmentation fault» (ошибка сегментации), «General protection fault» (общая ошибка защиты) или «Bus error» (ошибка шины). Применяя отладчик, можно найти строку программного кода, которая приводит к краху. В конце функции объект alpha содержит пару координат (1.0, 2.5), а объект beta — (4.0,4.5). Указатели часто используются для хранения объектов, память для которых выделяется динамически с помощью оператора new. Используя жаргон С++ можно сказать, что эти объекты распределяются в «куче», в то время как локальные переменные (т.е. переменные, определенные внутри функции) хранятся в «стеке». Ниже приводится фрагмент программного кода, иллюстрирующий динамическое распределение памяти при помощи оператора new: 01 #include "point2d.h" 02 int main() 03 { 04 Point2D *point = new Point2D; 05 point->setX(1.0); 06 point->setY(2.5); 07 delete point; 08 return 0; 09 } Оператор new возвращает адрес памяти для нового распределенного объекта. Мы сохраняем адрес в переменной указателя и обращаемся к объекту через этот указатель. Поработав с объектом, мы возвращаем занимаемую им память, используя оператор delete. В отличие от Java и C#, сборщик мусора отсутствует в С++; динамически распределяемые объекты должны явно освобождать занимаемую ими память при помощи оператора delete, когда они становятся больше ненужными. В главе 2 описывается механизм родственных связей Qt, который значительно упрощает управление памятью в программах, написанных на С++. Если не вызвать оператор delete, память остается занятой до тех пор, пока не завершится программа. Это не создаст никаких проблем в приведенном выше примере, потому что память выделяется только для одного объекта, однако в программе, в которой постоянно создаются новые объекты, это может привести к нехватке машинной памяти. После удаления объекта переменная указателя по-прежнему будет хранить адрес объекта. Такой указатель является «повисшим указателем» и не должен использоваться для обращения к объекту. Qt предоставляет «умный» указатель QPointer<T>, который автоматически устанавливает себя в 0, если удаляется объект QObject, на который он ссылается. В приведенном выше примере мы вызывали стандартный конструктор и функции setX() и setY() для инициализации объекта. Вместо этого можно было использовать конструктор с двумя параметрами: Point2D *point = new Point2D(1.0, 2.5); Кроме того, мы могли бы распределить объект в стеке следующим образом: Point2D point; point.setX(1.0); point.setY(2.5); Распределенные таким образом объекты автоматически освобождаются в конце блока, в котором они появляются. Если мы не собираемся модифицировать объект при помощи указателя, можно объявить указатель как константный. Например: const Point2D *ptr = new Point2D(1.0, 2.5); double x = ptr->x(); double у = ptr->y(); // НЕ БУДЕТ КОМПИЛИРОВАТЬСЯ ptr->setX(4.0); *ptr = Point2D(4.0, 4.5); Константный указатель ptr можно использовать лишь для вызова константных функций-членов, например x() и y(). Признаком хорошего стиля является объявление указателей константными, когда нет намерения модификации объекта с их помощью. Более того, если сам объект является константным, ничего не остается, кроме использования константного указателя для хранения его адреса. Применение ключевого слова const предоставляет компилятору информацию, позволяющую обнаруживать ошибки на ранних этапах и повысить производительность. C# имеет ключевое слово const с очень похожими свойствами. Ближайшим эквивалентом в Java является ключевое слово final, однако оно лишь защищает переменные от операций присваивания, но не от вызова «неконстантных» функций—членов объекта. Указатели могут использоваться со встроенными типами так же, как с классами. Используемый в выражении унарный оператор * возвращает значение объекта, на который ссылается указатель. Например: int i = 10; int j = 20; int *p = &i; int *q = &j; cout << *p << " equals 10" << endl; cout << *q << " equals 20" << endl; *p = 40; cout << i << " equals 40" << endl; p = q; *p = 100; cout << i << " equals 40" << endl; cout << j << " equals 100" << endl; Оператор ->, который можно использовать для обращения к членам объекта через указатель, является чисто синтаксическим приемом. Вместо ptr->member можно также написать (*ptr).member. Скобки обязательны, потому что оператор . (точка) имеет более высокий приоритет, чем унарный оператор *. Указатели имели плохую репутацию в С и С++, причем доходило до того, что рекламировалось отсутствие указателей в языке Java. На самом деле указатели С++ концептуально аналогичны ссылкам в Java и C#, за исключением того, что указатели можно использовать для прохода по памяти, как мы это увидим позже в данном разделе. Более того, включение в Qt классов—контейнеров, использующих метод «копирования при записи» вместе со способностью С++ инстанцировать любой класс в стеке, означает возможность во многих случаях обойтись без указателей. СсылкиКроме указателей С++ поддерживает также концепцию «ссылки». Подобно указателю, ссылка в С++ хранит адрес объекта. Основными отличиями являются следующие: • Объявляются ссылки с применением оператора & вместо *. • Ссылка должна быть инициализирована и не может в дальнейшем изменяться. • С помощью ссылки обеспечивается прямое обращение к объекту; не предусмотрен специальный синтаксис, подобный операторам * или ->. • Ссылка не может быть нулевой. Ссылки в основном используются при объявлении параметров. По умолчанию в С++ используется передача параметров по значению, т.е. при передаче параметров функции последняя получает в действительности новую копию объекта. Ниже приводится определение функции, которая получает параметры, передаваемые по значению. #include <cstdlib> using namespace std; double manhattanDistance(Point2D a, Point2D b) { return abs(b.x() - a.x()) + abs(b.y() - a.y()); } Эта функция может вызываться следующим образом: Point2D harlem(77.5, 50.0); Point2D broadway(12.5, 40.0); double distance = manhattanDistance(broadway, harlem); Опытные С—программисты избегают операций копирования путем объявления параметров в виде указателей вместо значений: double manhattanDistance(const Point2D *ap, const Point2D *bp) { return abs(bp->x() - ap->x()) + abs(bp->y() - ap->y()); } После этого при вызове функции должны передаваться адреса вместо значений: Point2D harlem(77.5, 50.0); Point2D broadway(12.5, 40.0); double distance = manhattanDistance(&broadway, &harlem); Ссылки введены в С++ для того, чтобы сделать синтаксис менее громоздким и чтобы предотвратить передачу нулевого указателя. Если вместо указателей использовать ссылки, функция будет иметь следующий вид: double manhattanDistance(const Point2D &a, const Point2D &b) { return abs(b.x() - a.x()) + abs(b.y() - a.y()); } Ссылка объявляется аналогично указателю с использованием & вместо *. Однако при использовании ссылки можно забыть о том, что она является каким-то адресом памяти, и рассматривать ее как обычную переменную. Кроме того, вызов функции, принимающей ссылки в качестве аргументов, не требует специальной записи аргументов (не требуется задавать оператор &). В конце концов, заменяя в списке параметров Point2D на const Point2D &, мы уменьшаем накладные расходы на вызов функции — вместо копирования 256 битов (размер четырех типов double) копируются только 64 или 128 бит, что зависит от размера указателя, принятого в целевой платформе. В предыдущем примере использовались константные ссылки, не позволяющие модифицировать в функции объекты, обращение к которым осуществляется с помощью ссылок. Когда желателен этот побочный эффект, можно передавать неконстантную ссылку или указатель. Например: void transpose(Point2D &point) { double oldX = point.x(); point.setX(point.y()); point.setY(oldX); } В некоторых случаях имеется ссылка и требуется вызвать функцию, которая принимает указатель и наоборот. Для преобразования ссылки в указатель можно просто использовать унарный оператор &: Point2D point; Point2D &ref = point; Point2D *ptr = &ref; Для преобразования указателя в ссылку используется унарный оператор *: Point2D point; Point2D *ptr = &point; Point2D &ref = *ptr; Ссылки и указатели представляются в памяти одинаково и часто могут использоваться вместо друг друга, из-за чего возникает естественный вопрос о том, в каких случаях что из них следует предпочесть. С одной стороны, ссылки имеют более удобный синтаксис, с другой стороны — указатели в любой момент можно вновь устанавливать на указатель другого объекта, они могут содержать нулевое значение и более явный синтаксис их применения часто является неприятностью, неожиданно оказавшейся благом. По этим причинам предпочтение часто отдается указателям, а ссылки почти исключительно используются при объявлении параметров функций совместно с ключевым словом const. МассивыМассивы в С++ объявляются с указанием количества элементов массива в квадратных скобках после имени переменной массива. Допускаются двумерные массивы, т.е. массив массивов. Ниже приводится определение одномерного массива, содержащего 10 элементов типа int: int fibonacci[10]; Доступ к элементам осуществляется с помощью следующей записи: fibonacci[0], fibonacci[1], … fibonacci[9]. Часто требуется инициализировать массив при его определении: int fibonacci[10] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; В таких случаях можно не указывать размер массива, поскольку компилятор может его рассчитать по количеству элементов в списке инициализации: int fibonacci[] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; Статическая инициализация также работает для сложных типов, например для Point2D: Point2D triangle[] = { Point2D(0.0, 0.0), Point2D(1.0, 0.0), Point2D(0.5, 0.866) }; Если не предполагается в дальнейшем изменять массив, его можно сделать константным: const int fibonacci[] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; Для нахождения количества элементов в массиве можно использовать оператор sizeof(): int n = sizeof(fibonacci) / sizeof(fibonacci[0]); Оператор sizeof() возвращает размер аргумента в байтах. Количество элементов массива равно его размеру в байтах, поделенному на размер одного его элемента. Поскольку это долго вводить, распространенной альтернативой является объявление константы и ее использование при определении массива: enum { NFibonacci = 10 }; const int fibonacci[NFibonacci] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; Есть соблазн объявить константу как переменную типа const int. К сожалению, некоторые компиляторы имеют проблемы при использовании константных переменных для представления размера массива. Ключевое слово enum будет объяснено далее в этом приложении. Проход в цикле по массиву обычно выполняется с использованием переменной целого типа. Например: for (int i = 0; i < NFibonacci; ++i) cout << fibonacci[i] << endl; Массив можно также проходить с помощью указателя: const int *ptr = &fibonacci[0]; while (ptr != &fibonacci[10]) { cout << *ptr << endl; ++ptr; } Мы инициализируем указатель адресом первого элемента и проходим его в цикле, пока не достигнем элемента «после последнего элемента» («одиннадцатого» элемента, fibonacci[10]). На каждом шаге цикла оператор ++ продвигает указатель к следующему элементу. Вместо &fibonacci[0] можно было бы также написать fibonacci. Это объясняется тем, что указанное без элементов имя массива автоматически преобразуется в указатель на первый элемент массива. Аналогично можно было бы подставить fibonacci + 10 вместо &fibonacci[10]. Эти приемы работают и в других местах: мы можем получить содержимое текущего элемента, используя запись *ptr или ptr[0], а получить доступ к следующему элементу могли бы, используя *(ptr + 1) или ptr[1]. Это свойство иногда называют «эквивалентностью указателей и массивов». Чтобы не допустить того, что считается необоснованной неэффективностью, С++ не позволяет передавать массивы функциям по значению. Вместо этого передается адрес массива. Например: 01 #include <iostream> 02 using namespace std; 03 void printIntegerTable(const int *table, int size) 04 { 05 for (int i = 0; i < size; ++i) 06 cout << table[i] << endl; 07 } 08 int main() 09 { 10 const int fibonacci[10] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; 11 printIntegerTable(fibonacci, 10); 12 return 0; 13 } Ирония в том, что, хотя С++ не позволяет выбирать между передачей массива по ссылке и передачей по значению, он предоставляет некоторую свободу синтаксиса при объявлении типа параметра. Вместо const int *table можно было бы также написать const int table[] для объявления в качестве параметра указателя на константный тип int. Аналогично параметр argv функции main() можно объявлять как char *argv[] или как char **argv. Для копирования одного массива в другой можно пройти в цикле по элементам массива: const int fibonacci[NFibonacci] = { 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 }; int temp[NFibonacci]; for (int i = 0; i < NFibonacci; ++i) temp[i] = fibonacci[i]; Для базовых типов, таких как int, можно также использовать функцию std::memcpy(), которая копирует блок памяти. Например: memcpy(temp, fibonacci, sizeof(fibonacci)); При объявлении массива С++ его размер должен быть константой[10]. Если необходимо создать массив переменного размера, это можно сделать несколькими способами: • Выделять память под массив можно динамически: int *fibonacci = new int[n]; Оператор new [] выделяет последовательные участки памяти под определенное количество элементов и возвращает указатель на первый элемент. Благодаря принципу «эквивалентности указателей и массивов» обращаться к элементам можно с помощью указателей: fibonacci[0], fibonacci[1], … fibonacci[n — 1]. После завершения работы с массивом необходимо освободить занимаемую им память, используя оператор delete []: delete [] fibonacci; • Можно использовать стандартный класс std::vector<T>: #include <vector> using namespace std; vector<int> fibonacci(n); Обращаться к элементам можно с помощью оператора [], как это делается для обычного массива С++. При использовании вектора std::vector<T> (где T — тип элемента, хранимого в векторе) можно изменить его размер в любой момент с помощью функции resize(), и его можно копировать, применяя оператор присваивания. Классы, содержащие угловые скобки в имени, называются шаблонными классами. • Можно использовать класс Qt QVector<T>: #include <QVector> QVector<int> fibonacci(n); Программный интерфейс вектора QVector<T> очень похож на интерфейс вектора std::vector<T>, кроме того, он поддерживает возможность прохода по его элементам с помощью ключевого слова Qt foreach и использует неявное совмещение данных («копирование при записи») как метод оптимизации расхода памяти и повышения быстродействия. В главе 11 представлены классы—контейнеры Qt и объясняется их связь со стандартными контейнерами С++. Может возникнуть соблазн применения везде векторов std::vector<T> или QVector<T> вместо встроенных массивов. Тем не менее полезно иметь представление о работе встроенных массивов, потому что рано или поздно вам может потребоваться очень быстрый программный код или придется использовать существующие библиотеки С. Символьные строкиОсновной способ представления символьных строк в С++ заключается в применении массива символов char, завершаемого нулевым байтом ('\0'). Следующие четыре функции демонстрируют работу таких строк: 01 void hello1() 02 { 03 const char str[] = { 04 'H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r' 'l', 'd', '\0' 05 }; 06 cout << str << endl; 07 } 08 void hello2() 09 { 10 const char str[] = "Hello world!"; 11 cout << str << endl; 12 } 13 void hello3() 14 { 15 cout << "Hello world!" << endl; 16 } 17 void hello4() 18 { 19 const char *str = "Hello world!"; 20 cout << str << endl; 21 } В первой функции строка объявляется как массив и инициализируется посимвольно. Обратите внимание на символ в конце '\0', обозначающий конец строки. Вторая функция имеет аналогичное определение массива, но на этот раз для инициализации массива используется строковый литерал. В С++ строковые литералы — это просто массивы символов const char, завершающиеся символом '\0', который не указывается в литерале. В третьей функции строковый литерал используется непосредственно без придания ему имени. После перевода на инструкции машинного языка она будет идентична первым двум функциям. Четвертая функция немного отличается, поскольку создает не только массив (без имени), но и переменную—указатель с именем str, в которой хранится адрес первого элемента массива. Несмотря на это, семантика данной функции идентична семантике предыдущих трех функций, и оптимизирующий компилятор удалит лишнюю переменную str. Функции, принимающие в качестве аргументов строки С++, обычно объявляют их как char * или const char *. Ниже приводится короткая программа, иллюстрирующая оба подхода: 01 #include <cctype> 02 #include <iostream> 03 using namespace std; 04 void makeUppercase(char *str) 05 { 06 for (int i = 0; str[i] != '\0'; ++i) 07 str[i] = toupper(str[i]); 08 } 09 void writeLine(const char *str) 10 { 11 cout << str << endl; 12 } 13 int main(int argc, char *argv[]) 14 { 15 for (int i = 1; i < argc; ++i) { 16 makeUppercase(argv[i]); 17 writeLine(argv[i]); 18 } 19 return 0; 20 } В С++ тип char обычно занимает 8 бит. Это значит, что в массиве символов char легко можно хранить строки в кодировке ASCII, ISO 8859-1 (Latin-1) и в других 8-битовых кодировках, но нельзя хранить произвольные символы Unicode, если не прибегать к многобайтовым последовательностям. Qt предоставляет мощный класс QString, который хранит строки Unicode в виде последовательностей 16-битовых символов QChar и при их реализации использует оптимизацию неявного совмещения данных («копирование при записи»). Более подробно строки QString рассматриваются в главе 11 («Классы—контейнеры») и в главе 17 («Интернационализация»). ПеречисленияС++ позволяет с помощью перечисления объявлять набор поименованных констант аналогично тому, как это делается в C#. Предположим, что в программе требуется хранить названия дней недели: enum DayOfWeek { Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday }; Обычно это объявление располагается в заголовочном файле или даже внутри класса. Приведенное выше объявление на первый взгляд представляется эквивалентным следующим определениям констант: const int Sunday = 0; const int Monday = 1; const int Tuesday = 2; const int Wednesday = 3; const int Thursday = 4; const int Friday = 5; const int Saturday = 6; Применяя конструкцию перечисления, мы можем затем объявлять переменные или параметры типа DayOfWeek, и компилятор гарантирует возможность присваивания им только значений перечисления DayOfWeek. Например: DayOfWeek day = Sunday; Если нас мало волнует обеспечение защищенности типов, мы можем просто написать int day = Sunday; Обратите внимание на то, что при ссылке на константу Sunday из перечисления DayOfWeek мы пишем просто Sunday, а не DayOfWeek::Sunday. По умолчанию компилятор назначает последовательные целочисленные значения константам перечисления, начиная с нуля. При необходимости можно назначить другие значения: enum DayOfWeek { Sunday = 628, Monday = 616, Tuesday = 735, Wednesday = 932, Thursday = 852, Friday = 607, Saturday = 845 }; Если значение не задается для элемента перечисления, этот элемент примет значение предыдущего элемента, увеличенное на 1. Перечисления иногда используются для объявления целочисленных констант, и в этих случаях перечислению обычно имя не задают: enum { FirstPort = 1024, MaxPorts = 32767 }; Другой областью применения перечислений является представление набора опций. Рассмотрим пример диалогового окна Find (поиск) с четырьмя переключателями, которые управляют алгоритмом поиска (применение шаблона поиска, учет регистра, поиск в обратном направлении и повторение поиска с начала документа). Это можно представить в виде перечисления, значения констант которого равны некоторой степени 2: enum FindOption { NoOptions = 0x00000000, WildcardSyntax = 0x00000001, CaseSensitive = 0x00000002, SearchBackward = 0x00000004, WrapAround = 0x00000008 }; Каждая опция часто называется «флажком». Флажки можно объединять при помощи логических поразрядных операторов | или |=: int options = NoOptions; if (wilcardSyntaxCheckBox->isChecked()) options |= WildcardSyntax; if (caseSensitiveCheckBox->isChecked()) options |= CaseSensitive; if (searchBackwardCheckBox->isChecked()) options |= SearchBackwardSyntax; if (wrapAroundCheckBox->isChecked()) options |= WrapAround; Проверить значение флажка можно при помощи логического поразрядного оператора &: if (options & CaseSensitive) { // поиск с учетом регистра } Переменная типа FindOption может содержать только один флажок в данный момент времени. Результат объединения нескольких флажков при помощи оператора | представляет собой обычное целое число. К сожалению, здесь не обеспечивается защищенность типа: компилятор не будет «жаловаться», если функция, которая должна принимать в качестве параметра типа int некую комбинацию опций FindOption, фактически получит Saturday. Qt использует класс QFlags<T> для обеспечения защищенности своих собственных типов флажков. Этот класс можно также применять при определении пользовательских типов флажков. Подробное описание класса QFlags<T> можно найти в онлайновой документации. Имена, вводимые typedefС++ позволяет с помощью ключевого слова typedef назначать псевдонимы типам данных. Например, если часто используется тип QVector<Point2D> и хотелось бы сэкономить немного на вводе символов (или, к несчастью, приходится иметь дело с норвежской клавиатурой и вам трудно найти на ней угловые скобки), то можно в одном из ваших заголовочных файлов использовать такое объявление typedef: typedef QVector<Point2D> PointVector; После этого можно использовать имя PointVector как сокращение для QVector<Point2D>. Следует отметить, что новое имя указывается после старого. Синтаксис typedef специально имитирует синтаксис объявлений переменных. В Qt имена, вводимые typedef, в основном используются по трем причинам: • Удобство: Qt объявляет с помощью typedef имена uint и QWidgetList для unsigned int и QList<QWidget *>, чтобы сэкономить несколько символов. • Различие платформ: определенные типы должны определяться по-разному на различных платформах. Например, qlonglong определяется как __int64 в Windows и как long long на других платформах. • Совместимость: класс QIconSet из Qt 3 был переименован в QIcon для Qt 4. Для облегчения пользователям Qt 3 перевода своих приложений в Qt 4 класс QIconSet объявляется как typedef QIcon, когда включается режим совместимости с Qt 3. Преобразование типовС++ представляет несколько синтаксических конструкций по приведению одного типа к другому. Заключение нужного типа результата в скобки и размещение его перед преобразуемым значением — это традиционный способ, унаследованный от С: const double Pi = 3.14159265359; int x = (int) (Pi * 100); cout << x << " equals 314" << endl; Это очень мощная конструкция. Она может использоваться для изменения типа указателя, устранения константности и для многого другого. Например: short j = 0x1234; if (*(char *) &j == 0x12) cout << "The byte order is big-endian" << endl; В этом примере мы приводим тип short * к типу char * и используем унарный оператор * для обращения к байту по заданному адресу памяти. В системах с прямым порядком байтов этот байт содержит значение 0x12; в системах с обратным порядком байтов он имеет значение 0x34. Поскольку указатели и ссылки представляются одинаково, не удивительно, что представленный выше программный код можно переписать с приведением типа ссылки: short j = 0x1234; if ((char &) j == 0x12) cout << "The byte order is big-endian" << endl; Если тип данных является именем класса, именем, введенным typedef, или элементарным типом, который может быть представлен одной буквенно—цифровой лексемой, для приведения типа можно использовать синтаксис конструктора: int x = int(Pi * 100); Приведение типа указателей и ссылок с использованием традиционного подхода в стиле языка С является неким экстремальным видом спорта, напоминающим параглайдинг и передвижение на кабине лифта, потому что компилятор позволяет приводить указатель (или ссылку) любого типа в любой другой тип указателя (или ссылки). По этой причине в С++ введены новые конструкции приведения типов с более точной семантикой. Для указателей и ссылок новые конструкции приведения типов более предпочтительны по сравнению с рискованными конструкциями в стиле С, и они используются в данной книге. • static_cast<T>() может применяться для приведения типа указателя на А к типу указателя на В при том ограничении, что класс В должен быть наследником класса А. Например: A *obj = new В; В *b = static_cast<B *>(obj); b->someFunctionDeclaredInB(); Если объект не является экземпляром В (но все же наследует А), применение полученного указателя может привести к неожиданному краху программы. • dynamic_cast<T>() действует аналогично static_cast<T>(), кроме применения информации о типах, получаемой на этапе выполнения (runtime type information — RTTI), для проверки принадлежности к классу В объекта, на который ссылается указатель. Если это не так, то оператор приведения типа возвратит нулевой указатель. Например: A *obj = new В; В *b = dynamic_cast<B *>(obj); if (b) b->someFunctionDeclaredInB(); В некоторых компиляторах оператор dynamic_cast<T>() не работает через границы динамических библиотек. Он также рассчитывает на поддержку компилятором технологии RTTI, а эта поддержка может быть отключена программистом для уменьшения размера своих исполняемых модулей. Qt решает эти проблемы, обеспечивая оператор приведения qobject_cast<T>() для подклассов QObject. • const_cast<T>() добавляет или удаляет спецификатор const из указателя или ссылки. Например: int MyClass::someConstFunction() const { if (isDirty()) { MyClass *that = const_cast<MyClass *>(this); that->recomputeInternalData(); } … } В предыдущем примере мы убрали спецификатор const при приведении типа указателя this для вызова неконстантной функции—члена recomputeInternalData(). Не рекомендуется так делать, и, если использовать ключевое слово mutable, этого можно избежать, как это делается в главе 4 («Реализация функциональности приложения»). • reinterpret_cast<T>() преобразует любой тип указателя или ссылки в любой другой их тип. Например: short j = 0x1234; if (reinterpret_cast<char &>(j) == 0x12) cout << "The byte order is big-endian" << endl; В Java и C# любая ссылка может храниться при необходимости как ссылка на Object. С++ не имеет никакого универсального базового класса, но предоставляет специальный тип данных void *, который содержит адрес экземпляра любого типа. Указатель void * необходимо привести к другому типу (используя static_cast<T>()) перед его использованием. С++ обеспечивает много способов приведения типов, однако в большинстве случаев это даже не приходится делать. При использовании таких классов—контейнеров, как std::vector<T> или QVector<T>, мы можем задать тип T и извлекать элементы без приведения типа. Кроме того, для элементарных типов некоторые преобразования происходят неявно (например, преобразование char в int), а для пользовательских типов можно определить неявные преобразования, предусматривая конструктор с одним параметром. Например: class MyInteger { public: MyInteger(); MyInteger(int i); … }; int main() { MyInteger n; n = 5; … } Автоматическое преобразование, обеспечиваемое некоторыми конструкторами с одним параметром, имеет мало смысла. Его можно отключить, если объявить конструктор с ключевым словом explicit: class MyVector { public: explicit MyVector(int size); … }; Перегрузка операторовС++ позволяет нам перегружать функции, т.е. мы можем объявлять несколько функций с одним именем в одной и той же области видимости, если они имеют различные списки параметров. Кроме того, С++ поддерживает перегрузку операторов, позволяя назначать специальную семантику встроенным операторам (таким, как +, << и [ ]) при их применении для пользовательских типов. Мы уже видели несколько примеров с перегруженными операторами. Когда использовался оператор << для вывода текста в поток cout или cerr, мы не пользовались оператором С++, выполняющим поразрядный сдвиг влево, но использовали специальную версию этого оператора, принимающего слева объект потока ostream (например, cout или cerr), а справа — строку (либо вместо строки число или манипулятор потока, например endl) и возвращающего объект ostream, что позволяет несколько раз вызывать оператор в одной строке. Красота перегрузки операторов заключается в возможности сделать поведение пользовательских типов в точности таким же, как поведение встроенных типов. Чтобы показать, как работает такая перегрузка, мы перегрузим операторы +=, —=, + и —, добавив возможность работы с объектами Point2D: 01 #ifndef POINT2D_H 02 #define POINT2D_H 03 class Point2D 04 { 05 public: 06 Point2D(); 07 Point2D(double x, double у); 08 void setX(double x); 09 void setY(double у); 10 double x() const; 11 double y() const; 12 Point2D &operator+=(const Point2D &other) 13 { 14 xVal += other.xVal; 15 yVal += other.yVal; 16 return *this; 17 } 18 Point2D &operator-=(const Point2D &other) 19 { 20 xVal -= other.xVal; 21 yVal -= other.yVal; 22 return *this; 23 } 24 private: 25 double xVal; 26 double yVal; 27 }; 28 inline Point2D operator+(const Point2D &a, const Point2D &b) 29 { 30 return Point2D(a.x() + b.x(), a.y() + b.y()); 31 } 32 inline Point2D operator-(const Point2D &a, const Point2D &b) 33 { 34 return Point2D(a.x() - b.x(), a.y() - b.y()); 35 } 36 #endif Операторы можно реализовать либо как функции—члены, либо как глобальные функции. В нашем примере мы реализовали операторы += и —= как функции—члены, а операторы + и — как глобальные функции. Операторы += и —= принимают ссылку на другой объект Point2D и увеличивают или уменьшают координаты x и у текущего объекта на значение координат другого объекта. Они возвращают *this, т.е. ссылку на текущий объект (this имеет тип Point2D *). Возвращение ссылки позволяет создавать экзотический программный код, например: a += b += с; Операторы + и — принимают два параметра и возвращают значение объекта Point2D (а не ссылку на существующий объект). Ключевое слово inline позволяет поместить эти функции в заголовочный файл. Если бы тело функции было более длинным, мы бы поместили в заголовочный файл прототип функции, а определение функции (без ключевого слова inline) в файл .cpp. Следующие фрагменты программного кода показывают, как можно использовать все четыре перегруженных оператора: Point2D beta(77.5, 50.0); Point2D alpha(12.5, 40.0); alpha += beta; beta -= alpha; Point2D gamma = alpha + beta; Point2D delta = beta - alpha; Кроме того, можно вызывать функции operator точно так же, как вызываются любые другие функции: Point2D beta(77.5, 50.0); Point2D alpha(12.5, 40.0); alpha.operator+=(beta); beta.operator-=(alpha); Point2D gamma = operator+(alpha, beta); Point2D delta = operator-(beta, alpha); Перегрузка операторов в С++ представляет собой сложную тему, однако мы вполне можем пока обходиться без знания всех деталей. Все же важно понимать принципы перегрузки операторов, потому что несколько классов Qt (в том числе QString и QVector<T>) используют их для обеспечения простого и более естественного синтаксиса для таких операций, как конкатенация и добавление в конец объекта. Типы значенийB Java и C# различаются типы значений и типы ссылок. • Типы значений. Это такие элементарные типы, как char, int и float, а также структуры struct в C#. Характерным для них является то, что для их создания не используется оператор new и оператор присваивания копирует значение переменной. Например: int i = 5; int j = 10; i = j; • Типы ссылок. Это такие классы, как Integer (в Java), String и MyVeryOwnClass. Их экземпляры создаются при помощи оператора new. Оператор присваивания копирует только ссылку на объект, а для действительного копирования объекта мы должны вызывать функцию clone() (в Java) или Clone() (в C#). Например: Integer i = new Integer(5); Integer j = new Integer(10); i = j.clone(); В С++ все типы могут использоваться как «типы ссылок», а в дополнение к этому те из них, которые допускают копирование, могут использоваться как «типы значений». Например, в С++ нет необходимости иметь класс, подобный Integer, потому что можно использовать указатели и оператор new: int *i = new int(5); int *j = new int(10); *i = *j; В отличие от Java и C#, в С++ определяемые пользователем типы используются так же, как встроенные типы: Point2D *i = new Point2D(5, 5); Point2D *j = new Point2D(10, 10); *i = *j; Если требуется сделать класс С++ копируемым, необходимо предусмотреть в этом классе конструктор копирования и оператор присваивания. Конструктор копирования вызывается при инициализации объекта другим объектом того же типа. Синтаксически в С++ это обеспечивается двумя способами: Point2D i(20, 20); Point2D j(i); // первый способ Point2D k = i; // второй способ Оператор присваивания вызывается при присваивании одной переменной другой переменной: Point2D i(5, 5); Point2D j(10, 10); j = i; При определении класса компилятор С++ автоматически обеспечивает конструктор копирования и оператор присваивания, выполняющие копирование члена в член. Для класса Point2D это равносильно тому, как если бы мы написали следующий программный код в определении класса: 01 class Point2D 02 { 03 public: 04 Point2D(const Point2D &other) 05 : xVal(other.xVal), yVal(other.yVal) { } 06 Point2D &operator=(const Point2D &other) 07 { 08 xVal = other.xVal; 09 yVal = other.yVal; 10 return *this; 11 } 12 … 13 private: 14 double xVal; 15 double yVal; 16 }; Для некоторых классов создаваемые по умолчанию конструктор копирования и оператор присваивания оказываются неподходящими. Обычно это происходит в тех случаях, когда класс использует динамическую память. Чтобы сделать класс копируемым, мы должны сами реализовать конструктор копирования и оператор присваивания. Для классов, которые не должны быть копируемыми, можно отключить конструктор копирования и оператор присваивания, если сделать их закрытыми. Если мы случайно попытаемся копировать экземпляры такого класса, компилятор выдаст сообщение об ошибке. Например: class BankAccount { public: … private: BankAccount(const BankAccount &other); BankAccount &operator=(const BankAccount &other); }; В Qt многие классы проектировались как используемые по значению. Они имеют конструктор копирования и оператор присваивания и обычно инстанцируются в стеке без использования оператора new. Это относится к классам QDateTime, QImage, QString и к классам—контейнерам, например QList<T>, QVector<T> и QMap<K, T>. Другие классы попадают в категорию «типа ссылок», в частности QObject и его подклассы (QWidget, QTimer, QTcpSocket и т.д.). Они имеют виртуальные функции и не могут копироваться. Например, QWidget представляет конкретное окно или элемент управления на экране дисплея. Если в памяти находится 75 экземпляров QWidget, на экране также будет находиться 75 окон или элементов управления. Обычно эти классы инстанцируются при помощи оператора new. Глобальные переменные и функцииС++ позволяет объявлять функции и переменные, которые не принадлежат никакому классу и к которым можно обращаться из любой другой функции. Мы видели несколько примеров глобальных функций, в частности main() — точка входа в программу. Глобальные переменные встречаются реже, потому что они плохо влияют на модульность и реентерабельность. Все же важно иметь представление о них, поскольку вам, возможно, придется с ними столкнуться в программном коде, написанном программистом, который раньше писал на С, и другими пользователями С++. Для иллюстрации работы глобальных функций и переменных рассмотрим небольшую программу, которая печатает список из 128 псевдослучайных чисел, используя придуманный на скорую руку алгоритм. Исходный код программы находится в двух файлах .cpp. Первый исходный файл — random.cpp: 01 int randomNumbers[128]; 02 static int seed = 42; 03 static int nextRandomNumber() 04 { 05 seed = 1009 + (seed * 2011); 06 return seed; 07 } 08 void populateRandomArray() 09 { 10 for (int i = 0; i < 128; ++i) 11 randomNumbers[i] = nextRandomNumber(); 12 } В этом файле объявляются две глобальные переменные (randomNumbers и seed) и две глобальные функции (nextRandomNumber() и populateRandomArray()). В двух объявлениях используется ключевое слово static; эти объявления видимы только внутри текущей единицы компиляции (random.cpp), и говорят, что они статически связаны (static linkage). Два других объявления доступны из любой единицы компиляции программы, они обеспечивают внешнюю связь (external linkage). Статическая компоновка идеально подходит для вспомогательных функций и внутренних переменных, которые не должны использоваться в других единицах компиляции. Она снижает риск «столкновения» идентификаторов (наличия глобальных переменных с одинаковым именем или глобальных функций с одинаковой сигнатурой в разных единицах компиляции) и не позволяет злонамеренным или другим опрометчивым пользователям получать доступ к внутренним объектам единицы компиляции. Теперь рассмотрим второй файл main.cpp, в котором используется две глобальные переменные, объявленные в random.cpp с обеспечением внешней связи: 01 #include <iostream> 02 using namespace std; 03 extern int randomNumbers[128]; 04 void populateRandomArray(); 05 int main() 06 { 07 populateRandomArray(); 08 for (int i = 0; i < 128; ++i) 09 cout << randomNumbers[i] << endl; 10 return 0; 11 } Мы объявляем внешние переменные и функции до их вызова. Объявление randomNumbers внешней переменной (что делает ее видимой в текущей единице компиляции) начинается с ключевого слова extern. Если бы не было этого ключевого слова, компилятор «посчитал» бы, что он имеет дело с определением переменной, и компоновщик «пожаловался» бы на определение одной и той же переменной в двух единицах компиляции (random.cpp и main.cpp). Переменные могут объявляться любое количество раз, однако они могут иметь только одно определение. Именно благодаря определению компилятор резервирует пространство для переменной. Функция populateRandomArray() объявляется с использованием прототипа. Указывать ключевое слово extern для функций необязательно. Обычно объявления внешних переменных и функций помещают в заголовочный файл и включают его во все файлы, где они требуются: 01 #ifndef RANDOM_H 02 #define RANDOM_H 03 extern int randomNumbers[128]; 04 void populateRandomArray(); 05 #endif Мы уже видели, как ключевое слово static может использоваться для объявления переменных—членов и функций—членов, которые не привязываются к конкретному экземпляру класса, и теперь мы увидели, как можно его использовать для объявления функций и переменных со статической связью. Существует еще одно применение ключевого слова static, о котором следует упомянуть. В С++ можно определить локальную переменную как статическую. Такие переменные инициализируются при первом вызове функции и сохраняют свои значения между вызовами функций. Например: 01 void nextPrime() 02 { 03 static int n = 1; 04 do { 05 ++n; 06 } while (!isPrime(n)); 07 return n; 08 } Статические локальные переменные подобны глобальным переменным, за исключением того, что они видимы только внутри функции, в которой они определены. Пространства именПространства имен позволяют снизить риск конфликта имен в программах С++. Конфликты имен часто возникают в больших программах, использующих несколько библиотек независимых разработчиков. В своей собственной программе вы решаете сами, использовать ли вам или нет пространства имен. Обычно в пространство имен заключаются все объявления заголовочного файла, чтобы гарантировать невозможность попадания идентификаторов, объявленных в этом заголовочном файле, в глобальное пространство имен. Например: 01 #ifndef SOFTWAREINC_RANDOM_H 02 #define SOFTWAREINC_RANDOM_H 03 namespace SoftwareInc 04 { 05 extern int randomNumbers[128]; 06 void populateRandomArray(); 07 } 08 #endif (Обратите внимание на то, что мы переименовали препроцессорные макросимволы, используемые для предотвращения многократного включения содержимого заголовочного файла, снижая риск конфликта имен с заголовочным файлом, имеющим такое же имя, но расположенным в другом каталоге.) Синтаксис пространства имен совпадает с синтаксисом класса, однако в конце не ставится точка с запятой. Ниже приводится новая версия файла random.cpp: 01 #include "random.h" 02 int SoftwareInc::randomNumbers[128]; 03 static int seed = 42; 04 static int nextRandomNumber() 05 { 06 seed = 1009 + (seed * 2011); 07 return seed; 08 } 09 void SoftwareInc::populateRandomArray() 10 { 11 for (int i = 0; i < 128; ++i) 12 randomNumbers[i] = nextRandomNumber(); 13 } В отличие от классов, пространства имен можно «повторно открывать» в любое время. Например: 01 namespace Alpha 02 { 03 void alpha1(); 04 void alpha2(); 05 } 06 namespace Beta 07 { 08 void beta1(); 09 } 10 namespace Alpha 11 { 12 void alpha3(); 13 } Это позволяет определять сотни классов, размещенных во многих заголовочных файлах и принадлежащих одному пространству имен. Используя этот прием, стандартная библиотека С++ помещает все свои идентификаторы в пространство имен std. В Qt пространства имен используются для таких подобных глобальным идентификаторов, как Qt::AlignBottom и Qt::yellow. По историческим причинам классы Qt не принадлежат никакому пространству имен, но имеют префикс 'Q'. Для ссылки на идентификатор, объявленный в другом пространстве имен, указывается префикс в виде имени этого пространства имен (и ::). Можно поступить по-другому — использовать один из следующих трех механизмов, нацеленных на уменьшение количества вводимых символов: • Можно определить псевдоним пространства имен: namespace ElPuebloDeLaReinaDeLosAngeles { void beverlyHills(); void culverCity(); void malibu(); void santaMonica(); } namespace LA = ElPuebloDeLaReinaDeLosAngeles; После определения псевдонима он может использоваться вместо исходного имени. • Из пространства имен можно импортировать один идентификатор: int main() { using ElPuebloDeLaReinaDeLosAngeles::beverlyHills; beverlyHills(); } Объявление using позволяет обращаться к данному идентификатору без указания префикса, состоящего из имени пространства имен. • Можно импортировать все пространство имен с помощью одной директивы: int main() { using namespace ElPuebloDeLaReinaDeLosAngeles; santaMonica(); malibu(); } При таком подходе конфликты имен становятся более вероятными. Если компилятор «жалуется» на двусмысленное имя (например, когда два класса имеют одинаковое имя, определенное в различных пространствах имен), всегда при ссылке на идентификатор его можно уточнить именем пространства имен. ПрепроцессорПрепроцессор С++ — это программа, которая обрабатывает исходный файл .cpp, содержащий директивы # (такие, как #include, #ifndef и #endif), и преобразует его файл исходного кода, который не содержит таких директив. Эти директивы предназначены для выполнения простых операций с текстом исходного файла, например для выполнения условной компиляции, включения файла и разворачивания макроса. Обычно препроцессор автоматически вызывается компилятором, однако в большинстве систем предусмотрена возможность непосредственного его вызова (часто для этого используется опция компилятора —E и /E). • Директива #include разворачивается в содержимое файла, имя которого указывается в угловых скобках (< >) или в двойных кавычках (" "), в зависимости от расположения заголовочного файла в стандартном каталоге или в каталоге текущего проекта. Имя файла может содержать .. и / (этот символ правильно интерпретируется компиляторами Windows как разделитель каталогов). Например: #include "../shared/globaldefs.h" • С помощью директивы #define определяется макрос. Каждое появление в тексте программы имени, расположенном после директивы #define, заменяется определенным для него значением. Например, директива #define PI 3.14159265359 указывает препроцессору на необходимость замены каждого появления в текущей единице компиляции лексемы PI лексемой 3.14159265359. Для предотвращения конфликтов имен с переменными и классами общей практикой стало назначение макросам имен, состоящих только из прописных букв. Можно определять макрос с аргументами: #define SQUARE(x) ((x) * (x)) Считается хорошим стилем окружение в теле макроса скобками любых параметров, а также всего тела макроса, что позволяет избегать проблем, связанных с приоритетностью операторов. В конце концов нам нужно, чтобы запись 7 * SQUARE(2 + 3) разворачивалась в 7 * ((2 + 3) * (2 + З)), а не в 7 * 2 + 3 * 2 + 3. Компиляторы С++ обычно позволяют определять макросы в командной строке, используя опцию —D или /D. Например: CC -DPI=3.14159265359 -с main.cpp Макросы были очень популярны в прежние дни, когда еще не были введены typedef, перечисления, константы, встраиваемые функции и шаблоны. В наши дни они играют важную роль в предотвращении многократных включений заголовочных файлов. • Макрос можно отменить в любом месте с помощью директивы #undef: #undef PI Эту возможность необходимо использовать, если требуется переопределить макрос, поскольку препроцессор не позволяет определять один и тот же макрос дважды. Эту директиву полезно также применять для управления условной компиляцией. • Отдельные фрагменты программного кода можно обрабатывать или пропускать при помощи директив #if, #elif, #else и #endif в зависимости от конкретных числовых значений макросов. Например: #define NO_OPTIM 0 #define OPTIM_FOR_SPEED 1 #define OPTIM_FOR_MEMORY 2 #define OPTIMIZATION OPTIM_FOR_MEMORY … #if OPTIMIZATION == OPTIM_FOR_SPEED typedef int MyInt; #elif OPTIMIZATION == OPTIM_FOR_MEMORY typedef short MyInt; #else typedef long long MyInt; #endif В приведенном выше примере компилятором будет обрабатываться только второе объявление, которое вводит синоним для short. Изменяя определение макроса OPTIMIZATION, мы получим другие программы. Если макрос не определен, он будет иметь значение 0. Другим оператором условной компиляции является проверка макроса на предмет его определения. Это можно сделать следующим образом, используя оператор defined(): #define OPTIM_FOR_MEMORY … #if defined(OPTIM_FOR_SPEED) typedef int MyInt; #elif defined(OPTIM_FOR_MEMORY) typedef short MyInt; #else typedef long long MyInt; #endif • Ради удобства препроцессор воспринимает #ifdef X и #ifndef X как синонимы #if defined(X) и #if !defined(X). Для пpeдoтвpaщeния мнoгoкpaтныx включeний заголовочного файла мы окружаем его содержимое следующими директивами: #ifndef MYHEADERFILE_H #define MYHEADERFILE_H … #endif При первом включении заголовочного файла символ MYHEADERFILE_H оказывается неопределенным, поэтому компилятор обрабатывает программный код, заключенный между директивами #ifndef и #endif. При повторном и последующих включениях заголовочного файла символ MYHEADERFILE_H оказывается определенным, поэтому весь блок #ifndef … #endif пропускается. • Директива #errоr генерирует на этапе компиляции определенное пользователем сообщение об ошибке. Эта директива часто используется в комбинации с директивами условной компиляции для вывода сообщения о возникновении недопустимого условия. Например: class UniChar { public: #if BYTE_ORDER == BIG_ENDIAN uchar row; uchar cell; #elif BYTE_ORDER == LITTLE_ENDIAN uchar cell; uchar row; #else #error "BYTE_ORDER must be BIG_ENDIAN or LITTLE_ENDIAN" #endif }; В отличие от большинства других конструкций С++, в которых недопустимы пробельные символы, препроцессорные директивы должны быть единственными в строке и не должны содержать точку с запятой. Слишком длинные директивы можно разбивать на несколько строк, заканчивая каждую строку, кроме последней, обратной наклонной чертой. Стандартная библиотека С++В данном разделе мы кратко рассмотрим стандартную библиотеку С++. На рис. Б.З приводится список базовых заголовочных файлов С++: • <bitset> — шаблонный класс для представления последовательностей битов фиксированной длины, • <complex> — шаблонный класс для представления комплексных чисел, • <exception> — типы и функции, относящиеся к обработке исключений, • <limits> — шаблонный класс, определяющий свойства числовых типов, • <locale> — классы и функции, относящиеся к локализации, • <new> — функции, управляющие динамическим распределением памяти, • <stdexcept> — заранее определенные типы исключений для вывода сообщений об ошибках, • <string> — шаблонный строковый контейнер и свойства символов, • <typeinfo> — класс, предоставляющий основную метаинформацию о типах, • <valarray> — шаблонные классы для представления массивов значений. Заголовочные файлы <exception>, <limits>, <new> и <typeinfo> поддерживают возможности языка С++; например, <limits> позволяет проверять возможности поддержки компилятором целочисленной арифметики и арифметики чисел с плавающей точкой, a <typeinfo> предлагает основные средства анализа информации о типах. Другие заголовочные файлы предоставляют часто используемые классы, в том числе класс строки и тип комплексных чисел. Функциональность, предлагаемая заголовочными файлами <bitset>, <locale>, <string> и <typeinfo>, свободно перекрывается в Qt классами QBitArray, QLocale, QString и QMetaObject. Стандартный С++ также включает ряд заголовочных файлов, обеспечивающих ввод—вывод (см. рис. Б.4): • <fstream> — шаблонные классы, манипулирующие внешними файлами, • <iomanip> — манипуляторы потоков ввода—вывода, принимающие один аргумент, • <ios> — шаблонный базовый класс потоков ввода—вывода, • <iosfwd> — предварительные объявления нескольких шаблонных классов потоков ввода—вывода, • <iostream> — стандартные потоки ввода—вывода (cin, cout, cerr, ctog), • <istream> — шаблонный класс, управляющий вводом из буфера потока, • <ostream> — шаблонный класс, управляющий выводом в буфер потока, • <sstream> — шаблонные классы, связывающие буферы потоков со строками, • <streambuf> — шаблонные классы, обеспечивающие буфер для операций ввода—вывода, • <strstream> — классы для выполнения операций потокового ввода-вывода с массивами символов. Классы стандартного ввода—вывода проектировались в 80-х годах и обладают излишней сложностью, что сильно затрудняет их понимание, причем настолько, что этой теме были посвящены целые книги. Кроме того, программист остается наедине с ящиком Пандоры неразрешенных проблем, связанных с кодировкой символов и зависимого от платформы двоичного представления элементарных типов данных. В главе 12 («Ввод—вывод») представлены соответствующие классы Qt, обеспечивающие ввод—вывод символов в кодировке Unicode, а также большой набор национальных кодировок и абстракцию независимого от платформы хранения двоичных данных. Qt—классы ввода—вывода формируют основу поддержки межпроцессной связи, работы с сетями и XML. Qt—классы двоичных и текстовых потоков можно очень легко расширить для работы с пользовательскими типами данных. В начале 90-х годов была введена стандартная библиотека шаблонов (Standard Template Library — STL), представляющая собой набор шаблонных классов-контейнеров, итераторов и алгоритмов, которые вошли в стандарт ISO С++ в последний момент. На рис. Б.5 приводится список заголовочных файлов библиотеки STL: • <algorithm> — шаблонные функции общего назначения, • <deque> — шаблонный контейнер очереди с двумя концами, • <functional> — шаблоны, помогающие конструировать и манипулировать функторами, • <iterator> — шаблоны, помогающие конструировать и манипулировать итераторами, • <list> — шаблонный контейнер двусвязного списка, • <map> — шаблонные контейнеры ассоциативных массивов, связывающие ключ с одним и с несколькими значениями, • <memory> — утилиты, позволяющие упростить управление памятью, • <numeric> — шаблонные операции с числами, • <queue> — шаблонный контейнер очереди, • <set> — шаблонные контейнеры наборов, допускающие и недопускающие повторения элементов, • <stack> — шаблонный контейнер стека, • <utility> — основные шаблонные функции, • <vector> — шаблонный контейнер вектора. Проект STL выполнен очень аккуратно, почти с математической точностью, и обеспечивает обобщенную типобезопасную функциональность. Qt предоставляет свои собственные классы—контейнеры, разработка которых отчасти инспирирована STL. Они описываются в главе 11. Поскольку С++ фактически является супермножеством относительно языка программирования С, программисты С++ имеют в своем распоряжении также полную библиотеку С. Заголовочные файлы библиотеки С доступны как с их традиционными именами (например, <stdio.h>), так и с новыми именами с с—префиксом и без расширения .h (например, <cstdio>). Когда используется новая версия имен заголовочных файлов, функции и типы данных объявляются в пространстве имен std. (Это не относится к таким макросам, как ASSERT(), потому что препроцессор никак не реагирует на пространства имен.) Рекомендуется использовать новый стиль обозначения имен, если его поддерживает ваш компилятор. На рис. Б.6 приводится список заголовочных файлов библиотеки С: • <cassert> — макрос ASSERT(), • <cctype> — функции классификации и отображения символов, • <cerrno> — макросы, относящиеся к сообщениям об ошибочных ситуациях, • <cfloat> — макросы, определяющие свойства элементарных типов чисел с плавающей точкой, • <ciso646> — альтернативное представление для пользователей набора символов ISO 646, • <climits> — макросы, определяющие свойства элементарных целочисленных типов, • <clocale> — функции и типы, относящиеся к локализации, • <cmath> — математические функции и константы, • <csetjmp> — функции для выполнения нелокальных переходов, • <csignal> — функции для обработки системных сигналов, • <cstdarg> — макросы для реализации функций с переменным числом аргументов, • <cstddef> — определения, общие для некоторых стандартных заголовочных файлов, • <cstdio> — функции ввода—вывода, • <cstdlib> — общие вспомогательные функции, • <cstring> — функции для манипулирования массивами char, • <ctime> — типы и функции для манипулирования временем, • <cwchar> — утилиты для работы с многобайтовыми символами и символами расширенной кодировки, • <cwctype> — функции классификации и отображения символов расширенной кодировки. Большинство из них предлагает функциональность, которая перекрывается более новыми заголовочными файлами С++ или Qt. Стоит отметить одно из исключений — <cmath>, в котором объявляются такие математические функции, как sin(), sqrt() и pow(). Этим завершается наш краткий обзор стандартной библиотеки С++. В сети Интернет можно получить предлагаемое компанией «Dinkumware» полное справочное руководство по стандартной библиотеке С++, размещенное на веб-странице http://www.dinkumware.com/refxcpp.html, и предлагаемое компанией «SGI» подробное руководство программиста по STL, размещенное на веб-странице http://www.sgi.com/tech/stl/. Официальное описание стандартной библиотеки С++ можно найти в стандартах С и С++ в виде файлов PDF или получить в бумажном виде в Международной организации по стандартизации (International Organization for Standardization — ISO). В данном приложении мы бегло рассмотрели многие темы. Когда вы станете изучать средства разработки Qt, начиная с главы 1, вы обнаружите, что используемый ими синтаксис значительно проще и аккуратнее, чем можно было бы предположить после прочтения данного приложения. Хорошее Qt—программирование требует применения только подмножества языка С++ и обычно не требует использования более сложного и не очень понятного синтаксиса, возможного в С++. После того как вы станете вводить программный код, собирать исполняемые модули и запускать их, четкость и простота принятого в Qt подхода станет очевидной. И когда вы начнете писать более амбициозные программы, особенно те, в которых требуется обеспечить быструю и сложную графику, возможности комбинации С++ и Qt всегда будут идти в ногу с вашими потребностями. Примечания:1 Если вы получаете ошибку при компиляции оператора #include <QApplication>, возможно, это происходит из-за применения старой версии Qt. Убедитесь, что вы используете Qt 4.1.1 или более новую версию Qt 4. 9 Компания Microsoft вместо long long использует тип __int64. В программах Qt доступен тип qlonglong в качестве альтернативы, работающей на всех платформах Qt. 10 Некоторые компиляторы позволяют использовать также переменные, однако нельзя на это рассчитывать в переносимых программах. |
|
||
|
Главная | В избранное | Наш E-MAIL | Прислать материал | Нашёл ошибку | Наверх |
||||
|
|
||||